
Was ist ein Autoencoder? Ein Leitfaden für Anfänger
Veröffentlicht: 2024-10-28Autoencoder sind ein wesentlicher Bestandteil des Deep Learning, insbesondere bei unbeaufsichtigten maschinellen Lernaufgaben. In diesem Artikel untersuchen wir die Funktionsweise von Autoencodern, ihre Architektur und die verschiedenen verfügbaren Typen. Sie werden auch ihre realen Anwendungen sowie die Vorteile und Kompromisse kennenlernen, die mit ihrer Verwendung verbunden sind.
Inhaltsverzeichnis
- Was ist ein Autoencoder?
- Autoencoder-Architektur
- Arten von Autoencodern
- Anwendung
- Vorteile
- Nachteile
Was ist ein Autoencoder?
Autoencoder sind eine Art neuronales Netzwerk, das beim Deep Learning verwendet wird, um effiziente, niedrigerdimensionale Darstellungen von Eingabedaten zu lernen, die dann zur Rekonstruktion der Originaldaten verwendet werden. Auf diese Weise lernt dieses Netzwerk während des Trainings die wichtigsten Merkmale der Daten, ohne dass explizite Bezeichnungen erforderlich sind, und macht es so zu einem Teil des selbstüberwachten Lernens. Autoencoder werden häufig bei Aufgaben wie Bildrauschen, Anomalieerkennung und Datenkomprimierung eingesetzt, bei denen ihre Fähigkeit zur Komprimierung und Rekonstruktion von Daten wertvoll ist.
Autoencoder-Architektur
Ein Autoencoder besteht aus drei Teilen: einem Encoder, einem Engpass (auch als latenter Raum oder Code bezeichnet) und einem Decoder. Diese Komponenten arbeiten zusammen, um die Schlüsselmerkmale der Eingabedaten zu erfassen und sie zur Generierung genauer Rekonstruktionen zu verwenden.
Autoencoder optimieren ihre Ausgabe, indem sie die Gewichte von Encoder und Decoder anpassen, mit dem Ziel, eine komprimierte Darstellung der Eingabe zu erzeugen, die wichtige Merkmale beibehält. Diese Optimierung minimiert den Rekonstruktionsfehler, der den Unterschied zwischen den Eingabe- und Ausgabedaten darstellt.
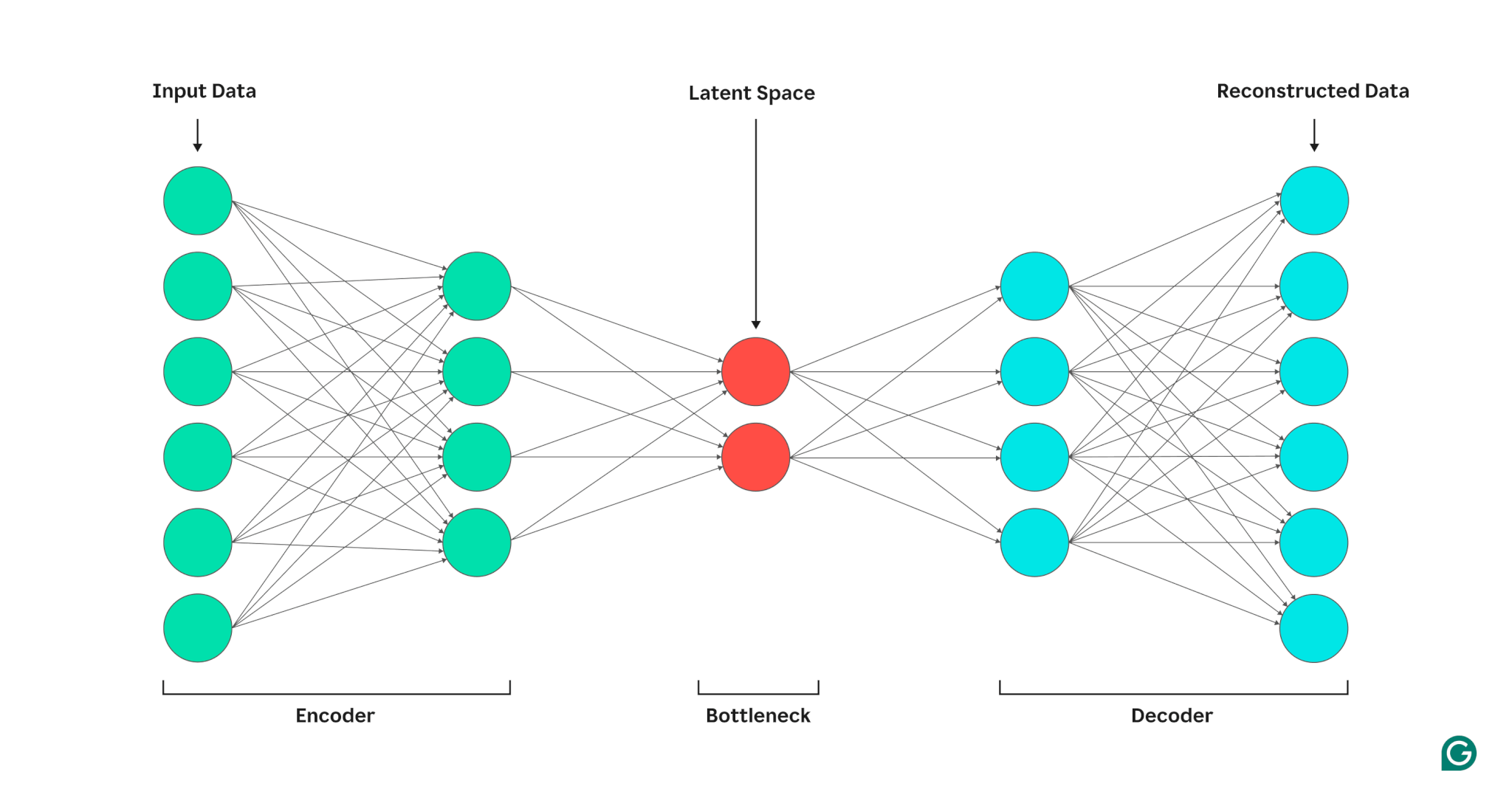
Encoder
