
Maschinelles Lernen 101: Was es ist und wie es funktioniert
Veröffentlicht: 2024-05-23Maschinelles Lernen (ML) hat sich schnell zu einer der wichtigsten Technologien unserer Zeit entwickelt. Es liegt Produkten wie ChatGPT, Netflix-Empfehlungen, selbstfahrenden Autos und E-Mail-Spamfiltern zugrunde. Um Ihnen das Verständnis dieser allgegenwärtigen Technologie zu erleichtern, behandelt dieser Leitfaden, was ML ist (und was nicht), wie es funktioniert und welche Auswirkungen es hat.
Inhaltsverzeichnis
- Was ist maschinelles Lernen?
- Wie maschinelles Lernen funktioniert
- Art des maschinellen Lernens
- Anwendungen
- Vorteile
- Nachteile
- Zukunft von ML
- Abschluss
Was ist maschinelles Lernen?
Um maschinelles Lernen zu verstehen, müssen wir zunächst künstliche Intelligenz (KI) verstehen. Obwohl die beiden synonym verwendet werden, sind sie nicht dasselbe. Künstliche Intelligenz ist sowohl ein Ziel als auch ein Forschungsgebiet. Ziel ist es, Computersysteme zu entwickeln, die in der Lage sind, auf menschlicher (oder sogar übermenschlicher) Ebene zu denken und zu argumentieren. KI besteht auch aus vielen verschiedenen Methoden, um dorthin zu gelangen. Maschinelles Lernen ist eine dieser Methoden und damit eine Teilmenge der künstlichen Intelligenz.
Maschinelles Lernen konzentriert sich speziell auf die Nutzung von Daten und Statistiken bei der Verfolgung von KI. Ziel ist es, intelligente Systeme zu schaffen, die durch die Eingabe zahlreicher Beispiele (Daten) lernen können und nicht explizit programmiert werden müssen. Mit genügend Daten und einem guten Lernalgorithmus erkennt der Computer die Muster in den Daten und verbessert seine Leistung.
Im Gegensatz dazu sind Nicht-ML-Ansätze für KI nicht auf Daten angewiesen und verfügen über eine fest codierte Logik. Sie könnten beispielsweise einen Tic-Tac-Toe-KI-Bot mit übermenschlicher Leistung erstellen, indem Sie einfach alle optimalen Bewegungen (die es gibt) einprogrammieren 255.168 mögliche Tic-Tac-Toe-Spiele, es würde also eine Weile dauern, aber es ist immer noch möglich. Es wäre jedoch unmöglich, einen Schach-KI-Bot fest zu programmieren – es gibt mehr mögliche Schachspiele als Atome im Universum. ML würde in solchen Fällen besser funktionieren.
Eine berechtigte Frage an dieser Stelle ist: Wie genau verbessert sich ein Computer, wenn man ihm Beispiele gibt?
Wie maschinelles Lernen funktioniert
In jedem ML-System benötigen Sie drei Dinge: den Datensatz, das ML-Modell (GPT ist ein Beispiel) und den Trainingsalgorithmus. Zunächst übergeben Sie Beispiele aus dem Datensatz. Das Modell sagt dann die richtige Ausgabe für dieses Beispiel voraus. Wenn das Modell falsch ist, verwenden Sie den Trainingsalgorithmus, um die Wahrscheinlichkeit zu erhöhen, dass das Modell für ähnliche Beispiele in der Zukunft richtig ist. Sie wiederholen diesen Vorgang, bis Ihnen die Daten ausgehen oder Sie mit den Ergebnissen zufrieden sind. Sobald Sie diesen Prozess abgeschlossen haben, können Sie Ihr Modell verwenden, um zukünftige Daten vorherzusagen.
Ein einfaches Beispiel für diesen Prozess besteht darin, einem Computer beizubringen, handgeschriebene Ziffern wie die folgenden zu erkennen.
