
Zufällige Wälder im maschinellen Lernen: Was sie sind und wie sie funktionieren
Veröffentlicht: 2025-02-03Zufällige Wälder sind eine leistungsstarke und vielseitige Technik im maschinellen Lernen (ML). Dieser Leitfaden hilft Ihnen, zufällige Wälder, ihre Arbeit und ihre Anwendungen, Vorteile und Herausforderungen zu verstehen.
Inhaltsverzeichnis
- Was ist ein zufälliger Wald?
- Entscheidungsbäume gegen zufälliger Wald: Was ist der Unterschied?
- Wie zufällige Wälder funktionieren
- Praktische Anwendungen von zufälligen Wäldern
- Vorteile von zufälligen Wäldern
- Nachteile von zufälligen Wäldern
Was ist ein zufälliger Wald?
Ein zufälliger Wald ist ein Algorithmus für maschinelles Lernen, der mehrere Entscheidungsbäume verwendet, um Vorhersagen zu treffen. Es handelt sich um eine überwachte Lernmethode, die sowohl für Klassifizierungs- als auch für Regressionsaufgaben entwickelt wurde. Durch die Kombination der Ausgaben vieler Bäume verbessert ein zufälliger Wald die Genauigkeit, reduziert die Überanpassung und liefert stabilere Vorhersagen im Vergleich zu einem einzelnen Entscheidungsbaum.
Entscheidungsbäume gegen zufälliger Wald: Was ist der Unterschied?
Obwohl zufällige Wälder auf Entscheidungsbäumen basieren, unterscheiden sich die beiden Algorithmen in Struktur und Anwendung signifikant:
Entscheidungsbäume
Ein Entscheidungsbaum besteht aus drei Hauptkomponenten: einem Wurzelknoten, Entscheidungsknoten (interne Knoten) und Blattknoten. Wie ein Flowdiagramm beginnt der Entscheidungsprozess am Wurzelknoten, fließt durch die Entscheidungsknoten basierend auf den Bedingungen und endet an einem Blattknoten, der das Ergebnis darstellt. Während Entscheidungsbäume leicht zu interpretieren und zu konzipieren sind, sind sie auch anfällig für Überanpassungen, insbesondere mit komplexen oder lauten Datensätzen.
Zufällige Wälder
Ein zufälliger Wald ist ein Ensemble von Entscheidungsbäumen, das ihre Ausgaben für verbesserte Vorhersagen kombiniert. Jeder Baum wird auf einer eindeutigen Bootstrap -Probe trainiert (eine zufällig abgetastete Teilmenge des ursprünglichen Datensatzes mit Ersatz) und bewertet Entscheidungsaufteilungen anhand einer zufällig ausgewählten Untergruppe von Merkmalen an jedem Knoten. Dieser als Feature -Bagging bekannte Ansatz führt die Vielfalt unter den Bäumen ein. Durch die Aggregation der Vorhersagen - die Verwendung der Mehrheit der Klassifizierung oder Durchschnittswerte für die Regression -, ergeben die randomischen Wälder genauere und stabilere Ergebnisse als jeder einzelne Entscheidungsbaum im Ensemble.
Wie zufällige Wälder funktionieren
Zufällige Wälder arbeiten, indem mehrere Entscheidungsbäume kombiniert werden, um ein robustes und genaues Vorhersagemodell zu erstellen.
