
Grundlagen generativer gegnerischer Netzwerke: Was Sie wissen müssen
Veröffentlicht: 2024-10-08Generative Adversarial Networks (GANs) sind ein leistungsstarkes Werkzeug der künstlichen Intelligenz (KI) mit zahlreichen Anwendungen im maschinellen Lernen (ML). In diesem Leitfaden werden GANs, ihre Funktionsweise, ihre Anwendungen sowie ihre Vor- und Nachteile untersucht.
Inhaltsverzeichnis
- Was ist ein GAN?
- GANs vs. CNNs
- Wie GANs funktionieren
- Arten von GANs
- Anwendungen von GANs
- Vorteile von GANs
- Nachteile von GANs
Was ist ein generatives kontradiktorisches Netzwerk?
Ein generatives kontradiktorisches Netzwerk oder GAN ist eine Art Deep-Learning-Modell, das typischerweise beim unbeaufsichtigten maschinellen Lernen verwendet wird, aber auch für halbüberwachtes und überwachtes Lernen anpassbar ist. GANs werden verwendet, um qualitativ hochwertige Daten ähnlich dem Trainingsdatensatz zu generieren. Als Teilmenge der generativen KI bestehen GANs aus zwei Untermodellen: dem Generator und dem Diskriminator.
1 Generator:Der Generator erstellt synthetische Daten.
2 Diskriminator:Der Diskriminator wertet die Ausgabe des Generators aus und unterscheidet zwischen echten Daten aus dem Trainingssatz und synthetischen Daten, die vom Generator erstellt wurden.
Die beiden Modelle konkurrieren miteinander: Der Generator versucht, den Diskriminator dazu zu bringen, generierte Daten als real zu klassifizieren, während der Diskriminator seine Fähigkeit, synthetische Daten zu erkennen, kontinuierlich verbessert. Dieser kontradiktorische Prozess dauert an, bis der Diskriminator nicht mehr zwischen realen und generierten Daten unterscheiden kann. An diesem Punkt ist das GAN in der Lage, realistische Bilder, Videos und andere Arten von Daten zu generieren.
GANs vs. CNNs
GANs und Convolutional Neural Networks (CNNs) sind leistungsstarke Arten neuronaler Netzwerke, die beim Deep Learning verwendet werden, sie unterscheiden sich jedoch erheblich in Bezug auf Anwendungsfälle und Architektur.
Anwendungsfälle
- GANs:Spezialisiert auf die Generierung realistischer synthetischer Daten basierend auf Trainingsdaten. Dadurch eignen sich GANs gut für Aufgaben wie Bildgenerierung, Bildstilübertragung und Datenerweiterung. GANs sind unbeaufsichtigt, was bedeutet, dass sie auf Szenarien angewendet werden können, in denen gekennzeichnete Daten knapp oder nicht verfügbar sind.
- CNNs:Wird hauptsächlich für strukturierte Datenklassifizierungsaufgaben wie Stimmungsanalyse, Themenkategorisierung und Sprachübersetzung verwendet. Aufgrund ihrer Klassifizierungsfähigkeiten dienen CNNs auch als gute Diskriminatoren in GANs. Da CNNs jedoch strukturierte, von Menschen kommentierte Trainingsdaten erfordern, sind sie auf überwachte Lernszenarien beschränkt.
Architektur
- GANs:Bestehen aus zwei Modellen – einem Diskriminator und einem Generator –, die an einem Wettbewerbsprozess teilnehmen. Der Generator erstellt Bilder, während der Diskriminator sie auswertet und den Generator dazu drängt, mit der Zeit immer realistischere Bilder zu erzeugen.
- CNNs:Nutzen Sie Schichten von Faltungs- und Pooling-Operationen, um Merkmale aus Bildern zu extrahieren und zu analysieren. Diese Einzelmodellarchitektur konzentriert sich auf das Erkennen von Mustern und Strukturen innerhalb der Daten.
Während sich CNNs insgesamt auf die Analyse bestehender strukturierter Daten konzentrieren, sind GANs auf die Erstellung neuer, realistischer Daten ausgerichtet.
Wie GANs funktionieren
Auf einer hohen Ebene funktioniert ein GAN, indem es zwei neuronale Netze – den Generator und den Diskriminator – gegeneinander antreten lässt. GANs erfordern für keine ihrer beiden Komponenten eine bestimmte Art neuronaler Netzwerkarchitektur, solange die ausgewählten Architekturen einander ergänzen. Wenn beispielsweise ein CNN als Diskriminator für die Bilderzeugung verwendet wird, könnte der Generator ein dekonvolutionelles neuronales Netzwerk (deCNN) sein, das den CNN-Prozess in umgekehrter Reihenfolge durchführt. Jede Komponente hat ein anderes Ziel:
- Generator:Um Daten von so hoher Qualität zu erzeugen, dass der Diskriminator sie als real einstufen kann.