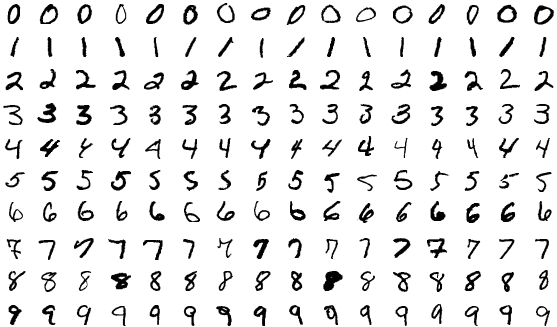
Quelle
Sie sammeln Tausende oder Hunderttausende Bilder von Ziffern. Sie beginnen mit einem ML-Modell, für das es noch keine Beispiele gibt. Sie geben die Bilder in das Modell ein und bitten es, vorherzusagen, welche Zahl seiner Meinung nach im Bild enthalten ist. Es wird eine Zahl zwischen null und neun zurückgegeben, beispielsweise eine Eins. Dann sagen Sie im Wesentlichen: „Diese Zahl ist tatsächlich fünf, nicht eins.“ Der Trainingsalgorithmus aktualisiert das Modell, sodass die Wahrscheinlichkeit höher ist, dass es beim nächsten Mal mit fünf antwortet. Sie wiederholen diesen Vorgang für (fast) alle verfügbaren Bilder und haben im Idealfall ein leistungsstarkes Modell, das Ziffern in 90 % der Fälle richtig erkennen kann. Jetzt können Sie dieses Modell verwenden, um Millionen von Ziffern im großen Maßstab schneller zu lesen, als es ein Mensch könnte. In der Praxis verwendet der United States Postal Service ML-Modelle, um 98 % der handgeschriebenen Adressen zu lesen.
Sie könnten Monate oder Jahre damit verbringen, die Details auch nur eines winzigen Teils dieses Prozesses zu analysieren (schauen Sie sich an, wie viele verschiedene Versionen von Optimierungsalgorithmen es gibt).
Gängige Arten des maschinellen Lernens
Tatsächlich gibt es vier verschiedene Arten maschineller Lernmethoden: überwacht, unüberwacht, halbüberwacht und Verstärkung. Der Hauptunterschied besteht darin, wie ihre Daten gekennzeichnet sind (dh mit oder ohne die richtige Antwort).
Überwachtes Lernen
Überwachte Lernmodelle erhalten gekennzeichnete Daten (mit richtigen Antworten). Das Beispiel handgeschriebener Ziffern fällt in diese Kategorie: Wir können dem Modell sagen: „Fünf ist die richtige Antwort.“ Das Modell zielt darauf ab, die expliziten Zusammenhänge zwischen den Ein- und Ausgängen zu lernen. Diese Modelle können entweder diskrete Bezeichnungen (z. B. „Katze“ oder „Hund“ anhand eines Bildes eines Haustiers vorhersagen) oder Zahlen (z. B. den vorhergesagten Preis eines Hauses anhand der Anzahl der Betten, Bäder, Lage usw.) ausgeben. .
Unbeaufsichtigtes Lernen
Unüberwachte Lernmodelle erhalten unbeschriftete Daten (ohne richtige Antworten). Diese Modelle identifizieren Muster in den Eingabedaten, um die Daten sinnvoll zu gruppieren. Wenn beispielsweise viele Bilder von Katzen und Hunden keine richtige Antwort haben, würde das unbeaufsichtigte ML-Modell Ähnlichkeiten und Unterschiede in den Bildern untersuchen, um Hunde- und Katzenbilder zusammenzufassen. Clustering, Assoziationsregeln und Dimensionsreduktion sind Kernmethoden im unbeaufsichtigten ML.
Halbüberwachtes Lernen
Halbüberwachtes Lernen ist ein maschineller Lernansatz, der zwischen überwachtem und unüberwachtem Lernen liegt. Diese Methode stellt eine erhebliche Menge unbeschrifteter Daten und einen kleineren Satz beschrifteter Daten für das Training des Modells bereit. Zuerst wird das Modell anhand der beschrifteten Daten trainiert und weist dann den unbeschrifteten Daten Beschriftungen zu, indem es deren Ähnlichkeit mit den beschrifteten Daten vergleicht.
Verstärkungslernen
Beim Reinforcement Learning gibt es keine vorgegebenen Beispiele und Bezeichnungen. Stattdessen erhält das Modell eine Umgebung (z. B. Spiele sind üblich), eine Belohnungsfunktion und ein Ziel. Das Modell lernt durch Versuch und Irrtum, das Ziel zu erreichen. Es führt eine Aktion aus und die Belohnungsfunktion teilt ihm mit, ob die Aktion zum Erreichen des übergeordneten Ziels beiträgt. Anschließend aktualisiert sich das Modell selbst, um mehr oder weniger dieser Aktion auszuführen. Das Modell kann lernen, das Ziel zu erreichen, indem es dies mehrmals durchführt.
