
Was ist ein neuronales Netzwerk?
Veröffentlicht: 2024-06-26Was ist ein neuronales Netzwerk?
Ein neuronales Netzwerk ist eine Art Deep-Learning-Modell im weiteren Bereich des maschinellen Lernens (ML), das das menschliche Gehirn simuliert. Es verarbeitet Daten über miteinander verbundene Knoten oder Neuronen, die in Schichten angeordnet sind – Eingabe, verborgen und Ausgabe. Jeder Knoten führt einfache Berechnungen durch und trägt so zur Fähigkeit des Modells bei, Muster zu erkennen und Vorhersagen zu treffen.
Deep-Learning-Neuronale Netze sind besonders effektiv bei der Bewältigung komplexer Aufgaben wie der Bild- und Spracherkennung und bilden einen entscheidenden Bestandteil vieler KI-Anwendungen. Jüngste Fortschritte bei neuronalen Netzwerkarchitekturen und Trainingstechniken haben die Fähigkeiten von KI-Systemen erheblich verbessert.
Wie neuronale Netze aufgebaut sind
Wie der Name schon sagt, ist ein neuronales Netzwerkmodell von Neuronen, den Bausteinen des Gehirns, inspiriert. Erwachsene Menschen verfügen über etwa 85 Milliarden Neuronen, von denen jedes mit etwa 1.000 anderen verbunden ist. Eine Gehirnzelle kommuniziert mit einer anderen, indem sie Chemikalien, sogenannte Neurotransmitter, sendet. Wenn die empfangende Zelle genug von diesen Chemikalien erhält, wird sie erregt und sendet ihre eigenen Chemikalien an eine andere Zelle.
Die Grundeinheit dessen, was manchmal als künstliches neuronales Netzwerk (KNN) bezeichnet wird, ist einKnoten, der keine Zelle, sondern eine mathematische Funktion ist. Genau wie Neuronen kommunizieren sie mit anderen Knoten, wenn sie genügend Input erhalten.
Das ist ungefähr das Ende der Ähnlichkeiten. Neuronale Netze sind viel einfacher strukturiert als das Gehirn und verfügen über klar definierte Schichten: Eingabe, Versteckt und Ausgabe. Eine Sammlung dieser Schichten wird alsModell bezeichnet.Sie lernen odertrainieren, indem sie wiederholt versuchen, künstlich Ergebnisse zu erzeugen, die den gewünschten Ergebnissen am ähnlichsten sind. (Mehr dazu gleich.)
