
ما هو عدم الملاءمة في التعلم الآلي؟
نشرت: 2024-10-16يعد نقص التجهيز مشكلة شائعة تمت مواجهتها أثناء تطوير نماذج التعلم الآلي (ML). ويحدث ذلك عندما يكون النموذج غير قادر على التعلم بشكل فعال من بيانات التدريب، مما يؤدي إلى أداء دون المستوى. في هذه المقالة، سوف نستكشف ما هو نقص الملاءمة، وكيف يحدث، واستراتيجيات تجنبه.
جدول المحتويات
- ما هو نقص الملاءمة؟
- كيف يحدث نقص التجهيز
- التجهيز الزائد مقابل التجهيز الزائد
- الأسباب الشائعة لنقص التجهيز
- كيفية اكتشاف نقص التجهيز
- تقنيات لمنع نقص التجهيز
- أمثلة عملية على نقص التجهيز
ما هو نقص الملاءمة؟
يحدث القصور عندما يفشل نموذج التعلم الآلي في التقاط الأنماط الأساسية في بيانات التدريب، مما يؤدي إلى ضعف الأداء في كل من بيانات التدريب والاختبار. عندما يحدث هذا، فهذا يعني أن النموذج بسيط جدًا ولا يقوم بعمل جيد في تمثيل العلاقات الأكثر أهمية بين البيانات. ونتيجة لذلك، يواجه النموذج صعوبة في تقديم تنبؤات دقيقة لجميع البيانات، سواء البيانات التي تمت مشاهدتها أثناء التدريب أو أي بيانات جديدة غير مرئية.
كيف يحدث نقص التجهيز؟
يحدث القصور عندما تنتج خوارزمية التعلم الآلي نموذجًا يفشل في التقاط أهم خصائص بيانات التدريب؛ تعتبر النماذج التي تفشل بهذه الطريقة بسيطة للغاية. على سبيل المثال، تخيل أنك تستخدم الانحدار الخطي للتنبؤ بالمبيعات بناءً على الإنفاق التسويقي، والمعلومات السكانية للعملاء، والموسمية. يفترض الانحدار الخطي أن العلاقة بين هذه العوامل والمبيعات يمكن تمثيلها كمزيج من الخطوط المستقيمة.
على الرغم من أن العلاقة الفعلية بين الإنفاق التسويقي والمبيعات قد تكون منحنية أو تتضمن تفاعلات متعددة (على سبيل المثال، زيادة المبيعات بسرعة في البداية، ثم الاستقرار)، فإن النموذج الخطي سوف يبالغ في التبسيط عن طريق رسم خط مستقيم. ويغفل هذا التبسيط الفروق الدقيقة المهمة، مما يؤدي إلى ضعف التوقعات والأداء العام.
هذه المشكلة شائعة في العديد من نماذج تعلم الآلة حيث يمنع التحيز العالي (الافتراضات الصارمة) النموذج من تعلم الأنماط الأساسية، مما يؤدي إلى ضعف أدائه في كل من بيانات التدريب والاختبار. عادةً ما يتم ملاحظة عدم المطابقة عندما يكون النموذج بسيطًا جدًا بحيث لا يمثل التعقيد الحقيقي للبيانات.
التجهيز الزائد مقابل التجهيز الزائد
في تعلم الآلة، يعد نقص التجهيز وفرط التجهيز من المشكلات الشائعة التي يمكن أن تؤثر سلبًا على قدرة النموذج على عمل تنبؤات دقيقة. يعد فهم الفرق بين الاثنين أمرًا بالغ الأهمية لبناء النماذج التي يمكن تعميمها بشكل جيد على البيانات الجديدة.
- يحدث النقص في المطابقةعندما يكون النموذج بسيطًا جدًا ويفشل في التقاط الأنماط الأساسية في البيانات. وهذا يؤدي إلى تنبؤات غير دقيقة لكل من بيانات التدريب والبيانات الجديدة.
- يحدثالإفراط في التجهيزعندما يصبح النموذج معقدًا للغاية، ولا يناسب الأنماط الحقيقية فحسب، بل أيضًا التشويش الموجود في بيانات التدريب. يؤدي هذا إلى أداء النموذج بشكل جيد في مجموعة التدريب ولكن بشكل سيئ على البيانات الجديدة غير المرئية.
