
敵対的生成ネットワークの基礎: 知っておくべきこと
公開: 2024-10-08敵対的生成ネットワーク (GAN) は、機械学習 (ML) に多数のアプリケーションを備えた強力な人工知能 (AI) ツールです。このガイドでは、GAN、GAN の仕組み、アプリケーション、利点と欠点について説明します。
目次
- GANとは何ですか?
- GAN 対 CNN
- GAN の仕組み
- GANの種類
- GANの応用
- GAN の利点
- GANの欠点
敵対的生成ネットワークとは何ですか?
敵対的生成ネットワーク (GAN) は、通常教師なし機械学習で使用される深層学習モデルの一種ですが、半教師あり学習や教師あり学習にも適応できます。 GAN は、トレーニング データセットと同様の高品質データを生成するために使用されます。生成 AI のサブセットとして、GAN はジェネレーターとディスクリミネーターの 2 つのサブモデルで構成されます。
1ジェネレーター:ジェネレーターは合成データを作成します。
2ディスクリミネーター:ディスクリミネーターは、トレーニング セットからの実際のデータとジェネレーターによって作成された合成データを区別して、ジェネレーターの出力を評価します。
2 つのモデルは競合します。ジェネレーターはディスクリミネーターをだまして、生成されたデータを本物として分類させようとしますが、ディスクリミネーターは合成データを検出する能力を継続的に向上させます。この敵対的なプロセスは、識別子が実際のデータと生成されたデータを区別できなくなるまで続きます。現時点では、GAN はリアルな画像、ビデオ、その他の種類のデータを生成できます。
GAN 対 CNN
GAN と畳み込みニューラル ネットワーク (CNN) は、深層学習で使用される強力なタイプのニューラル ネットワークですが、使用例とアーキテクチャの点で大きく異なります。
ユースケース
- GAN:トレーニング データに基づいて現実的な合成データを生成することに特化します。このため、GAN は画像生成、画像スタイルの転送、データ拡張などのタスクに適しています。 GAN は教師なしです。つまり、ラベル付きデータが不足している、または利用できないシナリオに適用できます。
- CNN:主に感情分析、トピックの分類、言語翻訳などの構造化データ分類タスクに使用されます。 CNN はその分類能力により、GAN における優れた識別子としても機能します。ただし、CNN は構造化され、人間が注釈を付けたトレーニング データを必要とするため、教師あり学習シナリオに限定されます。
建築
- GAN:競合プロセスに関与する 2 つのモデル (ディスクリミネーターとジェネレーター) で構成されます。ジェネレーターは画像を作成し、ディスクリミネーターはそれらを評価して、ジェネレーターが時間の経過とともにますます現実的な画像を生成するように促します。
- CNN:畳み込み演算とプーリング演算のレイヤーを利用して、画像から特徴を抽出して分析します。この単一モデル アーキテクチャは、データ内のパターンと構造を認識することに重点を置いています。
全体として、CNN は既存の構造化データの分析に重点を置いていますが、GAN は新しい現実的なデータの作成に重点を置いています。
GAN の仕組み
大まかに言うと、GAN は 2 つのニューラル ネットワーク (ジェネレーターとディスクリミネーター) を相互に対抗させることによって機能します。 GAN は、選択されたアーキテクチャが相互に補完する限り、2 つのコンポーネントのいずれにも特定の種類のニューラル ネットワーク アーキテクチャを必要としません。たとえば、CNN が画像生成の識別器として使用される場合、生成器は CNN プロセスを逆に実行する逆畳み込みニューラル ネットワーク (deCNN) になる可能性があります。各コンポーネントには異なる目標があります。
