
ما هو التجهيز الزائد في التعلم الآلي؟
نشرت: 2024-10-15تعد مشكلة التجهيز الزائد مشكلة شائعة تظهر عند تدريب نماذج التعلم الآلي (ML). يمكن أن يؤثر سلبًا على قدرة النموذج على التعميم بما يتجاوز بيانات التدريب، مما يؤدي إلى تنبؤات غير دقيقة في سيناريوهات العالم الحقيقي. في هذه المقالة، سنستكشف ماهية التجاوز، وكيفية حدوثه، والأسباب الشائعة وراءه، والطرق الفعالة لاكتشافه ومنعه.
جدول المحتويات
- ما هو التجهيز الزائد؟
- كيف يحدث التجهيز الزائد
- الإفراط في التجهيز مقابل عدم التجهيز
- ما الذي يسبب التجهيز الزائد؟
- كيفية الكشف عن التجاوز
- كيفية تجنب الإفراط في التجهيز
- أمثلة على التجهيز الزائد
ما هو التجهيز الزائد؟
يحدث التجاوز عندما يتعلم نموذج التعلم الآلي الأنماط الأساسية والضوضاء في بيانات التدريب، ويصبح متخصصًا بشكل مفرط في مجموعة البيانات المحددة تلك. ويؤدي هذا التركيز المفرط على تفاصيل بيانات التدريب إلى ضعف الأداء عند تطبيق النموذج على بيانات جديدة غير مرئية، حيث يفشل في التعميم بما يتجاوز البيانات التي تم تدريبه عليها.
كيف يحدث التجهيز الزائد؟
يحدث التجاوز عندما يتعلم النموذج الكثير من التفاصيل المحددة والضوضاء في بيانات التدريب، مما يجعله حساسًا بشكل مفرط للأنماط التي لا معنى لها للتعميم. على سبيل المثال، فكر في نموذج مصمم للتنبؤ بأداء الموظف بناءً على التقييمات التاريخية. إذا كان النموذج مفرطًا في التناسب، فقد يركز كثيرًا على تفاصيل محددة غير قابلة للتعميم، مثل أسلوب التصنيف الفريد لمدير سابق أو ظروف معينة خلال دورة المراجعة السابقة. وبدلاً من تعلم العوامل الأوسع والهادفة التي تساهم في الأداء - مثل المهارات أو الخبرة أو نتائج المشروع - قد يواجه النموذج صعوبة في تطبيق معرفته على الموظفين الجدد أو تطوير معايير التقييم. يؤدي هذا إلى تنبؤات أقل دقة عند تطبيق النموذج على البيانات التي تختلف عن مجموعة التدريب.
الإفراط في التجهيز مقابل عدم التجهيز
على النقيض من التجهيز الزائد، يحدث التجهيز غير المناسب عندما يكون النموذج بسيطًا جدًا بحيث لا يمكنه التقاط الأنماط الأساسية في البيانات. ونتيجة لذلك، يكون أداؤه سيئًا في التدريب وكذلك في البيانات الجديدة، ويفشل في تقديم تنبؤات دقيقة.
لتصور الفرق بين نقص اللياقة البدنية وفرط اللياقة، تخيل أننا نحاول التنبؤ بالأداء الرياضي بناءً على مستوى التوتر لدى الشخص. يمكننا رسم البيانات وإظهار ثلاثة نماذج تحاول التنبؤ بهذه العلاقة:

1 عدم المطابقة:في المثال الأول، يستخدم النموذج خطًا مستقيمًا لإجراء التنبؤات، بينما تتبع البيانات الفعلية منحنى. النموذج بسيط للغاية ويفشل في فهم مدى تعقيد العلاقة بين مستوى التوتر والأداء الرياضي. ونتيجة لذلك، فإن التوقعات غير دقيقة في معظمها، حتى بالنسبة لبيانات التدريب. هذا غير لائق.
2الملاءمة المثالية:يوضح المثال الثاني نموذجًا يحقق التوازن الصحيح. فهو يلتقط الاتجاه الأساسي في البيانات دون المبالغة في تعقيده. يعمم هذا النموذج بشكل جيد على البيانات الجديدة لأنه لا يحاول ملاءمة كل اختلاف صغير في بيانات التدريب - فقط النمط الأساسي.
