
機械学習におけるデシジョン ツリーとは何ですか?
公開: 2024-08-14デシジョン ツリーは、データ アナリストの機械学習ツールキットの中で最も一般的なツールの 1 つです。このガイドでは、デシジョン ツリーとは何か、その構築方法、さまざまなアプリケーション、利点などについて学びます。
目次
- 決定木とは何ですか?
- デシジョンツリーの用語
- デシジョンツリーの種類
- デシジョンツリーの仕組み
- アプリケーション
- 利点
- 短所
決定木とは何ですか?
機械学習 (ML) におけるデシジョン ツリーは、フローチャートまたはデシジョン チャートに似た教師あり学習アルゴリズムです。他の多くの教師あり学習アルゴリズムとは異なり、デシジョン ツリーは分類タスクと回帰タスクの両方に使用できます。データ サイエンティストやアナリストは、構築と解釈が簡単なため、新しいデータセットを調査するときにデシジョン ツリーをよく使用します。さらに、デシジョン ツリーは、より複雑な ML アルゴリズムを適用するときに役立つ可能性がある重要なデータ特徴を特定するのに役立ちます。
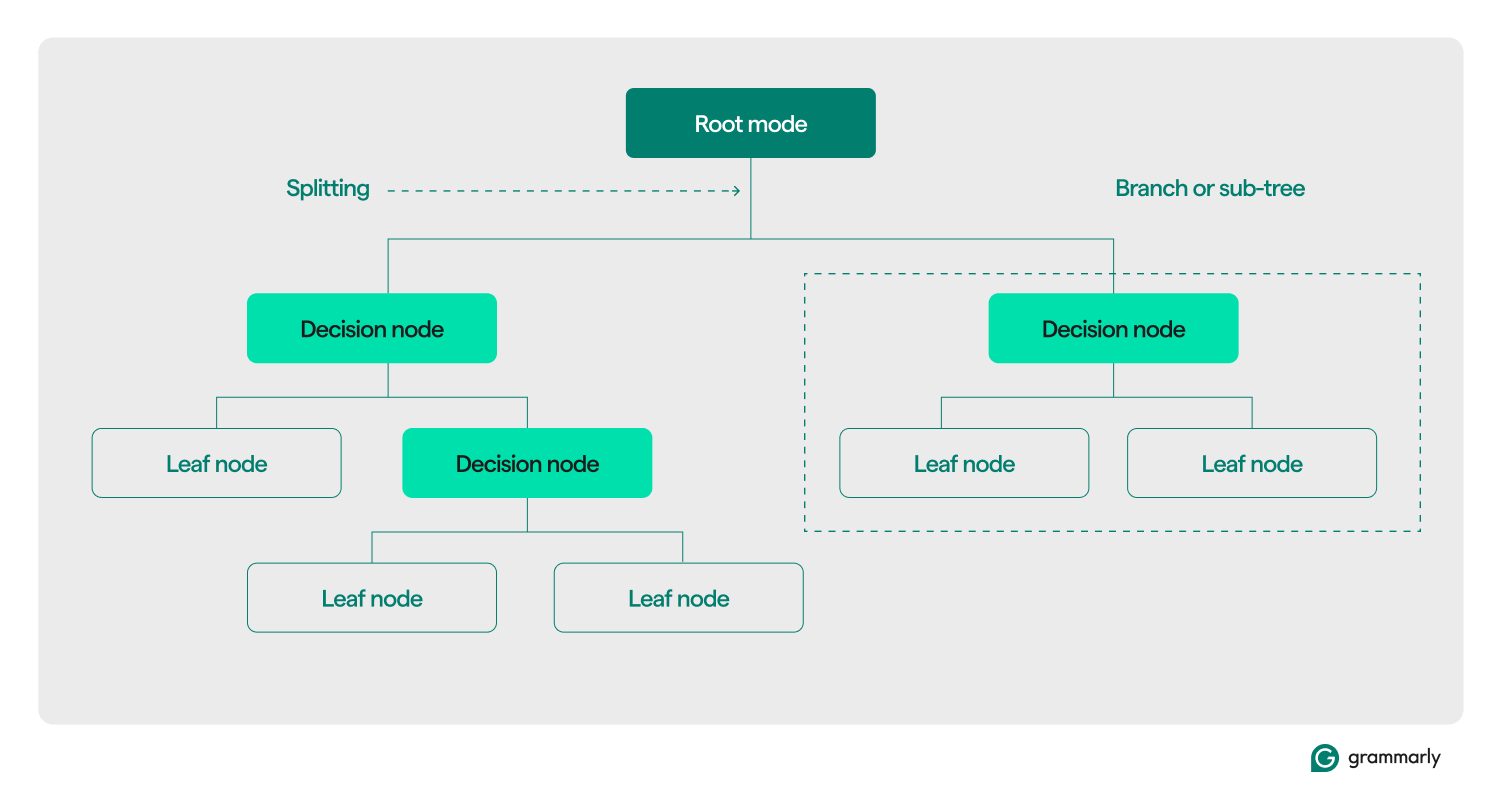
デシジョンツリーの用語
構造的には、デシジョン ツリーは通常、ルート ノード、リーフ ノード、デシジョン (内部) ノードの 3 つのコンポーネントで構成されます。他のドメインのフローチャートやツリーと同様に、ツリー内の意思決定は通常、ルート ノードから始まり、いくつかの意思決定ノードを通過し、特定のリーフ ノードで終了する一方向 (下または上) に移動します。各リーフ ノードは、トレーニング データのサブセットをラベルに接続します。このツリーは ML トレーニングと最適化プロセスを通じて組み立てられ、構築後はさまざまなデータセットに適用できます。
ここでは、残りの用語についてさらに詳しく説明します。
- ルート ノード:デシジョン ツリーがデータに関して尋ねる一連の質問の最初の質問を保持するノード。ノードは少なくとも 1 つ (通常は 2 つ以上) のデシジョン ノードまたはリーフ ノードに接続されます。
- 意思決定ノード (または内部ノード):質問を含む追加のノード。デシジョン ノードにはデータに関する質問が 1 つだけ含まれ、応答に基づいてデータフローがその子の 1 つに送信されます。
- 子:ルートまたはデシジョン ノードが指す 1 つ以上のノード。これらは、意思決定プロセスがデータを分析するときに選択できる次のオプションのリストを表します。
- リーフ ノード (またはターミナル ノード):決定プロセスが完了したことを示すノード。決定プロセスがリーフ ノードに到達すると、リーフ ノードからの値が出力として返されます。
- ラベル (クラス、カテゴリ):一般に、リーフ ノードによってトレーニング データの一部に関連付けられた文字列。たとえば、リーフは、「満足した顧客」というラベルを、デシジョン ツリー ML トレーニング アルゴリズムが提示された一連の特定の顧客に関連付けることができます。
- ブランチ (またはサブツリー):これは、ツリー内の任意の点にある決定ノードと、そのすべての子およびその子から葉ノードに至るまでのノードのセットです。