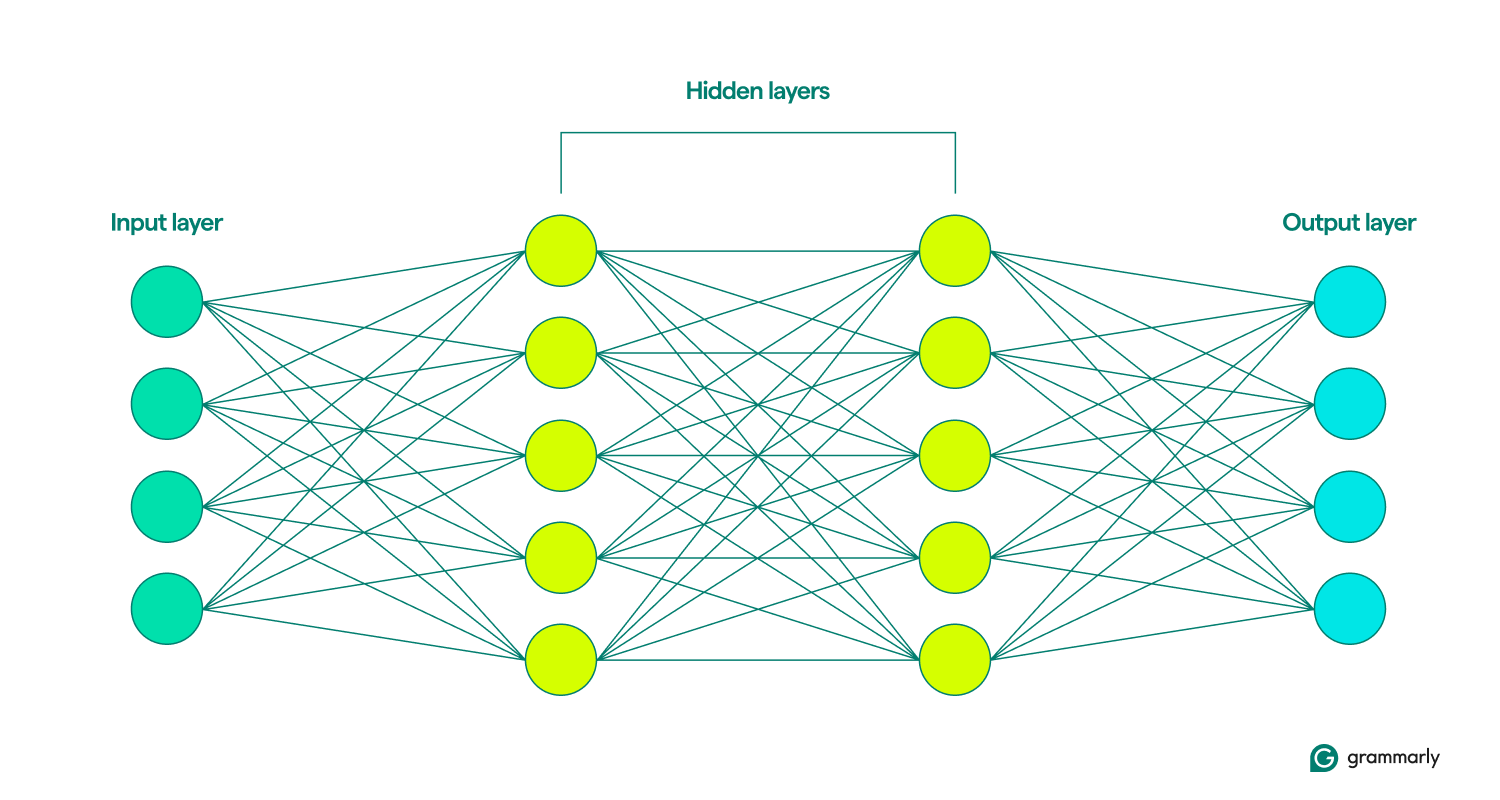
Die Eingabe- und Ausgabeebenen sind ziemlich selbsterklärend. Das meiste, was neuronale Netze tun, findet in den verborgenen Schichten statt. Wenn ein Knoten durch Eingaben aus einer vorherigen Ebene aktiviert wird, führt er seine Berechnungen durch und entscheidet, ob die Ausgabe an die Knoten in der nächsten Ebene weitergeleitet wird. Diese Schichten werden so genannt, weil ihre Vorgänge für den Endbenutzer unsichtbar sind. Allerdings gibt es Techniken, mit denen Ingenieure sehen können, was in den sogenannten verborgenen Schichten passiert.
Wenn neuronale Netze mehrere verborgene Schichten umfassen, werden sie als Deep-Learning-Netze bezeichnet. Moderne tiefe neuronale Netze bestehen normalerweise aus vielen Schichten, einschließlich spezialisierter Unterschichten, die unterschiedliche Funktionen ausführen. Einige Unterschichten verbessern beispielsweise die Fähigkeit des Netzwerks, kontextbezogene Informationen zu berücksichtigen, die über die unmittelbare Eingabe hinausgehen, die analysiert wird.
Wie neuronale Netze funktionieren
Denken Sie darüber nach, wie Babys lernen. Sie versuchen etwas, scheitern und versuchen es erneut auf eine andere Art und Weise. Die Schleife wird so lange fortgesetzt, bis das Verhalten perfektioniert ist. So lernen auch neuronale Netze mehr oder weniger.
Gleich zu Beginn ihres Trainings stellen neuronale Netze zufällige Vermutungen an. Ein Knoten auf der Eingabeschicht entscheidet zufällig, welcher der Knoten in der ersten verborgenen Schicht aktiviert werden soll, und dann aktivieren diese Knoten zufällig Knoten in der nächsten Schicht und so weiter, bis dieser zufällige Prozess die Ausgabeschicht erreicht. (Große Sprachmodelle wie GPT-4 haben etwa 100 Schichten mit Zehn- oder Hunderttausenden Knoten in jeder Schicht.)
