
Was ist ein Entscheidungsbaum beim maschinellen Lernen?
Veröffentlicht: 2024-08-14Entscheidungsbäume sind eines der gebräuchlichsten Werkzeuge im Toolkit für maschinelles Lernen eines Datenanalysten. In diesem Leitfaden erfahren Sie, was Entscheidungsbäume sind, wie sie aufgebaut sind, welche Anwendungen es gibt, welche Vorteile sie haben und vieles mehr.
Inhaltsverzeichnis
- Was ist ein Entscheidungsbaum?
- Terminologie des Entscheidungsbaums
- Arten von Entscheidungsbäumen
- Wie Entscheidungsbäume funktionieren
- Anwendungen
- Vorteile
- Nachteile
Was ist ein Entscheidungsbaum?
Beim maschinellen Lernen (ML) ist ein Entscheidungsbaum ein überwachter Lernalgorithmus, der einem Flussdiagramm oder Entscheidungsdiagramm ähnelt. Im Gegensatz zu vielen anderen überwachten Lernalgorithmen können Entscheidungsbäume sowohl für Klassifizierungs- als auch für Regressionsaufgaben verwendet werden. Datenwissenschaftler und -analysten verwenden bei der Untersuchung neuer Datensätze häufig Entscheidungsbäume, da diese einfach zu erstellen und zu interpretieren sind. Darüber hinaus können Entscheidungsbäume dabei helfen, wichtige Datenmerkmale zu identifizieren, die bei der Anwendung komplexerer ML-Algorithmen nützlich sein können.
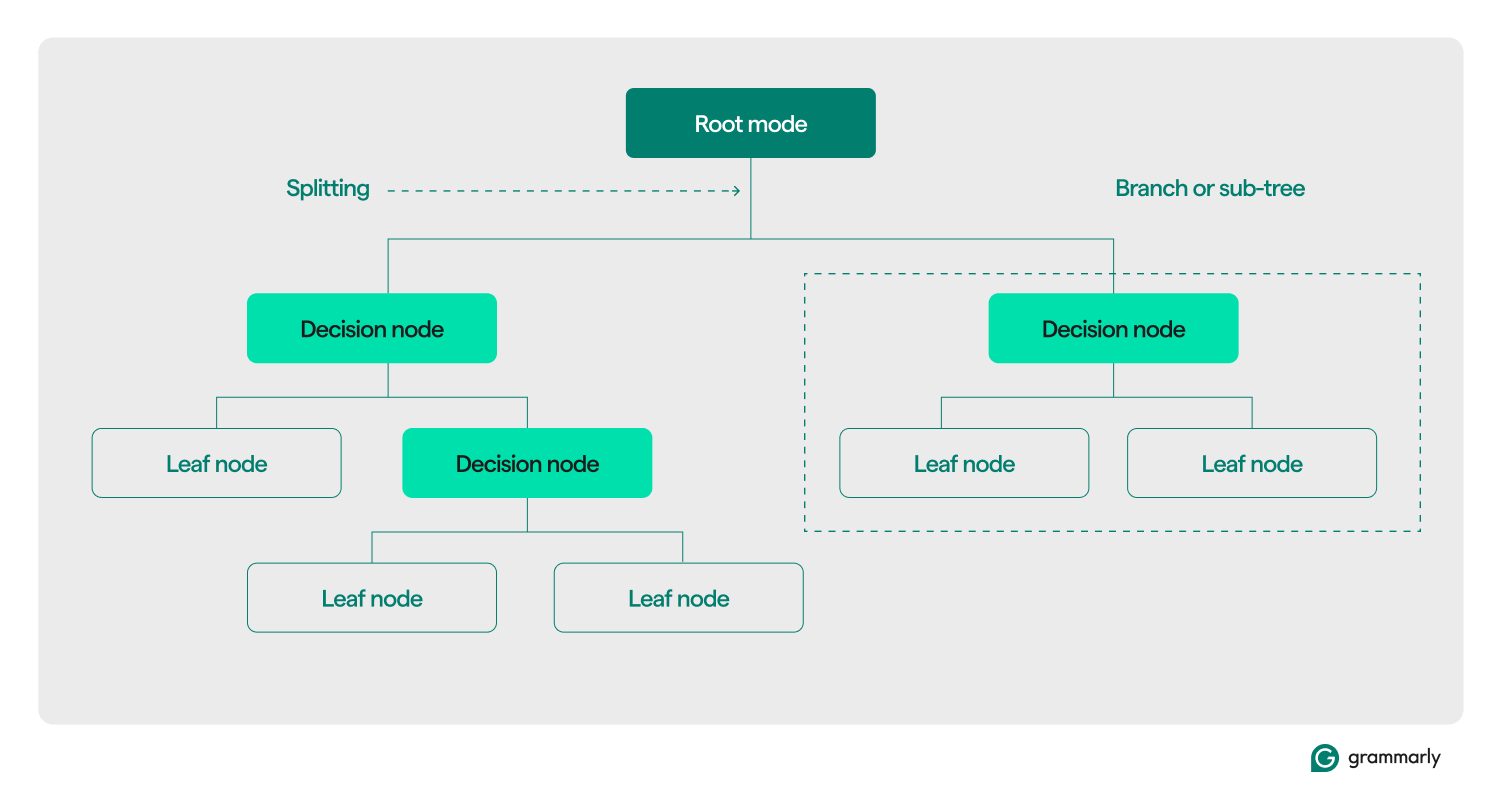
Terminologie des Entscheidungsbaums
Strukturell besteht ein Entscheidungsbaum typischerweise aus drei Komponenten: einem Wurzelknoten, Blattknoten und Entscheidungsknoten (oder internen Knoten). Genau wie Flussdiagramme oder Bäume in anderen Bereichen bewegen sich Entscheidungen in einem Baum normalerweise in eine Richtung (entweder nach unten oder nach oben), beginnend beim Wurzelknoten, durch einige Entscheidungsknoten hindurch und endend an einem bestimmten Blattknoten. Jeder Blattknoten verbindet eine Teilmenge der Trainingsdaten mit einer Bezeichnung. Der Baum wird durch einen ML-Trainings- und Optimierungsprozess zusammengestellt und kann nach seiner Erstellung auf verschiedene Datensätze angewendet werden.
