
Was ist Underfitting beim maschinellen Lernen?
Veröffentlicht: 2024-10-16Unteranpassung ist ein häufiges Problem, das bei der Entwicklung von Modellen für maschinelles Lernen (ML) auftritt. Es tritt auf, wenn ein Modell nicht in der Lage ist, effektiv aus den Trainingsdaten zu lernen, was zu einer unterdurchschnittlichen Leistung führt. In diesem Artikel untersuchen wir, was Unteranpassung ist, wie sie auftritt und welche Strategien es gibt, um sie zu vermeiden.
Inhaltsverzeichnis
- Was ist Unteranpassung?
- Wie es zu einer Unteranpassung kommt
- Unteranpassung vs. Überanpassung
- Häufige Ursachen für Unteranpassung
- So erkennen Sie eine Unteranpassung
- Techniken zur Vermeidung von Unteranpassung
- Praktische Beispiele für Unteranpassung
Was ist Unteranpassung?
Von einer Unteranpassung spricht man, wenn ein maschinelles Lernmodell die zugrunde liegenden Muster in den Trainingsdaten nicht erfasst, was zu einer schlechten Leistung sowohl bei den Trainings- als auch bei den Testdaten führt. Wenn dies auftritt, bedeutet dies, dass das Modell zu einfach ist und die wichtigsten Beziehungen der Daten nicht gut darstellen kann. Infolgedessen hat das Modell Schwierigkeiten, genaue Vorhersagen für alle Daten zu treffen, sowohl für die während des Trainings gesehenen Daten als auch für alle neuen, unsichtbaren Daten.
Wie kommt es zu einer Unteranpassung?
Eine Unteranpassung tritt auf, wenn ein Algorithmus für maschinelles Lernen ein Modell erstellt, das die wichtigsten Eigenschaften der Trainingsdaten nicht erfasst. Modelle, die auf diese Weise versagen, gelten als zu einfach. Stellen Sie sich zum Beispiel vor, Sie verwenden eine lineare Regression, um Verkäufe basierend auf Marketingausgaben, Kundendemografie und Saisonalität vorherzusagen. Bei der linearen Regression wird davon ausgegangen, dass die Beziehung zwischen diesen Faktoren und dem Umsatz als eine Mischung aus geraden Linien dargestellt werden kann.
Obwohl die tatsächliche Beziehung zwischen Marketingausgaben und Verkäufen gekrümmt sein oder mehrere Interaktionen umfassen kann (z. B. der Umsatz steigt zunächst schnell an und stagniert dann), wird das lineare Modell zu stark vereinfacht, indem eine gerade Linie gezeichnet wird. Diese Vereinfachung lässt wichtige Nuancen außer Acht, was zu schlechten Vorhersagen und einer schlechten Gesamtleistung führt.
Dieses Problem tritt häufig bei vielen ML-Modellen auf, bei denen eine hohe Verzerrung (starre Annahmen) das Modell daran hindert, wesentliche Muster zu lernen, was dazu führt, dass es sowohl bei den Trainings- als auch bei den Testdaten eine schlechte Leistung erbringt. Eine Unteranpassung tritt typischerweise dann auf, wenn das Modell zu einfach ist, um die wahre Komplexität der Daten darzustellen.
Unteranpassung vs. Überanpassung
Bei ML sind Unter- und Überanpassung häufige Probleme, die sich negativ auf die Fähigkeit eines Modells auswirken können, genaue Vorhersagen zu treffen. Das Verständnis des Unterschieds zwischen beiden ist entscheidend für die Erstellung von Modellen, die sich gut auf neue Daten übertragen lassen.
- Eine Unteranpassungtritt auf, wenn ein Modell zu einfach ist und die Schlüsselmuster in den Daten nicht erfassen kann. Dies führt zu ungenauen Vorhersagen sowohl für die Trainingsdaten als auch für neue Daten.
- Überanpassungtritt auf, wenn ein Modell übermäßig komplex wird und nicht nur die wahren Muster, sondern auch das Rauschen in den Trainingsdaten anpasst. Dies führt dazu, dass das Modell beim Trainingssatz gut abschneidet, bei neuen, unbekannten Daten jedoch schlecht.