- 枝刈り:通常、ツリーを小さくし、出力をより速く返すためにツリーに対して実行される最適化操作。枝刈りは通常「事後枝刈り」を指します。これには、ML トレーニング プロセスでツリーが構築された後に、アルゴリズムによってノードや枝を削除することが含まれます。 「事前枝刈り」とは、トレーニング中にデシジョン ツリーがどの程度の深さまたは大きさに成長できるかについて、任意の制限を設定することを指します。どちらのプロセスも、デシジョン ツリーの最大の複雑さを強制します。通常、その複雑さは最大の深さまたは高さによって測定されます。あまり一般的ではない最適化には、決定ノードまたはリーフ ノードの最大数の制限が含まれます。
- 分割:トレーニング中にデシジョン ツリーに対して実行される核となる変換ステップ。これには、ルートまたは決定ノードを 2 つ以上のサブノードに分割することが含まれます。
- 分類: (クラス、カテゴリ、またはラベルの定数および離散リストのうち) どれがデータに適用される可能性が最も高いかを判断しようとする ML アルゴリズム。 「フライトの予約に最適な曜日は何ですか?」などの質問に答えようとする可能性があります。分類については以下で詳しく説明します。
- 回帰:常に限界があるとは限らない、連続値を予測しようとする ML アルゴリズム。 「次の火曜日のフライトを予約する可能性がある人は何人ですか?」などの質問に答えよう (または答えを予測しよう) と試みる可能性があります。次のセクションで回帰ツリーについて詳しく説明します。
デシジョンツリーの種類
デシジョン ツリーは通常、分類ツリーと回帰ツリーの 2 つのカテゴリにグループ化されます。特定のツリーを構築して、分類、回帰、または両方のユースケースに適用できます。最新のデシジョン ツリーのほとんどは、両方のタイプのタスクを実行できる CART (分類および回帰ツリー) アルゴリズムを使用しています。
分類ツリー
最も一般的なタイプの決定ツリーである分類ツリーは、分類問題の解決を試みます。分類ツリーは、提示されたデータについていくつかの質問をした後、質問 (多くの場合「はい」または「いいえ」のような単純なもの) に対する可能な回答のリストから、最も可能性の高い回答を選択します。これらは通常、バイナリ ツリーとして実装されます。つまり、各決定ノードにはちょうど 2 つの子があります。
分類ツリーは、「この顧客は満足していますか?」などの多肢選択式の質問に答えようとする場合があります。または「この顧客が訪れる可能性が高い実店舗はどれですか?」または「明日はゴルフコースに行くのに良い日ですか?」
分類ツリーの品質を測定する最も一般的な 2 つの方法は、情報ゲインとエントロピーに基づきます。
- 情報の獲得:答えに到達する前に質問する質問が少なくなると、ツリーの効率が向上します。情報獲得は、各決定ノードでデータの一部についてどれだけ多くの情報を学習したかを評価することによって、ツリーがどれだけ「早く」答えを得ることができるかを測定します。最も重要で有用な質問がツリーの最初に尋ねられるかどうかを評価します。