Ein berühmtes Beispiel für ein Reinforcement-Learning-Modell ist AlphaGo Zero. Dieses Modell wurde darauf trainiert, Go-Spiele zu gewinnen und erhielt nur den Status des Go-Bretts. Anschließend spielte es Millionen von Spielen gegen sich selbst und lernte im Laufe der Zeit, welche Züge ihm Vorteile verschafften und welche nicht. In 70 Stunden Training erreichte er übermenschliche Leistungen und übertraf damit die Go-Weltmeister.
Selbstüberwachtes Lernen
Es gibt tatsächlich eine fünfte Art des maschinellen Lernens, die in letzter Zeit an Bedeutung gewonnen hat: selbstüberwachtes Lernen. Selbstüberwachte Lernmodelle erhalten unbeschriftete Daten, lernen aber, aus diesen Daten Etiketten zu erstellen. Dies liegt den GPT-Modellen hinter ChatGPT zugrunde. Während des GPT-Trainings zielt das Modell darauf ab, das nächste Wort anhand einer eingegebenen Wortfolge vorherzusagen. Nehmen Sie zum Beispiel den Satz „Die Katze saß auf der Matte.“ GPT erhält „The“ und wird gebeten, vorherzusagen, welches Wort als nächstes kommt. Es macht seine Vorhersage (z. B. „Hund“), aber da es den Originalsatz hat, weiß es, was die richtige Antwort ist: „Katze“. Dann erhält GPT „Die Katze“ und wird gebeten, das nächste Wort vorherzusagen, und so weiter. Auf diese Weise können statistische Muster zwischen Wörtern und mehr gelernt werden.
Anwendungen des maschinellen Lernens
Jedes Problem und jede Branche mit vielen Daten kann ML nutzen. Viele Branchen haben dadurch außergewöhnliche Ergebnisse erzielt und es entstehen ständig neue Anwendungsfälle. Hier sind einige häufige Anwendungsfälle von ML:
Schreiben
ML-Modelle unterstützen generative KI-Schreibprodukte wie Grammarly. Durch die Schulung in großen Mengen großartiger Texte kann Grammarly einen Entwurf für Sie erstellen, Ihnen beim Umschreiben und Verfeinern helfen und gemeinsam mit Ihnen Ideen sammeln, alles in Ihrem bevorzugten Ton und Stil.

Spracherkennung
Siri, Alexa und die Sprachversion von ChatGPT basieren alle auf ML-Modellen. Diese Modelle werden anhand vieler Audiobeispiele zusammen mit den entsprechenden korrekten Transkripten trainiert. Mit diesen Beispielen können Modelle Sprache in Text umwandeln. Ohne ML wäre dieses Problem nahezu unlösbar, da jeder unterschiedliche Sprech- und Ausspracheweisen hat. Es wäre unmöglich, alle Möglichkeiten aufzuzählen.
Empfehlungen
Hinter Ihren Feeds auf TikTok, Netflix, Instagram und Amazon stehen ML-Empfehlungsmodelle. Diese Modelle werden auf viele Beispiele von Präferenzen trainiert (z. B. Leute wie Sie mochten diesen Film gegenüber diesem Film, dieses Produkt gegenüber diesem Produkt), um Ihnen Elemente und Inhalte anzuzeigen, die Sie sehen möchten. Mit der Zeit können die Models auch Ihre spezifischen Vorlieben einbeziehen, um einen Feed zu erstellen, der speziell Sie anspricht.
Entdeckung eines Betruges
Banken nutzen ML-Modelle, um Kreditkartenbetrug aufzudecken. E-Mail-Anbieter nutzen ML-Modelle, um Spam-E-Mails zu erkennen und umzuleiten. Betrugs-ML-Modellen werden viele Beispiele für betrügerische Daten gegeben; Diese Modelle lernen dann Muster in den Daten, um Betrug in der Zukunft zu erkennen.
