
Conceptos básicos de la red generativa adversaria: lo que necesita saber
Publicado: 2024-10-08Las redes generativas adversarias (GAN) son una poderosa herramienta de inteligencia artificial (IA) con numerosas aplicaciones en aprendizaje automático (ML). Esta guía explora las GAN, cómo funcionan, sus aplicaciones y sus ventajas y desventajas.
Tabla de contenido
- ¿Qué es una GAN?
- GAN versus CNN
- Cómo funcionan las GAN
- Tipos de GAN
- Aplicaciones de GAN
- Ventajas de las GAN
- Desventajas de las GAN
¿Qué es una red generativa adversarial?
Una red generativa adversaria, o GAN, es un tipo de modelo de aprendizaje profundo que normalmente se utiliza en el aprendizaje automático no supervisado, pero que también se adapta al aprendizaje semisupervisado y supervisado. Las GAN se utilizan para generar datos de alta calidad similares al conjunto de datos de entrenamiento. Como subconjunto de la IA generativa, las GAN se componen de dos submodelos: el generador y el discriminador.
1 Generador:El generador crea datos sintéticos.
2 Discriminador:El discriminador evalúa la salida del generador, distinguiendo entre datos reales del conjunto de entrenamiento y datos sintéticos creados por el generador.
Los dos modelos participan en una competencia: el generador intenta engañar al discriminador para que clasifique los datos generados como reales, mientras que el discriminador mejora continuamente su capacidad para detectar datos sintéticos. Este proceso contradictorio continúa hasta que el discriminador ya no puede distinguir entre datos reales y generados. En este punto, la GAN es capaz de generar imágenes, vídeos y otros tipos de datos realistas.
GAN versus CNN
Las GAN y las redes neuronales convolucionales (CNN) son tipos potentes de redes neuronales que se utilizan en el aprendizaje profundo, pero difieren significativamente en términos de casos de uso y arquitectura.
Casos de uso
- GAN:se especializan en generar datos sintéticos realistas basados en datos de entrenamiento. Esto hace que las GAN sean ideales para tareas como generación de imágenes, transferencia de estilos de imágenes y aumento de datos. Las GAN no están supervisadas, lo que significa que se pueden aplicar a escenarios donde los datos etiquetados son escasos o no están disponibles.
- CNN:se utilizan principalmente para tareas de clasificación de datos estructurados, como análisis de sentimientos, categorización de temas y traducción de idiomas. Debido a sus capacidades de clasificación, las CNN también sirven como buenos discriminadores en las GAN. Sin embargo, debido a que las CNN requieren datos de entrenamiento estructurados y anotados por humanos, se limitan a escenarios de aprendizaje supervisado.
Arquitectura
- GAN:constan de dos modelos, un discriminador y un generador, que participan en un proceso competitivo. El generador crea imágenes, mientras que el discriminador las evalúa, lo que empuja al generador a producir imágenes cada vez más realistas con el tiempo.
- CNN:utilice capas de operaciones convolucionales y de agrupación para extraer y analizar características de imágenes. Esta arquitectura de modelo único se centra en reconocer patrones y estructuras dentro de los datos.
En general, mientras que las CNN se centran en analizar datos estructurados existentes, las GAN están orientadas a crear datos nuevos y realistas.
Cómo funcionan las GAN
En un nivel alto, una GAN funciona enfrentando dos redes neuronales (el generador y el discriminador) entre sí. Las GAN no requieren un tipo particular de arquitectura de red neuronal para ninguno de sus dos componentes, siempre que las arquitecturas seleccionadas se complementen entre sí. Por ejemplo, si se utiliza una CNN como discriminador para la generación de imágenes, entonces el generador podría ser una red neuronal deconvolucional (deCNN), que realiza el proceso de CNN a la inversa. Cada componente tiene un objetivo diferente:
- Generador:Producir datos de tan alta calidad que el discriminador se engañe y los clasifique como reales.
- Discriminador:clasificar con precisión una muestra de datos determinada como real (del conjunto de datos de entrenamiento) o falsa (generada por el generador).
Esta competencia es una implementación de un juego de suma cero, donde una recompensa dada a un modelo es también una penalización para el otro modelo. Para el generador, engañar con éxito al discriminador da como resultado una actualización del modelo que mejora su capacidad para generar datos realistas. Por el contrario, cuando el discriminador identifica correctamente datos falsos, recibe una actualización que mejora sus capacidades de detección. Matemáticamente, el discriminador busca minimizar el error de clasificación, mientras que el generador busca maximizarlo.
