
أساسيات الشبكة العصبية المتكررة: ما تحتاج إلى معرفته
نشرت: 2024-09-19تعد الشبكات العصبية المتكررة (RNNs) من الأساليب الأساسية في مجالات تحليل البيانات والتعلم الآلي (ML) والتعلم العميق. تهدف هذه المقالة إلى استكشاف RNNs وتفصيل وظائفها وتطبيقاتها ومزاياها وعيوبها ضمن السياق الأوسع للتعلم العميق.
جدول المحتويات
ما هو RNN؟
كيف تعمل شبكات RNN
أنواع RNNs
RNNs مقابل المحولات وCNNs
تطبيقات RNNs
المزايا
العيوب
ما هي الشبكة العصبية المتكررة؟
الشبكة العصبية المتكررة هي شبكة عصبية عميقة يمكنها معالجة البيانات المتسلسلة من خلال الحفاظ على ذاكرة داخلية، مما يسمح لها بتتبع المدخلات السابقة لتوليد المخرجات. تعد شبكات RNN مكونًا أساسيًا للتعلم العميق وهي مناسبة بشكل خاص للمهام التي تتضمن بيانات تسلسلية.
يشير "المتكرر" في "الشبكة العصبية المتكررة" إلى كيفية قيام النموذج بدمج المعلومات من المدخلات السابقة مع المدخلات الحالية. يتم تخزين المعلومات من المدخلات القديمة في نوع من الذاكرة الداخلية، تسمى "الحالة المخفية". إنه يتكرر، حيث يقوم بتغذية الحسابات السابقة مرة أخرى إلى نفسه لإنشاء تدفق مستمر للمعلومات.
دعونا نوضح بمثال: لنفترض أننا أردنا استخدام RNN لاكتشاف المشاعر (الإيجابية أو السلبية) للجملة "لقد أكل الفطيرة بسعادة". ستقوم RNN بمعالجة الكلمةhe، وتحديث حالتها المخفية لدمج تلك الكلمة، ثم الانتقال إلىate، ودمج ذلك مع ما تعلمتهمنه، وهكذا مع كل كلمة حتى تنتهي الجملة. لوضع الأمر في نصابه الصحيح، فإن قراءة الإنسان لهذه الجملة من شأنها تحديث فهمه مع كل كلمة. بمجرد قراءة الجملة بأكملها وفهمها، يمكن للإنسان أن يقول أن الجملة إيجابية أو سلبية. إن عملية الفهم الإنسانية هذه هي ما تحاول الحالة الخفية تقريبه.
تعد شبكات RNN أحد نماذج التعلم العميق الأساسية. لقد قاموا بعمل جيد جدًا في مهام معالجة اللغة الطبيعية (NLP)، على الرغم من أن المحولات قد حلت محلهم. المحولات عبارة عن بنيات شبكة عصبية متقدمة تعمل على تحسين أداء RNN من خلال، على سبيل المثال، معالجة البيانات بالتوازي والقدرة على اكتشاف العلاقات بين الكلمات المتباعدة في النص المصدر (باستخدام آليات الانتباه). ومع ذلك، لا تزال شبكات RNN مفيدة لبيانات السلاسل الزمنية وفي المواقف التي تكون فيها النماذج الأبسط كافية.
كيف تعمل شبكات RNN
لوصف كيفية عمل RNNs بالتفصيل، دعنا نعود إلى مهمة المثال السابقة: قم بتصنيف شعور الجملة "لقد أكل الفطيرة بسعادة".
نبدأ بشبكة RNN مدربة تقبل مدخلات النص وتعيد مخرجات ثنائية (يمثل 1 موجبًا و0 يمثل سالبًا). قبل تقديم المدخلات إلى النموذج، تكون الحالة المخفية عامة، وقد تم تعلمها من عملية التدريب ولكنها ليست خاصة بالمدخلات بعد.