- エントロピー:デシジョン ツリーのラベルには精度が非常に重要です。エントロピー メトリクスは、ツリーによって生成されたラベルを評価することによってこの精度を測定します。ランダムなデータに間違ったラベルが付けられる頻度と、同じラベルを受け取るすべてのトレーニング データ間の類似性を評価します。
木の品質のより高度な測定には、ジニ指数、利得比、カイ二乗評価、および分散削減のためのさまざまな測定が含まれます。
回帰木
回帰ツリーは通常、高度な統計分析のための回帰分析、または連続的で潜在的に無制限の範囲からのデータを予測するために使用されます。一連のオプション (実数スケールでの 0 から無限大など) が与えられると、回帰ツリーは一連の質問を行った後、特定のデータに対して最も一致する可能性が高いものを予測しようとします。各質問は、回答の可能性のある範囲を狭めます。たとえば、回帰ツリーは、クレジット スコア、事業部門からの収益、マーケティング ビデオでのインタラクションの数を予測するために使用される場合があります。

回帰ツリーの精度は通常、平均二乗誤差や平均絶対誤差などのメトリクスを使用して評価され、特定の予測セットが実際の値と比較してどれだけ離れているかを計算します。
デシジョンツリーの仕組み
教師あり学習の例として、デシジョン ツリーはトレーニング用に適切にフォーマットされたデータに依存します。通常、ソース データには、モデルが予測または分類するために学習する必要がある値のリストが含まれています。各値にはラベルと関連する特徴のリストが必要です。これらのプロパティは、モデルがラベルに関連付けることを学習する必要があります。
構築またはトレーニング
トレーニング プロセス中、デシジョン ツリー内のデシジョン ノードは、1 つ以上のトレーニング アルゴリズムに従って、より具体的なノードに再帰的に分割されます。このプロセスを人間レベルで説明すると、次のようになります。
- トレーニング セット全体に接続されているルート ノードから始めます。
- ルート ノードを分割する:統計的アプローチを使用して、データ特徴の 1 つに基づいてルート ノードに決定を割り当て、ルートに子として接続された少なくとも 2 つの別々のリーフ ノードにトレーニング データを分散します。
- ステップ 2 を各子に再帰的に適用し、子をリーフ ノードからデシジョン ノードに変換します。何らかの制限に達した場合 (例: ツリーの高さ/深さ、各ノードの各リーフの子の品質の尺度など)、またはデータが不足した場合 (つまり、各リーフにデータが含まれている場合) に停止します。正確に 1 つのラベルに関連するポイント)。
各ノードでどの特徴を考慮するかの決定は、分類、回帰、および分類と回帰の組み合わせのユースケースによって異なります。シナリオごとに選択できるアルゴリズムが多数あります。典型的なアルゴリズムには次のものがあります。
- ID3 (分類):エントロピーと情報ゲインを最適化します。
- C4.5 (分類):情報獲得に正規化を追加した、ID3 のより複雑なバージョン
- CART (分類/回帰): 「分類と回帰ツリー」;結果セットの不純物を最小限に抑えるために最適化する貪欲なアルゴリズム
