
F1 -Punktzahl im maschinellen Lernen: Berechnen, Anwendung und Verwendung effektiv
Veröffentlicht: 2025-02-10Der F1 -Score ist eine leistungsstarke Metrik für die Bewertung von Modellen für maschinelles Lernen (ML -Modelle), die zur Durchführung einer binären oder Multiclas -Klassifizierung entwickelt wurden. In diesem Artikel wird erklärt, was der F1 -Score ist, warum er wichtig ist, wie er berechnet wird und seine Anwendungen, Vorteile und Einschränkungen.
Inhaltsverzeichnis
- Was ist eine F1 -Punktzahl?
- Wie berechnet man einen F1 -Score
- F1 -Punktzahl vs. Genauigkeit
- Anwendungen der F1 -Punktzahl
- Vorteile der F1 -Punktzahl
- Einschränkungen der F1 -Punktzahl
Was ist eine F1 -Punktzahl?
ML -Praktiker stehen vor einer gemeinsamen Herausforderung beim Erstellen von Klassifizierungsmodellen: Schulung des Modells, um alle Fälle zu fangen und gleichzeitig Fehlalarme zu vermeiden. Dies ist besonders wichtig bei kritischen Anwendungen wie Erkennung von Finanzbetrug und medizinischer Diagnose, bei denen Fehlalarme und fehlende wichtige Klassifizierungen schwerwiegende Folgen haben. Das Erreichen des richtigen Gleichgewichts ist besonders wichtig, wenn es um unausgeglichene Datensätze geht, bei denen eine Kategorie wie betrügerische Transaktionen viel seltener ist als die andere Kategorie (legitime Transaktionen).
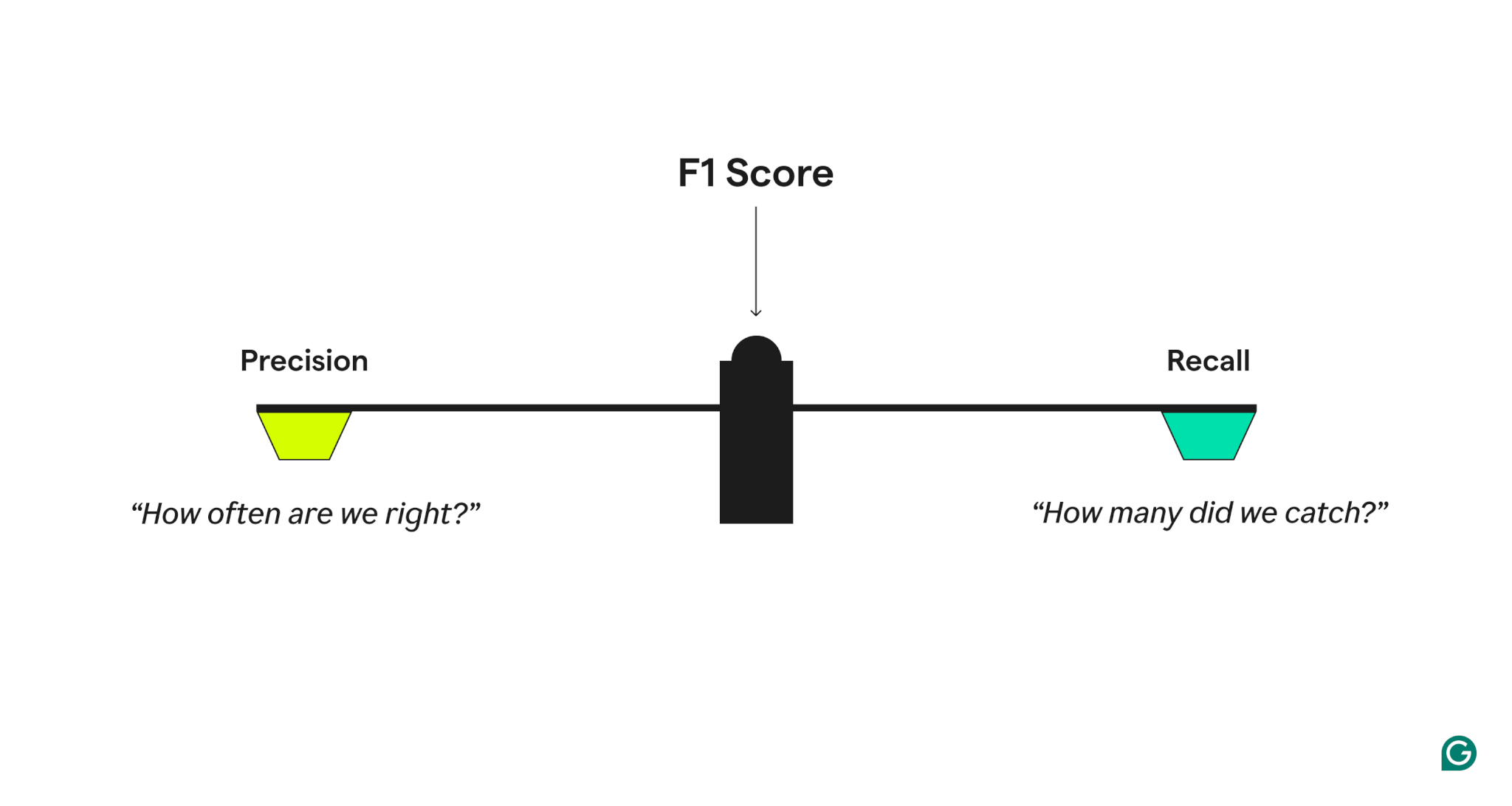
Präzision und Rückruf
Um die Qualität der Modellleistung zu messen, kombiniert der F1 -Score zwei verwandte Metriken:
- Präzision, welche antwortet: „Wenn das Modell einen positiven Fall vorhersagt, wie oft ist es korrekt?“
- Erinnern Sie sich an, welche antwortet: „Von allen tatsächlichen positiven Fällen wurde das Modell korrekt identifiziert?“
Ein Modell mit hoher Präzision, aber geringem Rückruf ist übermäßig vorsichtig und fehlt viele wahre positive Aspekte, während eines mit hoher Rückrufung, aber geringer Präzision übermäßig aggressiv ist und viele falsch positive Ergebnisse erzeugt. Der F1 -Score trifft ein Gleichgewicht, indem er den harmonischen Mittelwert von Präzision und Rückruf einnimmt, was den Werten mehr Gewicht verleiht und sicherstellt, dass ein Modell bei beiden Metriken eine gute Leistung erbringt, anstatt sich in nur einem auszunehmen.