تم تمرير الكلمة الأولى"هو"إلى النموذج. داخل RNN، يتم بعد ذلك تحديث حالتها المخفية (إلى الحالة المخفية h1) لدمج الكلمةHe. بعد ذلك، يتم تمرير الكلمةateإلى RNN، ويتم تحديث h1 (إلى h2) لتضمين هذه الكلمة الجديدة. تتكرر هذه العملية حتى يتم تمرير الكلمة الأخيرة. ويتم تحديث الحالة المخفية (h4) لتشمل الكلمة الأخيرة. ثم يتم استخدام الحالة المخفية المحدثة لإنشاء إما 0 أو 1.
فيما يلي تمثيل مرئي لكيفية عمل عملية RNN:
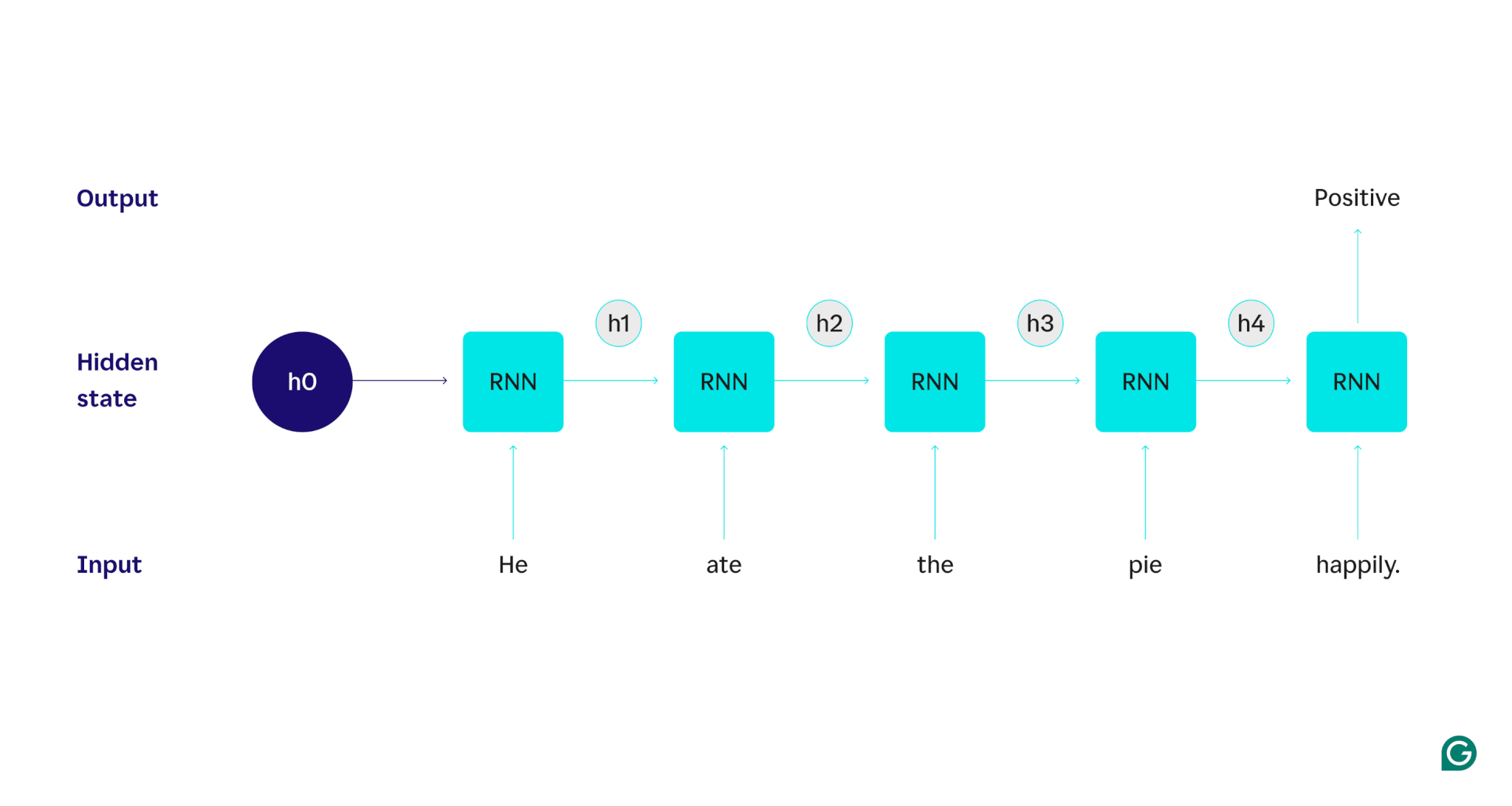
هذا التكرار هو جوهر RNN، ولكن هناك بعض الاعتبارات الأخرى:
- تضمين النص:لا تستطيع شبكة RNN معالجة النص مباشرة لأنها تعمل فقط على التمثيلات الرقمية. يجب تحويل النص إلى تضمينات قبل أن تتم معالجته بواسطة RNN.
