
Grundlagen wiederkehrender neuronaler Netze: Was Sie wissen müssen
Veröffentlicht: 2024-09-19Rekurrente neuronale Netze (RNNs) sind wesentliche Methoden in den Bereichen Datenanalyse, maschinelles Lernen (ML) und Deep Learning. Ziel dieses Artikels ist es, RNNs zu untersuchen und ihre Funktionalität, Anwendungen sowie Vor- und Nachteile im breiteren Kontext des Deep Learning zu beschreiben.
Inhaltsverzeichnis
Was ist ein RNN?
Wie RNNs funktionieren
Arten von RNNs
RNNs vs. Transformatoren und CNNs
Anwendungen von RNNs
Vorteile
Nachteile
Was ist ein wiederkehrendes neuronales Netzwerk?
Ein rekurrentes neuronales Netzwerk ist ein tiefes neuronales Netzwerk, das sequenzielle Daten verarbeiten kann, indem es einen internen Speicher verwaltet, der es ihm ermöglicht, frühere Eingaben zu verfolgen, um Ausgaben zu generieren. RNNs sind ein grundlegender Bestandteil des Deep Learning und eignen sich besonders für Aufgaben, die sequentielle Daten beinhalten.
Das „wiederkehrende“ in „wiederkehrendes neuronales Netzwerk“ bezieht sich darauf, wie das Modell Informationen aus früheren Eingaben mit aktuellen Eingaben kombiniert. Informationen aus alten Eingaben werden in einer Art internem Speicher gespeichert, der als „verborgener Zustand“ bezeichnet wird. Es wiederholt sich und speist frühere Berechnungen in sich selbst zurück, um einen kontinuierlichen Informationsfluss zu erzeugen.
Lassen Sie uns dies anhand eines Beispiels demonstrieren: Angenommen, wir möchten ein RNN verwenden, um die Stimmung (entweder positiv oder negativ) des Satzes „Er hat den Kuchen glücklich gegessen“ zu erkennen. Das RNN würde das Wortheverarbeiten, seinen verborgenen Zustand aktualisieren, um dieses Wort zu integrieren, und dann mitatefortfahren, dies mit dem kombinieren, was es vonhegelernt hat, und so weiter mit jedem Wort, bis der Satz fertig ist. Um es ins rechte Licht zu rücken: Ein Mensch, der diesen Satz liest, würde sein Verständnis mit jedem Wort aktualisieren. Sobald der Mensch den gesamten Satz gelesen und verstanden hat, kann er sagen, dass der Satz positiv oder negativ ist. Dieser menschliche Prozess des Verstehens versucht der verborgene Zustand anzunähern.
RNNs sind eines der grundlegenden Deep-Learning-Modelle. Bei NLP-Aufgaben (Natural Language Processing) haben sie sich sehr gut geschlagen, auch wenn Transformer sie verdrängt haben. Transformer sind fortschrittliche neuronale Netzwerkarchitekturen, die die RNN-Leistung verbessern, indem sie beispielsweise Daten parallel verarbeiten und in der Lage sind, Beziehungen zwischen Wörtern zu entdecken, die im Quelltext weit voneinander entfernt sind (unter Verwendung von Aufmerksamkeitsmechanismen). Allerdings sind RNNs immer noch nützlich für Zeitreihendaten und für Situationen, in denen einfachere Modelle ausreichen.
Wie RNNs funktionieren
Um die Funktionsweise von RNNs im Detail zu beschreiben, kehren wir zur vorherigen Beispielaufgabe zurück: Klassifizieren Sie die Stimmung des Satzes „Er hat den Kuchen glücklich gegessen.“
Wir beginnen mit einem trainierten RNN, das Texteingaben akzeptiert und eine binäre Ausgabe zurückgibt (1 steht für positiv und 0 für negativ). Bevor die Eingabe an das Modell übergeben wird, ist der verborgene Zustand generisch – er wurde aus dem Trainingsprozess gelernt, ist aber noch nicht spezifisch für die Eingabe.