3التجهيز الزائد:في المثال الأخير، يستخدم النموذج منحنى متموجًا شديد التعقيد ليناسب بيانات التدريب. في حين أن هذا المنحنى دقيق للغاية بالنسبة لبيانات التدريب، فإنه يلتقط أيضًا الضوضاء العشوائية والقيم المتطرفة التي لا تمثل العلاقة الفعلية. هذا النموذج مفرط في التجهيز لأنه تم ضبطه بدقة شديدة ليتوافق مع بيانات التدريب، مما يجعل من المحتمل أن يقوم بتنبؤات سيئة بشأن البيانات الجديدة غير المرئية.
الأسباب الشائعة للتجاوز
الآن بعد أن عرفنا ما هو التجاوز وسبب حدوثه، دعنا نستكشف بعض الأسباب الشائعة بمزيد من التفصيل:
- بيانات التدريب غير كافية
- بيانات غير دقيقة أو خاطئة أو غير ذات صلة
- أوزان كبيرة
- الإفراط في التدريب
- الهندسة المعمارية النموذجية معقدة للغاية
بيانات التدريب غير كافية
إذا كانت مجموعة بيانات التدريب الخاصة بك صغيرة جدًا، فقد لا تمثل سوى بعض السيناريوهات التي سيواجهها النموذج في العالم الحقيقي. أثناء التدريب، قد يتناسب النموذج مع البيانات بشكل جيد. ومع ذلك، قد ترى أخطاء كبيرة بمجرد اختبارها على بيانات أخرى. تحد مجموعة البيانات الصغيرة من قدرة النموذج على التعميم على المواقف غير المرئية، مما يجعله عرضة للتجاوز.
بيانات غير دقيقة أو خاطئة أو غير ذات صلة
حتى لو كانت مجموعة بيانات التدريب الخاصة بك كبيرة، فقد تحتوي على أخطاء. يمكن أن تنشأ هذه الأخطاء من مصادر مختلفة، مثل تقديم المشاركين معلومات خاطئة في الاستطلاعات أو قراءات أجهزة الاستشعار الخاطئة. إذا حاول النموذج التعلم من هذه الأخطاء، فسوف يتكيف مع الأنماط التي لا تعكس العلاقات الأساسية الحقيقية، مما يؤدي إلى التجاوز.
أوزان كبيرة
في نماذج التعلم الآلي، الأوزان هي قيم رقمية تمثل الأهمية المخصصة لميزات محددة في البيانات عند إجراء التنبؤات. عندما تصبح الأوزان كبيرة بشكل غير متناسب، قد يفرط النموذج في الاحتواء، ويصبح حساسًا بشكل مفرط لميزات معينة، بما في ذلك التشويش في البيانات. يحدث هذا لأن النموذج يصبح معتمدًا بشكل كبير على ميزات معينة، مما يضر بقدرته على التعميم على البيانات الجديدة.
الإفراط في التدريب
أثناء التدريب، تقوم الخوارزمية بمعالجة البيانات على دفعات، وتحسب الخطأ لكل دفعة، وتضبط أوزان النموذج لتحسين دقته.
هل من الجيد الاستمرار في التدريب لأطول فترة ممكنة؟ ليس حقيقيًا! يمكن أن يؤدي التدريب المطول على نفس البيانات إلى حفظ النموذج لنقاط بيانات محددة، مما يحد من قدرته على التعميم على البيانات الجديدة أو غير المرئية، وهو جوهر التجهيز الزائد. يمكن التخفيف من هذا النوع من التجهيز الزائد باستخدام تقنيات الإيقاف المبكر أو مراقبة أداء النموذج على مجموعة التحقق من الصحة أثناء التدريب. سنناقش كيفية عمل ذلك لاحقًا في المقالة.

بنية النموذج معقدة للغاية
تشير بنية نموذج التعلم الآلي إلى كيفية تنظيم طبقاته وخلاياه العصبية وكيفية تفاعلها لمعالجة المعلومات.