Unter Berücksichtigung aller Zufälligkeiten vergleicht das Modell seine Ausgabe – die wahrscheinlich schrecklich ist – und findet heraus, wie falsch sie war. Anschließend passt es die Verbindung jedes Knotens zu anderen Knoten an und ändert, wie wahrscheinlich die Aktivierung auf der Grundlage einer bestimmten Eingabe ist. Dies wird wiederholt durchgeführt, bis die Ergebnisse den gewünschten Antworten möglichst nahe kommen.
Woher wissen neuronale Netze also, was sie tun sollen? Maschinelles Lernen (ML) kann in verschiedene Ansätze unterteilt werden, darunter überwachtes und unüberwachtes Lernen. Beim überwachten Lernen wird das Modell anhand von Daten trainiert, die explizite Bezeichnungen oder Antworten enthalten, beispielsweise Bilder gepaart mit beschreibendem Text. Beim unüberwachten Lernen wird das Modell jedoch mit unbeschrifteten Daten versorgt, die es ihm ermöglichen, Muster und Zusammenhänge selbstständig zu erkennen.
Eine übliche Ergänzung zu diesem Training ist das Reinforcement Learning, bei dem sich das Modell als Reaktion auf Feedback verbessert. Dies wird häufig von menschlichen Bewertern bereitgestellt (wenn Sie jemals mit dem Daumen nach oben oder dem Daumen nach unten auf den Vorschlag eines Computers geklickt haben, haben Sie zum verstärkenden Lernen beigetragen). Dennoch gibt es auch Möglichkeiten für Modelle, iterativ unabhängig zu lernen.
Es ist genau und aufschlussreich, sich die Ausgabe eines neuronalen Netzwerks als Vorhersage vorzustellen. Ganz gleich, ob es um die Beurteilung der Kreditwürdigkeit oder die Generierung eines Songs geht: KI-Modelle funktionieren, indem sie erraten, was am wahrscheinlichsten richtig ist. Generative KI wie ChatGPT geht bei der Vorhersage noch einen Schritt weiter. Es arbeitet sequentiell und macht Vermutungen darüber, was nach der gerade gemachten Ausgabe kommen soll. (Wir werden später darauf eingehen, warum dies problematisch sein kann.)
Wie neuronale Netze Antworten generieren
Wie verarbeitet ein Netzwerk nach dem Training die angezeigten Informationen, um die richtige Reaktion vorherzusagen? Wie entscheidet ChatGPT, wie reagiert wird, wenn Sie eine Aufforderung wie „Erzähl mir eine Geschichte über Feen“ in die ChatGPT-Benutzeroberfläche eingeben?
Der erste Schritt besteht darin, dass die Eingabeschicht des neuronalen Netzwerks Ihre Eingabeaufforderung in kleine Informationsblöcke, sogenannteToken, aufteilt. Bei einem Bilderkennungsnetzwerk könnten Token Pixel sein. Für ein Netzwerk, das Natural Language Processing (NLP) nutzt, wie ChatGPT, ist ein Token typischerweise ein Wort, ein Teil eines Wortes oder eine sehr kurze Phrase.
Sobald das Netzwerk die Token in der Eingabe registriert hat, werden diese Informationen durch die zuvor trainierten verborgenen Schichten weitergeleitet. Die Knoten, die von einer Ebene zur nächsten weitergegeben werden, analysieren immer größere Abschnitte der Eingabe. Auf diese Weise kann ein NLP-Netzwerk schließlich einen ganzen Satz oder Absatz interpretieren, nicht nur ein Wort oder einen Buchstaben.
Jetzt kann das Netzwerk damit beginnen, seine Reaktion zu formulieren. Dabei handelt es sich um eine Reihe von Wort-für-Wort-Vorhersagen darüber, was als Nächstes passieren würde, basierend auf allem, worauf es trainiert wurde.