Das erste Wort,He, wird an das Modell übergeben. Innerhalb des RNN wird dann sein verborgener Zustand aktualisiert (auf den verborgenen Zustand h1), um das WortHeeinzubinden. Als nächstes wird das Wort„ate“an das RNN übergeben und h1 wird aktualisiert (auf h2), um dieses neue Wort einzuschließen. Dieser Vorgang wiederholt sich, bis das letzte Wort übergeben wurde. Der verborgene Zustand (h4) wird aktualisiert, um das letzte Wort einzuschließen. Dann wird der aktualisierte verborgene Zustand verwendet, um entweder eine 0 oder eine 1 zu generieren.
Hier ist eine visuelle Darstellung der Funktionsweise des RNN-Prozesses:
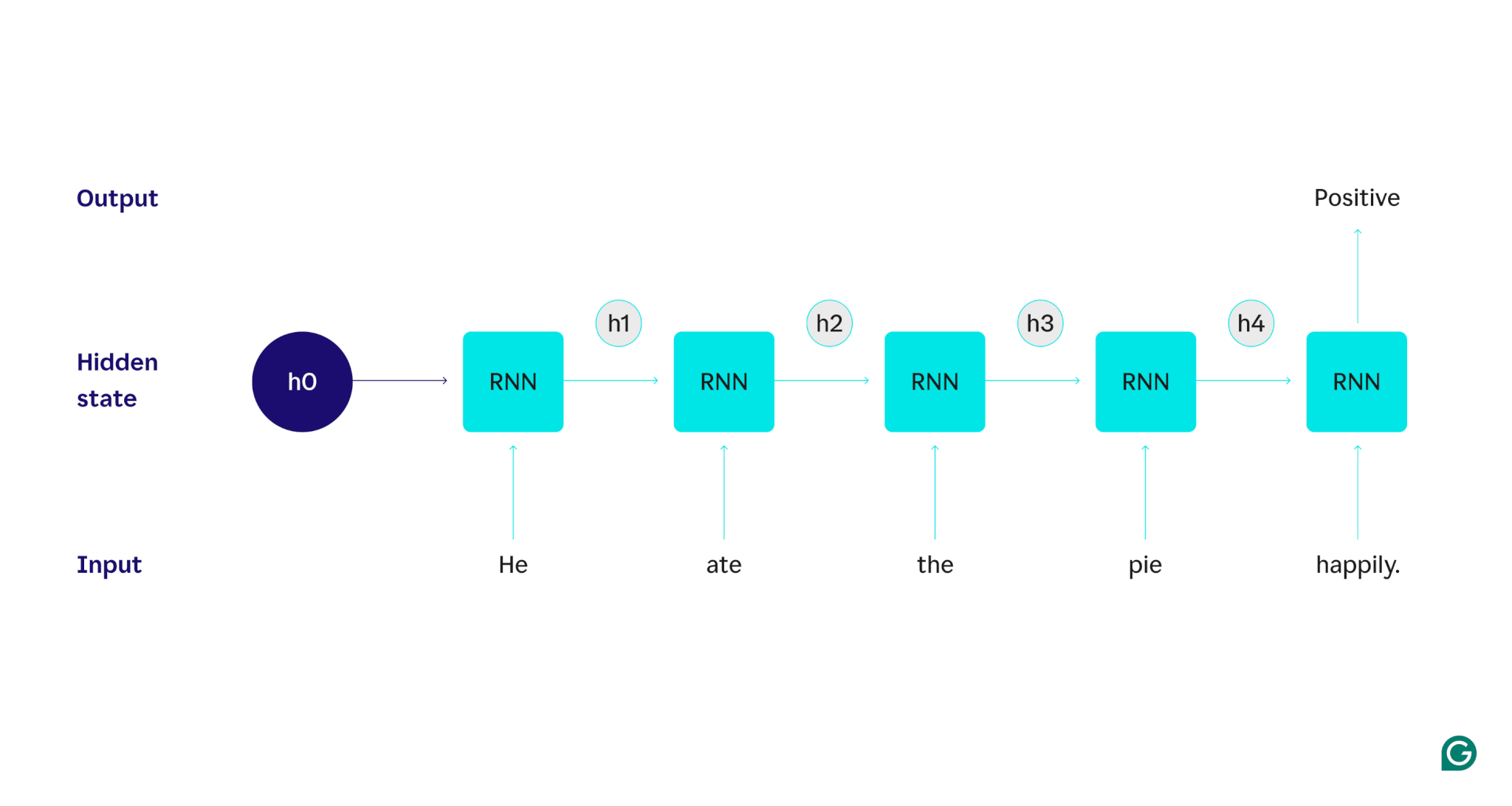
Diese Wiederholung ist der Kern des RNN, aber es gibt noch ein paar andere Überlegungen:
- Texteinbettung:Das RNN kann Text nicht direkt verarbeiten, da es nur bei numerischen Darstellungen funktioniert. Der Text muss in Einbettungen umgewandelt werden, bevor er von einem RNN verarbeitet werden kann.
- Ausgabegenerierung:Bei jedem Schritt wird vom RNN eine Ausgabe generiert. Allerdings ist die Ausgabe möglicherweise nicht sehr genau, bis die meisten Quelldaten verarbeitet sind. Nachdem beispielsweise nur der Teil des Satzes „Er hat gegessen“ verarbeitet wurde, ist das RNN möglicherweise unsicher, ob es sich um eine positive oder negative Stimmung handelt – „Er hat gegessen“ könnte neutral rüberkommen. Erst nach der Verarbeitung des gesamten Satzes wäre die Ausgabe des RNN korrekt.