Präzisions- und Rückrufbeispiel
Um Präzision und Rückruf besser zu verstehen, sollten Sie ein Spam -Erkennungssystem in Betracht ziehen. Wenn das System eine hohe korrekte E -Mails als Spam hat, bedeutet dies eine hohe Präzision. Wenn das System beispielsweise 100 E -Mails als Spam und 90 von ihnen tatsächlich Spam sind, beträgt die Präzision 90%. Ein hoher Rückruf hingegen bedeutet, dass das System die meisten tatsächlichen Spam -E -Mails erwischt. Wenn beispielsweise 200 tatsächliche Spam -E -Mails vorhanden sind und unser System 90 davon fängt, beträgt der Rückruf 45%.
Varianten der F1 -Punktzahl
In Multiclas -Klassifizierungssystemen oder Szenarien mit spezifischen Anforderungen kann der F1 -Score auf unterschiedliche Weise berechnet werden, abhängig davon, welche Faktoren wichtig sind:
- MACRO-F1:Berechnet die F1-Punktzahl für jede Klasse separat und nimmt den Durchschnitt an
- MICRO-F1:Berechnet Rückruf und Präzision über alle Vorhersagen
- Gewichtete F1: Ähnlich wie bei MACRO-F1, aber die Klassen werden basierend auf der Frequenz gewichtet
Jenseits der F1-Punktzahl: Die F-Score-Familie
Die F1-Punktzahl ist Teil einer größeren Familie von Metriken, die als F-Scores bezeichnet werden. Diese Ergebnisse bieten unterschiedliche Möglichkeiten, Präzision zu gewichten und zu erinnern:
- F2:legt stärker auf den Rückruf, was nützlich ist, wenn falsch negative kostspielig sind
- F0.5:legt stärker auf Präzision, was nützlich ist, wenn falsch positive Ergebnisse kostspielig sind
Wie berechnet man einen F1 -Score
Der F1 -Score wird mathematisch als harmonisches Mittel von Präzision und Rückruf definiert. Während dies komplex klingen mag, ist der Berechnungsprozess unkompliziert, wenn es in klare Schritte unterteilt ist.