Selbstfahrende Autos
Selbstfahrende Autos nutzen ML, um die Straßen zu interpretieren und zu navigieren. ML hilft den Autos, Fußgänger und Fahrspuren zu identifizieren, die Bewegung anderer Autos vorherzusagen und über ihre nächste Aktion zu entscheiden (z. B. schneller fahren, die Spur wechseln usw.). Selbstfahrende Autos werden durch das Training an Milliarden von Beispielen mit diesen ML-Methoden leistungsfähiger.
Vorteile des maschinellen Lernens
Wenn ML gut gemacht wird, kann es transformativ sein. ML-Modelle können Prozesse im Allgemeinen billiger, besser oder beides machen.
Arbeitskosteneffizienz
Geschulte ML-Modelle können die Arbeit eines Experten zu einem Bruchteil der Kosten simulieren. Ein menschlicher Immobilienmakler hat beispielsweise ein gutes Gespür dafür, wie viel ein Haus kostet, aber das kann jahrelange Schulung erfordern. Auch die Beauftragung erfahrener Immobilienmakler (und Experten jeglicher Art) ist teuer. Ein anhand von Millionen von Beispielen trainiertes ML-Modell könnte jedoch der Leistung eines erfahrenen Immobilienmaklers näher kommen. Ein solches Modell könnte innerhalb weniger Tage trainiert werden und würde nach dem Training deutlich weniger Kosten verursachen. Weniger erfahrene Makler können diese Modelle dann nutzen, um mehr Arbeit in kürzerer Zeit zu erledigen.
Zeiteffizienz
ML-Modelle unterliegen nicht wie Menschen zeitlichen Einschränkungen. AlphaGo Zero hatin drei Trainingstagen4,9 Millionen Go-Spiele gespielt. Dies würde einen Menschen Jahre, wenn nicht Jahrzehnte dauern. Aufgrund dieser Skalierbarkeit war das Modell in der Lage, eine Vielzahl von Go-Bewegungen und -Positionen zu erkunden, was zu übermenschlichen Leistungen führte. ML-Modelle können sogar Muster aufgreifen, die Experten übersehen; AlphaGo Zero hat sogar Bewegungen gefunden und verwendet, die normalerweise nicht von Menschen ausgeführt werden. Das bedeutet jedoch nicht, dass Experten nicht mehr wertvoll sind; Go-Experten sind viel besser geworden, indem sie Modelle wie AlphaGo verwenden, um neue Strategien auszuprobieren.
Nachteile des maschinellen Lernens
Natürlich hat die Verwendung von ML-Modellen auch Nachteile. Sie sind nämlich teuer in der Ausbildung und ihre Ergebnisse sind nicht leicht zu erklären.
Teure Ausbildung
ML-Training kann teuer werden. Beispielsweise kostete die Entwicklung von AlphaGo Zero 25 Millionen US-Dollar und die Entwicklung von GPT-4 mehr als 100 Millionen US-Dollar. Die Hauptkosten für die Entwicklung von ML-Modellen sind Datenkennzeichnung, Hardwarekosten und Mitarbeitergehälter.
Großartige überwachte ML-Modelle erfordern Millionen beschrifteter Beispiele, von denen jedes von einem Menschen beschriftet werden muss. Sobald alle Etiketten gesammelt sind, ist spezielle Hardware erforderlich, um das Modell zu trainieren. Grafikprozessoren (GPUs) und Tensorprozessoren (TPUs) sind der Standard für ML-Hardware und können teuer in der Miete oder im Kauf sein – der Kauf von GPUs kann zwischen Tausenden und Zehntausenden Dollar kosten.
Schließlich erfordert die Entwicklung hervorragender ML-Modelle die Einstellung von Forschern oder Ingenieuren für maschinelles Lernen, die aufgrund ihrer Fähigkeiten und ihres Fachwissens hohe Gehälter verlangen können.
Eingeschränkte Klarheit bei der Entscheidungsfindung
Bei vielen ML-Modellen ist unklar, warum sie die erzielten Ergebnisse liefern. AlphaGo Zero kann die Gründe für seine Entscheidung nicht erklären; Es weiß, dass ein Umzug in einer bestimmten Situation funktionieren wird, weiß aber nicht,warum. Dies kann erhebliche Konsequenzen haben, wenn ML-Modelle in Alltagssituationen eingesetzt werden. Im Gesundheitswesen verwendete ML-Modelle können zu falschen oder verzerrten Ergebnissen führen, und wir wissen es möglicherweise nicht, weil der Grund für die Ergebnisse unklar ist. Verzerrungen sind im Allgemeinen ein großes Problem bei ML-Modellen, und mangelnde Erklärbarkeit macht es schwieriger, mit dem Problem umzugehen. Diese Probleme gelten insbesondere für Deep-Learning-Modelle. Deep-Learning-Modelle sind ML-Modelle, die mehrschichtige neuronale Netze zur Verarbeitung der Eingabe verwenden. Sie sind in der Lage, mit komplizierteren Daten und Fragen umzugehen.