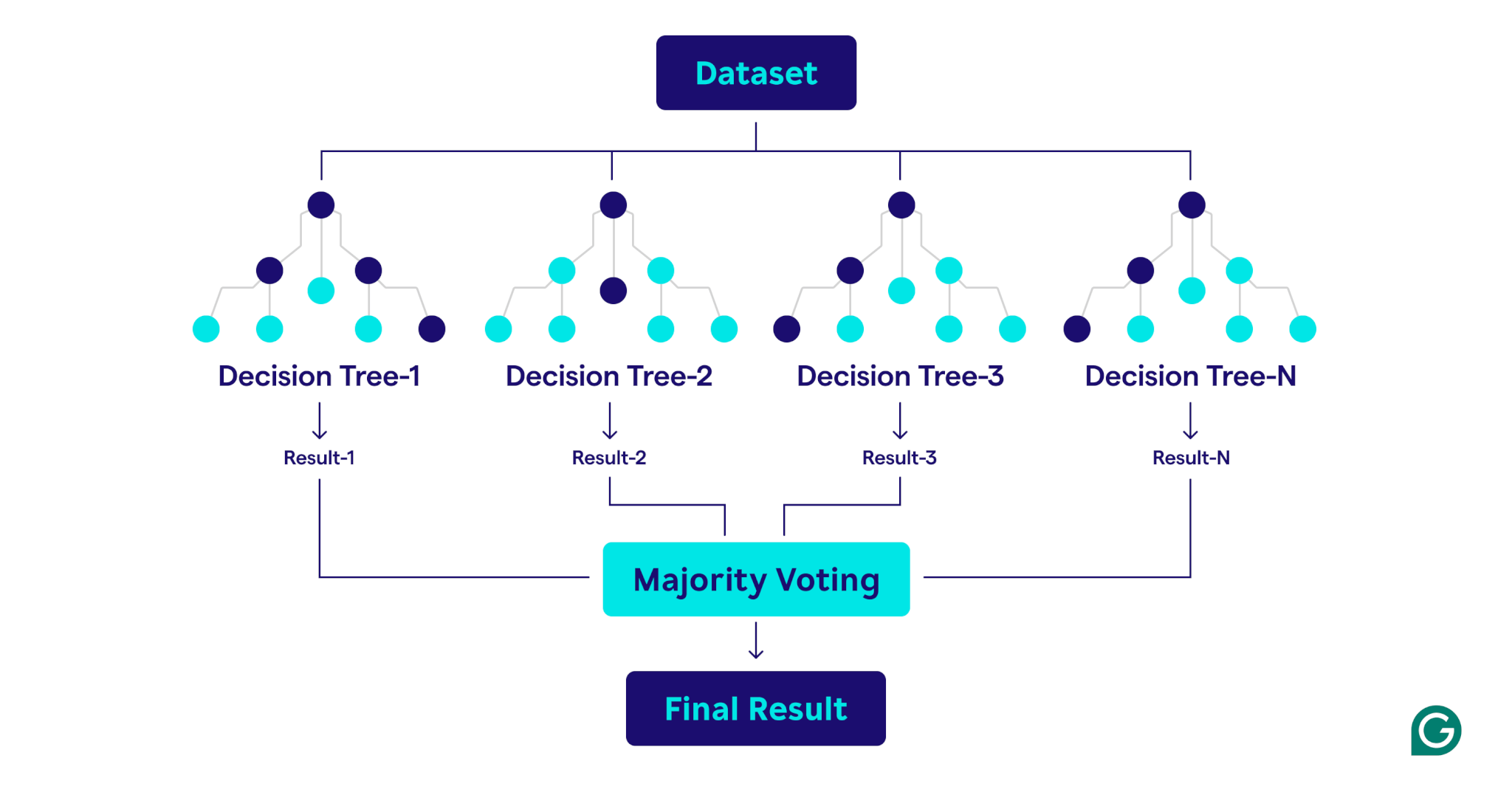
Hier ist eine Schritt-für-Schritt-Erklärung des Prozesses:
1. Einstellen von Hyperparametern
Der erste Schritt besteht darin, die Hyperparameter des Modells zu definieren. Dazu gehören:
- Anzahl der Bäume:Bestimmt die Größe des Waldes
- Maximale Tiefe für jeden Baum:Steuert, wie tief jeder Entscheidungsbaum wachsen kann
- Anzahl der bei jedem geteilten Merkmalen:Begrenzt die Anzahl der bewerteten Merkmale beim Erstellen von Splits
Diese Hyperparameter ermöglichen die Feinabstimmung der Komplexität des Modells und die Optimierung der Leistung für bestimmte Datensätze.
2. Bootstrap -Sampling
Sobald die Hyperparameter festgelegt sind, beginnt der Trainingsprozess mit Bootstrap -Probenahme. Dies beinhaltet:
- Datenpunkte aus dem ursprünglichen Datensatz werden zufällig ausgewählt, um für jeden Entscheidungsbaum Trainingsdatensätze (Bootstrap -Beispiele) zu erstellen.
- Jede Bootstrap-Probe ist in der Regel etwa zwei Drittel der Größe des ursprünglichen Datensatzes, wobei einige Datenpunkte wiederholt und andere ausgeschlossen sind.
- Das verbleibende Drittel der Datenpunkte, die nicht in der Bootstrap-Stichprobe enthalten sind, wird als OB-of-Bag-Daten (OOB) bezeichnet.
3.. Aufbau von Entscheidungsbäumen
Jeder Entscheidungsbaum im zufälligen Wald wird in seiner entsprechenden Bootstrap -Probe unter Verwendung eines einzigartigen Prozesses trainiert:
- Merkmalsbaging:Bei jedem Split wird eine zufällige Untergruppe von Merkmalen ausgewählt, um die Vielfalt zwischen den Bäumen zu gewährleisten.