لتوضيح هذه المفاهيم بشكل أفضل، فكر في نموذج يتنبأ بالأداء الرياضي بناءً على مستويات التوتر. تمثل النقاط الزرقاء في المخطط نقاط البيانات من مجموعة التدريب، بينما توضح الخطوط توقعات النموذج بعد تدريبه على تلك البيانات. 
1 عدم التجهيز:في هذه الحالة، يستخدم النموذج خطًا مستقيمًا بسيطًا للتنبؤ بالأداء، على الرغم من أن العلاقة الفعلية منحنية. وبما أن الخط لا يتناسب مع البيانات بشكل جيد، فإن النموذج بسيط للغاية ويفشل في التقاط الأنماط المهمة، مما يؤدي إلى تنبؤات سيئة. وهذا أمر غير مناسب، حيث يفشل النموذج في تعلم الخصائص الأكثر فائدة للبيانات.
2 التوافق الأمثل:هنا، يناسب النموذج منحنى البيانات بشكل مناسب بما فيه الكفاية. فهو يلتقط الاتجاه الأساسي دون أن يكون حساسًا بشكل مفرط لنقاط بيانات محددة أو ضوضاء. هذا هو السيناريو المرغوب، حيث يعمم النموذج بشكل جيد ويمكنه تقديم تنبؤات دقيقة بشأن بيانات جديدة مماثلة. ومع ذلك، لا يزال التعميم يمثل تحديًا عند مواجهة مجموعات بيانات مختلفة إلى حد كبير أو أكثر تعقيدًا.
3 التجهيز الزائد:في سيناريو التجهيز الزائد، يتابع النموذج عن كثب كل نقطة بيانات تقريبًا، بما في ذلك الضوضاء والتقلبات العشوائية في بيانات التدريب. على الرغم من أن النموذج يؤدي أداءً جيدًا للغاية في مجموعة التدريب، إلا أنه محدد جدًا لبيانات التدريب، وبالتالي سيكون أقل فعالية عند التنبؤ بالبيانات الجديدة. إنه يكافح من أجل التعميم ومن المحتمل أن يقدم تنبؤات غير دقيقة عند تطبيقها على سيناريوهات غير مرئية.
الأسباب الشائعة لنقص التجهيز
هناك العديد من الأسباب المحتملة لعدم التجهيز. الأربعة الأكثر شيوعًا هي:
- بنية النموذج بسيطة للغاية.
- اختيار ميزة سيئة
- بيانات التدريب غير كافية
- لا يوجد تدريب كافي
دعونا نتعمق في هذه الأمور قليلاً لفهمها.
بنية النموذج بسيطة للغاية
تشير بنية النموذج إلى مزيج من الخوارزمية المستخدمة لتدريب النموذج وبنية النموذج. إذا كانت البنية بسيطة للغاية، فقد تواجه مشكلة في التقاط الخصائص عالية المستوى لبيانات التدريب، مما يؤدي إلى تنبؤات غير دقيقة.
على سبيل المثال، إذا حاول النموذج استخدام خط مستقيم واحد لنمذجة البيانات التي تتبع نمطًا منحنيًا، فسوف يكون غير مناسب باستمرار. وذلك لأن الخط المستقيم لا يمكن أن يمثل بدقة العلاقة عالية المستوى في البيانات المنحنية، مما يجعل بنية النموذج غير كافية للمهمة.
اختيار ميزة سيئة
يتضمن اختيار الميزة اختيار المتغيرات المناسبة لنموذج ML أثناء التدريب. على سبيل المثال، قد تطلب من خوارزمية تعلم الآلة أن تنظر إلى سنة ميلاد الشخص أو لون عينه أو عمره أو الثلاثة معًا عند التنبؤ بما إذا كان الشخص سيضغط على زر الشراء على موقع التجارة الإلكترونية.
إذا كان هناك عدد كبير جدًا من الميزات، أو إذا كانت الميزات المحددة لا ترتبط بقوة بالمتغير المستهدف، فلن يحتوي النموذج على معلومات كافية ذات صلة لإجراء تنبؤات دقيقة. قد يكون لون العين غير ذي صلة بالتحويل، ويلتقط العمر الكثير من المعلومات نفسها مثل سنة الميلاد.

بيانات التدريب غير كافية
عندما يكون هناك عدد قليل جدًا من نقاط البيانات، قد يكون النموذج غير ملائم لأن البيانات لا تلتقط أهم خصائص المشكلة. يمكن أن يحدث هذا إما بسبب نقص البيانات أو بسبب تحيز أخذ العينات، حيث يتم استبعاد بعض مصادر البيانات أو تمثيلها بشكل ناقص، مما يمنع النموذج من تعلم أنماط مهمة.