- Diskriminator:Um eine bestimmte Datenprobe genau als echt (aus dem Trainingsdatensatz) oder gefälscht (vom Generator generiert) zu klassifizieren.
Dieser Wettbewerb ist eine Umsetzung eines Nullsummenspiels, bei dem eine Belohnung für ein Modell auch eine Strafe für das andere Modell darstellt. Für den Generator führt die erfolgreiche Täuschung des Diskriminators zu einer Modellaktualisierung, die seine Fähigkeit zur Generierung realistischer Daten verbessert. Wenn der Diskriminator umgekehrt gefälschte Daten korrekt identifiziert, erhält er ein Update, das seine Erkennungsfähigkeiten verbessert. Mathematisch gesehen zielt der Diskriminator darauf ab, den Klassifizierungsfehler zu minimieren, während der Generator darauf abzielt, ihn zu maximieren.
Der GAN-Trainingsprozess
Beim Training von GANs wird über mehrere Epochen hinweg zwischen Generator und Diskriminator gewechselt. Epochen sind vollständige Trainingsläufe über den gesamten Datensatz. Dieser Prozess wird fortgesetzt, bis der Generator synthetische Daten erzeugt, die den Diskriminator in etwa 50 % der Fälle täuschen. Während beide Modelle ähnliche Algorithmen zur Leistungsbewertung und -verbesserung verwenden, erfolgen ihre Aktualisierungen unabhängig voneinander. Diese Aktualisierungen werden mit einer Methode namens Backpropagation durchgeführt, die den Fehler jedes Modells misst und Parameter anpasst, um die Leistung zu verbessern. Ein Optimierungsalgorithmus passt dann die Parameter jedes Modells unabhängig an.
Hier ist eine visuelle Darstellung der GAN-Architektur, die den Wettbewerb zwischen Generator und Diskriminator veranschaulicht:
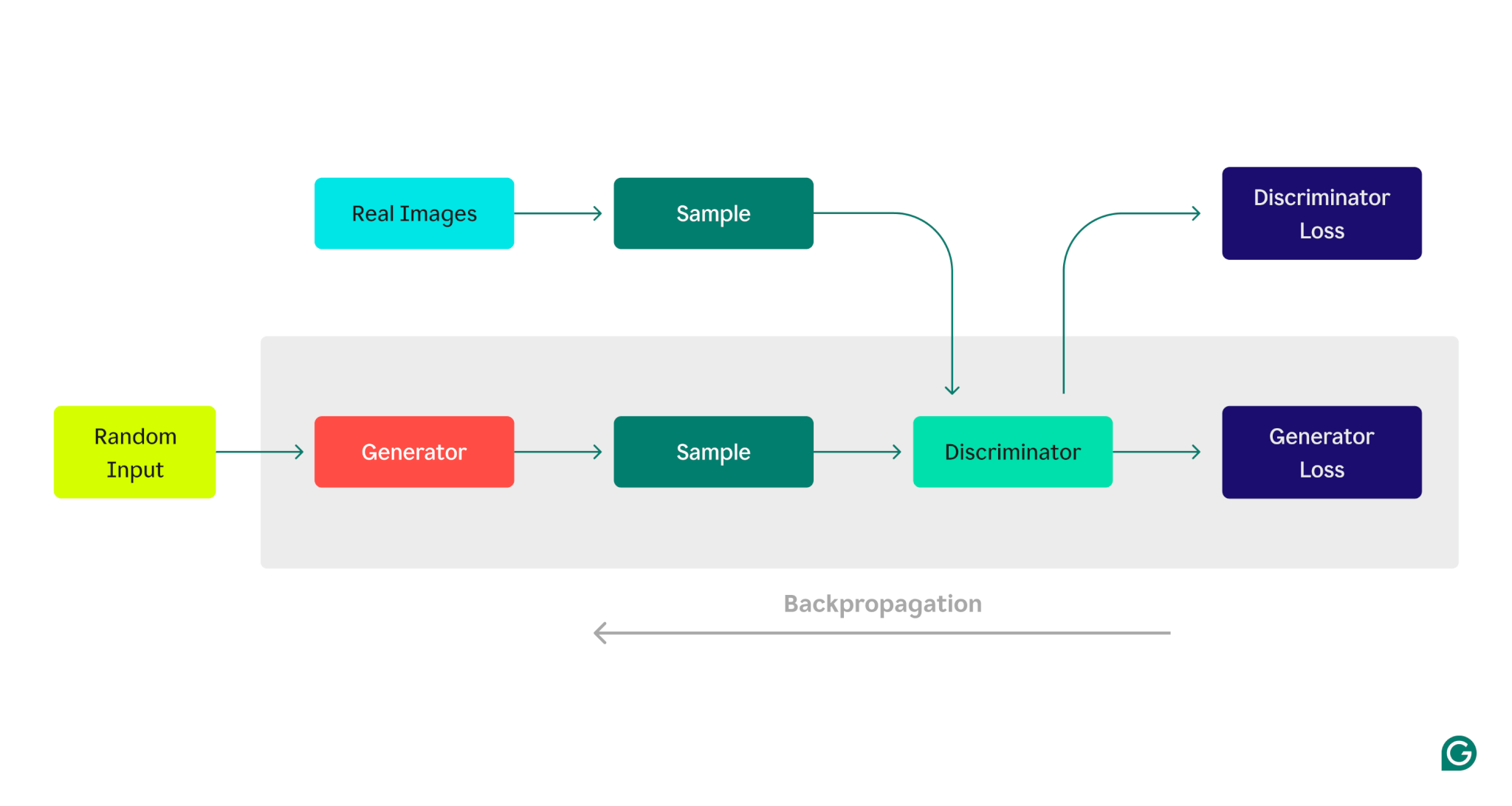
Generator-Trainingsphase:
1 Der Generator erstellt Datenbeispiele, typischerweise beginnend mit zufälligem Rauschen als Eingabe.
2 Der Diskriminator klassifiziert diese Proben als echt (aus dem Trainingsdatensatz) oder gefälscht (vom Generator generiert).
3 Basierend auf der Antwort des Diskriminators werden die Generatorparameter mithilfe von Backpropagation aktualisiert.
Trainingsphase des Diskriminators:
1 Fake-Daten werden anhand des aktuellen Status des Generators generiert.
2 Die generierten Proben werden dem Diskriminator zusammen mit Proben aus dem Trainingsdatensatz bereitgestellt.