- Knotenaufteilung:Die beste Funktion aus der Teilmenge wird verwendet, um den Knoten aufzuteilen:
- Für Klassifizierungsaufgaben messen Kriterien wie Gini -Verunreinigungen (ein Maß dafür, wie oft ein zufällig ausgewähltes Element klassifiziert wird, wenn es nach der Verteilung der Klassenbezeichnungen im Knoten zufällig gekennzeichnet würde), wie gut der Split die Klassen trennt.
- Bei Regressionsaufgaben bewerten Techniken wie Varianzreduktion (eine Methode, die misst, wie viel Aufteilung eines Knotens die Varianz der Zielwerte verringert, was zu genaueren Vorhersagen führt), wie stark der Split -Vorhersagefehler reduziert.
- Der Baum wächst rekursiv, bis er die Stoppbedingungen erfüllt, z. B. eine maximale Tiefe oder eine Mindestanzahl von Datenpunkten pro Knoten.
4. Bewertung der Leistung
Während jeder Baum konstruiert wird, wird die Leistung des Modells anhand der OOB -Daten geschätzt:
- Die OOB -Fehlerschätzung liefert ein unvoreingenommenes Maß für die Modellleistung und beseitigt die Notwendigkeit eines separaten Validierungsdatensatzes.
- Durch die Aggregation von Vorhersagen aus allen Bäumen erreicht der zufällige Wald eine verbesserte Genauigkeit und reduziert die Überanpassung im Vergleich zu einzelnen Entscheidungsbäumen.

Praktische Anwendungen von zufälligen Wäldern
Wie die Entscheidungsbäume, auf denen sie gebaut werden, können zufällige Wälder auf Klassifizierung und Regressionsprobleme in einer Vielzahl von Sektoren wie Gesundheitswesen und Finanzen angewendet werden.
Patientenzustände klassifizieren
Im Gesundheitswesen werden zufällige Wälder verwendet, um Patientenerkrankungen auf der Grundlage von Informationen wie Krankengeschichte, Demografie und Testergebnissen zu klassifizieren. Um vorherzusagen, ob ein Patient wahrscheinlich eine bestimmte Erkrankung wie Diabetes entwickelt, klassifiziert jeder Entscheidungsbaum den Patienten als Risiko oder nicht auf relevanten Daten, und der Zufallswald erfolgt die endgültige Bestimmung auf der Grundlage einer Mehrheit. Dieser Ansatz bedeutet, dass zufällige Wälder für die komplexen, featurereichen Datensätze im Gesundheitswesen besonders gut geeignet sind.
Vorhersage von Darlehensausfällen
Banken und große Finanzinstitute verwenden zufällige Wälder weit verbreitet, um die Darlehensberechtigung zu bestimmen und das Risiko besser zu verstehen. Das Modell verwendet Faktoren wie Einkommen und Kredit -Score, um das Risiko zu bestimmen. Da das Risiko als kontinuierlicher numerischer Wert gemessen wird, führt der Zufallswald eine Regression anstelle einer Klassifizierung durch. Jeder Entscheidungsbaum, der auf leicht unterschiedlichen Bootstrap -Proben trainiert wurde, gibt einen vorhergesagten Risikowert aus. Anschließend hat der zufällige Wald alle individuellen Vorhersagen durchschnittlich, was zu einer robusten, ganzheitlichen Risikoschätzung führt.
Vorhersage des Kundenverlusts
Im Marketing werden zufällige Wälder häufig verwendet, um die Wahrscheinlichkeit eines Kunden vorherzusagen, der die Verwendung eines Produkts oder einer Dienstleistung einstellt. Dies beinhaltet die Analyse von Kundenverhaltensmustern wie Kaufhäufigkeiten und Interaktionen mit dem Kundenservice. Durch die Identifizierung dieser Muster können zufällige Wälder Kunden klassifizieren, aus denen das Risiko eines Verlassens besteht. Mit diesen Erkenntnissen können Unternehmen proaktive, datengesteuerte Schritte unternehmen, um Kunden zu behalten, z. B. das Anbieten von Treueprogrammen oder gezielten Werbeaktionen.