Um diese Konzepte besser zu veranschaulichen, betrachten Sie ein Modell, das die sportliche Leistung basierend auf dem Stressniveau vorhersagt. Die blauen Punkte im Diagramm stellen die Datenpunkte aus dem Trainingssatz dar, während die Linien die Vorhersagen des Modells nach dem Training mit diesen Daten zeigen. 
1 Unteranpassung:In diesem Fall verwendet das Modell eine einfache gerade Linie, um die Leistung vorherzusagen, obwohl die tatsächliche Beziehung gekrümmt ist. Da die Linie nicht gut zu den Daten passt, ist das Modell zu einfach und kann wichtige Muster nicht erfassen, was zu schlechten Vorhersagen führt. Hierbei handelt es sich um eine Unteranpassung, bei der das Modell nicht in der Lage ist, die nützlichsten Eigenschaften der Daten zu erlernen.
2 Optimale Anpassung:Hier passt das Modell ausreichend gut an die Kurve der Daten an. Es erfasst den zugrunde liegenden Trend, ohne übermäßig empfindlich auf bestimmte Datenpunkte oder Rauschen zu reagieren. Dies ist das gewünschte Szenario, in dem sich das Modell einigermaßen gut verallgemeinern lässt und genaue Vorhersagen für ähnliche, neue Daten treffen kann. Allerdings kann die Verallgemeinerung immer noch eine Herausforderung sein, wenn es um sehr unterschiedliche oder komplexere Datensätze geht.
3 Überanpassung:Im Überanpassungsszenario folgt das Modell nahezu jedem Datenpunkt genau, einschließlich Rauschen und zufälligen Schwankungen in den Trainingsdaten. Während das Modell beim Trainingssatz eine sehr gute Leistung erbringt, ist es zu spezifisch für die Trainingsdaten und daher bei der Vorhersage neuer Daten weniger effektiv. Es lässt sich nur schwer verallgemeinern und wird wahrscheinlich ungenaue Vorhersagen treffen, wenn man es auf unbekannte Szenarien anwendet.
Häufige Ursachen für Unteranpassung
Es gibt viele mögliche Ursachen für eine Unteranpassung. Die vier häufigsten sind:
- Die Modellarchitektur ist zu einfach.
- Schlechte Funktionsauswahl
- Unzureichende Trainingsdaten
- Nicht genug Training
Schauen wir uns diese etwas genauer an, um sie zu verstehen.
Die Modellarchitektur ist zu einfach
Unter Modellarchitektur versteht man die Kombination des zum Trainieren des Modells verwendeten Algorithmus und der Struktur des Modells. Wenn die Architektur zu einfach ist, kann es zu Problemen bei der Erfassung der übergeordneten Eigenschaften der Trainingsdaten kommen, was zu ungenauen Vorhersagen führt.
Wenn ein Modell beispielsweise versucht, eine einzelne gerade Linie zu verwenden, um Daten zu modellieren, die einem gekrümmten Muster folgen, wird die Anpassung durchweg unzureichend sein. Dies liegt daran, dass eine gerade Linie die Beziehung auf hoher Ebene in gekrümmten Daten nicht genau darstellen kann, sodass die Architektur des Modells für diese Aufgabe nicht geeignet ist.
Schlechte Funktionsauswahl
Bei der Funktionsauswahl geht es darum, während des Trainings die richtigen Variablen für das ML-Modell auszuwählen. Beispielsweise könnten Sie einen ML-Algorithmus bitten, das Geburtsjahr, die Augenfarbe, das Alter oder alle drei einer Person zu berücksichtigen, um vorherzusagen, ob eine Person auf einer E-Commerce-Website auf die Schaltfläche „Kaufen“ klickt.
Wenn zu viele Features vorhanden sind oder die ausgewählten Features nicht stark mit der Zielvariablen korrelieren, verfügt das Modell nicht über genügend relevante Informationen, um genaue Vorhersagen zu treffen. Die Augenfarbe ist möglicherweise für die Konvertierung irrelevant und das Alter erfasst weitgehend die gleichen Informationen wie das Geburtsjahr.
Unzureichende Trainingsdaten
Wenn zu wenige Datenpunkte vorhanden sind, passt das Modell möglicherweise nicht richtig, da die Daten die wichtigsten Eigenschaften des Problems nicht erfassen. Dies kann entweder auf einen Mangel an Daten oder auf eine Stichprobenverzerrung zurückzuführen sein, bei der bestimmte Datenquellen ausgeschlossen oder unterrepräsentiert sind, wodurch das Modell daran gehindert wird, wichtige Muster zu lernen.