- Training des RNN:Das RNN muss trainiert werden, um eine Stimmungsanalyse genau durchzuführen. Zum Training gehört es, viele gekennzeichnete Beispiele zu verwenden (z. B. „Er hat den Kuchen wütend gegessen“, als negativ gekennzeichnet), sie durch das RNN laufen zu lassen und das Modell basierend darauf anzupassen, wie weit seine Vorhersagen entfernt sind. Dieser Prozess legt den Standardwert und den Änderungsmechanismus für den verborgenen Zustand fest, sodass das RNN lernen kann, welche Wörter für die Verfolgung in der gesamten Eingabe von Bedeutung sind.
Arten wiederkehrender neuronaler Netze
Es gibt verschiedene Arten von RNNs, die sich jeweils in ihrer Struktur und Anwendung unterscheiden. Grundlegende RNNs unterscheiden sich hauptsächlich in der Größe ihrer Ein- und Ausgänge. Fortgeschrittene RNNs, wie z. B. LSTM-Netzwerke (Long Short-Term Memory), beseitigen einige der Einschränkungen grundlegender RNNs.
Grundlegende RNNs
Eins-zu-eins-RNN:Dieses RNN nimmt eine Eingabe der Länge eins auf und gibt eine Ausgabe der Länge eins zurück. Daher kommt es tatsächlich zu keiner Wiederholung, sodass es sich eher um ein standardmäßiges neuronales Netzwerk als um ein RNN handelt. Ein Beispiel für ein Eins-zu-eins-RNN wäre ein Bildklassifikator, bei dem die Eingabe ein einzelnes Bild und die Ausgabe eine Beschriftung (z. B. „Vogel“) ist.
Eins-zu-viele-RNN:Dieses RNN nimmt eine Eingabe der Länge eins auf und gibt eine mehrteilige Ausgabe zurück. Bei einer Bildunterschriftsaufgabe ist die Eingabe beispielsweise ein Bild und die Ausgabe eine Folge von Wörtern, die das Bild beschreiben (z. B. „Ein Vogel überquert an einem sonnigen Tag einen Fluss“).