- ジェネレーター:ディスクリミネーターが騙されて本物として分類されるような高品質のデータを生成すること。
- Discriminator:指定されたデータ サンプルを本物 (トレーニング データセットから) または偽物 (ジェネレーターによって生成) として正確に分類すること。
この競争はゼロサム ゲームの実装であり、一方のモデルに与えられる報酬は、もう一方のモデルにとってはペナルティでもあります。ジェネレーターの場合、ディスクリミネーターを騙すことに成功すると、モデルが更新され、現実的なデータを生成する能力が強化されます。逆に、ディスクリミネーターが偽のデータを正しく識別すると、検出機能を向上させるアップデートを受け取ります。数学的には、弁別器は分類誤差を最小限に抑えることを目的とし、生成器は分類誤差を最大化しようとします。
GAN トレーニング プロセス
GAN のトレーニングには、複数のエポックにわたってジェネレーターとディスクリミネーターを交互に繰り返すことが含まれます。エポックとは、データセット全体に対する完全なトレーニングの実行です。このプロセスは、ジェネレーターが約 50% の確率でディスクリミネーターを欺く合成データを生成するまで続きます。どちらのモデルもパフォーマンスの評価と改善に同様のアルゴリズムを使用しますが、更新は独立して行われます。これらの更新は、各モデルの誤差を測定し、パラメーターを調整してパフォーマンスを向上させるバックプロパゲーションと呼ばれる方法を使用して実行されます。次に、最適化アルゴリズムが各モデルのパラメーターを個別に調整します。
以下は、ジェネレーターとディスクリミネーター間の競合を示す GAN アーキテクチャの視覚的表現です。
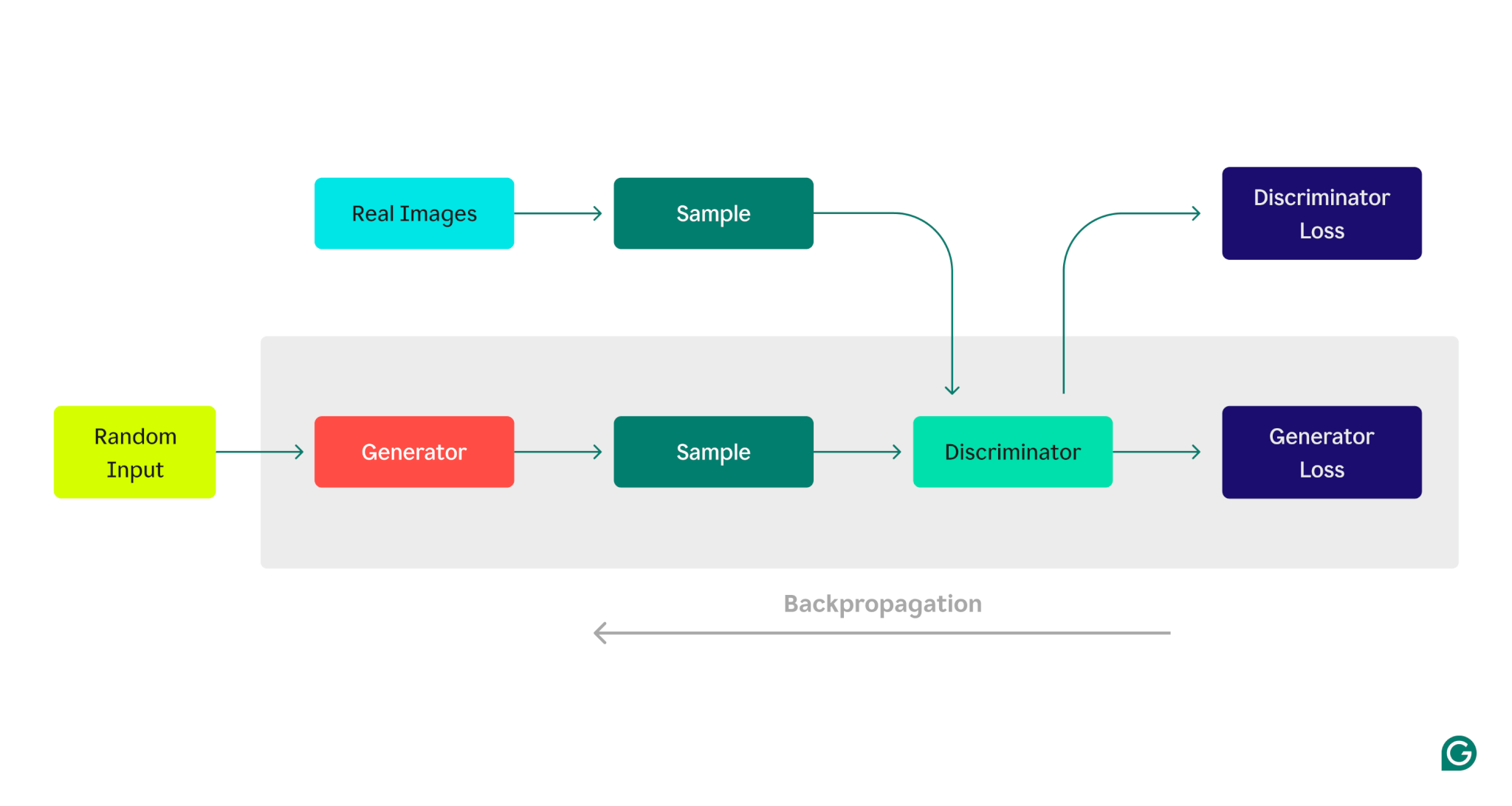
ジェネレーターのトレーニング フェーズ:
1ジェネレーターは、通常、入力としてランダム ノイズから開始してデータ サンプルを作成します。
2ディスクリミネーターは、これらのサンプルを本物 (トレーニング データセットから) または偽物 (ジェネレーターによって生成された) として分類します。
3弁別器の応答に基づいて、逆伝播を使用して生成器パラメータが更新されます。
弁別器トレーニングフェーズ:
1ジェネレーターの現在の状態を使用して偽のデータが生成されます。
2生成されたサンプルは、トレーニング データセットからのサンプルとともに識別器に提供されます。

3バックプロパゲーションを使用すると、識別器のパラメータがその分類パフォーマンスに基づいて更新されます。
この反復トレーニング プロセスは、各モデルのパラメーターがそのパフォーマンスに基づいて調整され、ジェネレーターがディスクリミネーターが実際のデータと確実に区別できないデータを一貫して生成するまで継続されます。
GANの種類
バニラ GAN とよく呼ばれる基本的な GAN アーキテクチャに基づいて、他の特殊なタイプの GAN が開発され、さまざまなタスク向けに最適化されています。最も一般的なバリエーションのいくつかを以下に説明しますが、これは完全なリストではありません。
条件付き GAN (cGAN)
条件付き GAN (cGAN) は、条件と呼ばれる追加情報を使用して、より一般的なデータセットでトレーニングするときにモデルが特定の種類のデータを生成するようにガイドします。条件には、クラス ラベル、テキストベースの説明、またはデータの別のタイプの分類情報を指定できます。たとえば、シャム猫の画像のみを生成する必要があるが、トレーニング データセットにはあらゆる種類の猫の画像が含まれていると想像してください。 cGAN では、トレーニング画像に猫の種類のラベルを付けることができ、モデルはこれを使用してシャム猫の画像のみを生成する方法を学習できます。