Zunächst komprimiert der Encoder die Eingabedaten in eine effizientere Darstellung. Encoder bestehen im Allgemeinen aus mehreren Schichten mit weniger Knoten in jeder Schicht. Während die Daten durch jede Schicht verarbeitet werden, zwingt die reduzierte Anzahl von Knoten das Netzwerk dazu, die wichtigsten Merkmale der Daten zu lernen, um eine Darstellung zu erstellen, die in jeder Schicht gespeichert werden kann. Dieser als Dimensionsreduktion bekannte Prozess wandelt die Eingabe in eine kompakte Zusammenfassung der Schlüsselmerkmale der Daten um. Zu den wichtigsten Hyperparametern im Encoder gehören die Anzahl der Schichten und Neuronen pro Schicht, die die Tiefe und Granularität der Komprimierung bestimmen, sowie die Aktivierungsfunktion, die vorgibt, wie Datenmerkmale auf jeder Schicht dargestellt und transformiert werden.
Engpass
Der Engpass, auch Latentraum oder Code genannt, ist der Ort, an dem die komprimierte Darstellung der Eingabedaten während der Verarbeitung gespeichert wird. Der Engpass weist eine kleine Anzahl von Knoten auf; Dies begrenzt die Menge der speicherbaren Daten und bestimmt den Grad der Komprimierung. Die Anzahl der Knoten im Engpass ist ein einstellbarer Hyperparameter, der es Benutzern ermöglicht, den Kompromiss zwischen Komprimierung und Datenaufbewahrung zu steuern. Wenn der Engpass zu klein ist, kann es sein, dass der Autoencoder die Daten aufgrund des Verlusts wichtiger Details falsch rekonstruiert. Wenn der Engpass andererseits zu groß ist, kopiert der Autoencoder möglicherweise einfach die Eingabedaten, anstatt eine sinnvolle, allgemeine Darstellung zu lernen.
Decoder
In diesem letzten Schritt erstellt der Decoder die Originaldaten aus der komprimierten Form unter Verwendung der während des Codierungsprozesses erlernten Schlüsselfunktionen neu. Die Qualität dieser Dekomprimierung wird anhand des Rekonstruktionsfehlers quantifiziert, der im Wesentlichen ein Maß dafür ist, wie unterschiedlich die rekonstruierten Daten von der Eingabe sind. Der Rekonstruktionsfehler wird im Allgemeinen anhand des mittleren quadratischen Fehlers (MSE) berechnet. Da MSE die quadrierte Differenz zwischen den Original- und den rekonstruierten Daten misst, bietet es eine mathematisch einfache Möglichkeit, größere Rekonstruktionsfehler stärker zu bestrafen.
Arten von Autoencodern
Es gibt verschiedene Arten spezialisierter Autoencoder, die jeweils für bestimmte Anwendungen optimiert sind, ähnlich wie bei anderen neuronalen Netzen.
