
Conceptos básicos de las redes neuronales convolucionales: lo que necesita saber
Publicado: 2024-09-10Las redes neuronales convolucionales (CNN) son herramientas fundamentales en el análisis de datos y el aprendizaje automático (ML). Esta guía explica cómo funcionan las CNN, en qué se diferencian de otras redes neuronales, sus aplicaciones y las ventajas y desventajas asociadas con su uso.
Tabla de contenido
- ¿Qué es una CNN?
- Cómo funcionan las CNN
- CNN frente a RNN y transformadores
- Aplicaciones de las CNN
- Ventajas
- Desventajas
¿Qué es una red neuronal convolucional?
Una red neuronal convolucional (CNN) es una red neuronal integral para el aprendizaje profundo, diseñada para procesar y analizar datos espaciales. Emplea capas convolucionales con filtros para detectar y aprender automáticamente características importantes dentro de la entrada, lo que lo hace particularmente efectivo para tareas como el reconocimiento de imágenes y videos.
Analicemos un poco esta definición. Los datos espaciales son datos en los que las partes se relacionan entre sí a través de su posición. Las imágenes son el mejor ejemplo de ello.
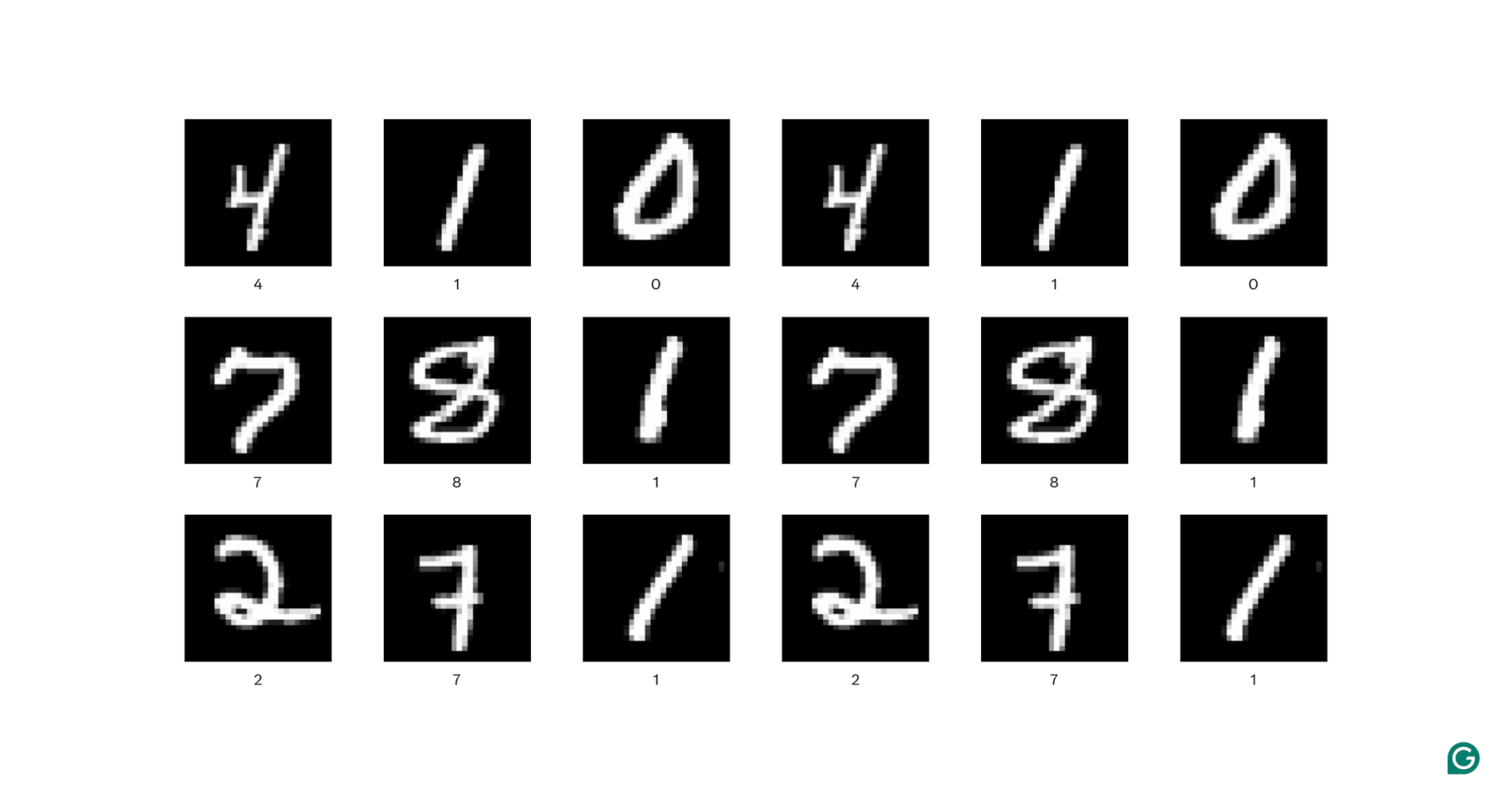
En cada imagen de arriba, cada píxel blanco está conectado a cada píxel blanco circundante: forman el dígito. Las ubicaciones de los píxeles también le indican al espectador dónde se encuentra el dígito dentro de la imagen.