يمكن للبنيات الأكثر تعقيدًا التقاط أنماط تفصيلية في بيانات التدريب. ومع ذلك، يزيد هذا التعقيد من احتمالية التجهيز الزائد، حيث قد يتعلم النموذج أيضًا التقاط الضوضاء أو التفاصيل غير ذات الصلة التي لا تساهم في التنبؤات الدقيقة للبيانات الجديدة. يمكن أن يساعد تبسيط البنية أو استخدام تقنيات التنظيم في تقليل مخاطر التجهيز الزائد.
كيفية الكشف عن التجاوز
يمكن أن يكون اكتشاف التجاوز أمرًا صعبًا لأن كل شيء قد يبدو أنه يسير على ما يرام أثناء التدريب، حتى عند حدوث التجاوز. سيستمر معدل الخسارة (أو الخطأ) - وهو مقياس لمدى تكرار خطأ النموذج - في الانخفاض، حتى في سيناريو التجهيز الزائد. إذًا، كيف يمكننا معرفة ما إذا حدث فرط التجهيز؟ نحن بحاجة إلى اختبار موثوق.
إحدى الطرق الفعالة هي استخدام منحنى التعلم، وهو مخطط يتتبع مقياسًا يسمى الخسارة. تمثل الخسارة حجم الخطأ الذي يرتكبه النموذج. ومع ذلك، فإننا لا نتتبع فقط فقدان بيانات التدريب؛ نقوم أيضًا بقياس الخسارة في البيانات غير المرئية، والتي تسمى بيانات التحقق من الصحة. ولهذا السبب يتكون منحنى التعلم عادة من خطين: فقدان التدريب وفقدان التحقق من الصحة.
إذا استمر فقدان التدريب في الانخفاض كما هو متوقع، لكن فقدان التحقق من الصحة يزداد، فهذا يشير إلى فرط التجهيز. بمعنى آخر، أصبح النموذج متخصصًا بشكل مفرط في بيانات التدريب ويكافح من أجل التعميم على البيانات الجديدة غير المرئية. قد يبدو منحنى التعلم كما يلي:
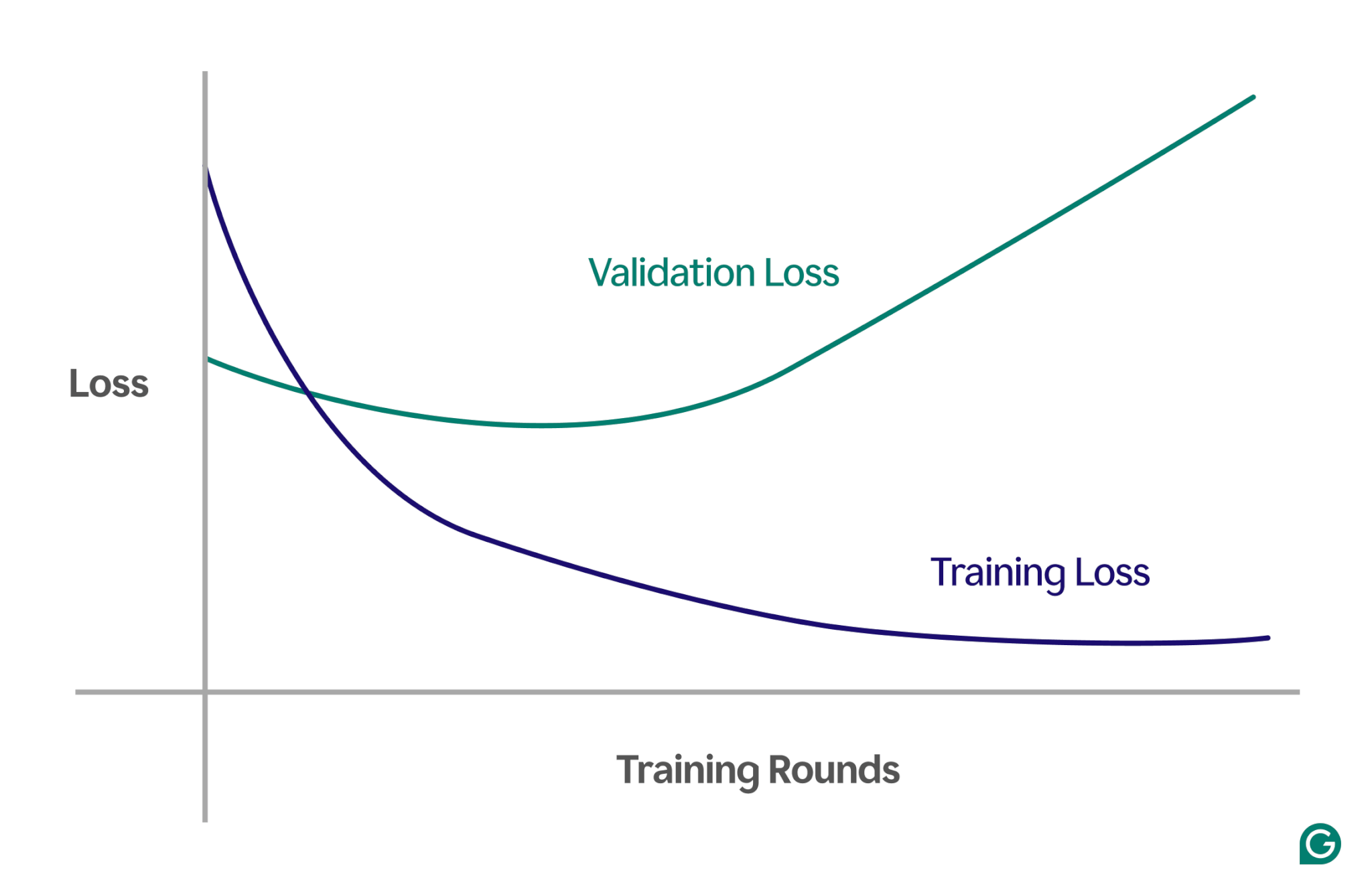
في هذا السيناريو، بينما يتحسن النموذج أثناء التدريب، فإنه يؤدي بشكل سيئ على البيانات غير المرئية. وهذا يعني على الأرجح أن التجهيز الزائد قد حدث.