- توليد المخرجات:سيتم إنشاء مخرجات بواسطة RNN في كل خطوة. ومع ذلك، قد لا يكون الإخراج دقيقًا جدًا حتى تتم معالجة معظم البيانات المصدر. على سبيل المثال، بعد معالجة الجزء "He ate" من الجملة فقط، قد يكون RNN غير متأكد مما إذا كان يمثل شعورًا إيجابيًا أم سلبيًا - قد تبدو عبارة "He ate" محايدة. فقط بعد معالجة الجملة الكاملة سيكون إخراج RNN دقيقًا.
- تدريب RNN:يجب تدريب RNN على إجراء تحليل المشاعر بدقة. يتضمن التدريب استخدام العديد من الأمثلة المصنفة (على سبيل المثال، "أكل الفطيرة بغضب"، والتي تم تصنيفها على أنها سلبية)، وتشغيلها من خلال شبكة RNN، وتعديل النموذج بناءً على مدى بعد تنبؤاته. تقوم هذه العملية بتعيين القيمة الافتراضية وآلية التغيير للحالة المخفية، مما يسمح لـ RNN بمعرفة الكلمات المهمة للتتبع خلال الإدخال.
أنواع الشبكات العصبية المتكررة
هناك عدة أنواع مختلفة من شبكات RNN، ويختلف كل منها في بنيتها وتطبيقها. تختلف شبكات RNN الأساسية في الغالب في حجم مدخلاتها ومخرجاتها. تعالج شبكات RNN المتقدمة، مثل شبكات الذاكرة طويلة المدى (LSTM)، بعض القيود المفروضة على شبكات RNN الأساسية.
شبكات RNN الأساسية
RNN واحد لواحد:يأخذ RNN هذا مدخلاً بطول واحد ويعيد مخرجًا بطول واحد. لذلك، لا يحدث أي تكرار فعليًا، مما يجعلها شبكة عصبية قياسية بدلاً من شبكة RNN. مثال على RNN واحد لواحد هو مصنف الصور، حيث يكون الإدخال صورة واحدة والإخراج عبارة عن تسمية (على سبيل المثال، "طائر").
واحد إلى متعدد RNN:يأخذ RNN هذا مدخلاً بطول واحد ويعيد مخرجات متعددة الأجزاء. على سبيل المثال، في مهمة التعليق على الصورة، يكون الإدخال هو صورة واحدة، ويكون الإخراج عبارة عن سلسلة من الكلمات التي تصف الصورة (على سبيل المثال، "طائر يعبر فوق نهر في يوم مشمس").
RNN متعدد إلى واحد:يأخذ RNN هذا مدخلات متعددة الأجزاء (على سبيل المثال، جملة أو سلسلة من الصور أو بيانات السلاسل الزمنية) ويعيد مخرجات بطول واحد. على سبيل المثال، مصنف مشاعر الجملة (مثل الذي ناقشناه)، حيث يكون الإدخال جملة والمخرجات عبارة عن تسمية مشاعر واحدة (إما إيجابية أو سلبية).