Viele-zu-eins-RNN:Dieses RNN nimmt eine mehrteilige Eingabe (z. B. einen Satz, eine Reihe von Bildern oder Zeitreihendaten) auf und gibt eine Ausgabe der Länge eins zurück. Zum Beispiel ein Satz-Stimmungsklassifikator (wie der, den wir besprochen haben), bei dem die Eingabe ein Satz und die Ausgabe eine einzelne Stimmungsbezeichnung (entweder positiv oder negativ) ist.
Viele-zu-viele-RNN:Dieses RNN nimmt eine mehrteilige Eingabe entgegen und gibt eine mehrteilige Ausgabe zurück. Ein Beispiel ist ein Spracherkennungsmodell, bei dem die Eingabe eine Reihe von Audiowellenformen und die Ausgabe eine Folge von Wörtern ist, die den gesprochenen Inhalt darstellen.
Erweitertes RNN: Langes Kurzzeitgedächtnis (LSTM)
Netzwerke mit langem Kurzzeitgedächtnis sind darauf ausgelegt, ein wichtiges Problem bei Standard-RNNs zu lösen: Sie vergessen Informationen bei langen Eingaben. In Standard-RNNs ist der verborgene Zustand stark auf aktuelle Teile der Eingabe ausgerichtet. Bei einer Eingabe, die Tausende von Wörtern umfasst, vergisst das RNN wichtige Details aus den ersten Sätzen. LSTMs verfügen über eine spezielle Architektur, um dieses Vergessensproblem zu umgehen. Sie verfügen über Module, die auswählen, welche Informationen explizit gespeichert und vergessen werden sollen. So werden aktuelle, aber nutzlose Informationen vergessen, während alte, aber relevante Informationen erhalten bleiben. Infolgedessen sind LSTMs weitaus häufiger anzutreffen als Standard-RNNs – sie sind bei komplexen oder langen Aufgaben einfach leistungsfähiger. Sie sind jedoch nicht perfekt, da sie es immer noch vorziehen, Gegenstände zu vergessen.

RNNs vs. Transformatoren und CNNs
Zwei weitere gängige Deep-Learning-Modelle sind Convolutional Neural Networks (CNNs) und Transformer. Wie unterscheiden sie sich?
RNNs vs. Transformatoren
Sowohl RNNs als auch Transformatoren werden im NLP häufig verwendet. Sie unterscheiden sich jedoch erheblich in ihren Architekturen und Ansätzen zur Verarbeitung von Eingaben.
Architektur und Verarbeitung
- RNNs:RNNs verarbeiten Eingaben sequentiell Wort für Wort und behalten dabei einen verborgenen Zustand bei, der Informationen aus vorherigen Wörtern enthält. Diese sequentielle Natur bedeutet, dass RNNs aufgrund dieses Vergessens mit langfristigen Abhängigkeiten zu kämpfen haben können, bei denen frühere Informationen im Verlauf der Sequenz verloren gehen können.
- Transformer:Transformer nutzen einen Mechanismus namens „Aufmerksamkeit“, um Eingaben zu verarbeiten. Im Gegensatz zu RNNs betrachten Transformer die gesamte Sequenz gleichzeitig und vergleichen jedes Wort mit jedem anderen Wort. Dieser Ansatz beseitigt das Problem des Vergessens, da jedes Wort direkten Zugriff auf den gesamten Eingabekontext hat. Aufgrund dieser Fähigkeit haben Transformer bei Aufgaben wie Textgenerierung und Stimmungsanalyse eine überlegene Leistung gezeigt.
Parallelisierung
- RNNs:Die sequentielle Natur von RNNs bedeutet, dass das Modell die Verarbeitung eines Teils der Eingabe abschließen muss, bevor es mit dem nächsten fortfährt. Dies ist sehr zeitaufwändig, da jeder Schritt vom vorherigen abhängt.