كيفية تجنب الإفراط في التجهيز
يمكن معالجة التجهيز الزائد باستخدام عدة تقنيات. فيما يلي بعض الطرق الأكثر شيوعًا:
تقليل حجم النموذج
تسمح لك معظم بنيات النماذج بضبط عدد الأوزان عن طريق تغيير عدد الطبقات وأحجامها والمعلمات الأخرى المعروفة باسم المعلمات الفائقة. إذا كان تعقيد النموذج يسبب فرط التجهيز، فإن تقليل حجمه يمكن أن يساعد. إن تبسيط النموذج عن طريق تقليل عدد الطبقات أو الخلايا العصبية يمكن أن يقلل من خطر الإفراط في التجهيز، حيث سيكون لدى النموذج فرص أقل لحفظ بيانات التدريب.
تنظيم النموذج
يتضمن التنظيم تعديل النموذج لتثبيط الأوزان الكبيرة. أحد الأساليب هو ضبط دالة الخسارة بحيث تقيس الخطأ وتتضمن حجم الأوزان.
من خلال التنظيم، تعمل خوارزمية التدريب على تقليل الخطأ وحجم الأوزان، مما يقلل من احتمالية الأوزان الكبيرة ما لم توفر ميزة واضحة للنموذج. يساعد هذا في منع التجهيز الزائد عن طريق الحفاظ على النموذج أكثر عمومية.
إضافة المزيد من بيانات التدريب
يمكن أن تساعد زيادة حجم مجموعة بيانات التدريب أيضًا في منع التجهيز الزائد. ومع وجود المزيد من البيانات، تقل احتمالية تأثر النموذج بالتشويش أو عدم الدقة في مجموعة البيانات. إن تعريض النموذج لأمثلة أكثر تنوعًا سيجعله أقل ميلًا إلى حفظ نقاط البيانات الفردية وتعلم أنماط أوسع بدلاً من ذلك.
تطبيق تخفيض الأبعاد
في بعض الأحيان، قد تحتوي البيانات على ميزات (أو أبعاد) مترابطة، مما يعني أن العديد من الميزات مرتبطة بطريقة ما. تتعامل نماذج التعلم الآلي مع الأبعاد على أنها مستقلة، لذا إذا كانت الميزات مرتبطة، فقد يركز النموذج عليها بشكل كبير، مما يؤدي إلى التجاوز.