Las características son atributos presentes dentro de la imagen. Estos atributos pueden ser cualquier cosa, desde un borde ligeramente inclinado hasta la presencia de una nariz o un ojo o una composición de ojos, bocas y narices. Fundamentalmente, los rasgos pueden estar compuestos de rasgos más simples (por ejemplo, un ojo se compone de unos pocos bordes curvos y una mancha oscura central).
Los filtros son la parte del modelo que detecta estas características dentro de la imagen. Cada filtro busca una característica específica (por ejemplo, un borde que se curva de izquierda a derecha) en toda la imagen.
Finalmente, lo "convolucional" en una red neuronal convolucional se refiere a cómo se aplica un filtro a una imagen. Lo explicaremos en la siguiente sección.
Las CNN han mostrado un sólido rendimiento en diversas tareas de imágenes, como la detección de objetos y la segmentación de imágenes. Un modelo de CNN (AlexNet) jugó un papel importante en el auge del aprendizaje profundo en 2012.
Cómo funcionan las CNN
Exploremos la arquitectura general de una CNN usando el ejemplo de determinar qué número (0–9) está en una imagen.
Antes de introducir la imagen en el modelo, la imagen debe convertirse en una representación numérica (o codificación). Para imágenes en blanco y negro, a cada píxel se le asigna un número: 255 si es completamente blanco y 0 si es completamente negro (a veces normalizado a 1 y 0). Para las imágenes en color, a cada píxel se le asignan tres números: uno que indica la cantidad de rojo, verde y azul que contiene, conocido como valor RGB. Entonces, una imagen de 256×256 píxeles (con 65.536 píxeles) tendría 65.536 valores en su codificación en blanco y negro y 196.608 valores en su codificación en color.
Luego, el modelo procesa la imagen a través de tres tipos de capas:
1 capa convolucional:esta capa aplica filtros a su entrada. Cada filtro es una cuadrícula de números de un tamaño definido (por ejemplo, 3×3). Esta cuadrícula se superpone en la imagen comenzando desde la parte superior izquierda; Se utilizarán los valores de píxeles de las filas 1 a 3 de las columnas 1 a 3. Estos valores de píxeles se multiplican por los valores del filtro y luego se suman. Luego, esta suma se coloca en la cuadrícula de salida del filtro en la fila 1, columna 1. Luego, el filtro se desliza un píxel hacia la derecha y repite el proceso hasta que haya cubierto todas las filas y columnas de la imagen. Al deslizar un píxel a la vez, el filtro puede encontrar características en cualquier parte de la imagen, una propiedad conocida como invariancia traslacional. Cada filtro crea su propia cuadrícula de salida, que luego se envía a la siguiente capa.