- CHAID (分類/回帰): 「カイ二乗自動相互作用検出」。エントロピーと情報ゲインの代わりにカイ二乗測定を使用します
- MARS (分類/回帰):区分的線形近似を使用して非線形性を捕捉します
一般的なトレーニング計画はランダム フォレストです。ランダム フォレストまたはランダム デシジョン フォレストは、関連する多数のデシジョン ツリーを構築するシステムです。トレーニング アルゴリズムの組み合わせを使用して、ツリーの複数のバージョンを並行してトレーニングできます。木の品質のさまざまな測定に基づいて、これらの木のサブセットが答えを生成するために使用されます。分類のユースケースでは、最大数のツリーによって選択されたクラスが答えとして返されます。回帰の使用例の場合、答えは通常、個々のツリーの平均値または平均予測として集計されます。
デシジョン ツリーの評価と使用
デシジョン ツリーが構築されると、新しいデータを分類したり、特定のユース ケースの値を予測したりできます。ツリーのパフォーマンスに関するメトリクスを保持し、それを使用して精度とエラー頻度を評価することが重要です。モデルが期待されるパフォーマンスから大きく逸脱している場合は、新しいデータでモデルを再トレーニングするか、そのユースケースに適用する他の ML システムを見つける時期が来ている可能性があります。
ML におけるデシジョン ツリーの応用
デシジョン ツリーは、さまざまな分野で幅広い用途に使用できます。以下にその多用途性を示す例をいくつか示します。
情報に基づいた個人的な意思決定
個人は、たとえば訪れたレストランに関するデータを追跡しているかもしれません。移動時間、待ち時間、提供される料理、営業時間、レビューの平均スコア、費用、最近の訪問など、関連する詳細を、そのレストランへの個人の訪問の満足度スコアと組み合わせて追跡する可能性があります。このデータに基づいてデシジョン ツリーをトレーニングして、新しいレストランの満足度スコアを予測できます。
顧客の行動に関する確率を計算する
カスタマー サポート システムは、デシジョン ツリーを使用して顧客満足度を予測または分類する場合があります。デシジョン ツリーは、顧客がサポートに連絡したか、繰り返し購入したか、アプリ内で実行されたアクションに基づいてなど、さまざまな要因に基づいて顧客満足度を予測するようにトレーニングできます。さらに、満足度調査やその他の顧客からのフィードバックの結果を組み込むこともできます。
ビジネス上の意思決定を支援する
豊富な履歴データを使用して特定のビジネス上の意思決定を行う場合、デシジョン ツリーは次のステップの推定や予測を提供できます。たとえば、顧客に関する人口統計および地理情報を収集する企業は、どの新しい地理的場所が利益を生む可能性が高いか、または避けるべきかを評価するためにデシジョン ツリーをトレーニングできます。デシジョン ツリーは、顧客をグループ化するときに個別に考慮すべき年齢範囲を特定するなど、既存の人口統計データの最適な分類境界を決定するのにも役立ちます。
高度な ML およびその他のユースケース向けの機能選択