ディープ畳み込み GAN (DCGAN)
深層畳み込み GAN (DCGAN) は、画像生成用に最適化されています。 DCGAN では、ジェネレーターはディープ エンベディング畳み込みニューラル ネットワーク (deCNN) であり、ディスクリミネーターはディープ CNN です。 CNN は空間階層とパターンをキャプチャできるため、画像の操作と生成に適しています。 DCGAN のジェネレーターは、アップサンプリングと転置畳み込み層を使用して、多層パーセプトロン (入力特徴を重み付けして意思決定を行う単純なニューラル ネットワーク) が生成するよりも高品質の画像を作成します。同様に、ディスクリミネーターは畳み込み層を使用して画像サンプルから特徴を抽出し、それらを本物か偽物かを正確に分類します。
サイクルガン
CycleGAN は、あるタイプの画像を別のタイプの画像から生成するように設計された GAN の一種です。たとえば、CycleGAN はマウスの画像をラットに、または犬をコヨーテに変換できます。 CycleGAN は、ペアのデータセット、つまりベース画像と目的の変換の両方を含むデータセットでトレーニングすることなく、この画像間の変換を実行できます。この機能は、通常の GAN が使用する 1 つのペアの代わりに、2 つのジェネレーターと 2 つのディスクリミネーターを使用することで実現されます。 CycleGAN では、1 つのジェネレーターがベース画像から変換バージョンに画像を変換し、もう 1 つのジェネレーターが逆方向の変換を実行します。同様に、各識別器は特定の画像タイプをチェックして、それが本物か偽物かを判断します。 CycleGAN は一貫性チェックを使用して、画像を他のスタイルに変換し、元の画像に戻すことを確認します。
GANの応用
GAN はその独特なアーキテクチャにより、さまざまな革新的なユースケースに適用されていますが、そのパフォーマンスは特定のタスクとデータ品質に大きく依存します。より強力なアプリケーションには、テキストから画像への生成、データ拡張、ビデオの生成と操作などがあります。
テキストから画像への生成
GAN はテキストの説明から画像を生成できます。このアプリケーションはクリエイティブ業界で価値があり、著者やデザイナーがテキストで説明されているシーンやキャラクターを視覚化できるようになります。 GAN はそのようなタスクによく使用されますが、OpenAI の DALL-E などの他の生成 AI モデルは、トランスフォーマーベースのアーキテクチャを使用して同様の結果を達成します。
データの増強
GAN は実際のトレーニング データに似た合成データを生成できるため、データ拡張に役立ちますが、精度と現実性の程度は特定のユースケースやモデルのトレーニングによって異なります。この機能は、限られたデータセットを拡張し、モデルのパフォーマンスを向上させるための機械学習において特に価値があります。さらに、GAN はデータのプライバシーを維持するためのソリューションを提供します。医療や金融などの機密分野では、GAN は機密情報を損なうことなく、元のデータセットの統計的特性を保存する合成データを生成できます。
ビデオの生成と操作
GAN は、特定のビデオ生成および操作タスクにおいて有望であることが示されています。たとえば、GAN を使用して初期ビデオ シーケンスから将来のフレームを生成し、歩行者の動きの予測や自動運転車の道路上の危険の予測などのアプリケーションに役立てることができます。ただし、これらのアプリケーションはまだ活発に研究開発中です。 GAN を使用して、完全に合成されたビデオ コンテンツを生成したり、リアルな特殊効果でビデオを強化したりすることもできます。
GAN の利点