2 Capa de agrupación: esta capa resume la información de características de la capa convolucional. La capa convolucional devuelve una salida más grande que su entrada (cada filtro devuelve un mapa de características aproximadamente del mismo tamaño que la entrada y hay varios filtros). La capa de agrupación toma cada mapa de características y le aplica otra cuadrícula. Esta cuadrícula toma el promedio o el máximo de los valores que contiene y lo genera. Sin embargo, esta cuadrícula no se mueve un píxel a la vez; saltará al siguiente parche de píxeles. Por ejemplo, una cuadrícula de agrupación de 3 × 3 funcionará primero en los píxeles de las filas 1 a 3 y de las columnas 1 a 3. Luego, permanecerá en la misma fila pero pasará a las columnas 4 a 6. Después de cubrir todas las columnas del primer conjunto de filas (1 a 3), bajará a las filas 4 a 6 y abordará esas columnas. Esto reduce efectivamente el número de filas y columnas en la salida. La capa de agrupación ayuda a reducir la complejidad, hace que el modelo sea más robusto ante el ruido y los pequeños cambios, y ayuda al modelo a centrarse en las características más importantes.
3 Capa completamente conectada: después de múltiples rondas de capas convolucionales y de agrupación, los mapas de características finales se pasan a una capa de red neuronal completamente conectada, que devuelve el resultado que nos interesa (por ejemplo, la probabilidad de que la imagen sea un número particular). Los mapas de características deben aplanarse (cada fila de un mapa de características se concatena en una fila larga) y luego combinarse (cada fila larga del mapa de características se concatena en una megafila).
A continuación se muestra una representación visual de la arquitectura CNN, que ilustra cómo cada capa procesa la imagen de entrada y contribuye al resultado final:

Algunas notas adicionales sobre el proceso:
- Cada capa convolucional sucesiva encuentra características de nivel superior. La primera capa convolucional detecta bordes, puntos o patrones simples. La siguiente capa convolucional toma la salida agrupada de la primera capa convolucional como entrada, lo que le permite detectar composiciones de características de nivel inferior que forman características de nivel superior, como una nariz o un ojo.
- El modelo requiere entrenamiento. Durante el entrenamiento, se pasa una imagen a través de todas las capas (con pesos aleatorios al principio) y se genera el resultado. La diferencia entre el resultado y la respuesta real se utiliza para ajustar ligeramente las ponderaciones, lo que hace que sea más probable que el modelo responda correctamente en el futuro. Esto se hace mediante descenso de gradiente, donde el algoritmo de entrenamiento calcula cuánto contribuye cada peso del modelo a la respuesta final (usando derivadas parciales) y lo mueve ligeramente en la dirección de la respuesta correcta. La capa de agrupación no tiene ningún peso, por lo que no se ve afectada por el proceso de entrenamiento.
- Las CNN solo pueden funcionar con imágenes del mismo tamaño que aquellas en las que fueron entrenadas. Si un modelo se entrenó en imágenes con 256 × 256 píxeles, entonces será necesario reducir la resolución de cualquier imagen más grande y aumentar la resolución de cualquier imagen más pequeña.

CNN frente a RNN y transformadores
Las redes neuronales convolucionales se mencionan a menudo junto con las redes neuronales recurrentes (RNN) y los transformadores. Entonces, ¿en qué se diferencian?
CNN frente a RNN
Las RNN y las CNN operan en diferentes dominios. Las RNN son más adecuadas para datos secuenciales, como texto, mientras que las CNN sobresalen con datos espaciales, como imágenes. Los RNN tienen un módulo de memoria que realiza un seguimiento de las partes de una entrada vistas anteriormente para contextualizar la siguiente parte. Por el contrario, las CNN contextualizan partes de la entrada mirando a sus vecinos inmediatos. Debido a que las CNN carecen de un módulo de memoria, no son adecuadas para tareas de texto: olvidarían la primera palabra de una oración cuando llegaran a la última.
CNN versus transformadores
Los transformadores también se utilizan mucho para tareas secuenciales. Pueden utilizar cualquier parte de la entrada para contextualizar la nueva entrada, lo que los hace populares para tareas de procesamiento del lenguaje natural (PLN). Sin embargo, recientemente también se han aplicado transformadores a las imágenes, en forma de transformadores de visión. Estos modelos toman una imagen, la dividen en parches, dirigen la atención (el mecanismo central en las arquitecturas de transformadores) sobre los parches y luego clasifican la imagen. Los transformadores de visión pueden superar a las CNN en grandes conjuntos de datos, pero carecen de la invariancia traslacional inherente a las CNN. La invariancia traslacional en las CNN permite que el modelo reconozca objetos independientemente de su posición en la imagen, lo que hace que las CNN sean muy efectivas para tareas donde la relación espacial de las características es importante.