Vorhersage von Immobilienpreisen
Zufällige Wälder können verwendet werden, um Immobilienpreise vorherzusagen, was eine Regressionsaufgabe ist. Um die Vorhersage zu machen, verwendet der zufällige Wald historische Daten, die Faktoren wie geografische Lage, Quadratmeterzahl und jüngste Verkäufe in der Region enthalten. Der Mittelwertverfahren des Zufallswaldes führt zu einer zuverlässigeren und stabileren Preisvorhersage als die eines einzelnen Entscheidungsbaums, was auf den hochvolatilen Immobilienmärkten nützlich ist.
Vorteile von zufälligen Wäldern
Zufällige Wälder bieten zahlreiche Vorteile, einschließlich Genauigkeit, Robustheit, Vielseitigkeit und der Fähigkeit, die Bedeutung der Merkmale abzuschätzen.
Genauigkeit und Robustheit
Zufällige Wälder sind genauer und robuster als einzelne Entscheidungsbäume. Dies wird erreicht, indem die Ausgaben mehrerer Entscheidungsbäume kombiniert werden, die auf verschiedenen Bootstrap -Proben des ursprünglichen Datensatzes geschult sind. Die daraus resultierende Vielfalt bedeutet, dass zufällige Wälder weniger anfällig für Überanpassung sind als einzelne Entscheidungsbäume. Dieser Ensemble -Ansatz bedeutet, dass zufällige Wälder auch in komplexen Datensätzen gut mit lauten Daten umgehen können.
Vielseitigkeit
Wie die Entscheidungsbäume, auf denen sie gebaut werden, sind zufällige Wälder sehr vielseitig. Sie können sowohl Regressions- als auch Klassifizierungsaufgaben erledigen, wodurch sie für eine Vielzahl von Problemen anwendbar sind. Zufällige Wälder funktionieren auch gut mit großen, featurereichen Datensätzen und können sowohl numerische als auch kategoriale Daten verarbeiten.
Wichtigkeit aufweisen
Zufällige Wälder haben eine integrierte Fähigkeit, die Bedeutung bestimmter Merkmale zu schätzen. Im Rahmen des Trainingsprozesses geben zufällige Wälder eine Punktzahl aus, die misst, wie stark die Genauigkeit des Modells ändert, wenn ein bestimmtes Merkmal entfernt wird. Durch die Mittelung der Bewertungen für jedes Merkmal können zufällige Wälder ein quantifizierbares Maß für die Merkmals Bedeutung liefern. Weniger wichtige Merkmale können dann entfernt werden, um effizientere Bäume und Wälder zu erzeugen.
Nachteile von zufälligen Wäldern
Während zufällige Wälder viele Vorteile bieten, sind sie schwerer zu interpretieren und teurer zu trainieren als ein einzelner Entscheidungsbaum, und sie können langsamer Vorhersagen als andere Modelle ausgeben.
Komplexität
Während zufällige Wälder und Entscheidungsbäume viel gemeinsam haben, sind zufällige Wälder schwerer zu interpretieren und zu visualisieren. Diese Komplexität entsteht, weil zufällige Wälder Hunderte oder Tausende von Entscheidungsbäumen verwenden. Die „Black Box“ -Fature von zufälligen Wäldern ist ein schwerwiegender Nachteil, wenn die Erklärung des Modells eine Voraussetzung ist.
Rechenkosten
Das Training von Hunderten oder Tausenden von Entscheidungsbäumen erfordert viel mehr Verarbeitungsleistung und Gedächtnis als einen einzigen Entscheidungsbaum. Wenn große Datensätze beteiligt sind, können die Rechenkosten sogar noch höher sein. Diese große Ressourcenanforderung kann zu höheren Geldkosten und längeren Trainingszeiten führen. Infolgedessen sind zufällige Wälder in Szenarien wie Edge Computing möglicherweise nicht praktisch, in denen sowohl Berechnungsleistung als auch Speicher knapp sind. Zufällige Wälder können jedoch parallelisiert werden, was dazu beitragen kann, die Berechnungskosten zu senken.
Langsamere Vorhersagezeit
Der Vorhersageprozess eines zufälligen Waldes beinhaltet das Durchqueren jedes Baumes im Wald und die Aggregation ihrer Ausgaben, was von Natur aus langsamer ist als die Verwendung eines einzelnen Modells. Dieser Prozess kann zu langsameren Vorhersageszeiten führen als einfachere Modelle wie logistische Regression oder neuronale Netzwerke, insbesondere für große Wälder, die tiefe Bäume enthalten. Für Anwendungsfälle, in denen Zeit im Wesentlichen ist, wie z. B. Hochfrequenzhandel oder autonome Fahrzeuge, kann diese Verzögerung unerschwinglich sein.