RNN متعدد إلى متعدد:يأخذ RNN هذا مدخلات متعددة الأجزاء ويعيد مخرجات متعددة الأجزاء. ومن الأمثلة على ذلك نموذج التعرف على الكلام، حيث يكون الإدخال عبارة عن سلسلة من أشكال الموجات الصوتية ويكون الإخراج عبارة عن سلسلة من الكلمات التي تمثل المحتوى المنطوق.
RNN المتقدم: الذاكرة طويلة المدى (LSTM)
تم تصميم شبكات الذاكرة الطويلة قصيرة المدى لمعالجة مشكلة مهمة تتعلق بشبكات RNN القياسية: فهي تنسى المعلومات عبر المدخلات الطويلة. في شبكات RNN القياسية، يتم ترجيح الحالة المخفية بشكل كبير تجاه الأجزاء الحديثة من الإدخال. في المدخلات التي يبلغ طولها آلاف الكلمات، سوف تنسى شبكة RNN التفاصيل المهمة من الجمل الافتتاحية. تمتلك LSTMs بنية خاصة للتغلب على مشكلة النسيان هذه. لديهم وحدات تختار وتختار المعلومات التي يجب تذكرها ونسيانها بشكل صريح. سيتم نسيان المعلومات الحديثة ولكن غير المفيدة، في حين سيتم الاحتفاظ بالمعلومات القديمة ولكن ذات الصلة. ونتيجة لذلك، تعد شبكات LSTM أكثر شيوعًا بكثير من شبكات RNN القياسية، فهي ببساطة تؤدي أداءً أفضل في المهام المعقدة أو الطويلة. ومع ذلك، فهم ليسوا مثاليين لأنهم ما زالوا يختارون نسيان العناصر.
RNNs مقابل المحولات وCNNs
هناك نموذجان شائعان آخران للتعلم العميق هما الشبكات العصبية التلافيفية (CNNs) والمحولات. كيف تختلف؟

RNNs مقابل المحولات
يتم استخدام كل من RNNs والمحولات بشكل كبير في البرمجة اللغوية العصبية. ومع ذلك، فهي تختلف بشكل كبير في بنياتها وأساليب معالجة المدخلات.
الهندسة المعمارية والمعالجة
- شبكات RNN:تقوم شبكات RNN بمعالجة الإدخال بشكل تسلسلي، كلمة واحدة في كل مرة، مع الحفاظ على حالة مخفية تحمل معلومات من الكلمات السابقة. تعني هذه الطبيعة التسلسلية أن شبكات RNN يمكن أن تعاني من التبعيات طويلة المدى بسبب هذا النسيان، حيث يمكن فقدان المعلومات السابقة مع تقدم التسلسل.
- المحولات:تستخدم المحولات آلية تسمى "الانتباه" لمعالجة المدخلات. على عكس شبكات RNN، تنظر المحولات إلى التسلسل بأكمله في وقت واحد، وتقارن كل كلمة بكل كلمة أخرى. يؤدي هذا الأسلوب إلى التخلص من مشكلة النسيان، حيث تتمتع كل كلمة بإمكانية الوصول المباشر إلى سياق الإدخال بأكمله. لقد أظهرت المحولات أداءً فائقًا في مهام مثل إنشاء النص وتحليل المشاعر بسبب هذه الإمكانية.
التوازي
- RNNs:تعني الطبيعة التسلسلية لشبكات RNN أن النموذج يجب أن يكمل معالجة جزء واحد من المدخلات قبل الانتقال إلى الجزء التالي. يستغرق هذا وقتًا طويلاً جدًا، حيث تعتمد كل خطوة على الخطوة السابقة.
- المحولات:تقوم المحولات بمعالجة جميع أجزاء المدخلات في وقت واحد، حيث أن بنيتها لا تعتمد على حالة مخفية تسلسلية. وهذا يجعلها أكثر قابلية للتوازي وأكثر كفاءة. على سبيل المثال، إذا كانت معالجة الجملة تستغرق 5 ثوانٍ لكل كلمة، فإن RNN سيستغرق 25 ثانية لجملة مكونة من 5 كلمات، بينما سيستغرق المحول 5 ثوانٍ فقط.