3 Mithilfe der Backpropagation werden die Parameter des Diskriminators basierend auf seiner Klassifizierungsleistung aktualisiert.
Dieser iterative Trainingsprozess wird fortgesetzt, wobei die Parameter jedes Modells basierend auf seiner Leistung angepasst werden, bis der Generator konsistent Daten erzeugt, die der Diskriminator nicht zuverlässig von realen Daten unterscheiden kann.
Arten von GANs
Aufbauend auf der grundlegenden GAN-Architektur, die oft als Vanilla-GAN bezeichnet wird, wurden andere spezialisierte Arten von GANs entwickelt und für verschiedene Aufgaben optimiert. Nachfolgend werden einige der gängigsten Varianten beschrieben, die Liste erhebt jedoch keinen Anspruch auf Vollständigkeit:
Bedingtes GAN (cGAN)
Bedingte GANs oder cGANs verwenden zusätzliche Informationen, sogenannte Bedingungen, um das Modell bei der Generierung bestimmter Datentypen beim Training an einem allgemeineren Datensatz zu unterstützen. Eine Bedingung kann eine Klassenbezeichnung, eine textbasierte Beschreibung oder eine andere Art von Klassifizierungsinformationen für die Daten sein. Stellen Sie sich beispielsweise vor, dass Sie nur Bilder von Siamkatzen generieren müssen, Ihr Trainingsdatensatz jedoch Bilder von allen Arten von Katzen enthält. In einem cGAN könnten Sie Trainingsbilder mit der Art der Katze kennzeichnen und das Modell könnte damit lernen, nur Bilder von Siamkatzen zu generieren.

Tiefes Faltungs-GAN (DCGAN)
Ein Deep Convolutional GAN oder DCGAN ist für die Bilderzeugung optimiert. In einem DCGAN ist der Generator ein Deep Embedding Convolutional Neural Network (deCNN) und der Diskriminator ist ein Deep CNN. CNNs eignen sich aufgrund ihrer Fähigkeit, räumliche Hierarchien und Muster zu erfassen, besser für die Arbeit mit und die Generierung von Bildern. Der Generator in einem DCGAN verwendet Upsampling und transponierte Faltungsschichten, um Bilder mit höherer Qualität zu erzeugen, als ein mehrschichtiges Perzeptron (ein einfaches neuronales Netzwerk, das Entscheidungen durch Gewichtung von Eingabemerkmalen trifft) erzeugen könnte. In ähnlicher Weise verwendet der Diskriminator Faltungsschichten, um Merkmale aus den Bildproben zu extrahieren und sie genau als echt oder gefälscht zu klassifizieren.
