
Was ist Überanpassung beim maschinellen Lernen?
Veröffentlicht: 2024-10-15Überanpassung ist ein häufiges Problem, das beim Training von Modellen für maschinelles Lernen (ML) auftritt. Dies kann sich negativ auf die Fähigkeit eines Modells auswirken, über die Trainingsdaten hinaus zu verallgemeinern, was zu ungenauen Vorhersagen in realen Szenarien führen kann. In diesem Artikel untersuchen wir, was Überanpassung ist, wie sie auftritt, welche häufigen Ursachen dahinter stecken und wie sie wirksam erkannt und verhindert werden kann.
Inhaltsverzeichnis
- Was ist Überanpassung?
- Wie Überanpassung auftritt
- Überanpassung vs. Unteranpassung
- Was verursacht Überanpassung?
- So erkennen Sie eine Überanpassung
- So vermeiden Sie eine Überanpassung
- Beispiele für Überanpassung
Was ist Überanpassung?
Überanpassung liegt vor, wenn ein Modell für maschinelles Lernen die zugrunde liegenden Muster und das Rauschen in den Trainingsdaten lernt und sich dadurch übermäßig auf diesen spezifischen Datensatz spezialisiert. Dieser übermäßige Fokus auf die Details der Trainingsdaten führt zu einer schlechten Leistung, wenn das Modell auf neue, unsichtbare Daten angewendet wird, da es nicht über die Daten hinaus, auf denen es trainiert wurde, verallgemeinern kann.
Wie kommt es zu einer Überanpassung?
Überanpassung tritt auf, wenn ein Modell zu viel aus den spezifischen Details und dem Rauschen in den Trainingsdaten lernt, wodurch es übermäßig empfindlich auf Muster reagiert, die für die Generalisierung nicht aussagekräftig sind. Betrachten Sie beispielsweise ein Modell, das erstellt wurde, um die Leistung von Mitarbeitern auf der Grundlage historischer Bewertungen vorherzusagen. Wenn das Modell zu sehr passt, konzentriert es sich möglicherweise zu sehr auf spezifische, nicht verallgemeinerbare Details, wie etwa den einzigartigen Bewertungsstil eines ehemaligen Managers oder besondere Umstände während eines vergangenen Überprüfungszyklus. Anstatt die umfassenderen, bedeutsamen Faktoren zu lernen, die zur Leistung beitragen – wie Fähigkeiten, Erfahrung oder Projektergebnisse –, kann es für das Modell schwierig sein, sein Wissen auf neue Mitarbeiter anzuwenden oder Bewertungskriterien zu entwickeln. Dies führt zu weniger genauen Vorhersagen, wenn das Modell auf Daten angewendet wird, die sich vom Trainingssatz unterscheiden.
Überanpassung vs. Unteranpassung
Im Gegensatz zur Überanpassung tritt eine Unteranpassung auf, wenn ein Modell zu einfach ist, um die zugrunde liegenden Muster in den Daten zu erfassen. Infolgedessen schneidet es sowohl beim Training als auch bei neuen Daten schlecht ab und kann keine genauen Vorhersagen treffen.
Um den Unterschied zwischen Unter- und Überanpassung zu veranschaulichen, stellen Sie sich vor, wir versuchen, die sportliche Leistung anhand des Stressniveaus einer Person vorherzusagen. Wir können die Daten grafisch darstellen und drei Modelle zeigen, die versuchen, diese Beziehung vorherzusagen:

1 Unteranpassung:Im ersten Beispiel verwendet das Modell eine gerade Linie, um Vorhersagen zu treffen, während die tatsächlichen Daten einer Kurve folgen. Das Modell ist zu einfach und erfasst nicht die Komplexität des Zusammenhangs zwischen Stresslevel und sportlicher Leistung. Dadurch sind die Vorhersagen selbst für die Trainingsdaten meist ungenau. Das ist unzureichend.
2Optimale Passform:Das zweite Beispiel zeigt ein Modell, das die richtige Balance findet. Es erfasst den zugrunde liegenden Trend in den Daten, ohne ihn zu verkomplizieren. Dieses Modell lässt sich gut auf neue Daten verallgemeinern, da es nicht versucht, jede kleine Variation in den Trainingsdaten anzupassen, sondern nur das Kernmuster.