Denken Sie an die Aufforderung „Erzähl mir eine Geschichte über Feen.“ Um eine Antwort zu generieren, analysiert das neuronale Netzwerk die Aufforderung, um das wahrscheinlichste erste Wort vorherzusagen. Es könnte beispielsweise ermittelt werden, dass eine Wahrscheinlichkeit von 80 % besteht, dass „The“ die beste Wahl ist, eine Chance von 10 % für „A“ und eine Wahrscheinlichkeit von 10 % für „Once“. Anschließend wählt es zufällig eine Zahl aus: Wenn die Zahl zwischen 1 und 8 liegt, wählt es „The“; wenn es 9 ist, wählt es „A“; und wenn es 10 ist, wählt es „Einmal“. Angenommen, die Zufallszahl ist 4, was „The“ entspricht. Das Netzwerk aktualisiert dann die Aufforderung zu „Erzähl mir eine Geschichte über Feen.“ „The“ und wiederholt den Vorgang, um das nächste Wort nach „The“ vorherzusagen. Dieser Zyklus wird mit jeder neuen Wortvorhersage basierend auf der aktualisierten Eingabeaufforderung fortgesetzt, bis eine vollständige Geschichte generiert ist.
Verschiedene Netzwerke werden diese Vorhersage unterschiedlich treffen. Beispielsweise könnte ein Bilderkennungsmodell versuchen, vorherzusagen, welche Bezeichnung einem Bild eines Hundes zu geben ist, und feststellen, dass die Wahrscheinlichkeit, dass die richtige Bezeichnung „Schokoladenlabor“ ist, bei 70 % liegt, bei 20 % für „Englischer Spaniel“ und bei 10 %. für „Golden Retriever“. Bei der Klassifizierung wählt das Netzwerk im Allgemeinen eher die wahrscheinlichste Wahl als eine probabilistische Vermutung.
Arten neuronaler Netze
Hier finden Sie einen Überblick über die verschiedenen Arten neuronaler Netze und ihre Funktionsweise.
- Feedforward Neural Networks (FNNs): In diesen Modellen fließen Informationen in eine Richtung: von der Eingabeschicht über die verborgenen Schichten und schließlich zur Ausgabeschicht.Dieser Modelltyp eignet sich am besten für einfachere Vorhersageaufgaben, beispielsweise die Erkennung von Kreditkartenbetrug.
- Rekurrente neuronale Netze (RNNs): Im Gegensatz zu FNNs berücksichtigen RNNs bei der Erstellung einer Vorhersage frühere Eingaben.Dadurch eignen sie sich gut für Sprachverarbeitungsaufgaben, da das Ende eines Satzes, der als Reaktion auf eine Eingabeaufforderung generiert wird, davon abhängt, wie der Satz begonnen hat.
- Lange Kurzzeitgedächtnisnetzwerke (LSTMs): LSTMs vergessen selektiv Informationen, wodurch sie effizienter arbeiten können.Dies ist für die Verarbeitung großer Textmengen von entscheidender Bedeutung. Beispielsweise basierte das Upgrade von Google Translate auf neuronale maschinelle Übersetzung im Jahr 2016 auf LSTMs.
- Convolutional Neural Networks (CNNs): CNNs funktionieren am besten bei der Verarbeitung von Bildern.Sie verwendenFaltungsschichten,um das gesamte Bild zu scannen und nach Merkmalen wie Linien oder Formen zu suchen. Dies ermöglicht es CNNs, den räumlichen Standort zu berücksichtigen, z. B. festzustellen, ob sich ein Objekt in der oberen oder unteren Hälfte des Bildes befindet, und auch eine Form oder einen Objekttyp unabhängig von seinem Standort zu identifizieren.
- Generative Adversarial Networks (GANs): GANs werden häufig verwendet, um neue Bilder basierend auf einer Beschreibung oder einem vorhandenen Bild zu generieren.Sie sind als Wettbewerb zwischen zwei neuronalen Netzen aufgebaut: einemGeneratornetz, das versucht, einemDiskriminatornetzvorzutäuschen, dass eine gefälschte Eingabe echt sei.