Nicht genug Training
Das Training eines ML-Modells umfasst die Anpassung seiner internen Parameter (Gewichte) basierend auf der Differenz zwischen seinen Vorhersagen und den tatsächlichen Ergebnissen. Je mehr Trainingsiterationen das Modell durchläuft, desto besser kann es sich an die Daten anpassen. Wenn das Modell mit zu wenigen Iterationen trainiert wird, hat es möglicherweise nicht genügend Möglichkeiten, aus den Daten zu lernen, was zu einer Unteranpassung führt.
So erkennen Sie eine Unteranpassung
Eine Möglichkeit, eine Unteranpassung zu erkennen, besteht in der Analyse der Lernkurven, die die Leistung des Modells (typischerweise Verlust oder Fehler) im Vergleich zur Anzahl der Trainingsiterationen darstellen. Eine Lernkurve zeigt, wie sich das Modell im Laufe der Zeit sowohl im Trainings- als auch im Validierungsdatensatz verbessert (oder nicht verbessert).
Der Verlust ist die Größe des Modellfehlers für einen bestimmten Datensatz. Der Trainingsverlust misst dies für die Trainingsdaten und den Validierungsverlust für die Validierungsdaten. Validierungsdaten sind ein separater Datensatz, der zum Testen der Modellleistung verwendet wird. Es wird normalerweise durch zufällige Aufteilung eines größeren Datensatzes in Trainings- und Validierungsdaten erstellt.
Im Falle einer Unteranpassung werden Sie die folgenden Schlüsselmuster bemerken:
- Hoher Trainingsverlust:Wenn der Trainingsverlust des Modells zu Beginn des Prozesses hoch und flach bleibt, deutet dies darauf hin, dass das Modell nicht aus den Trainingsdaten lernt. Dies ist ein klares Zeichen für eine Unteranpassung, da das Modell zu einfach ist, um sich an die Komplexität der Daten anzupassen.
- Ähnlicher Trainings- und Validierungsverlust:Wenn sowohl der Trainings- als auch der Validierungsverlust hoch sind und während des gesamten Trainingsprozesses nahe beieinander bleiben, bedeutet dies, dass das Modell bei beiden Datensätzen eine unterdurchschnittliche Leistung erbringt. Dies weist darauf hin, dass das Modell nicht genügend Informationen aus den Daten erfasst, um genaue Vorhersagen zu treffen, was auf eine Unteranpassung hindeutet.