GAN には、現実的な合成データの生成、不対データからの学習、教師なしトレーニングの実行など、いくつかの明確な利点があります。
高品質な合成データの生成
GAN のアーキテクチャにより、データ拡張やビデオ作成などのアプリケーションで現実世界のデータに近似できる合成データを生成できますが、このデータの品質と精度はトレーニング条件やモデル パラメーターに大きく依存する可能性があります。たとえば、CNN を利用して最適な画像処理を行う DCGAN は、リアルな画像の生成に優れています。
ペアになっていないデータから学習できる
一部の ML モデルとは異なり、GAN は入力と出力のペアの例がなくてもデータセットから学習できます。この柔軟性により、ペアのデータが不足している、または利用できないような幅広いタスクで GAN を使用できます。たとえば、画像から画像への変換タスクでは、従来のモデルではトレーニングのために画像とその変換のデータセットが必要になることがよくあります。対照的に、GAN は、トレーニングにさまざまな潜在的なデータセットを活用できます。
教師なし学習
GAN は教師なし機械学習手法であり、明示的な指示なしにラベルなしのデータでトレーニングできることを意味します。データのラベル付けは時間とコストがかかるプロセスであるため、これは特に有利です。ラベルなしデータから学習する GAN の機能は、ラベル付きデータが限られている、または取得が困難なアプリケーションにとって価値があります。 GAN は半教師あり学習および教師あり学習にも適応でき、ラベル付きデータも使用できます。
GANの欠点
GAN は機械学習における強力なツールですが、そのアーキテクチャにより特有の一連の欠点が生じます。これらの欠点には、ハイパーパラメータに対する敏感さ、高い計算コスト、収束の失敗、およびモード崩壊と呼ばれる現象が含まれます。
ハイパーパラメータの感度
GAN はハイパーパラメータに敏感です。ハイパーパラメータは、トレーニング前に設定され、データから学習されないパラメータです。例には、ネットワーク アーキテクチャや 1 回の反復で使用されるトレーニング サンプルの数が含まれます。これらのパラメーターのわずかな変更がトレーニング プロセスとモデルの出力に大きな影響を与える可能性があるため、実際のアプリケーションでは広範な微調整が必要になります。
高い計算コスト
GAN は、その複雑なアーキテクチャ、反復トレーニング プロセス、およびハイパーパラメーターの感度により、多くの場合、高い計算コストが発生します。 GAN のトレーニングを成功させるには、特殊で高価なハードウェアと多大な時間が必要であり、これが GAN の利用を検討している多くの組織にとって障壁となる可能性があります。
収束失敗
エンジニアや研究者は、モデルの出力が安定して正確になる収束率と呼ばれる許容可能な速度に達するまで、トレーニング構成の実験にかなりの時間を費やすことがあります。 GAN での収束は達成が非常に難しく、あまり長く続かない可能性があります。収束失敗とは、ディスクリミネーターが本物のデータと偽のデータを十分に判断できない場合であり、トレーニングが成功したときに到達した意図されたバランスとは異なり、本物のデータを識別する能力を獲得していないため、精度が約 50% になります。一部の GAN は収束に達しない可能性があり、修復するには特殊な分析が必要になる場合があります。
モード崩壊
GAN は、ジェネレーターが限られた範囲の出力を作成し、現実世界のデータ分布の多様性を反映できない、モード崩壊と呼ばれる問題を起こしやすいです。この問題は GAN アーキテクチャから発生します。ジェネレーターがディスクリミネーターを欺く可能性のあるデータを生成することに過度に集中し、同様のサンプルを生成するようになるためです。