- Transformers und Aufmerksamkeitsnetzwerke: Transformers sind für die aktuelle Explosion der KI-Fähigkeiten verantwortlich.Diese Modelle verfügen über einen Aufmerksamkeitsscheinwerfer, der es ihnen ermöglicht, ihre Eingaben zu filtern, um sich auf die wichtigsten Elemente und die Beziehung dieser Elemente zueinander zu konzentrieren, selbst über Textseiten hinweg. Transformer können auch auf riesigen Datenmengen trainieren, daher werden Modelle wie ChatGPT und Gemini alsLarge Language Models (LLMs)bezeichnet.
Anwendungen neuronaler Netze
Es gibt viel zu viele, um sie alle aufzuzählen. Deshalb finden Sie hier eine Auswahl an Möglichkeiten, wie neuronale Netze heute verwendet werden, mit Schwerpunkt auf natürlicher Sprache.

Schreibhilfe: Transformers haben die Art und Weise verändert, wie Computer Menschen dabei helfen können, besser zu schreiben.KI-Schreibtools wie Grammarly bieten Umschreibungen auf Satz- und Absatzebene, um den Ton und die Klarheit zu verbessern. Dieser Modelltyp hat auch die Geschwindigkeit und Genauigkeit grundlegender grammatikalischer Vorschläge verbessert. Erfahren Sie mehr darüber, wie Grammarly KI nutzt.
Inhaltsgenerierung: Wenn Sie ChatGPT oder DALL-E verwendet haben, haben Sie generative KI aus erster Hand erlebt.Transformatoren haben die Fähigkeit von Computern revolutioniert, Medien zu schaffen, die beim Menschen Anklang finden, von Gute-Nacht-Geschichten bis hin zu hyperrealistischen Architekturdarstellungen.
Spracherkennung: Computer werden von Tag zu Tag besser darin, menschliche Sprache zu erkennen.Mit neueren Technologien, die es ihnen ermöglichen, mehr Kontext zu berücksichtigen, sind Modelle bei der Erkennung dessen, was der Sprecher sagen möchte, immer genauer geworden, selbst wenn die Geräusche allein mehrere Interpretationen haben könnten.
Medizinische Diagnose und Forschung: Neuronale Netze zeichnen sich durch Mustererkennung und -klassifizierung aus und werden zunehmend eingesetzt, um Forschern und Gesundheitsdienstleistern dabei zu helfen, Krankheiten zu verstehen und zu bekämpfen.Die schnelle Entwicklung von COVID-19-Impfstoffen verdanken wir zum Beispiel teilweise der KI.
Herausforderungen und Grenzen neuronaler Netze
Hier ist ein kurzer Blick auf einige, aber nicht alle Probleme, die neuronale Netze aufwerfen.
Voreingenommenheit: Ein neuronales Netzwerk kann nur aus dem lernen, was ihm gesagt wurde.Wenn es sexistischen oder rassistischen Inhalten ausgesetzt ist, wird sein Output wahrscheinlich auch sexistisch oder rassistisch sein. Dies kann beim Übersetzen aus einer nicht geschlechtsspezifischen Sprache in eine geschlechtsspezifische Sprache auftreten, bei der Stereotypen ohne explizite Geschlechtsidentifizierung bestehen bleiben.
Überanpassung: Ein falsch trainiertes Modell kann zu viel in die ihm gegebenen Daten hineinlesen und Probleme mit neuartigen Eingaben haben.Beispielsweise kann Gesichtserkennungssoftware, die hauptsächlich auf Menschen einer bestimmten ethnischen Zugehörigkeit ausgerichtet ist, bei Gesichtern anderer Rassen schlecht funktionieren. Oder ein Spam-Filter übersieht möglicherweise eine neue Art von Junk-Mail, weil er sich zu sehr auf Muster konzentriert, die er bereits gesehen hat.
Halluzinationen: Ein Großteil der heutigen generativen KI nutzt in gewissem Maße Wahrscheinlichkeiten, um zu entscheiden, was produziert werden soll, anstatt immer die oberste Wahl zu treffen.Dieser Ansatz hilft dabei, kreativer zu sein und Texte zu produzieren, die natürlicher klingen, kann aber auch dazu führen, dass Aussagen gemacht werden, die einfach falsch sind. (Das ist auch der Grund, warum LLMs manchmal grundlegende mathematische Fehler machen.) Leider sind diese Halluzinationen schwer zu erkennen, es sei denn, Sie wissen es besser oder überprüfen die Fakten anhand anderer Quellen.