Hier ist ein tieferer Einblick in den Rest der Terminologie:
- Wurzelknoten:Ein Knoten, der die erste einer Reihe von Fragen enthält, die der Entscheidungsbaum zu den Daten stellt. Der Knoten wird mit mindestens einem (normalerweise jedoch zwei oder mehr) Entscheidungs- oder Blattknoten verbunden.
- Entscheidungsknoten (oder interne Knoten):Zusätzliche Knoten, die Fragen enthalten. Ein Entscheidungsknoten enthält genau eine Frage zu den Daten und leitet den Datenfluss basierend auf der Antwort an eines seiner untergeordneten Knoten weiter.
- Untergeordnete Elemente:Ein oder mehrere Knoten, auf die ein Wurzel- oder Entscheidungsknoten verweist. Sie stellen eine Liste der nächsten Optionen dar, die der Entscheidungsprozess bei der Datenanalyse nutzen kann.
- Blattknoten (oder Endknoten):Knoten, die anzeigen, dass der Entscheidungsprozess abgeschlossen ist. Sobald der Entscheidungsprozess einen Blattknoten erreicht, gibt er den/die Wert(e) vom Blattknoten als Ausgabe zurück.
- Bezeichnung (Klasse, Kategorie):Im Allgemeinen eine Zeichenfolge, die durch einen Blattknoten mit einigen Trainingsdaten verknüpft wird. Beispielsweise könnte ein Blatt die Bezeichnung „Zufriedener Kunde“ mit einer Reihe spezifischer Kunden verknüpfen, die dem Entscheidungsbaum-ML-Trainingsalgorithmus präsentiert wurden.
- Zweig (oder Unterbaum):Dies ist die Menge von Knoten, die aus einem Entscheidungsknoten an jedem Punkt im Baum sowie allen seinen untergeordneten Elementen und deren untergeordneten Elementen bis hinunter zu den Blattknoten besteht.