- Transformatoren:Transformatoren verarbeiten alle Teile der Eingabe gleichzeitig, da ihre Architektur nicht auf einem sequentiellen verborgenen Zustand beruht. Dadurch sind sie deutlich parallelisierbarer und effizienter. Wenn die Verarbeitung eines Satzes beispielsweise 5 Sekunden pro Wort dauert, würde ein RNN 25 Sekunden für einen Satz mit 5 Wörtern benötigen, während ein Transformator nur 5 Sekunden benötigen würde.
Praktische Implikationen
Aufgrund dieser Vorteile werden Transformatoren in der Industrie immer häufiger eingesetzt. Allerdings können RNNs, insbesondere Netzwerke mit langem Kurzzeitgedächtnis (LSTM), für einfachere Aufgaben oder bei der Bearbeitung kürzerer Sequenzen dennoch effektiv sein. LSTMs werden häufig als kritische Speichermodule in großen Architekturen für maschinelles Lernen verwendet.
RNNs vs. CNNs
CNNs unterscheiden sich grundlegend von RNNs hinsichtlich der von ihnen verarbeiteten Daten und ihrer Betriebsmechanismen.
Datentyp
- RNNs:RNNs sind für sequentielle Daten wie Text oder Zeitreihen konzipiert, bei denen die Reihenfolge der Datenpunkte wichtig ist.
- CNNs:CNNs werden hauptsächlich für räumliche Daten wie Bilder verwendet, bei denen der Schwerpunkt auf den Beziehungen zwischen benachbarten Datenpunkten liegt (z. B. stehen Farbe, Intensität und andere Eigenschaften eines Pixels in einem Bild in engem Zusammenhang mit den Eigenschaften anderer in der Nähe befindlicher Datenpunkte). Pixel).
Betrieb
- RNNs:RNNs speichern die gesamte Sequenz im Gedächtnis und eignen sich daher für Aufgaben, bei denen Kontext und Sequenz wichtig sind.
- CNNs:CNNs funktionieren, indem sie lokale Regionen der Eingabe (z. B. benachbarte Pixel) durch Faltungsschichten betrachten. Dies macht sie für die Bildverarbeitung äußerst effektiv, für sequentielle Daten jedoch weniger effektiv, wo langfristige Abhängigkeiten möglicherweise wichtiger sind.
Eingabelänge
- RNNs:RNNs können Eingabesequenzen variabler Länge mit einer weniger definierten Struktur verarbeiten, wodurch sie für verschiedene sequentielle Datentypen flexibel sind.
- CNNs:CNNs erfordern normalerweise Eingaben mit fester Größe, was eine Einschränkung für die Verarbeitung von Sequenzen variabler Länge darstellen kann.
Anwendungen von RNNs
RNNs werden aufgrund ihrer Fähigkeit, sequentielle Daten effektiv zu verarbeiten, in verschiedenen Bereichen häufig eingesetzt.
Verarbeitung natürlicher Sprache
Sprache ist eine hochgradig sequentielle Datenform, sodass RNNs bei Sprachaufgaben eine gute Leistung erbringen. RNNs zeichnen sich durch Aufgaben wie Textgenerierung, Stimmungsanalyse, Übersetzung und Zusammenfassung aus. Mit Bibliotheken wie PyTorch könnte jemand mithilfe eines RNN und ein paar Gigabyte Textbeispielen einen einfachen Chatbot erstellen.
Spracherkennung
Spracherkennung ist im Kern Sprache und daher auch sehr sequenziell. Für diese Aufgabe könnte ein Many-to-Many-RNN verwendet werden. Bei jedem Schritt übernimmt das RNN den vorherigen verborgenen Zustand und die Wellenform und gibt das mit der Wellenform verknüpfte Wort aus (basierend auf dem Kontext des Satzes bis zu diesem Punkt).