Nachfolgend finden Sie ein Beispieldiagramm, das Lernkurven in einem Szenario mit unzureichender Anpassung zeigt:
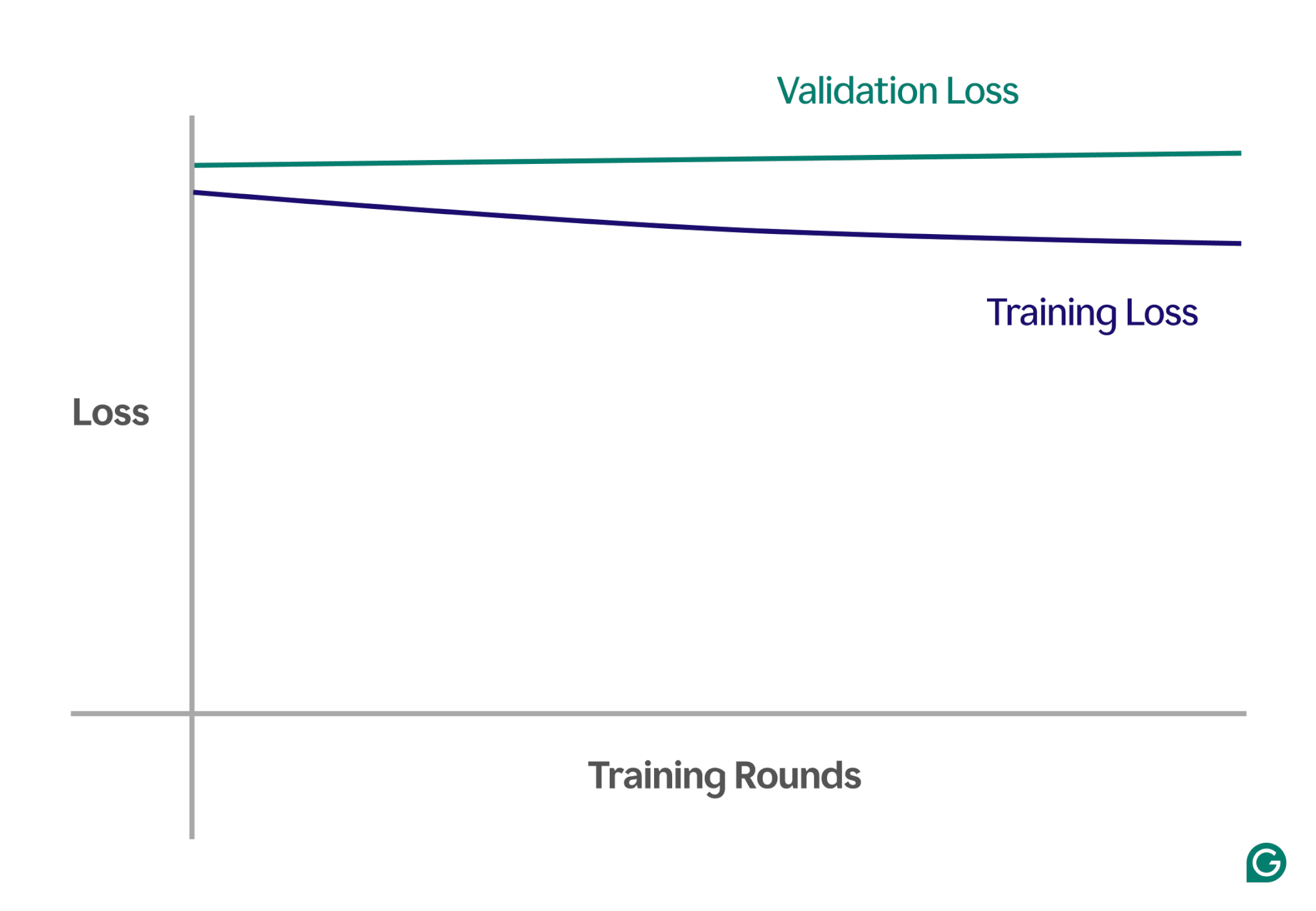
In dieser visuellen Darstellung ist eine Unteranpassung leicht zu erkennen:
- In einem gut passenden Modell nimmt der Trainingsverlust erheblich ab, während der Validierungsverlust einem ähnlichen Muster folgt und sich schließlich stabilisiert.
- In einem unzureichend angepassten Modell beginnen sowohl der Trainings- als auch der Validierungsverlust hoch und bleiben hoch, ohne dass es zu einer wesentlichen Verbesserung kommt.
Durch die Beobachtung dieser Trends können Sie schnell erkennen, ob das Modell zu einfach ist und Anpassungen erforderlich sind, um seine Komplexität zu erhöhen.
Techniken zur Vermeidung von Unteranpassung
Wenn eine Unteranpassung auftritt, gibt es mehrere Strategien, mit denen Sie die Leistung des Modells verbessern können:
- Weitere Trainingsdaten:Besorgen Sie sich nach Möglichkeit zusätzliche Trainingsdaten. Mehr Daten geben dem Modell zusätzliche Möglichkeiten, Muster zu lernen, vorausgesetzt, die Daten sind von hoher Qualität und für das vorliegende Problem relevant.
- Funktionsauswahl erweitern:Fügen Sie relevantere Modellfunktionen hinzu. Wählen Sie Merkmale aus, die eine starke Beziehung zur Zielvariablen haben, um dem Modell eine bessere Chance zu geben, wichtige Muster zu erfassen, die zuvor übersehen wurden.
- Erhöhen Sie die Architekturleistung:In Modellen, die auf neuronalen Netzen basieren, können Sie die Architekturstruktur anpassen, indem Sie die Anzahl der Gewichte, Schichten oder anderer Hyperparameter ändern. Dadurch kann das Modell flexibler sein und die Muster auf hoher Ebene in den Daten leichter finden.