3Überanpassung:Im letzten Beispiel verwendet das Modell eine hochkomplexe Wellenkurve, um die Trainingsdaten anzupassen. Während diese Kurve für die Trainingsdaten sehr genau ist, erfasst sie auch zufälliges Rauschen und Ausreißer, die nicht die tatsächliche Beziehung darstellen. Dieses Modell ist überangepasst, da es so genau auf die Trainingsdaten abgestimmt ist, dass es wahrscheinlich schlechte Vorhersagen für neue, unsichtbare Daten macht.
Häufige Ursachen für Überanpassung
Nachdem wir nun wissen, was Überanpassung ist und warum sie auftritt, wollen wir einige häufige Ursachen genauer untersuchen:
- Unzureichende Trainingsdaten
- Ungenaue, fehlerhafte oder irrelevante Daten
- Große Gewichte
- Übertraining
- Die Modellarchitektur ist zu anspruchsvoll
Unzureichende Trainingsdaten
Wenn Ihr Trainingsdatensatz zu klein ist, repräsentiert er möglicherweise nur einige der Szenarien, denen das Modell in der realen Welt begegnet. Während des Trainings passt das Modell möglicherweise gut zu den Daten. Beim Testen mit anderen Daten können jedoch erhebliche Ungenauigkeiten auftreten. Der kleine Datensatz schränkt die Fähigkeit des Modells ein, auf unbekannte Situationen zu verallgemeinern, was es anfällig für eine Überanpassung macht.
Ungenaue, fehlerhafte oder irrelevante Daten
Auch wenn Ihr Trainingsdatensatz groß ist, kann er Fehler enthalten. Diese Fehler können verschiedene Ursachen haben, beispielsweise falsche Angaben der Teilnehmer in Umfragen oder fehlerhafte Sensormesswerte. Wenn das Modell versucht, aus diesen Ungenauigkeiten zu lernen, passt es sich an Muster an, die nicht die wahren zugrunde liegenden Beziehungen widerspiegeln, was zu einer Überanpassung führt.
Große Gewichte
In Modellen für maschinelles Lernen sind Gewichtungen numerische Werte, die die Bedeutung darstellen, die bestimmten Merkmalen in den Daten bei der Erstellung von Vorhersagen zugewiesen wird. Wenn die Gewichte unverhältnismäßig groß werden, kann es zu einer Überanpassung des Modells kommen, wodurch eine übermäßige Empfindlichkeit gegenüber bestimmten Merkmalen, einschließlich Rauschen in den Daten, entsteht. Dies liegt daran, dass das Modell zu sehr auf bestimmte Funktionen angewiesen ist, was seine Fähigkeit zur Verallgemeinerung auf neue Daten beeinträchtigt.
Übertraining
Während des Trainings verarbeitet der Algorithmus Daten in Stapeln, berechnet den Fehler für jeden Stapel und passt die Gewichte des Modells an, um seine Genauigkeit zu verbessern.
Ist es eine gute Idee, das Training so lange wie möglich fortzusetzen? Nicht wirklich! Längeres Training mit denselben Daten kann dazu führen, dass sich das Modell bestimmte Datenpunkte merkt, wodurch seine Fähigkeit zur Verallgemeinerung auf neue oder unbekannte Daten eingeschränkt wird, was den Kern der Überanpassung darstellt. Diese Art der Überanpassung kann durch den Einsatz früher Stopptechniken oder die Überwachung der Modellleistung anhand eines Validierungssatzes während des Trainings abgemildert werden. Wir werden später in diesem Artikel besprechen, wie das funktioniert.
Die Modellarchitektur ist zu komplex
Die Architektur eines maschinellen Lernmodells bezieht sich darauf, wie seine Schichten und Neuronen strukturiert sind und wie sie interagieren, um Informationen zu verarbeiten.