يمكن للتقنيات الإحصائية، مثل تحليل المكونات الرئيسية (PCA)، أن تقلل من هذه الارتباطات. تعمل PCA على تبسيط البيانات عن طريق تقليل عدد الأبعاد وإزالة الارتباطات، مما يجعل احتمال التجاوز أقل. من خلال التركيز على الميزات الأكثر صلة، يصبح النموذج أفضل في التعميم على البيانات الجديدة.
أمثلة عملية على الإفراط في التجهيز
لفهم التجهيز الزائد بشكل أفضل، دعنا نستكشف بعض الأمثلة العملية عبر مجالات مختلفة حيث يمكن أن يؤدي التجهيز الزائد إلى نتائج مضللة.
تصنيف الصور
تم تصميم مصنفات الصور للتعرف على الكائنات الموجودة في الصور، على سبيل المثال، ما إذا كانت الصورة تحتوي على طائر أو كلب.
قد ترتبط التفاصيل الأخرى بما تحاول اكتشافه في هذه الصور. على سبيل المثال، قد تحتوي صور الكلاب في كثير من الأحيان على عشب في الخلفية، بينما قد تحتوي صور الطيور غالبًا على سماء أو رؤوس أشجار في الخلفية.
إذا كانت جميع صور التدريب تحتوي على تفاصيل الخلفية المتسقة هذه، فقد يبدأ نموذج التعلم الآلي في الاعتماد على الخلفية للتعرف على الحيوان، بدلاً من التركيز على السمات الفعلية للحيوان نفسه. ونتيجة لذلك، عندما يُطلب من النموذج تصنيف صورة لطائر جاثم على العشب، فقد يصنفها بشكل غير صحيح على أنها كلب لأنها تتلاءم مع معلومات الخلفية. هذه حالة من التناسب الزائد لبيانات التدريب.
النمذجة المالية
لنفترض أنك تتداول الأسهم في وقت فراغك، وتعتقد أنه من الممكن التنبؤ بتحركات الأسعار بناءً على اتجاهات عمليات بحث Google لكلمات رئيسية معينة. يمكنك إعداد نموذج للتعلم الآلي باستخدام بيانات Google Trends لآلاف الكلمات.
نظرًا لوجود الكثير من الكلمات، فمن المحتمل أن يُظهر بعضها ارتباطًا بأسعار أسهمك عن طريق الصدفة البحتة. قد يبالغ النموذج في احتواء هذه الارتباطات المصادفة، مما يؤدي إلى تنبؤات سيئة بشأن البيانات المستقبلية لأن الكلمات ليست تنبؤات ذات صلة بأسعار الأسهم.
عند بناء نماذج للتطبيقات المالية، من المهم فهم الأساس النظري للعلاقات الموجودة في البيانات. يمكن أن يؤدي إدخال مجموعات كبيرة من البيانات إلى نموذج دون اختيار دقيق للميزات إلى زيادة خطر التجهيز الزائد، خاصة عندما يحدد النموذج ارتباطات زائفة موجودة بالصدفة البحتة في بيانات التدريب.
الخرافة الرياضية
على الرغم من أن الخرافات الرياضية لا ترتبط ارتباطًا وثيقًا بالتعلم الآلي، إلا أنها يمكن أن توضح مفهوم التجهيز الزائد، خاصة عندما تكون النتائج مرتبطة ببيانات ليس لها علاقة منطقيًا بالنتيجة.
خلال بطولة كأس الأمم الأوروبية لكرة القدم 2008 وكأس العالم لكرة القدم 2010، تم استخدام الأخطبوط المسمى بول للتنبؤ بنتائج المباريات التي تنطوي على ألمانيا. حصل بول على أربعة من أصل ستة تنبؤات صحيحة في عام 2008 وكلها في عام 2010.
إذا نظرت فقط إلى "بيانات التدريب" الخاصة بتنبؤات بول السابقة، فإن النموذج الذي يتفق مع اختيارات بول سيبدو أنه يتنبأ بالنتائج بشكل جيد للغاية. ومع ذلك، لن يتم تعميم هذا النموذج بشكل جيد على الألعاب المستقبلية، حيث أن اختيارات الأخطبوط هي تنبؤات غير موثوقة لنتائج المباراة.