Rauschunterdrückung von Autoencodern
Entrauschende Autoencoder sind darauf ausgelegt, saubere Daten aus verrauschten oder beschädigten Eingaben zu rekonstruieren. Während des Trainings wird den Eingabedaten absichtlich Rauschen hinzugefügt, sodass das Modell Merkmale erlernen kann, die trotz des Rauschens konsistent bleiben. Die Ausgaben werden dann mit den ursprünglichen sauberen Eingaben verglichen. Dieser Prozess macht Rauschunterdrückungs-Autoencoder äußerst effektiv bei der Reduzierung von Bild- und Audiorauschen, einschließlich der Entfernung von Hintergrundgeräuschen in Videokonferenzen.
Sparse Autoencoder
Sparse-Autoencoder begrenzen die Anzahl der aktiven Neuronen zu einem bestimmten Zeitpunkt und ermutigen das Netzwerk, im Vergleich zu Standard-Autoencodern effizientere Datendarstellungen zu lernen. Diese Einschränkung der Sparsität wird durch eine Strafe erzwungen, die davon abhält, mehr Neuronen als einen bestimmten Schwellenwert zu aktivieren. Sparse-Autoencoder vereinfachen hochdimensionale Daten und bewahren gleichzeitig wesentliche Merkmale, was sie für Aufgaben wie die Extraktion interpretierbarer Merkmale und die Visualisierung komplexer Datensätze wertvoll macht.
Variationale Autoencoder (VAEs)
Im Gegensatz zu typischen Autoencodern generieren VAEs neue Daten, indem sie Merkmale aus Trainingsdaten in eine Wahrscheinlichkeitsverteilung und nicht in einen festen Punkt kodieren. Durch Stichproben aus dieser Verteilung können VAEs vielfältige neue Daten generieren, anstatt die Originaldaten aus der Eingabe zu rekonstruieren. Diese Fähigkeit macht VAEs für generative Aufgaben, einschließlich der Generierung synthetischer Daten, nützlich. Beispielsweise kann bei der Bildgenerierung ein VAE, das anhand eines Datensatzes handgeschriebener Zahlen trainiert wurde, auf der Grundlage des Trainingssatzes neue, realistisch aussehende Ziffern erstellen, bei denen es sich nicht um exakte Nachbildungen handelt.

Kontraktive Autoencoder
Kontraktive Autoencoder führen bei der Berechnung des Rekonstruktionsfehlers einen zusätzlichen Strafterm ein und ermutigen das Modell, Merkmalsdarstellungen zu lernen, die robust gegenüber Rauschen sind. Diese Strafe trägt dazu bei, eine Überanpassung zu verhindern, indem sie das Feature-Lernen fördert, das gegenüber kleinen Variationen in den Eingabedaten invariant ist. Infolgedessen sind kontraktive Autoencoder robuster gegenüber Rauschen als Standard-Autoencoder.
Faltungs-Autoencoder (CAEs)
CAEs nutzen Faltungsschichten, um räumliche Hierarchien und Muster in hochdimensionalen Daten zu erfassen. Durch den Einsatz von Faltungsschichten eignen sich CAEs besonders gut für die Verarbeitung von Bilddaten. CAEs werden häufig für Aufgaben wie Bildkomprimierung und Anomalieerkennung in Bildern verwendet.
Anwendungen von Autoencodern in der KI
Autoencoder haben verschiedene Anwendungen, z. B. Dimensionsreduzierung, Bildrauschunterdrückung und Anomalieerkennung.
Dimensionsreduktion
Autoencoder sind wirksame Werkzeuge zur Reduzierung der Dimensionalität von Eingabedaten unter Beibehaltung wichtiger Funktionen. Dieser Prozess ist für Aufgaben wie die Visualisierung hochdimensionaler Datensätze und die Komprimierung von Daten wertvoll. Durch die Vereinfachung der Daten steigert die Dimensionsreduktion auch die Recheneffizienz und verringert sowohl die Größe als auch die Komplexität.
Anomalieerkennung
Durch das Erlernen der Schlüsselmerkmale eines Zieldatensatzes können Autoencoder bei der Bereitstellung neuer Eingaben zwischen normalen und anomalen Daten unterscheiden. Eine Abweichung vom Normalzustand wird durch höhere Rekonstruktionsfehlerraten als normal angezeigt. Daher können Autoencoder in verschiedenen Bereichen wie der vorausschauenden Wartung und der Sicherheit von Computernetzwerken eingesetzt werden.