Interpretierbarkeit: Es ist oft unmöglich, genau zu wissen, wie ein neuronales Netzwerk Vorhersagen trifft.Während dies aus der Sicht von jemandem, der versucht, das Modell zu verbessern, frustrierend sein kann, kann es auch folgenreich sein, da man sich zunehmend auf KI verlässt, um Entscheidungen zu treffen, die große Auswirkungen auf das Leben der Menschen haben. Einige heute verwendete Modelle basieren nicht auf neuronalen Netzen, gerade weil ihre Entwickler jede Phase des Prozesses untersuchen und verstehen möchten.
Geistiges Eigentum: Viele glauben, dass LLMs das Urheberrecht verletzen, indem sie Schriften und andere Kunstwerke ohne Genehmigung einbinden.Obwohl sie dazu neigen, urheberrechtlich geschützte Werke nicht direkt zu reproduzieren, ist bekannt, dass diese Modelle Bilder oder Formulierungen erstellen, die wahrscheinlich von bestimmten Künstlern stammen, oder sogar Werke im unverwechselbaren Stil eines Künstlers erstellen, wenn sie dazu aufgefordert werden.
Stromverbrauch: Das gesamte Training und der Betrieb von Transformatormodellen verbraucht enorme Energie.Tatsächlich könnte KI innerhalb weniger Jahre so viel Strom verbrauchen wie Schweden oder Argentinien. Dies unterstreicht die wachsende Bedeutung der Berücksichtigung von Energiequellen und Effizienz bei der KI-Entwicklung.
Zukunft neuronaler Netze
Es ist bekanntermaßen schwierig, die Zukunft der KI vorherzusagen. Im Jahr 1970 sagte einer der führenden KI-Forscher voraus, dass „wir in drei bis acht Jahren eine Maschine mit der allgemeinen Intelligenz eines durchschnittlichen Menschen haben werden.“ (Wir sind der künstlichen allgemeinen Intelligenz (AGI) noch nicht sehr nahe. Zumindest die meisten Menschen glauben das nicht.)
Wir können jedoch auf einige Trends hinweisen, auf die man achten sollte. Effizientere Modelle würden den Stromverbrauch senken und leistungsfähigere neuronale Netze direkt auf Geräten wie Smartphones betreiben. Neue Trainingstechniken könnten nützlichere Vorhersagen mit weniger Trainingsdaten ermöglichen. Ein Durchbruch bei der Interpretierbarkeit könnte das Vertrauen stärken und neue Wege zur Verbesserung der Leistung neuronaler Netze ebnen. Schließlich könnte die Kombination von Quantencomputern und neuronalen Netzen zu Innovationen führen, die wir uns nur ansatzweise vorstellen können.
Abschluss
Neuronale Netze, die von der Struktur und Funktion des menschlichen Gehirns inspiriert sind, sind von grundlegender Bedeutung für die moderne künstliche Intelligenz. Sie zeichnen sich durch Mustererkennung und Vorhersageaufgaben aus und bilden die Grundlage für viele heutige KI-Anwendungen, von der Bild- und Spracherkennung bis zur Verarbeitung natürlicher Sprache. Mit Fortschritten in der Architektur und den Trainingstechniken sorgen neuronale Netze weiterhin für erhebliche Verbesserungen der KI-Fähigkeiten.
Trotz ihres Potenzials stehen neuronale Netze vor Herausforderungen wie Verzerrung, Überanpassung und hohem Energieverbrauch. Die Lösung dieser Probleme ist von entscheidender Bedeutung, da sich die KI weiterentwickelt. Mit Blick auf die Zukunft versprechen Innovationen in den Bereichen Modelleffizienz, Interpretierbarkeit und Integration mit Quantencomputern, die Möglichkeiten neuronaler Netze weiter zu erweitern und möglicherweise zu noch mehr transformativen Anwendungen zu führen.