لا يوجد تدريب كافي
يتضمن تدريب نموذج تعلم الآلة تعديل معلماته الداخلية (الأوزان) بناءً على الفرق بين توقعاته والنتائج الفعلية. كلما زاد عدد تكرارات التدريب التي يخضع لها النموذج، كلما كان من الأفضل تعديله ليناسب البيانات. إذا تم تدريب النموذج بعدد قليل جدًا من التكرارات، فقد لا يكون لديه فرص كافية للتعلم من البيانات، مما يؤدي إلى عدم المطابقة.
كيفية اكتشاف نقص التجهيز
تتمثل إحدى طرق اكتشاف عدم الملائمة في تحليل منحنيات التعلم، التي ترسم أداء النموذج (عادةً الخسارة أو الخطأ) مقابل عدد تكرارات التدريب. يوضح منحنى التعلم كيف يتحسن النموذج (أو يفشل في التحسن) بمرور الوقت في كل من مجموعات بيانات التدريب والتحقق من الصحة.
الخسارة هي حجم خطأ النموذج لمجموعة معينة من البيانات. يقيس فقدان التدريب ذلك بالنسبة لبيانات التدريب وفقدان التحقق من صحة بيانات التحقق من الصحة. بيانات التحقق من الصحة هي مجموعة بيانات منفصلة تستخدم لاختبار أداء النموذج. يتم إنتاجه عادةً عن طريق التقسيم العشوائي لمجموعة بيانات أكبر إلى بيانات التدريب والتحقق من الصحة.
في حالة عدم التجهيز، ستلاحظ الأنماط الرئيسية التالية:
- خسارة تدريب عالية:إذا ظلت خسارة تدريب النموذج عالية وخطوط ثابتة في وقت مبكر من العملية، فهذا يشير إلى أن النموذج لا يتعلم من بيانات التدريب. وهذه علامة واضحة على عدم الملائمة، حيث أن النموذج بسيط جدًا بحيث لا يمكنه التكيف مع تعقيد البيانات.
- فقدان التدريب والتحقق المماثل:إذا كان كل من فقدان التدريب والتحقق مرتفعًا وظلا قريبين من بعضهما البعض طوال عملية التدريب، فهذا يعني أن أداء النموذج ضعيف في كلتا مجموعتي البيانات. يشير هذا إلى أن النموذج لا يلتقط معلومات كافية من البيانات لإجراء تنبؤات دقيقة، مما يشير إلى عدم المطابقة.