Die Formel für die F1 -Punktzahl:

Bevor Sie in die Schritte zur Berechnung von F1 eintauchen, ist es wichtig, die Schlüsselkomponenten einer sogenanntenVerwirrungsmatrixzu verstehen, mit der die Klassifizierungsergebnisse organisiert werden:
- Richtige positive (TP):Die Anzahl der korrekt identifizierten Fälle als positiv identifiziert
- Fehlalarme Aspekte (FP):Die Anzahl der Fälle, die falsch als positiv identifiziert wurden
- Falsches Negative (FN):Die Anzahl der fehlenden Fälle (tatsächliche positive Identifizierungen, die nicht identifiziert wurden)
Der allgemeine Prozess beinhaltet das Training des Modells, das Testen von Vorhersagen und das Organisieren von Ergebnissen, die Berechnung von Präzision und Rückruf sowie die Berechnung des F1 -Scores.
Schritt 1: Trainieren Sie ein Klassifizierungsmodell
Zunächst muss ein Modell geschult werden, um Binär- oder Multiclas -Klassifizierungen vorzunehmen. Dies bedeutet, dass das Modell in der Lage sein muss, Fälle als zu einer von zwei Kategorien anzugreifen. Beispiele sind "Spam/nicht Spam" und "Betrug/nicht Betrug".
Schritt 2: Testen Sie Vorhersagen und organisieren Sie Ergebnisse
Verwenden Sie als nächstes das Modell, um Klassifikationen in einem separaten Datensatz durchzuführen, das nicht als Teil des Trainings verwendet wurde. Organisieren Sie die Ergebnisse in die Verwirrungsmatrix. Diese Matrix zeigt:
- TP: Wie viele Vorhersagen waren tatsächlich korrekt
- FP: Wie viele positive Vorhersagen waren falsch
- FN: Wie viele positive Fälle wurden übersehen
Die Verwirrungsmatrix bietet einen Überblick über die Leistung des Modells.
Schritt 3: Präzision berechnen
Mit der Verwirrungsmatrix wird mit dieser Formel Präzision berechnet:

Wenn beispielsweise ein SPAM -Erkennungsmodell 90 Spam -E -Mails (TP) korrekt identifiziert, aber fälschlicherweise 10 Nonspam -E -Mails (FP) markiert hat, beträgt die Genauigkeit 0,90.

Schritt 4: Rückruf berechnen
Berechnen Sie als nächstes den Rückruf mit der Formel:

Unter Verwendung des Spam -Erkennungsbeispiels, wenn es 200 Spam -E -Mails insgesamt gab und das Modell 90 von ihnen (TP) fing, während 110 (FN) fehlte, beträgt der Rückruf 0,45.

Schritt 5: Berechnen Sie den F1 -Score
Mit den Präzisions- und Rückrufwerten in der Hand kann der F1 -Score berechnet werden.
Die F1 -Punktzahl reicht von 0 bis 1. Bei der Interpretation der Punktzahl berücksichtigen Sie diese allgemeinen Benchmarks:
- 0,9 oder höher:Das Modell leistet großartig, sollte aber auf Überanpassung überprüft werden.
- 0,7 bis 0,9:gute Leistung für die meisten Anwendungen
- 0,5 bis 0,7:Die Leistung ist in Ordnung, aber das Modell könnte eine Verbesserung verwenden.
- 0,5 oder weniger:Das Modell leistet schlecht und braucht ernsthafte Verbesserungen.
Unter Verwendung der Spam -Erkennungsbeispielberechnungen für Präzision und Rückruf würde der F1 -Score 0,60 oder 60%beträgt.


In diesem Fall zeigt der F1 -Score an, dass der niedrigere Rückruf auch bei hoher Genauigkeit die Gesamtleistung beeinflusst. Dies deutet darauf hin, dass es Raum für Verbesserungen beim Fangen mehr Spam -E -Mails gibt.
F1 -Punktzahl vs. Genauigkeit
Während sowohl F1- als auchGenauigkeitdie Modellleistung quantifizieren, liefert der F1 -Score eine nuanciertere Maßnahme. Die Genauigkeit berechnet einfach den Prozentsatz der korrekten Vorhersagen. Wenn Sie sich jedoch nur auf die Genauigkeit verlassen, um die Modellleistung zu messen, kann jedoch problematisch sein, wenn die Anzahl der Fälle einer Kategorie in einem Datensatz die andere Kategorie erheblich übertroffen hat. Dieses Problem wird alsGenauigkeitsparadoxbezeichnet.