- Beschneiden:Eine Optimierungsoperation, die normalerweise am Baum durchgeführt wird, um ihn zu verkleinern und ihm zu helfen, schneller Ausgaben zurückzugeben. Beschneiden bezieht sich normalerweise auf „Nachbeschneiden“, bei dem Knoten oder Zweige algorithmisch entfernt werden, nachdem der ML-Trainingsprozess den Baum erstellt hat. Unter „Pre-Pruning“ versteht man das Festlegen einer willkürlichen Grenze dafür, wie tief oder groß ein Entscheidungsbaum während des Trainings wachsen kann. Beide Prozesse erzwingen eine maximale Komplexität für den Entscheidungsbaum, die normalerweise an seiner maximalen Tiefe oder Höhe gemessen wird. Zu den weniger verbreiteten Optimierungen gehört die Begrenzung der maximalen Anzahl von Entscheidungsknoten oder Blattknoten.
- Aufteilung:Der Kerntransformationsschritt, der während des Trainings an einem Entscheidungsbaum ausgeführt wird. Dabei wird ein Wurzel- oder Entscheidungsknoten in zwei oder mehr Unterknoten unterteilt.
- Klassifizierung:Ein ML-Algorithmus, der versucht herauszufinden, welche (aus einer konstanten und diskreten Liste von Klassen, Kategorien oder Labels) am wahrscheinlichsten auf ein Datenelement anwendbar ist. Es könnte versucht werden, Fragen wie „Welcher Wochentag eignet sich am besten für die Buchung eines Fluges?“ zu beantworten. Mehr zur Klassifizierung weiter unten.
- Regression:Ein ML-Algorithmus, der versucht, einen kontinuierlichen Wert vorherzusagen, der möglicherweise nicht immer Grenzen hat. Es könnte versuchen, Fragen wie „Wie viele Personen werden voraussichtlich nächsten Dienstag einen Flug buchen?“ zu beantworten (oder die Antwort vorherzusagen). Wir werden im nächsten Abschnitt mehr über Regressionsbäume sprechen.
Arten von Entscheidungsbäumen
Entscheidungsbäume werden typischerweise in zwei Kategorien eingeteilt: Klassifizierungsbäume und Regressionsbäume. Ein spezifischer Baum kann für die Klassifizierung, Regression oder beide Anwendungsfälle erstellt werden. Die meisten modernen Entscheidungsbäume verwenden den CART-Algorithmus (Classification and Regression Trees), der beide Arten von Aufgaben ausführen kann.
Klassifizierungsbäume
Klassifizierungsbäume, die häufigste Art von Entscheidungsbäumen, versuchen, ein Klassifizierungsproblem zu lösen. Aus einer Liste möglicher Antworten auf eine Frage (oft so einfach wie „Ja“ oder „Nein“) wählt ein Klassifizierungsbaum die wahrscheinlichste aus, nachdem er einige Fragen zu den vorgelegten Daten gestellt hat. Sie werden normalerweise als binäre Bäume implementiert, was bedeutet, dass jeder Entscheidungsknoten genau zwei untergeordnete Knoten hat.
Klassifizierungsbäume könnten versuchen, Multiple-Choice-Fragen wie „Ist dieser Kunde zufrieden?“ zu beantworten. oder „Welches Ladengeschäft wird dieser Kunde voraussichtlich besuchen?“ oder „Wird morgen ein guter Tag sein, um auf den Golfplatz zu gehen?“
Die beiden gängigsten Methoden zur Messung der Qualität eines Klassifizierungsbaums basieren auf Informationsgewinn und Entropie:
- Informationsgewinn:Die Effizienz eines Baums wird gesteigert, wenn er weniger Fragen stellt, bevor er zu einer Antwort gelangt. Der Informationsgewinn misst, wie „schnell“ ein Baum eine Antwort erhalten kann, indem er bewertet, wie viel mehr Informationen über ein Datenelement an jedem Entscheidungsknoten gelernt werden. Dabei wird beurteilt, ob die wichtigsten und nützlichsten Fragen im Baum zuerst gestellt werden.
- Entropie:Genauigkeit ist für Entscheidungsbaumbezeichnungen von entscheidender Bedeutung. Entropiemetriken messen diese Genauigkeit, indem sie die vom Baum erzeugten Beschriftungen auswerten. Sie bewerten, wie oft ein zufälliges Datenelement mit der falschen Bezeichnung endet und wie ähnlich alle Trainingsdaten sind, die dieselbe Bezeichnung erhalten.