فيما يلي مثال لمخطط يوضح منحنيات التعلم في سيناريو غير مناسب:
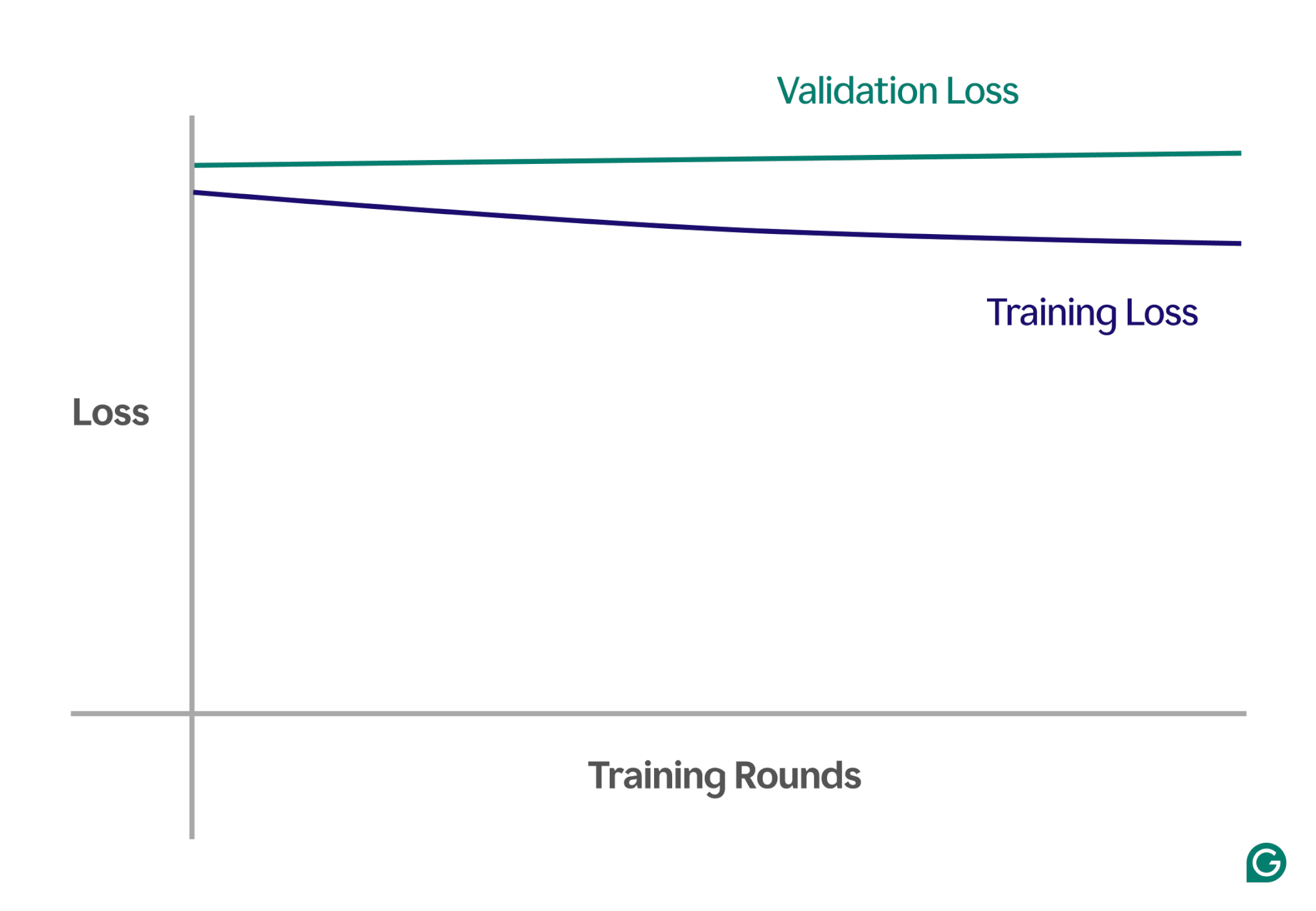
في هذا التمثيل المرئي، من السهل اكتشاف عدم التناسب:
- في النموذج الملائم، تنخفض خسارة التدريب بشكل كبير بينما تتبع خسارة التحقق نمطًا مشابهًا، وتستقر في النهاية.
- في النموذج غير المجهز، يبدأ كل من فقدان التدريب والتحقق من الصحة مرتفعًا ويظل مرتفعًا، دون أي تحسن كبير.
ومن خلال ملاحظة هذه الاتجاهات، يمكنك بسرعة تحديد ما إذا كان النموذج مبسطًا للغاية ويحتاج إلى تعديلات لزيادة تعقيده.
تقنيات لمنع نقص التجهيز
إذا واجهت عدم ملائمة، فهناك العديد من الاستراتيجيات التي يمكنك استخدامها لتحسين أداء النموذج:
- المزيد من بيانات التدريب:احصل على بيانات تدريب إضافية، إن أمكن. المزيد من البيانات يمنح النموذج فرصًا إضافية لتعلم الأنماط، بشرط أن تكون البيانات عالية الجودة وذات صلة بالمشكلة المطروحة.
- توسيع تحديد الميزة:أضف إلى ميزات النموذج الأكثر صلة. اختر الميزات التي لها علاقة قوية بالمتغير المستهدف، مما يمنح النموذج فرصة أفضل لالتقاط الأنماط المهمة التي تم تفويتها سابقًا.
- زيادة القوة المعمارية:في النماذج المعتمدة على الشبكات العصبية، يمكنك ضبط البنية المعمارية عن طريق تغيير عدد الأوزان أو الطبقات أو المعلمات الفائقة الأخرى. يمكن أن يسمح ذلك للنموذج بأن يكون أكثر مرونة ويسهل العثور على الأنماط عالية المستوى في البيانات.
- اختر نموذجًا مختلفًا:في بعض الأحيان، حتى بعد ضبط المعلمات الفائقة، قد لا يكون نموذج معين مناسبًا تمامًا للمهمة. يمكن أن يساعد اختبار خوارزميات النماذج المتعددة في العثور على نموذج أكثر ملاءمة وتحسين الأداء.