CycleGAN
CycleGAN ist ein GAN-Typ, der dazu dient, einen Bildtyp aus einem anderen zu generieren. Beispielsweise kann ein CycleGAN das Bild einer Maus in eine Ratte oder eines Hundes in einen Kojoten umwandeln. CycleGANs sind in der Lage, diese Bild-zu-Bild-Übersetzung ohne Training an gepaarten Datensätzen durchzuführen, d. h. Datensätzen, die sowohl das Basisbild als auch die gewünschte Transformation enthalten. Diese Fähigkeit wird durch die Verwendung von zwei Generatoren und zwei Diskriminatoren anstelle des einzelnen Paares erreicht, das ein Vanilla-GAN verwendet. In CycleGAN konvertiert ein Generator Bilder vom Basisbild in die transformierte Version, während der andere Generator eine Konvertierung in die entgegengesetzte Richtung durchführt. Ebenso prüft jeder Diskriminator einen bestimmten Bildtyp, um festzustellen, ob er echt oder gefälscht ist. CycleGAN verwendet dann eine Konsistenzprüfung, um sicherzustellen, dass die Konvertierung eines Bildes in den anderen Stil und zurück zum Originalbild führt.
Anwendungen von GANs
Aufgrund ihrer besonderen Architektur wurden GANs in einer Reihe innovativer Anwendungsfälle eingesetzt, ihre Leistung hängt jedoch stark von spezifischen Aufgaben und der Datenqualität ab. Zu den leistungsstärkeren Anwendungen gehören die Text-zu-Bild-Generierung, die Datenerweiterung sowie die Videogenerierung und -bearbeitung.
Text-zu-Bild-Generierung
GANs können Bilder aus einer Textbeschreibung generieren. Diese Anwendung ist in der Kreativbranche wertvoll und ermöglicht es Autoren und Designern, die im Text beschriebenen Szenen und Charaktere zu visualisieren. Während für solche Aufgaben häufig GANs verwendet werden, verwenden andere generative KI-Modelle wie DALL-E von OpenAI transformatorbasierte Architekturen, um ähnliche Ergebnisse zu erzielen.
Datenerweiterung
GANs sind für die Datenerweiterung nützlich, da sie synthetische Daten generieren können, die echten Trainingsdaten ähneln, obwohl der Grad der Genauigkeit und des Realismus je nach spezifischem Anwendungsfall und Modelltraining variieren kann. Diese Fähigkeit ist beim maschinellen Lernen besonders wertvoll, um begrenzte Datensätze zu erweitern und die Modellleistung zu verbessern. Darüber hinaus bieten GANs eine Lösung zur Wahrung des Datenschutzes. In sensiblen Bereichen wie dem Gesundheitswesen und dem Finanzwesen können GANs synthetische Daten erzeugen, die die statistischen Eigenschaften des Originaldatensatzes bewahren, ohne sensible Informationen zu gefährden.
Videogenerierung und -manipulation
GANs haben sich bei bestimmten Videogenerierungs- und -manipulationsaufgaben als vielversprechend erwiesen. Beispielsweise können GANs verwendet werden, um zukünftige Frames aus einer ersten Videosequenz zu generieren, was bei Anwendungen wie der Vorhersage von Fußgängerbewegungen oder der Vorhersage von Straßengefahren für autonome Fahrzeuge hilfreich ist. Diese Anwendungen befinden sich jedoch noch in der aktiven Forschung und Entwicklung. Mit GANs lassen sich auch komplett synthetische Videoinhalte generieren und Videos mit realistischen Spezialeffekten aufwerten.
Vorteile von GANs
GANs bieten mehrere entscheidende Vorteile, darunter die Möglichkeit, realistische synthetische Daten zu generieren, aus ungepaarten Daten zu lernen und unbeaufsichtigtes Training durchzuführen.