Zu den fortgeschritteneren Messungen der Baumqualität gehören derGini-Index,das Verstärkungsverhältnis,Chi-Quadrat-Bewertungenund verschiedene Messungen zur Varianzreduzierung.
Regressionsbäume
Regressionsbäume werden typischerweise in der Regressionsanalyse für erweiterte statistische Analysen oder zur Vorhersage von Daten aus einem kontinuierlichen, potenziell unbegrenzten Bereich verwendet. Bei einer Reihe kontinuierlicher Optionen (z. B. Null bis Unendlich auf der Skala reeller Zahlen) versucht der Regressionsbaum, die wahrscheinlichste Übereinstimmung für ein bestimmtes Datenelement vorherzusagen, nachdem eine Reihe von Fragen gestellt wurden. Jede Frage schränkt den möglichen Antwortbereich ein. Beispielsweise könnte ein Regressionsbaum verwendet werden, um Kredit-Scores, Einnahmen aus einem Geschäftsbereich oder die Anzahl der Interaktionen in einem Marketingvideo vorherzusagen.
Die Genauigkeit von Regressionsbäumen wird normalerweise anhand von Metriken wiedem mittleren quadratischen Fehleroderdem mittleren absoluten Fehlerbewertet, die berechnen, wie weit ein bestimmter Satz von Vorhersagen von den tatsächlichen Werten abweicht.
Wie Entscheidungsbäume funktionieren
Als Beispiel für überwachtes Lernen stützen sich Entscheidungsbäume für das Training auf gut formatierte Daten. Die Quelldaten enthalten normalerweise eine Liste von Werten, die das Modell vorhersagen oder klassifizieren lernen soll. Jeder Wert sollte über eine angehängte Beschriftung und eine Liste der zugehörigen Features verfügen – Eigenschaften, die das Modell lernen sollte, mit der Beschriftung zu verknüpfen.

Bauen oder trainieren
Während des Trainingsprozesses werden Entscheidungsknoten im Entscheidungsbaum gemäß einem oder mehreren Trainingsalgorithmen rekursiv in spezifischere Knoten aufgeteilt. Eine Beschreibung des Prozesses auf menschlicher Ebene könnte wie folgt aussehen:
- Beginnen Sie mit dem Wurzelknoten,der mit dem gesamten Trainingssatz verbunden ist.
- Teilen Sie den Wurzelknoten:Weisen Sie mithilfe eines statistischen Ansatzes eine Entscheidung basierend auf einem der Datenmerkmale dem Wurzelknoten zu und verteilen Sie die Trainingsdaten auf mindestens zwei separate Blattknoten, die als untergeordnete Knoten mit der Wurzel verbunden sind.
- Wenden Sie Schritt zwei rekursivauf jedes der untergeordneten Elemente an und verwandeln Sie sie von Blattknoten in Entscheidungsknoten. Stoppen Sie, wenn ein Grenzwert erreicht ist (z. B. die Höhe/Tiefe des Baums, ein Maß für die Qualität der untergeordneten Elemente in jedem Blatt an jedem Knoten usw.) oder wenn Ihnen die Daten ausgehen (d. h. jedes Blatt enthält Daten). Punkte, die sich auf genau ein Label beziehen).