Komplexere Architekturen können detaillierte Muster in den Trainingsdaten erfassen. Diese Komplexität erhöht jedoch die Wahrscheinlichkeit einer Überanpassung, da das Modell möglicherweise auch lernt, Rauschen oder irrelevante Details zu erfassen, die nicht zu genauen Vorhersagen für neue Daten beitragen. Eine Vereinfachung der Architektur oder der Einsatz von Regularisierungstechniken können dazu beitragen, das Risiko einer Überanpassung zu verringern.
So erkennen Sie eine Überanpassung
Das Erkennen einer Überanpassung kann schwierig sein, da während des Trainings möglicherweise alles gut läuft, selbst wenn eine Überanpassung stattfindet. Die Verlust- (oder Fehler-)Rate – ein Maß dafür, wie oft das Modell falsch ist – wird selbst in einem Überanpassungsszenario weiter sinken. Wie können wir also wissen, ob eine Überanpassung stattgefunden hat? Wir brauchen einen zuverlässigen Test.
Eine effektive Methode ist die Verwendung einer Lernkurve, eines Diagramms, das eine Kennzahl namens Verlust verfolgt. Der Verlust stellt die Größe des Fehlers dar, den das Modell macht. Wir verfolgen jedoch nicht nur den Verlust der Trainingsdaten; Wir messen auch den Verlust an unsichtbaren Daten, sogenannten Validierungsdaten. Aus diesem Grund besteht die Lernkurve typischerweise aus zwei Linien: Trainingsverlust und Validierungsverlust.
Wenn der Trainingsverlust wie erwartet weiter abnimmt, der Validierungsverlust jedoch zunimmt, deutet dies auf eine Überanpassung hin. Mit anderen Worten: Das Modell spezialisiert sich übermäßig auf die Trainingsdaten und hat Schwierigkeiten, auf neue, noch nie gesehene Daten zu verallgemeinern. Die Lernkurve könnte etwa so aussehen:
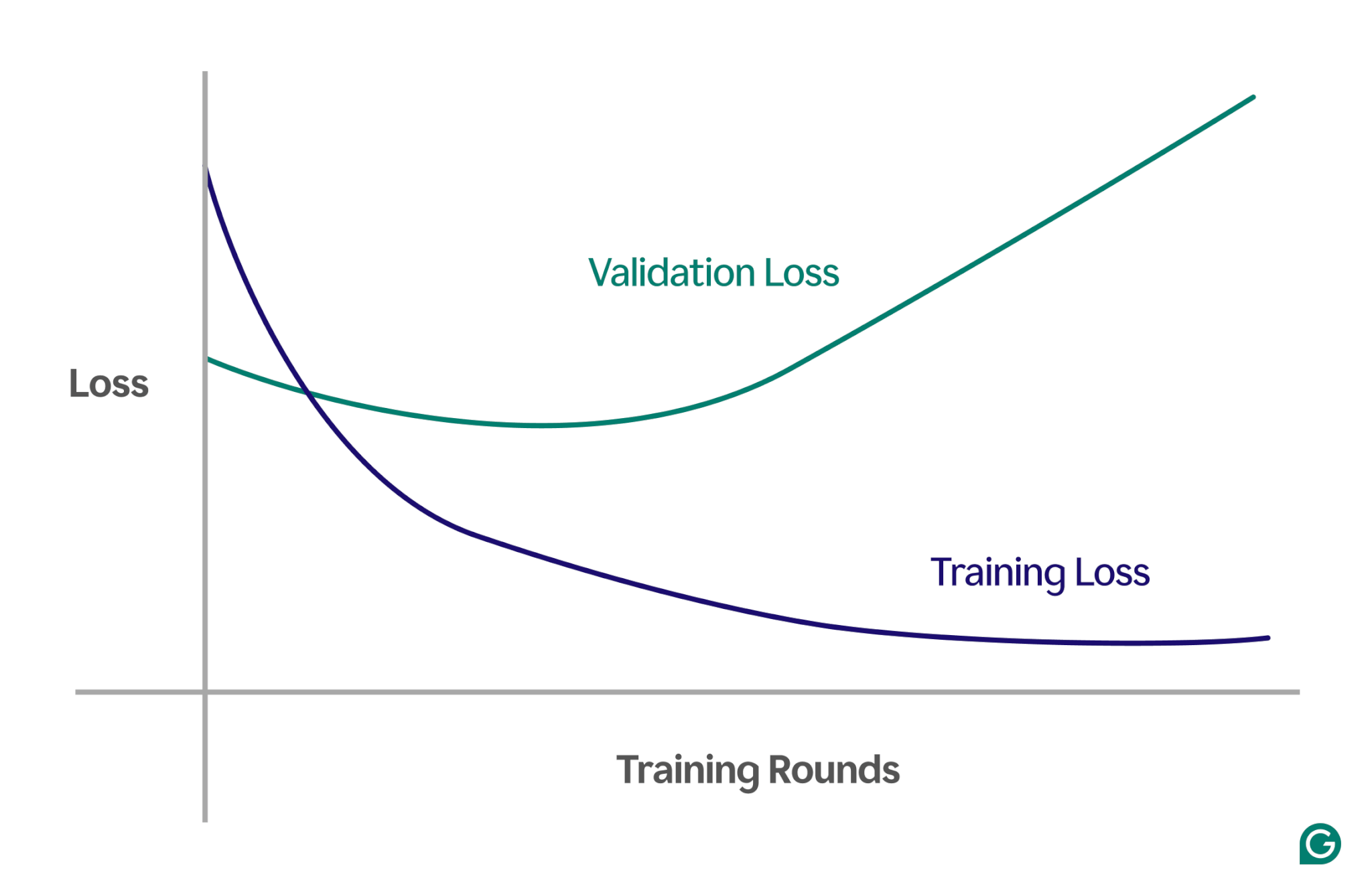
In diesem Szenario verbessert sich das Modell zwar während des Trainings, schneidet jedoch bei nicht sichtbaren Daten schlecht ab. Dies bedeutet wahrscheinlich, dass eine Überanpassung stattgefunden hat.
So vermeiden Sie eine Überanpassung
Überanpassung kann mit verschiedenen Techniken angegangen werden. Hier sind einige der gängigsten Methoden:
Reduzieren Sie die Modellgröße
Bei den meisten Modellarchitekturen können Sie die Anzahl der Gewichte anpassen, indem Sie die Anzahl der Schichten, die Schichtgröße und andere Parameter, die als Hyperparameter bezeichnet werden, ändern. Wenn die Komplexität des Modells zu einer Überanpassung führt, kann eine Reduzierung seiner Größe hilfreich sein. Die Vereinfachung des Modells durch Reduzierung der Anzahl der Schichten oder Neuronen kann das Risiko einer Überanpassung verringern, da das Modell weniger Möglichkeiten hat, sich die Trainingsdaten zu merken.
Regularisieren Sie das Modell
Bei der Regularisierung wird das Modell geändert, um große Gewichte zu verhindern. Ein Ansatz besteht darin, die Verlustfunktion so anzupassen, dass sie den Fehler misst und die Größe der Gewichte berücksichtigt.
Durch die Regularisierung minimiert der Trainingsalgorithmus sowohl den Fehler als auch die Größe der Gewichte und verringert so die Wahrscheinlichkeit großer Gewichte, es sei denn, sie bieten dem Modell einen klaren Vorteil. Dies trägt dazu bei, eine Überanpassung zu verhindern, indem das Modell allgemeiner gehalten wird.
Fügen Sie weitere Trainingsdaten hinzu
Eine Vergrößerung des Trainingsdatensatzes kann auch dazu beitragen, eine Überanpassung zu verhindern. Bei mehr Daten ist es weniger wahrscheinlich, dass das Modell durch Rauschen oder Ungenauigkeiten im Datensatz beeinflusst wird. Wenn das Modell vielfältigeren Beispielen ausgesetzt wird, neigt es weniger dazu, sich einzelne Datenpunkte zu merken und stattdessen umfassendere Muster zu lernen.
Wenden Sie die Dimensionsreduktion an
Manchmal können die Daten korrelierte Merkmale (oder Dimensionen) enthalten, was bedeutet, dass mehrere Merkmale in irgendeiner Weise miteinander verbunden sind. Modelle für maschinelles Lernen behandeln Dimensionen als unabhängig. Wenn also Features korreliert sind, konzentriert sich das Modell möglicherweise zu stark auf sie, was zu einer Überanpassung führt.