الآثار العملية
وبسبب هذه المزايا، يتم استخدام المحولات على نطاق واسع في الصناعة. ومع ذلك، فإن شبكات RNN، وخاصة شبكات الذاكرة طويلة المدى (LSTM)، لا تزال فعالة في المهام الأبسط أو عند التعامل مع تسلسلات أقصر. غالبًا ما تُستخدم وحدات LSTM كوحدات تخزين ذاكرة مهمة في بنيات التعلم الآلي الكبيرة.
RNNs مقابل CNNs
تختلف شبكات CNN بشكل أساسي عن شبكات RNN من حيث البيانات التي تتعامل معها وآلياتها التشغيلية.
نوع البيانات
- شبكات RNN:تم تصميم شبكات RNN للبيانات المتسلسلة، مثل النصوص أو السلاسل الزمنية، حيث يكون ترتيب نقاط البيانات مهمًا.
- شبكات CNN:تُستخدم شبكات CNN في المقام الأول للبيانات المكانية، مثل الصور، حيث يكون التركيز على العلاقات بين نقاط البيانات المتجاورة (على سبيل المثال، يرتبط اللون والكثافة والخصائص الأخرى للبكسل في الصورة ارتباطًا وثيقًا بخصائص النقاط الأخرى القريبة بكسل).
عملية
- RNNs:تحتفظ RNNs بذاكرة التسلسل بأكمله، مما يجعلها مناسبة للمهام التي يكون فيها السياق والتسلسل مهمًا.
- شبكات CNN:تعمل شبكات CNN من خلال النظر إلى المناطق المحلية للإدخال (على سبيل المثال، وحدات البكسل المجاورة) من خلال الطبقات التلافيفية. وهذا يجعلها فعالة للغاية لمعالجة الصور ولكنها أقل فعالية بالنسبة للبيانات التسلسلية، حيث قد تكون التبعيات طويلة المدى أكثر أهمية.
طول الإدخال
- شبكات RNN:يمكن لشبكات RNN التعامل مع تسلسلات الإدخال ذات الطول المتغير ببنية أقل تحديدًا، مما يجعلها مرنة لأنواع البيانات المتسلسلة المختلفة.
- شبكات CNN:تتطلب شبكات CNN عادةً مدخلات ذات حجم ثابت، مما قد يشكل قيدًا على التعامل مع التسلسلات ذات الطول المتغير.
تطبيقات RNNs
تُستخدم شبكات RNN على نطاق واسع في مجالات مختلفة نظرًا لقدرتها على التعامل مع البيانات التسلسلية بفعالية.
معالجة اللغة الطبيعية
اللغة هي شكل متسلسل للغاية من البيانات، لذا فإن شبكات RNN تؤدي أداءً جيدًا في المهام اللغوية. تتفوق RNNs في مهام مثل إنشاء النص، وتحليل المشاعر، والترجمة، والتلخيص. باستخدام مكتبات مثل PyTorch، يمكن لأي شخص إنشاء روبوت دردشة بسيط باستخدام RNN وبضعة غيغابايت من الأمثلة النصية.
التعرف على الكلام
التعرف على الكلام هو لغة في جوهره وبالتالي فهو متسلسل للغاية أيضًا. يمكن استخدام RNN متعدد إلى متعدد لهذه المهمة. في كل خطوة، تأخذ RNN الحالة المخفية السابقة وشكل الموجة، وتخرج الكلمة المرتبطة بشكل الموجة (استنادًا إلى سياق الجملة حتى تلك النقطة).
جيل الموسيقى
الموسيقى أيضًا متسلسلة للغاية. تؤثر الإيقاعات السابقة في الأغنية بقوة على الإيقاعات المستقبلية. يمكن لـ RNN متعدد إلى متعدد أن يأخذ بضع دقات بداية كمدخل ثم يقوم بإنشاء نبضات إضافية حسب رغبة المستخدم. وبدلاً من ذلك، يمكن أن يأخذ إدخال نص مثل "موسيقى الجاز اللحنية" ويخرج أفضل تقريب لإيقاعات موسيقى الجاز اللحنية.