Die Entscheidung, welche Features an jedem Knoten berücksichtigt werden sollen, ist für Klassifizierung, Regression und kombinierte Klassifizierungs- und Regressionsanwendungsfälle unterschiedlich. Für jedes Szenario stehen viele Algorithmen zur Auswahl. Zu den typischen Algorithmen gehören:
- ID3 (Klassifizierung):Optimiert Entropie und Informationsgewinn
- C4.5 (Klassifizierung):Eine komplexere Version von ID3, die den Informationsgewinn durch Normalisierung erhöht
- CART (Klassifizierung/Regression): „Klassifizierungs- und Regressionsbaum“; ein gieriger Algorithmus, der auf minimale Verunreinigung in Ergebnismengen optimiert
- CHAID (Klassifizierung/Regression): „Chi-Quadrat-Automatische Interaktionserkennung“; verwendet Chi-Quadrat-Messungen anstelle von Entropie und Informationsgewinn
- MARS (Klassifizierung/Regression): Verwendet stückweise lineare Approximationen, um Nichtlinearitäten zu erfassen
Ein gängiges Trainingsprogramm ist der Random Forest. Eine Zufallsstruktur oder eine Zufallsentscheidungsstruktur ist ein System, das viele verwandte Entscheidungsbäume erstellt. Mithilfe von Kombinationen von Trainingsalgorithmen können mehrere Versionen eines Baums parallel trainiert werden. Basierend auf verschiedenen Messungen der Baumqualität wird eine Teilmenge dieser Bäume verwendet, um eine Antwort zu erstellen. Bei Klassifizierungsanwendungsfällen wird die von der größten Anzahl an Bäumen ausgewählte Klasse als Antwort zurückgegeben. Bei Regressionsanwendungsfällen wird die Antwort aggregiert, normalerweise als mittlere oder durchschnittliche Vorhersage einzelner Bäume.
Entscheidungsbäume auswerten und nutzen
Sobald ein Entscheidungsbaum erstellt wurde, kann er neue Daten klassifizieren oder Werte für einen bestimmten Anwendungsfall vorhersagen. Es ist wichtig, Metriken zur Baumleistung zu behalten und sie zur Bewertung der Genauigkeit und Fehlerhäufigkeit zu verwenden. Wenn das Modell zu stark von der erwarteten Leistung abweicht, ist es möglicherweise an der Zeit, es auf neue Daten umzuschulen oder andere ML-Systeme zu finden, die auf diesen Anwendungsfall anwendbar sind.
Anwendungen von Entscheidungsbäumen in ML
Entscheidungsbäume haben ein breites Anwendungsspektrum in verschiedenen Bereichen. Hier einige Beispiele, um ihre Vielseitigkeit zu veranschaulichen:
Informierte persönliche Entscheidungsfindung
Eine Person kann beispielsweise Daten über die Restaurants, die sie besucht hat, im Auge behalten. Sie könnten alle relevanten Details verfolgen – wie Reisezeit, Wartezeit, angebotene Küche, Öffnungszeiten, durchschnittliche Bewertungspunktzahl, Kosten und letzter Besuch, zusammen mit einem Zufriedenheitswert für den Besuch der Person in diesem Restaurant. Anhand dieser Daten kann ein Entscheidungsbaum trainiert werden, um den wahrscheinlichen Zufriedenheitswert für ein neues Restaurant vorherzusagen.
Berechnen Sie Wahrscheinlichkeiten rund um das Kundenverhalten
Kundensupportsysteme können Entscheidungsbäume verwenden, um die Kundenzufriedenheit vorherzusagen oder zu klassifizieren. Ein Entscheidungsbaum kann trainiert werden, um die Kundenzufriedenheit anhand verschiedener Faktoren vorherzusagen, z. B. ob der Kunde den Support kontaktiert oder einen erneuten Kauf getätigt hat, oder anhand von Aktionen, die innerhalb einer App ausgeführt werden. Darüber hinaus können Ergebnisse aus Zufriedenheitsumfragen oder anderem Kundenfeedback einfließen.
Helfen Sie dabei, geschäftliche Entscheidungen zu treffen
Für bestimmte Geschäftsentscheidungen mit einer Fülle an historischen Daten kann ein Entscheidungsbaum Schätzungen oder Vorhersagen für die nächsten Schritte liefern. Beispielsweise kann ein Unternehmen, das demografische und geografische Informationen über seine Kunden sammelt, einen Entscheidungsbaum trainieren, um zu bewerten, welche neuen geografischen Standorte wahrscheinlich profitabel sind oder vermieden werden sollten. Entscheidungsbäume können auch dabei helfen, die besten Klassifizierungsgrenzen für vorhandene demografische Daten zu ermitteln, z. B. die Identifizierung von Altersgruppen, die bei der Gruppierung von Kunden separat berücksichtigt werden sollen.