- Wählen Sie ein anderes Modell:Manchmal ist ein bestimmtes Modell auch nach der Optimierung der Hyperparameter möglicherweise nicht gut für die Aufgabe geeignet. Das Testen mehrerer Modellalgorithmen kann dabei helfen, ein geeigneteres Modell zu finden und die Leistung zu verbessern.
Praktische Beispiele für Unteranpassung
Um die Auswirkungen einer Unteranpassung zu veranschaulichen, schauen wir uns Beispiele aus der Praxis in verschiedenen Bereichen an, bei denen Modelle die Komplexität der Daten nicht erfassen können, was zu ungenauen Vorhersagen führt.
Immobilienpreise vorhersagen
Um den Preis eines Hauses genau vorherzusagen, müssen Sie viele Faktoren berücksichtigen, darunter Lage, Größe, Haustyp, Zustand und Anzahl der Schlafzimmer.
Wenn Sie zu wenige Merkmale verwenden, beispielsweise nur die Größe und den Typ des Hauses, hat das Modell keinen Zugriff auf wichtige Informationen. Das Modell könnte beispielsweise davon ausgehen, dass ein kleines Studio günstig ist, ohne zu wissen, dass es sich in Mayfair, London, einer Gegend mit hohen Immobilienpreisen, befindet. Dies führt zu schlechten Vorhersagen.
Um dieses Problem zu lösen, müssen Datenwissenschaftler die richtige Funktionsauswahl sicherstellen. Dabei geht es darum, alle relevanten Funktionen einzubeziehen, irrelevante auszuschließen und genaue Trainingsdaten zu verwenden.
Spracherkennung
Spracherkennungstechnologie ist im täglichen Leben immer häufiger anzutreffen. Beispielsweise nutzen Smartphone-Assistenten, Kundendienst-Hotlines und unterstützende Technologien für Menschen mit Behinderungen alle die Spracherkennung. Beim Training dieser Modelle werden Daten aus Sprachproben und deren korrekte Interpretation verwendet.
Um Sprache zu erkennen, wandelt das Modell von einem Mikrofon erfasste Schallwellen in Daten um. Wenn wir dies vereinfachen, indem wir nur die dominante Frequenz und Lautstärke der Stimme in bestimmten Intervallen angeben, reduzieren wir die Datenmenge, die das Modell verarbeiten muss.
Bei diesem Ansatz werden jedoch wesentliche Informationen weggelassen, die zum vollständigen Verständnis der Rede erforderlich sind. Die Daten werden zu einfach, um die Komplexität der menschlichen Sprache zu erfassen, wie etwa Variationen in Ton, Tonhöhe und Akzent.
Infolgedessen ist das Modell unzureichend und hat Schwierigkeiten, selbst grundlegende Wortbefehle zu erkennen, ganz zu schweigen von vollständigen Sätzen. Selbst wenn das Modell ausreichend komplex ist, führt der Mangel an umfassenden Daten zu einer Unteranpassung.
Bildklassifizierung
Ein Bildklassifikator dient dazu, ein Bild als Eingabe zu verwenden und ein Wort zur Beschreibung auszugeben. Nehmen wir an, Sie erstellen ein Modell, um zu erkennen, ob ein Bild einen Ball enthält oder nicht. Sie trainieren das Modell anhand beschrifteter Bilder von Bällen und anderen Objekten.
Wenn Sie fälschlicherweise ein einfaches zweischichtiges neuronales Netzwerk anstelle eines geeigneteren Modells wie einem Faltungs-Neuronalen Netzwerk (CNN) verwenden, wird das Modell Probleme haben. Das zweischichtige Netzwerk glättet das Bild auf eine einzige Schicht und geht dabei wichtige räumliche Informationen verloren. Darüber hinaus ist das Modell mit nur zwei Schichten nicht in der Lage, komplexe Merkmale zu identifizieren.
Dies führt zu einer Unteranpassung, da das Modell selbst anhand der Trainingsdaten keine genauen Vorhersagen treffen kann. CNNs lösen dieses Problem, indem sie die räumliche Struktur von Bildern bewahren und Faltungsschichten mit Filtern verwenden, die automatisch lernen, wichtige Merkmale wie Kanten und Formen in den frühen Schichten und komplexere Objekte in den späteren Schichten zu erkennen.