Um dieses Problem zu verstehen, berücksichtigen Sie das Beispiel des Spam -Erkennungssystems. Angenommen, ein E -Mail -System erhält täglich 1.000 E -Mails, aber nur 10 davon sind tatsächlich Spam. Wenn die SPAM -Erkennung einfach jede E -Mail als nicht als Spam klassifiziert, erreicht sie immer noch eine Genauigkeit von 99%. Dies liegt daran, dass 990 Vorhersagen von 1.000 korrekt waren, obwohl das Modell bei der Erkennung von Spam tatsächlich nutzlos ist. Genauigkeit ergibt eindeutig kein genaues Bild der Qualität des Modells.
Der F1 -Score vermeidet dieses Problem, indem die Präzision und Rückrufmessungen kombiniert werden. Daher sollte F1 in den folgenden Fällen anstelle der Genauigkeit verwendet werden:
- Der Datensatz ist unausgeglichen.Dies ist häufig in Bereichen wie der Diagnose von dunklen Erkrankungen oder einer Spam -Erkennung, wobei eine Kategorie relativ selten ist.
- FN und FP sind beide wichtig.Beispielsweise versuchen medizinische Screening -Tests, um tatsächliche Probleme mit der Nichtbeschaffung von Fehlalarmen auszugleichen.
- Das Modell muss ein Gleichgewicht zwischen zu aggressiv und zu vorsichtig sein.Zum Beispiel könnte bei der Spamfilterung ein übermäßig vorsichtiger Filter zu viel Spam (geringer Rückruf) lassen, aber selten Fehler machen (hohe Präzision). Andererseits kann ein übermäßig aggressiver Filter echte E -Mails (geringe Präzision) blockieren, selbst wenn er alle Spam (hoher Rückruf) fängt.
Anwendungen der F1 -Punktzahl
Der F1 -Score verfügt über eine breite Palette von Anwendungen in verschiedenen Branchen, in denen eine ausgewogene Klassifizierung von entscheidender Bedeutung ist. Diese Anwendungen umfassen Erkennung von Finanzbetrug, medizinische Diagnose und Mäßigung des Inhalts.
Erkennung von Finanzbetrug
Modelle zur Erkennung von Finanzbetrug sind eine Kategorie von Systemen, die für die Messung mit dem F1 -Score gut geeignet sind. Finanzunternehmen verarbeiten täglich Millionen oder Milliarden von Transaktionen, wobei tatsächliche Fälle von Betrug relativ selten sind. Aus diesem Grund muss ein Betrugserkennungssystem möglichst viele betrügerische Transaktionen wie möglich fangen und gleichzeitig die Anzahl der Fehlalarme und die daraus resultierenden Unannehmlichkeiten für Kunden minimieren. Durch die Messung des F1 -Scores können Finanzinstitute feststellen, wie gut ihre Systeme die Zwillingssäulen der Betrugsprävention und eines guten Kundenerlebnisses ausgleichen.
Medizinische Diagnose
Bei der medizinischen Diagnose und Prüfung haben FN und FP sowohl schwerwiegende Folgen. Betrachten Sie das Beispiel eines Modells, mit dem seltene Krebsformen erfasst werden sollen. Eine falsche Diagnose eines gesunden Patienten kann zu unnötigem Stress und Behandlung führen, während das Fehlen eines tatsächlichen Krebsfalls schwerwiegende Konsequenzen für den Patienten hat. Mit anderen Worten, das Modell muss sowohl eine hohe Präzision als auch einen hohen Rückruf haben, was die F1 -Punktzahl messen kann.
Inhalts Moderation
Moderierende Inhalte sind eine häufigste Herausforderung in Online -Foren, Social -Media -Plattformen und Online -Marktplätzen. Um die Plattformsicherheit ohne Überzinsoring zu erreichen, müssen diese Systeme Präzision und Rückruf ausgleichen. Der F1 -Score kann Plattformen helfen, zu bestimmen, wie gut ihr System diese beiden Faktoren ausgleichen.
Vorteile der F1 -Punktzahl
Der F1 -Score bietet im Allgemeinen eine nuanciertere Ansicht über die Modellleistung als die Genauigkeit als Genauigkeit, sondern bietet bei der Bewertung der Klassifizierungsmodellleistung mehrere wichtige Vorteile. Zu diesen Vorteilen gehören schnelleres Modelltraining und -optimierung, reduzierte Schulungskosten und das frühzeitige Aufpassen.