Funktionsauswahl für fortgeschrittenes ML und andere Anwendungsfälle
Entscheidungsbaumstrukturen sind für Menschen lesbar und verständlich. Sobald ein Baum erstellt ist, ist es möglich, zu identifizieren, welche Features für den Datensatz am relevantesten sind und in welcher Reihenfolge. Diese Informationen können die Entwicklung komplexerer ML-Systeme oder Entscheidungsalgorithmen leiten. Wenn ein Unternehmen beispielsweise aus einem Entscheidungsbaum erfährt, dass Kunden die Kosten eines Produkts über alles andere stellen, kann es komplexere ML-Systeme auf diese Erkenntnisse konzentrieren oder die Kosten ignorieren, wenn es differenziertere Funktionen untersucht.
Vorteile von Entscheidungsbäumen in ML
Entscheidungsbäume bieten mehrere wesentliche Vorteile, die sie zu einer beliebten Wahl in ML-Anwendungen machen. Hier sind einige wichtige Vorteile:
Schnell und einfach aufzubauen
Entscheidungsbäume gehören zu den ausgereiftesten und am besten verstandenen ML-Algorithmen. Sie sind nicht auf besonders komplexe Berechnungen angewiesen und können schnell und einfach erstellt werden. Solange die erforderlichen Informationen leicht verfügbar sind, ist ein Entscheidungsbaum ein einfacher erster Schritt, wenn man über ML-Lösungen für ein Problem nachdenkt.
Für den Menschen leicht verständlich
Die Ausgabe von Entscheidungsbäumen ist besonders einfach zu lesen und zu interpretieren. Die grafische Darstellung eines Entscheidungsbaums erfordert keine fortgeschrittenen Kenntnisse der Statistik. Daher können Entscheidungsbäume und ihre Darstellungen verwendet werden, um die Ergebnisse komplexerer Analysen zu interpretieren, zu erklären und zu unterstützen. Entscheidungsbäume eignen sich hervorragend zum Auffinden und Hervorheben einiger übergeordneter Eigenschaften eines bestimmten Datensatzes.
Minimale Datenverarbeitung erforderlich
Entscheidungsbäume können genauso einfach auf der Grundlage unvollständiger Daten oder Daten mit eingeschlossenen Ausreißern erstellt werden. Da die Daten mit interessanten Merkmalen versehen sind, sind die Entscheidungsbaumalgorithmen in der Regel nicht so stark betroffen wie andere ML-Algorithmen, wenn ihnen Daten zugeführt werden, die nicht vorverarbeitet wurden.
Nachteile von Entscheidungsbäumen in ML
Obwohl Entscheidungsbäume viele Vorteile bieten, bringen sie auch einige Nachteile mit sich:
Anfällig für Überanpassung
Entscheidungsbäume sind anfällig für eine Überanpassung, die auftritt, wenn ein Modell das Rauschen und die Details in den Trainingsdaten lernt und dadurch seine Leistung bei neuen Daten verringert. Wenn die Trainingsdaten beispielsweise unvollständig oder spärlich sind, können kleine Änderungen in den Daten zu deutlich unterschiedlichen Baumstrukturen führen. Fortgeschrittene Techniken wie das Beschneiden oder das Festlegen einer maximalen Tiefe können das Verhalten des Baumes verbessern. In der Praxis müssen Entscheidungsbäume häufig mit neuen Informationen aktualisiert werden, was ihre Struktur erheblich verändern kann.
Schlechte Skalierbarkeit
Zusätzlich zu ihrer Tendenz zur Überanpassung haben Entscheidungsbäume mit komplexeren Problemen zu kämpfen, die deutlich mehr Daten erfordern. Im Vergleich zu anderen Algorithmen nimmt die Trainingszeit für Entscheidungsbäume mit zunehmendem Datenvolumen rapide zu. Für größere Datensätze, die möglicherweise wichtige Eigenschaften auf hoher Ebene erkennen müssen, eignen sich Entscheidungsbäume nicht besonders gut.
Nicht so effektiv für Regression oder kontinuierliche Anwendungsfälle
Entscheidungsbäume lernen komplexe Datenverteilungen nicht sehr gut. Sie teilen den Merkmalsraum entlang leicht verständlicher, aber mathematisch einfacher Linien auf. Bei komplexen Problemen, bei denen Ausreißer relevant sind, Regression und kontinuierliche Anwendungsfälle, führt dies häufig zu einer viel schlechteren Leistung als bei anderen ML-Modellen und -Techniken.