Musikgeneration
Musik ist auch sehr sequenziell. Die vorherigen Beats in einem Song haben großen Einfluss auf die zukünftigen Beats. Ein Viele-zu-Viele-RNN könnte einige Startschläge als Eingabe verwenden und dann nach Wunsch des Benutzers zusätzliche Schläge erzeugen. Alternativ könnte es eine Texteingabe wie „melodischer Jazz“ nehmen und die beste Annäherung an melodische Jazz-Beats ausgeben.
Vorteile von RNNs
Obwohl RNNs nicht mehr das De-facto-NLP-Modell sind, haben sie aufgrund einiger Faktoren immer noch einige Verwendungsmöglichkeiten.
Gute sequentielle Leistung
RNNs, insbesondere LSTMs, eignen sich gut für sequentielle Daten. LSTMs können mit ihrer speziellen Speicherarchitektur lange und komplexe sequentielle Eingaben verwalten. Beispielsweise lief Google Translate vor der Ära der Transformatoren auf einem LSTM-Modell. LSTMs können verwendet werden, um strategische Speichermodule hinzuzufügen, wenn transformatorbasierte Netzwerke zu fortschrittlicheren Architekturen kombiniert werden.
Kleinere, einfachere Modelle
RNNs haben normalerweise weniger Modellparameter als Transformatoren. Die Aufmerksamkeits- und Feedforward-Schichten in Transformatoren erfordern mehr Parameter, um effektiv zu funktionieren. RNNs können mit weniger Durchläufen und Datenbeispielen trainiert werden, was sie für einfachere Anwendungsfälle effizienter macht. Das Ergebnis sind kleinere, kostengünstigere und effizientere Modelle, die dennoch ausreichend leistungsfähig sind.
Nachteile von RNNs
RNNs sind aus einem Grund in Ungnade gefallen: Transformer weisen trotz ihrer größeren Größe und ihres größeren Trainingsprozesses nicht die gleichen Mängel auf wie RNNs.
Begrenzter Speicher
Der verborgene Zustand in Standard-RNNs verzerrt die jüngsten Eingaben stark, was es schwierig macht, langfristige Abhängigkeiten beizubehalten. Aufgaben mit langen Eingaben funktionieren mit RNNs nicht so gut. Während LSTMs darauf abzielen, dieses Problem anzugehen, mildern sie es nur und lösen es nicht vollständig. Viele KI-Aufgaben erfordern die Verarbeitung langer Eingaben, was den begrenzten Speicher zu einem erheblichen Nachteil macht.
Nicht parallelisierbar
Jeder Lauf des RNN-Modells hängt von der Ausgabe des vorherigen Laufs ab, insbesondere vom aktualisierten verborgenen Zustand. Daher muss das gesamte Modell für jeden Teil einer Eingabe sequentiell verarbeitet werden. Im Gegensatz dazu können Transformatoren und CNNs den gesamten Input gleichzeitig verarbeiten. Dies ermöglicht eine parallele Verarbeitung über mehrere GPUs hinweg, was die Berechnung erheblich beschleunigt. Die mangelnde Parallelisierbarkeit von RNNs führt zu einem langsameren Training, einer langsameren Ausgabegenerierung und einer geringeren maximalen Datenmenge, aus der gelernt werden kann.
Probleme mit dem Farbverlauf
Das Training von RNNs kann eine Herausforderung sein, da der Backpropagation-Prozess jeden Eingabeschritt durchlaufen muss (Backpropagation über die Zeit). Aufgrund der vielen Zeitschritte können sich die Gradienten – die angeben, wie die einzelnen Modellparameter angepasst werden sollen – verschlechtern und unwirksam werden. Gradienten können durch Verschwinden scheitern, was bedeutet, dass sie sehr klein werden und das Modell sie nicht mehr zum Lernen verwenden kann, oder durch Explodieren, wobei Gradienten sehr groß werden und das Modell über seine Aktualisierungen hinausschießt, was das Modell unbrauchbar macht. Es ist schwierig, diese Probleme in Einklang zu bringen.