El proceso de formación de GAN
El entrenamiento de GAN implica alternar entre el generador y el discriminador durante múltiples épocas. Las épocas son ejecuciones de entrenamiento completas en todo el conjunto de datos. Este proceso continúa hasta que el generador produce datos sintéticos que engañan al discriminador alrededor del 50% de las veces. Si bien ambos modelos utilizan algoritmos similares para la evaluación y mejora del desempeño, sus actualizaciones se realizan de forma independiente. Estas actualizaciones se realizan mediante un método llamado retropropagación, que mide el error de cada modelo y ajusta los parámetros para mejorar el rendimiento. Luego, un algoritmo de optimización ajusta los parámetros de cada modelo de forma independiente.
Aquí hay una representación visual de la arquitectura GAN, que ilustra la competencia entre el generador y el discriminador:
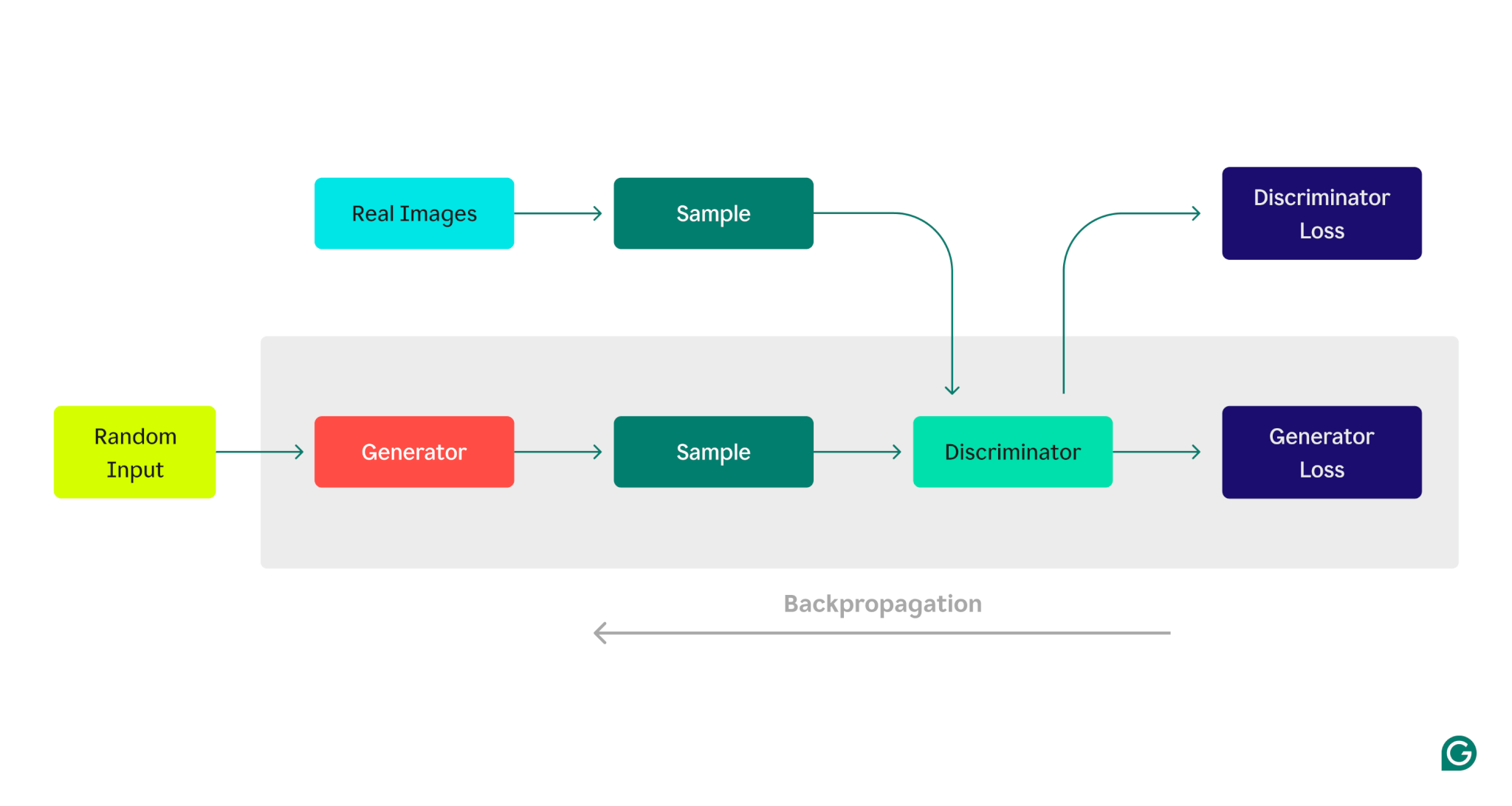
Fase de entrenamiento del generador:
1 El generador crea muestras de datos, normalmente comenzando con ruido aleatorio como entrada.
2 El discriminador clasifica estas muestras como reales (del conjunto de datos de entrenamiento) o falsas (generadas por el generador).