Schnelleres Modelltraining und -optimierung
Der F1 -Score kann dazu beitragen, das Modelltraining zu beschleunigen, indem eine klare Referenzmetrik bereitgestellt wird, mit der die Optimierung geleitet werden kann. Anstatt den Rückruf und die Präzision getrennt abzustimmen, was im Allgemeinen komplexe Kompromisse beinhaltet, können sich ML-Praktiker auf die Erhöhung des F1-Scores konzentrieren. Mit diesem optimierten Ansatz können optimale Modellparameter schnell identifiziert werden.
Reduzierte Schulungskosten
Die F1 -Punktzahl kann ML -Praktikern helfen, fundierte Entscheidungen darüber zu treffen, wann ein Modell bereitgestellt wird, indem ein nuanciertes, einziges Maß für die Modellleistung bereitgestellt wird. Mit diesen Informationen können Praktiker unnötige Schulungszyklen, Investitionen in Rechenressourcen und zusätzliche Schulungsdaten erwerben oder erstellen. Insgesamt kann dies bei Schulungsklassifizierungsmodellen zu erheblichen Kostensenkungen führen.
Früh überpitzen
Da der F1 -Score sowohl Präzision als auch Rückruf berücksichtigt, kann er ML -Praktikern helfen, sich zu identifizieren, wann ein Modell zu zu spezifisch auf die Trainingsdaten spezialisiert ist. Dieses Problem, das als Überanpassung bezeichnet wird, ist ein häufiges Problem bei den Klassifizierungsmodellen. Die F1-Partitur gibt den Praktikern eine frühe Warnung, dass sie das Training anpassen müssen, bevor das Modell einen Punkt erreicht, an dem es nicht in der Lage ist, auf reale Daten zu verallgemeinern.
Einschränkungen der F1 -Punktzahl
Trotz seiner vielen Vorteile hat die F1 -Punktzahl mehrere wichtige Einschränkungen, die Praktiker berücksichtigen sollten. Zu diesen Einschränkungen gehören eine mangelnde Sensibilität gegenüber echten Negativen, die für einige Datensätze nicht geeignet sind und für Multiclas -Probleme schwerer zu interpretieren sind.
Mangel an Sensibilität für wahre Negative
Die F1 -Punktzahl berücksichtigt echte Negative nicht, was bedeutet, dass er nicht gut für Anwendungen geeignet ist, bei denen das Messen wichtig ist. Betrachten Sie beispielsweise ein System zur Ermittlung sicherer Fahrbedingungen. In diesem Fall ist es genauso wichtig, dass die korrekten Erkennen, wann die Bedingungen wirklich sicher sind (wahre Negative), genauso wichtig ist wie die Identifizierung gefährlicher Bedingungen. Da es FN nicht verfolgt, würde der F1 -Score diesen Aspekt der Gesamtmodellleistung nicht genau erfassen.
Nicht für einige Datensätze geeignet
Der F1 -Score ist möglicherweise nicht für Datensätze geeignet, bei denen sich die Auswirkungen von FP und FN erheblich unterscheiden. Betrachten Sie das Beispiel eines Krebs -Screening -Modells. In einer solchen Situation könnte das Fehlen eines positiven Falls (FN) lebensbedrohlich sein, während fälschlicherweise ein positiver Fall (FP) gefunden wird, führt nur zu zusätzlichen Tests. Die Verwendung einer Metrik, die gewichtet werden kann, um diese Kosten zu berücksichtigen, ist eine bessere Wahl als die F1 -Punktzahl.
Schwerer zu interpretieren für Multiclas -Probleme
Während Variationen wie Micro-F1 und MACRO-F1-Ergebnisse bedeuten, dass der F1-Score zur Bewertung von Klassifizierungssystemen mit mehreren Klassen verwendet werden kann, ist die Interpretation dieser aggregierten Metriken häufig komplexer als der binäre F1-Score. Beispielsweise könnte der Micro-F1-Score eine schlechte Leistung bei der Klassifizierung weniger häufiger Klassen verbergen, während der MACRO-F1-Score seltene Klassen übergewichtig ist. In Anbetracht dessen müssen Unternehmen überlegen, ob die gleichmäßige Behandlung von Klassen oder Gesamtleistung der Instanzebene bei der Auswahl der richtigen F1-Variante für Klassifizierungsmodelle mit mehreren Klassen wichtiger ist.