Andererseits weisen einfachere, „flachere“ ML-Modelle (wie Entscheidungsbäume und Regressionsmodelle) nicht die gleichen Nachteile auf. Sie benötigen immer noch viele Daten, sind aber ansonsten kostengünstig zu trainieren. Sie sind auch besser erklärbar. Der Nachteil besteht darin, dass der Nutzen solcher Modelle eingeschränkt sein kann; Fortgeschrittene Anwendungen wie GPT erfordern komplexere Modelle.
Zukunft des maschinellen Lernens
Transformer-basierte ML-Modelle liegen seit einigen Jahren voll im Trend. Dies ist der spezifische ML-Modelltyp, der GPT (das T in GPT), Grammarly und Claude AI unterstützt. Auch diffusionsbasierte ML-Modelle, die Bilderzeugungsprodukte wie DALL-E und Midjourney antreiben, haben Aufmerksamkeit erregt.
Dieser Trend scheint sich so schnell nicht zu ändern. ML-Unternehmen konzentrieren sich darauf, die Größe ihrer Modelle zu vergrößern – größere Modelle mit besseren Fähigkeiten und größeren Datensätzen, auf denen sie trainieren können. GPT-4 hatte beispielsweise zehnmal mehr Modellparameter als GPT-3. Wir werden wahrscheinlich sehen, dass noch mehr Branchen generative KI in ihren Produkten verwenden, um personalisierte Erlebnisse für Benutzer zu schaffen.
Auch die Robotik nimmt Fahrt auf. Forscher nutzen ML, um Roboter zu entwickeln, die Objekte wie Menschen bewegen und nutzen können. Diese Roboter können in ihrer Umgebung experimentieren und verstärkendes Lernen nutzen, um sich schnell anzupassen und ihre Ziele zu erreichen – zum Beispiel, wie man einen Fußball kickt.
Da ML-Modelle jedoch immer leistungsfähiger und allgegenwärtiger werden, bestehen Bedenken hinsichtlich ihrer möglichen Auswirkungen auf die Gesellschaft. Themen wie Voreingenommenheit, Privatsphäre und Arbeitsplatzverdrängung werden heiß diskutiert, und die Notwendigkeit ethischer Richtlinien und verantwortungsvoller Entwicklungspraktiken wird zunehmend anerkannt.
Abschluss
Maschinelles Lernen ist eine Teilmenge der KI mit dem ausdrücklichen Ziel, intelligente Systeme zu schaffen, indem man sie aus Daten lernen lässt. Überwachtes, unbeaufsichtigtes, halbüberwachtes und verstärkendes Lernen sind die Haupttypen von ML (neben selbstüberwachtem Lernen). ML ist der Kern vieler neuer Produkte, die heute auf den Markt kommen, wie etwa ChatGPT, selbstfahrende Autos und Netflix-Empfehlungen. Es kann billiger oder besser sein als menschliche Leistung, ist aber gleichzeitig zunächst teuer und weniger erklärbar und steuerbar. Auch ML dürfte in den nächsten Jahren noch beliebter werden.
Es gibt viele Feinheiten bei ML und die Möglichkeiten, etwas zu lernen und einen Beitrag dazu zu leisten, nehmen zu. Insbesondere die Grammarly-Leitfäden zu KI, Deep Learning und ChatGPT können Ihnen dabei helfen, mehr über andere wichtige Teile dieses Bereichs zu erfahren. Darüber hinaus kann Ihnen die Auseinandersetzung mit den Details von ML (z. B. wie Daten gesammelt werden, wie Modelle tatsächlich aussehen und die Algorithmen hinter dem „Lernen“) dabei helfen, es effektiv in Ihre Arbeit zu integrieren.
Da ML weiter wächst – und mit der Erwartung, dass es fast jede Branche erreichen wird – ist es jetzt an der Zeit, Ihre ML-Reise zu beginnen!