3 Según la respuesta del discriminador, los parámetros del generador se actualizan mediante retropropagación.
Fase de formación del discriminador:
1 Los datos falsos se generan utilizando el estado actual del generador.
2 Las muestras generadas se proporcionan al discriminador, junto con muestras del conjunto de datos de entrenamiento.
3 Mediante la propagación hacia atrás, los parámetros del discriminador se actualizan en función de su rendimiento de clasificación.
Este proceso de entrenamiento iterativo continúa, ajustando los parámetros de cada modelo en función de su rendimiento, hasta que el generador produce consistentemente datos que el discriminador no puede distinguir de manera confiable de los datos reales.
Tipos de GAN
Sobre la base de la arquitectura GAN básica, a menudo denominada GAN básica, se han desarrollado y optimizado otros tipos especializados de GAN para diversas tareas. Algunas de las variaciones más comunes se describen a continuación, aunque no es una lista exhaustiva:
GAN condicional (cGAN)
Las GAN condicionales, o cGAN, utilizan información adicional, llamada condiciones, para guiar al modelo en la generación de tipos específicos de datos cuando se entrena en un conjunto de datos más general. Una condición puede ser una etiqueta de clase, una descripción basada en texto u otro tipo de información de clasificación para los datos. Por ejemplo, imagina que necesitas generar imágenes solo de gatos siameses, pero tu conjunto de datos de entrenamiento contiene imágenes de todo tipo de gatos. En una cGAN, se pueden etiquetar imágenes de entrenamiento con el tipo de gato, y el modelo podría usar esto para aprender a generar solo imágenes de gatos siameses.

GAN convolucional profunda (DCGAN)
Una GAN convolucional profunda, o DCGAN, está optimizada para la generación de imágenes. En un DCGAN, el generador es una red neuronal convolucional de incrustación profunda (deCNN) y el discriminador es una CNN profunda. Las CNN son más adecuadas para trabajar y generar imágenes debido a su capacidad para capturar jerarquías y patrones espaciales. El generador de un DCGAN utiliza capas convolucionales transpuestas y de muestreo superior para crear imágenes de mayor calidad que las que podría generar un perceptrón multicapa (una red neuronal simple que toma decisiones sopesando las características de entrada). De manera similar, el discriminador utiliza capas convolucionales para extraer características de las muestras de imágenes y clasificarlas con precisión como reales o falsas.
CicloGAN
CycleGAN es un tipo de GAN diseñado para generar un tipo de imagen a partir de otro. Por ejemplo, un CycleGAN puede transformar una imagen de un ratón en una rata o de un perro en un coyote. Los CycleGAN pueden realizar esta traducción de imagen a imagen sin entrenamiento en conjuntos de datos emparejados, es decir, conjuntos de datos que contienen tanto la imagen base como la transformación deseada. Esta capacidad se logra mediante el uso de dos generadores y dos discriminadores en lugar del par único que utiliza una GAN básica. En CycleGAN, un generador convierte imágenes de la imagen base a la versión transformada, mientras que el otro generador realiza una conversión en la dirección opuesta. Asimismo, cada discriminador comprueba un tipo de imagen particular para determinar si es real o falsa. Luego, CycleGAN utiliza una verificación de coherencia para asegurarse de que la conversión de una imagen al otro estilo y viceversa dé como resultado la imagen original.
Aplicaciones de GAN
Debido a su arquitectura distintiva, las GAN se han aplicado a una variedad de casos de uso innovadores, aunque su desempeño depende en gran medida de tareas específicas y la calidad de los datos. Algunas de las aplicaciones más poderosas incluyen la generación de texto a imagen, el aumento de datos y la generación y manipulación de videos.
Generación de texto a imagen
Las GAN pueden generar imágenes a partir de una descripción textual. Esta aplicación es valiosa en las industrias creativas, ya que permite a los autores y diseñadores visualizar las escenas y personajes descritos en el texto. Si bien las GAN se utilizan a menudo para este tipo de tareas, otros modelos de IA generativa, como DALL-E de OpenAI, utilizan arquitecturas basadas en transformadores para lograr resultados similares.
Aumento de datos
Las GAN son útiles para el aumento de datos porque pueden generar datos sintéticos que se asemejan a datos de entrenamiento reales, aunque el grado de precisión y realismo puede variar según el caso de uso específico y el entrenamiento del modelo. Esta capacidad es particularmente valiosa en el aprendizaje automático para expandir conjuntos de datos limitados y mejorar el rendimiento del modelo. Además, las GAN ofrecen una solución para mantener la privacidad de los datos. En campos sensibles como la atención médica y las finanzas, las GAN pueden producir datos sintéticos que preservan las propiedades estadísticas del conjunto de datos original sin comprometer la información confidencial.