أمثلة عملية على نقص التجهيز
لتوضيح تأثيرات عدم المطابقة، دعونا نلقي نظرة على أمثلة من العالم الحقيقي عبر مجالات مختلفة حيث تفشل النماذج في التقاط تعقيد البيانات، مما يؤدي إلى تنبؤات غير دقيقة.
التنبؤ بأسعار المنازل
للتنبؤ بدقة بسعر المنزل، عليك أن تأخذ في الاعتبار العديد من العوامل، بما في ذلك الموقع والحجم ونوع المنزل والحالة وعدد غرف النوم.
إذا كنت تستخدم ميزات قليلة جدًا، مثل حجم المنزل ونوعه فقط، فلن يتمكن النموذج من الوصول إلى المعلومات المهمة. على سبيل المثال، قد يفترض النموذج أن الاستوديو الصغير غير مكلف، دون أن يعرف أنه يقع في مايفير، لندن، وهي منطقة ذات أسعار عقارات مرتفعة. وهذا يؤدي إلى توقعات سيئة.
لحل هذه المشكلة، يجب على علماء البيانات التأكد من اختيار الميزات المناسبة. يتضمن ذلك تضمين جميع الميزات ذات الصلة، باستثناء الميزات غير ذات الصلة، واستخدام بيانات التدريب الدقيقة.
التعرف على الكلام
أصبحت تقنية التعرف على الصوت شائعة بشكل متزايد في الحياة اليومية. على سبيل المثال، يستخدم مساعدو الهواتف الذكية وخطوط مساعدة خدمة العملاء والتكنولوجيا المساعدة للأشخاص ذوي الإعاقة التعرف على الكلام. عند تدريب هذه النماذج، يتم استخدام البيانات من عينات الكلام وتفسيراتها الصحيحة.
وللتعرف على الكلام، يقوم النموذج بتحويل الموجات الصوتية الملتقطة بواسطة الميكروفون إلى بيانات. إذا قمنا بتبسيط ذلك من خلال توفير التردد السائد وحجم الصوت فقط على فترات زمنية محددة، فإننا نقوم بتقليل كمية البيانات التي يجب على النموذج معالجتها.
ومع ذلك، فإن هذا النهج يجرد المعلومات الأساسية اللازمة لفهم الخطاب بشكل كامل. تصبح البيانات مبسطة جدًا بحيث لا يمكنها التقاط مدى تعقيد الكلام البشري، مثل الاختلافات في النغمة وطبقة الصوت واللهجة.
ونتيجة لذلك، فإن النموذج لن يكون مناسبًا، وسيواجه صعوبة في التعرف حتى على أوامر الكلمات الأساسية، ناهيك عن إكمال الجمل. وحتى لو كان النموذج معقدًا بما فيه الكفاية، فإن الافتقار إلى بيانات شاملة يؤدي إلى عدم ملائمة النموذج.
تصنيف الصور
تم تصميم مصنف الصور لالتقاط صورة كمدخل وإخراج كلمة لوصفها. لنفترض أنك تقوم ببناء نموذج لاكتشاف ما إذا كانت الصورة تحتوي على كرة أم لا. يمكنك تدريب النموذج باستخدام صور محددة للكرات والأشياء الأخرى.
إذا استخدمت عن طريق الخطأ شبكة عصبية بسيطة مكونة من طبقتين بدلاً من نموذج أكثر ملاءمة مثل الشبكة العصبية التلافيفية (CNN)، فسوف يواجه النموذج صعوبات. تقوم الشبكة المكونة من طبقتين بتسوية الصورة إلى طبقة واحدة، مما يؤدي إلى فقدان المعلومات المكانية المهمة. بالإضافة إلى ذلك، مع طبقتين فقط، يفتقر النموذج إلى القدرة على تحديد الميزات المعقدة.
يؤدي هذا إلى عدم المطابقة، حيث سيفشل النموذج في تقديم تنبؤات دقيقة، حتى على بيانات التدريب. تعمل شبكات CNN على حل هذه المشكلة من خلال الحفاظ على البنية المكانية للصور واستخدام الطبقات التلافيفية مع المرشحات التي تتعلم تلقائيًا اكتشاف الميزات المهمة مثل الحواف والأشكال في الطبقات المبكرة والكائنات الأكثر تعقيدًا في الطبقات اللاحقة.