Statistische Techniken wie die Hauptkomponentenanalyse (PCA) können diese Korrelationen reduzieren. PCA vereinfacht die Daten, indem es die Anzahl der Dimensionen reduziert und Korrelationen entfernt, wodurch eine Überanpassung weniger wahrscheinlich wird. Durch die Konzentration auf die relevantesten Merkmale kann das Modell besser auf neue Daten verallgemeinert werden.
Praktische Beispiele für Überanpassung
Um die Überanpassung besser zu verstehen, untersuchen wir einige praktische Beispiele aus verschiedenen Bereichen, in denen eine Überanpassung zu irreführenden Ergebnissen führen kann.
Bildklassifizierung
Bildklassifikatoren sollen Objekte in Bildern erkennen – beispielsweise, ob ein Bild einen Vogel oder einen Hund enthält.
Andere Details könnten mit dem korrelieren, was Sie in diesen Bildern erkennen möchten. Beispielsweise ist bei Hundefotos häufig Gras im Hintergrund zu sehen, während bei Vogelfotos häufig ein Himmel oder Baumwipfel im Hintergrund zu sehen sind.
Wenn alle Trainingsbilder über diese konsistenten Hintergrunddetails verfügen, verlässt sich das maschinelle Lernmodell möglicherweise auf den Hintergrund, um das Tier zu erkennen, anstatt sich auf die tatsächlichen Merkmale des Tieres selbst zu konzentrieren. Wenn das Modell daher aufgefordert wird, ein Bild eines auf einem Rasen sitzenden Vogels zu klassifizieren, kann es ihn fälschlicherweise als Hund klassifizieren, da es zu sehr zu den Hintergrundinformationen passt. Hierbei handelt es sich um eine Überanpassung an die Trainingsdaten.
Finanzmodellierung
Nehmen wir an, Sie handeln in Ihrer Freizeit mit Aktien und glauben, dass es möglich ist, Preisbewegungen anhand der Trends der Google-Suche nach bestimmten Schlüsselwörtern vorherzusagen. Sie richten ein maschinelles Lernmodell ein, indem Sie Google Trends-Daten für Tausende von Wörtern verwenden.
Da es so viele Wörter gibt, werden einige wahrscheinlich rein zufällig einen Zusammenhang mit Ihren Aktienkursen aufweisen. Das Modell passt diese zufälligen Korrelationen möglicherweise zu sehr an und macht dadurch schlechte Vorhersagen über zukünftige Daten, da die Wörter keine relevanten Prädiktoren für Aktienkurse sind.
Beim Erstellen von Modellen für Finanzanwendungen ist es wichtig, die theoretischen Grundlagen für die Beziehungen in den Daten zu verstehen. Das Einspeisen großer Datensätze in ein Modell ohne sorgfältige Merkmalsauswahl kann das Risiko einer Überanpassung erhöhen, insbesondere wenn das Modell falsche Korrelationen erkennt, die rein zufällig in den Trainingsdaten vorhanden sind.
Sportlicher Aberglaube
Auch wenn der Aberglaube im Sport nicht unbedingt mit maschinellem Lernen zu tun hat, kann er das Konzept der Überanpassung veranschaulichen – insbesondere, wenn Ergebnisse mit Daten verknüpft sind, die logischerweise keinen Zusammenhang mit dem Ergebnis haben.
Während der UEFA-Fußball-Europameisterschaft 2008 und der FIFA-Weltmeisterschaft 2010 wurde ein Oktopus namens Paul bekanntermaßen eingesetzt, um den Ausgang von Spielen mit Beteiligung Deutschlands vorherzusagen. Im Jahr 2008 hatte Paul vier von sechs Vorhersagen richtig und im Jahr 2010 alle sieben.
Wenn Sie nur die „Trainingsdaten“ von Pauls früheren Vorhersagen berücksichtigen, scheint ein Modell, das mit Pauls Entscheidungen übereinstimmt, die Ergebnisse sehr gut vorherzusagen. Allerdings lässt sich dieses Modell nicht gut auf zukünftige Spiele übertragen, da die Entscheidungen des Oktopus keine verlässlichen Vorhersagen über den Spielausgang darstellen.