مزايا شبكات RNN
على الرغم من أن RNNs لم تعد نموذج البرمجة اللغوية العصبية بحكم الأمر الواقع، إلا أنها لا تزال لديها بعض الاستخدامات بسبب بعض العوامل.
أداء متسلسل جيد
تعمل شبكات RNN، وخاصة LSTM، بشكل جيد فيما يتعلق بالبيانات التسلسلية. يمكن لـ LSTMs، بفضل بنية الذاكرة المتخصصة الخاصة بها، إدارة المدخلات التسلسلية الطويلة والمعقدة. على سبيل المثال، كانت خدمة الترجمة من Google تعمل على نموذج LSTM قبل عصر المحولات. يمكن استخدام LSTMs لإضافة وحدات ذاكرة استراتيجية عند دمج الشبكات القائمة على المحولات لتشكيل بنيات أكثر تقدمًا.
نماذج أصغر وأبسط
عادةً ما تحتوي شبكات RNN على معلمات نموذجية أقل من المحولات. تتطلب طبقات الانتباه والتغذية في المحولات المزيد من المعلمات لتعمل بفعالية. يمكن تدريب RNNs بعدد أقل من عمليات التشغيل وأمثلة البيانات، مما يجعلها أكثر كفاءة لحالات الاستخدام الأبسط. وينتج عن ذلك نماذج أصغر حجمًا وأقل تكلفة وأكثر كفاءة ولا تزال ذات أداء كافٍ.
عيوب RNNs
لقد فقدت شبكات RNN شعبيتها لسبب ما: المحولات، على الرغم من حجمها الكبير وعملية التدريب الخاصة بها، لا تعاني من نفس العيوب التي تعاني منها شبكات RNN.
ذاكرة محدودة
إن الحالة الخفية في شبكات RNN القياسية تحيّز بشكل كبير المدخلات الحديثة، مما يجعل من الصعب الاحتفاظ بالتبعيات طويلة المدى. المهام ذات المدخلات الطويلة لا تعمل بشكل جيد مع شبكات RNN. في حين تهدف LSTMs إلى معالجة هذه المشكلة، إلا أنها تخفف منها فقط ولا تحلها بالكامل. تتطلب العديد من مهام الذكاء الاصطناعي التعامل مع المدخلات الطويلة، مما يجعل الذاكرة المحدودة عيبًا كبيرًا.
غير قابلة للتوازي
يعتمد كل تشغيل لنموذج RNN على مخرجات التشغيل السابق، وتحديدًا الحالة المخفية المحدثة. ونتيجة لذلك، يجب معالجة النموذج بأكمله بشكل تسلسلي لكل جزء من المدخلات. في المقابل، يمكن للمحولات وشبكات CNN معالجة المدخلات بالكامل في وقت واحد. وهذا يسمح بالمعالجة المتوازية عبر وحدات معالجة الرسومات المتعددة، مما يؤدي إلى تسريع العملية الحسابية بشكل كبير. يؤدي افتقار شبكات RNN إلى إمكانية التوازي إلى تباطؤ التدريب، وتباطؤ توليد المخرجات، وانخفاض الحد الأقصى لكمية البيانات التي يمكن التعلم منها.
قضايا التدرج
قد يكون تدريب RNNs أمرًا صعبًا لأن عملية الانتشار العكسي يجب أن تمر بكل خطوة إدخال (الانتشار العكسي عبر الزمن). ونظرًا للخطوات الزمنية العديدة، فإن التدرجات - التي تشير إلى كيفية تعديل كل معلمة نموذج - يمكن أن تتدهور وتصبح غير فعالة. يمكن أن تفشل التدرجات عن طريق التلاشي، مما يعني أنها تصبح صغيرة جدًا ولم يعد النموذج قادرًا على استخدامها للتعلم، أو عن طريق الانفجار، حيث تصبح التدرجات كبيرة جدًا ويتجاوز النموذج تحديثاته، مما يجعل النموذج غير قابل للاستخدام. إن تحقيق التوازن بين هذه القضايا أمر صعب.