Aplicaciones de las CNN
Las CNN se utilizan a menudo con imágenes debido a su invariancia traslacional y características espaciales. Pero, con un procesamiento inteligente, las CNN pueden funcionar en otros dominios (a menudo convirtiéndolas primero en imágenes).
Clasificación de imágenes
La clasificación de imágenes es el uso principal de las CNN. Las CNN grandes y bien entrenadas pueden reconocer millones de objetos diferentes y pueden trabajar en casi cualquier imagen que se les proporcione. A pesar del auge de los transformadores, la eficiencia computacional de las CNN las convierte en una opción viable.
reconocimiento de voz
El audio grabado se puede convertir en datos espaciales mediante espectrogramas, que son representaciones visuales del audio. Una CNN puede tomar un espectrograma como entrada y aprender a asignar diferentes formas de onda a diferentes palabras. De manera similar, una CNN puede reconocer ritmos y muestras de música.
Segmentación de imágenes
La segmentación de imágenes implica identificar y trazar límites alrededor de diferentes objetos en una imagen. Las CNN son populares para esta tarea debido a su gran rendimiento en el reconocimiento de diversos objetos. Una vez segmentada una imagen, podemos comprender mejor su contenido. Por ejemplo, otro modelo de aprendizaje profundo podría analizar los segmentos y describir esta escena: “Dos personas caminan por un parque. Hay una farola a su derecha y un coche delante de ellos”. En el campo de la medicina, la segmentación de imágenes puede diferenciar tumores de células normales en las exploraciones. Para vehículos autónomos, puede identificar marcas de carril, señales de tráfico y otros vehículos.
Ventajas de las CNN
Las CNN se utilizan ampliamente en la industria por varias razones.
Fuerte rendimiento de imagen
Con la abundancia de datos de imágenes disponibles, se necesitan modelos que funcionen bien en varios tipos de imágenes. Las CNN son muy adecuadas para este propósito. Su invariancia traslacional y su capacidad para crear características más grandes a partir de otras más pequeñas les permiten detectar características en toda una imagen. No se requieren diferentes arquitecturas para diferentes tipos de imágenes, ya que una CNN básica se puede aplicar a todo tipo de datos de imágenes.
Sin ingeniería de funciones manual
Antes de las CNN, los modelos de imágenes de mejor rendimiento requerían un esfuerzo manual significativo. Los expertos en el campo tuvieron que crear módulos para detectar tipos específicos de características (por ejemplo, filtros para bordes), un proceso que requería mucho tiempo y carecía de flexibilidad para diversas imágenes. Cada conjunto de imágenes necesitaba su propio conjunto de características. Por el contrario, la primera CNN famosa (AlexNet) podía categorizar 20.000 tipos de imágenes automáticamente, reduciendo la necesidad de ingeniería de funciones manual.
Desventajas de las CNN
Por supuesto, el uso de CNN tiene sus ventajas y desventajas.
Muchos hiperparámetros
Entrenar una CNN implica seleccionar muchos hiperparámetros. Como cualquier red neuronal, existen hiperparámetros como el número de capas, el tamaño del lote y la tasa de aprendizaje. Además, cada filtro requiere su propio conjunto de hiperparámetros: tamaño del filtro (por ejemplo, 3×3, 5×5) y zancada (el número de píxeles que se moverán después de cada paso). Los hiperparámetros no se pueden ajustar fácilmente durante el proceso de entrenamiento. En su lugar, es necesario entrenar varios modelos con diferentes conjuntos de hiperparámetros (por ejemplo, el conjunto A y el conjunto B) y comparar su rendimiento para determinar las mejores opciones.
Sensibilidad al tamaño de entrada
Cada CNN está entrenada para aceptar una imagen de un tamaño determinado (por ejemplo, 256 × 256 píxeles). Es posible que muchas imágenes que desee procesar no coincidan con este tamaño. Para solucionar este problema, puede aumentar o reducir la escala de sus imágenes. Sin embargo, este cambio de tamaño puede provocar la pérdida de información valiosa y degradar el rendimiento del modelo.