Generación y manipulación de videos.
Las GAN se han mostrado prometedoras en determinadas tareas de generación y manipulación de vídeos. Por ejemplo, las GAN se pueden utilizar para generar cuadros futuros a partir de una secuencia de video inicial, lo que ayuda en aplicaciones como predecir el movimiento de peatones o pronosticar peligros en la carretera para vehículos autónomos. Sin embargo, estas aplicaciones todavía se encuentran bajo investigación y desarrollo activo. Las GAN también se pueden utilizar para generar contenido de vídeo completamente sintético y mejorar vídeos con efectos especiales realistas.
Ventajas de las GAN
Las GAN ofrecen varias ventajas distintas, incluida la capacidad de generar datos sintéticos realistas, aprender de datos no emparejados y realizar capacitación sin supervisión.
Generación de datos sintéticos de alta calidad.
La arquitectura de las GAN les permite producir datos sintéticos que pueden aproximarse a los datos del mundo real en aplicaciones como el aumento de datos y la creación de videos, aunque la calidad y precisión de estos datos pueden depender en gran medida de las condiciones de entrenamiento y los parámetros del modelo. Por ejemplo, las DCGAN, que utilizan CNN para un procesamiento óptimo de imágenes, destacan en la generación de imágenes realistas.
Capaz de aprender de datos no emparejados
A diferencia de algunos modelos de ML, las GAN pueden aprender de conjuntos de datos sin ejemplos emparejados de entradas y salidas. Esta flexibilidad permite que las GAN se utilicen en una amplia gama de tareas donde los datos emparejados son escasos o no están disponibles. Por ejemplo, en las tareas de traducción de imagen a imagen, los modelos tradicionales a menudo requieren un conjunto de datos de imágenes y sus transformaciones para el entrenamiento. Por el contrario, las GAN pueden aprovechar una variedad más amplia de conjuntos de datos potenciales para la capacitación.
Aprendizaje no supervisado
Las GAN son un método de aprendizaje automático no supervisado, lo que significa que se pueden entrenar con datos sin etiquetar sin una dirección explícita. Esto es particularmente ventajoso porque etiquetar datos es un proceso costoso y que requiere mucho tiempo. La capacidad de las GAN para aprender de datos no etiquetados las hace valiosas para aplicaciones donde los datos etiquetados son limitados o difíciles de obtener. Las GAN también se pueden adaptar para el aprendizaje supervisado y semisupervisado, lo que les permite utilizar también datos etiquetados.
Desventajas de las GAN
Si bien las GAN son una herramienta poderosa en el aprendizaje automático, su arquitectura crea un conjunto único de desventajas. Estas desventajas incluyen sensibilidad a los hiperparámetros, altos costos computacionales, fallas de convergencia y un fenómeno llamado colapso modal.
Sensibilidad de hiperparámetro
Las GAN son sensibles a los hiperparámetros, que son parámetros establecidos antes del entrenamiento y no aprendidos de los datos. Los ejemplos incluyen arquitecturas de red y la cantidad de ejemplos de capacitación utilizados en una sola iteración. Pequeños cambios en estos parámetros pueden afectar significativamente el proceso de capacitación y los resultados del modelo, lo que requiere amplios ajustes para aplicaciones prácticas.
Alto coste computacional
Debido a su arquitectura compleja, proceso de entrenamiento iterativo y sensibilidad de hiperparámetros, las GAN a menudo incurren en altos costos computacionales. Entrenar una GAN con éxito requiere hardware costoso y especializado, así como mucho tiempo, lo que puede ser una barrera para muchas organizaciones que buscan utilizar GAN.
Fallo de convergencia
Los ingenieros e investigadores pueden dedicar cantidades significativas de tiempo a experimentar con configuraciones de entrenamiento antes de alcanzar una tasa aceptable a la cual la salida del modelo se vuelve estable y precisa, conocida como tasa de convergencia. La convergencia en las GAN puede ser muy difícil de lograr y puede que no dure mucho. El fallo de convergencia se produce cuando el discriminador no logra decidir suficientemente entre datos reales y falsos, lo que da como resultado una precisión de aproximadamente el 50% porque no ha adquirido la capacidad de identificar datos reales, a diferencia del equilibrio previsto alcanzado durante un entrenamiento exitoso. Es posible que algunas GAN nunca alcancen la convergencia y pueden requerir un análisis especializado para repararlas.
Colapso de modo
Las GAN son propensas a sufrir un problema llamado colapso de modo, donde el generador crea una gama limitada de resultados y no refleja la diversidad de distribuciones de datos del mundo real. Este problema surge de la arquitectura GAN, porque el generador se concentra demasiado en producir datos que pueden engañar al discriminador, lo que lo lleva a generar ejemplos similares.