Hochwertige synthetische Datengenerierung
Die Architektur von GANs ermöglicht es ihnen, synthetische Daten zu erzeugen, die reale Daten in Anwendungen wie Datenerweiterung und Videoerstellung annähern können, obwohl die Qualität und Präzision dieser Daten stark von den Trainingsbedingungen und Modellparametern abhängen kann. Beispielsweise zeichnen sich DCGANs, die CNNs für eine optimale Bildverarbeitung nutzen, durch die Erzeugung realistischer Bilder aus.
Kann aus ungepaarten Daten lernen
Im Gegensatz zu einigen ML-Modellen können GANs aus Datensätzen ohne gepaarte Beispiele von Ein- und Ausgaben lernen. Diese Flexibilität ermöglicht den Einsatz von GANs in einem breiten Spektrum von Aufgaben, bei denen gepaarte Daten knapp oder nicht verfügbar sind. Beispielsweise benötigen herkömmliche Modelle bei Bild-zu-Bild-Übersetzungsaufgaben häufig einen Datensatz mit Bildern und deren Transformationen für das Training. Im Gegensatz dazu können GANs eine größere Vielfalt potenzieller Datensätze für das Training nutzen.
Unbeaufsichtigtes Lernen
GANs sind eine unbeaufsichtigte Methode des maschinellen Lernens, was bedeutet, dass sie ohne explizite Anweisung auf unbeschriftete Daten trainiert werden können. Dies ist besonders vorteilhaft, da die Kennzeichnung von Daten ein zeitaufwändiger und kostspieliger Prozess ist. Die Fähigkeit von GANs, aus unbeschrifteten Daten zu lernen, macht sie für Anwendungen wertvoll, bei denen beschriftete Daten begrenzt oder schwer zu erhalten sind. GANs können auch für halbüberwachtes und überwachtes Lernen angepasst werden, sodass sie auch gekennzeichnete Daten verwenden können.
Nachteile von GANs
Während GANs ein leistungsstarkes Werkzeug beim maschinellen Lernen sind, bringt ihre Architektur eine Reihe einzigartiger Nachteile mit sich. Zu diesen Nachteilen gehören die Empfindlichkeit gegenüber Hyperparametern, hohe Rechenkosten, Konvergenzfehler und ein Phänomen, das als Modenkollaps bezeichnet wird.
Hyperparameter-Empfindlichkeit
GANs reagieren empfindlich auf Hyperparameter, bei denen es sich um Parameter handelt, die vor dem Training festgelegt und nicht aus den Daten gelernt werden. Beispiele hierfür sind Netzwerkarchitekturen und die Anzahl der in einer einzelnen Iteration verwendeten Trainingsbeispiele. Kleine Änderungen dieser Parameter können den Trainingsprozess und die Modellergebnisse erheblich beeinflussen und erfordern eine umfangreiche Feinabstimmung für praktische Anwendungen.
Hoher Rechenaufwand
Aufgrund ihrer komplexen Architektur, des iterativen Trainingsprozesses und der Empfindlichkeit gegenüber Hyperparametern verursachen GANs häufig hohe Rechenkosten. Das erfolgreiche Training eines GAN erfordert spezielle und teure Hardware sowie viel Zeit, was für viele Organisationen, die GANs nutzen möchten, ein Hindernis darstellen kann.
Konvergenzfehler
Ingenieure und Forscher können viel Zeit damit verbringen, mit Trainingskonfigurationen zu experimentieren, bevor sie eine akzeptable Rate erreichen, mit der die Modellausgabe stabil und genau wird, die sogenannte Konvergenzrate. Konvergenz in GANs kann sehr schwierig zu erreichen sein und möglicherweise nicht sehr lange anhalten. Von einem Konvergenzfehler spricht man, wenn der Diskriminator nicht hinreichend zwischen echten und gefälschten Daten unterscheiden kann, was zu einer Genauigkeit von etwa 50 % führt, weil er nicht in der Lage ist, echte Daten zu identifizieren, im Gegensatz zu dem angestrebten Gleichgewicht, das während des erfolgreichen Trainings erreicht wurde. Einige GANs erreichen möglicherweise nie die Konvergenz und erfordern möglicherweise eine spezielle Analyse zur Reparatur.
Moduszusammenbruch
GANs sind anfällig für ein Problem namens Mode Collapse, bei dem der Generator eine begrenzte Auswahl an Ausgaben erzeugt und die Vielfalt der realen Datenverteilungen nicht widerspiegelt. Dieses Problem ergibt sich aus der GAN-Architektur, da sich der Generator zu sehr auf die Erzeugung von Daten konzentriert, die den Diskriminator täuschen und ihn dazu verleiten können, ähnliche Beispiele zu generieren.