Entrauschen
Entrauschende Autoencoder können verrauschte Daten bereinigen, indem sie lernen, sie aus verrauschten Trainingseingaben zu rekonstruieren. Diese Funktion macht Autoencoder zur Rauschunterdrückung wertvoll für Aufgaben wie die Bildoptimierung, einschließlich der Verbesserung der Qualität verschwommener Fotos. Entrauschende Autoencoder sind auch in der Signalverarbeitung nützlich, wo sie verrauschte Signale für eine effizientere Verarbeitung und Analyse bereinigen können.
Vorteile von Autoencodern
Autoencoder bieten eine Reihe entscheidender Vorteile. Dazu gehört die Möglichkeit, aus unbeschrifteten Daten zu lernen, Features ohne explizite Anweisung automatisch zu lernen und nichtlineare Features zu extrahieren.
Kann aus unbeschrifteten Daten lernen
Autoencoder sind ein unbeaufsichtigtes Modell des maschinellen Lernens, was bedeutet, dass sie zugrunde liegende Datenmerkmale aus unbeschrifteten Daten lernen können. Diese Fähigkeit bedeutet, dass Autoencoder auf Aufgaben angewendet werden können, bei denen gekennzeichnete Daten möglicherweise knapp oder nicht verfügbar sind.
Automatisches Feature-Lernen
Standardtechniken zur Merkmalsextraktion, wie etwa die Hauptkomponentenanalyse (PCA), sind oft unpraktisch, wenn es um den Umgang mit komplexen und/oder großen Datensätzen geht. Da Autoencoder mit Blick auf Aufgaben wie Dimensionsreduzierung entwickelt wurden, können sie wichtige Merkmale und Muster in Daten automatisch lernen, ohne dass ein manuelles Merkmalsdesign erforderlich ist.
Nichtlineare Merkmalsextraktion
Autoencoder können nichtlineare Beziehungen in Eingabedaten verarbeiten, sodass das Modell wichtige Merkmale aus komplexeren Datendarstellungen erfassen kann. Diese Fähigkeit bedeutet, dass Autoencoder gegenüber Modellen, die nur mit linearen Daten arbeiten können, einen Vorteil haben, da sie komplexere Datensätze verarbeiten können.
Einschränkungen von Autoencodern
Wie andere ML-Modelle haben auch Autoencoder ihre eigenen Nachteile. Dazu gehören mangelnde Interpretierbarkeit, die Notwendigkeit großer Trainingsdatensätze für eine gute Leistung und begrenzte Generalisierungsmöglichkeiten.
Mangelnde Interpretierbarkeit
Ähnlich wie bei anderen komplexen ML-Modellen leiden Autoencoder unter mangelnder Interpretierbarkeit, was bedeutet, dass es schwierig ist, die Beziehung zwischen Eingabedaten und Modellausgabe zu verstehen. Bei Autoencodern tritt dieser Mangel an Interpretierbarkeit auf, weil Autoencoder Features automatisch lernen, im Gegensatz zu herkömmlichen Modellen, bei denen Features explizit definiert sind. Diese maschinengenerierte Merkmalsdarstellung ist oft sehr abstrakt und weist tendenziell keine für den Menschen interpretierbaren Merkmale auf, was es schwierig macht, zu verstehen, was jede Komponente in der Darstellung bedeutet.
Erfordern große Trainingsdatensätze
Autoencoder erfordern in der Regel große Trainingsdatensätze, um verallgemeinerbare Darstellungen wichtiger Datenmerkmale zu erlernen. Bei kleinen Trainingsdatensätzen neigen Autoencoder möglicherweise zu einer Überanpassung, was bei der Präsentation neuer Daten zu einer schlechten Generalisierung führt. Große Datensätze hingegen bieten dem Autoencoder die nötige Vielfalt, um Datenfunktionen zu erlernen, die in einer Vielzahl von Szenarien angewendet werden können.
Begrenzte Verallgemeinerung neuer Daten
Auf einem Datensatz trainierte Autoencoder verfügen häufig nur über begrenzte Generalisierungsfähigkeiten, was bedeutet, dass sie sich nicht an neue Datensätze anpassen können. Diese Einschränkung tritt auf, weil Autoencoder auf die Datenrekonstruktion basierend auf herausragenden Merkmalen eines bestimmten Datensatzes ausgerichtet sind. Daher verwerfen Autoencoder während des Trainings im Allgemeinen kleinere Details aus den Daten und können keine Daten verarbeiten, die nicht zur verallgemeinerten Merkmalsdarstellung passen.