デシジョン ツリー構造は人間が読みやすく、理解できるものです。ツリーが構築されると、どのフィーチャがデータセットに最も関連しており、その順序を特定することができます。この情報は、より複雑な ML システムや意思決定アルゴリズムの開発に役立ちます。たとえば、企業がデシジョン ツリーから、顧客が製品のコストを何よりも優先していることを学んだ場合、より複雑な ML システムをこの洞察に集中させたり、より微妙な機能を検討するときにコストを無視したりすることができます。
ML におけるデシジョン ツリーの利点
デシジョン ツリーにはいくつかの重要な利点があるため、ML アプリケーションで人気の選択肢となっています。主な利点は次のとおりです。
素早く簡単に構築可能
デシジョン ツリーは、最も成熟し、よく理解されている ML アルゴリズムの 1 つです。特に複雑な計算に依存せず、迅速かつ簡単に構築できます。必要な情報がすぐに入手できる限り、デシジョン ツリーは、問題に対する ML ソリューションを検討する際の簡単な最初のステップとなります。
人間にとって理解しやすい
デシジョン ツリーからの出力は、特に読みやすく解釈しやすいです。デシジョン ツリーのグラフィック表現は、統計の高度な理解に依存しません。したがって、決定木とその表現は、より複雑な分析の結果を解釈、説明、サポートするために使用できます。デシジョン ツリーは、特定のデータセットの高レベルのプロパティの一部を見つけて強調表示することに優れています。
最小限のデータ処理が必要
デシジョン ツリーは、不完全なデータや外れ値が含まれるデータに対しても同様に簡単に構築できます。データが興味深い特徴で装飾されている場合、前処理されていないデータが与えられた場合、デシジョン ツリー アルゴリズムは他の ML アルゴリズムほど影響を受けない傾向があります。
ML におけるデシジョン ツリーの欠点
デシジョン ツリーには多くの利点がありますが、いくつかの欠点もあります。
過学習の影響を受けやすい
デシジョン ツリーは、モデルがトレーニング データ内のノイズと詳細を学習するときに発生する過学習が発生し、新しいデータでのパフォーマンスが低下する傾向があります。たとえば、トレーニング データが不完全またはまばらな場合、データの小さな変更によって大幅に異なるツリー構造が生成される可能性があります。枝刈りや最大深さの設定などの高度なテクニックを使用すると、ツリーの動作を改善できます。実際には、多くの場合、デシジョン ツリーを新しい情報で更新する必要があり、その構造が大幅に変更される可能性があります。
スケーラビリティが低い
デシジョン ツリーは、過剰適合する傾向に加えて、大幅に多くのデータを必要とするより高度な問題にも対処します。他のアルゴリズムと比較して、デシジョン ツリーのトレーニング時間は、データ量が増加するにつれて急速に増加します。検出すべき重要な高レベルのプロパティがある可能性がある大規模なデータセットの場合、デシジョン ツリーはあまり適していません。
回帰または継続的なユースケースにはそれほど効果的ではありません
デシジョン ツリーは複雑なデータ分布をあまり学習しません。理解しやすく数学的に単純な線に沿って特徴空間を分割します。外れ値が関係する複雑な問題、回帰、継続的なユースケースでは、他の ML モデルや手法よりもパフォーマンスが大幅に低下することがよくあります。