
Conceptos básicos de las redes neuronales recurrentes: lo que necesita saber
Publicado: 2024-09-19Las redes neuronales recurrentes (RNN) son métodos esenciales en los ámbitos del análisis de datos, el aprendizaje automático (ML) y el aprendizaje profundo. Este artículo tiene como objetivo explorar las RNN y detallar su funcionalidad, aplicaciones y ventajas y desventajas dentro del contexto más amplio del aprendizaje profundo.
Tabla de contenido
¿Qué es un RNN?
Cómo funcionan los RNN
Tipos de RNN
RNN frente a transformadores y CNN
Aplicaciones de RNN
Ventajas
Desventajas
¿Qué es una red neuronal recurrente?
Una red neuronal recurrente es una red neuronal profunda que puede procesar datos secuenciales manteniendo una memoria interna, lo que le permite realizar un seguimiento de las entradas pasadas para generar salidas. Los RNN son un componente fundamental del aprendizaje profundo y son particularmente adecuados para tareas que involucran datos secuenciales.
Lo "recurrente" en "red neuronal recurrente" se refiere a cómo el modelo combina información de entradas pasadas con entradas actuales. La información de entradas antiguas se almacena en una especie de memoria interna, denominada "estado oculto". Se repite: se retroalimenta de cálculos anteriores para crear un flujo continuo de información.
Demostrémoslo con un ejemplo: supongamos que queremos usar un RNN para detectar el sentimiento (ya sea positivo o negativo) de la oración "Se comió el pastel felizmente". El RNN procesaría la palabrahe, actualizaría su estado oculto para incorporar esa palabra y luego pasaría aate, combinaría eso con lo que aprendió dehe, y así sucesivamente con cada palabra hasta terminar la oración. Para ponerlo en perspectiva, un humano que leyera esta oración actualizaría su comprensión con cada palabra. Una vez que ha leído y comprendido la oración completa, el humano puede decir que la oración es positiva o negativa. Este proceso humano de comprensión es lo que el estado oculto intenta aproximar.
Los RNN son uno de los modelos fundamentales de aprendizaje profundo. Les ha ido muy bien en tareas de procesamiento del lenguaje natural (PNL), aunque los transformadores los han suplantado. Los transformadores son arquitecturas de redes neuronales avanzadas que mejoran el rendimiento de RNN, por ejemplo, procesando datos en paralelo y siendo capaces de descubrir relaciones entre palabras que están muy separadas en el texto fuente (utilizando mecanismos de atención). Sin embargo, los RNN siguen siendo útiles para datos de series temporales y para situaciones en las que son suficientes modelos más simples.
Cómo funcionan los RNN
Para describir en detalle cómo funcionan los RNN, volvamos a la tarea de ejemplo anterior: clasifique el sentimiento de la oración "Se comió el pastel felizmente".
Comenzamos con un RNN entrenado que acepta entradas de texto y devuelve una salida binaria (1 representa positivo y 0 representa negativo). Antes de que se proporcione la entrada al modelo, el estado oculto es genérico: se aprendió del proceso de capacitación pero aún no es específico de la entrada.
La primera palabra,Él, se pasa al modelo. Dentro del RNN, su estado oculto se actualiza (al estado oculto h1) para incorporar la palabraHe. A continuación, la palabraatese pasa al RNN y h1 se actualiza (a h2) para incluir esta nueva palabra. Este proceso se repite hasta que se pasa la última palabra. El estado oculto (h4) se actualiza para incluir la última palabra. Luego, el estado oculto actualizado se utiliza para generar un 0 o un 1.
Aquí hay una representación visual de cómo funciona el proceso RNN:
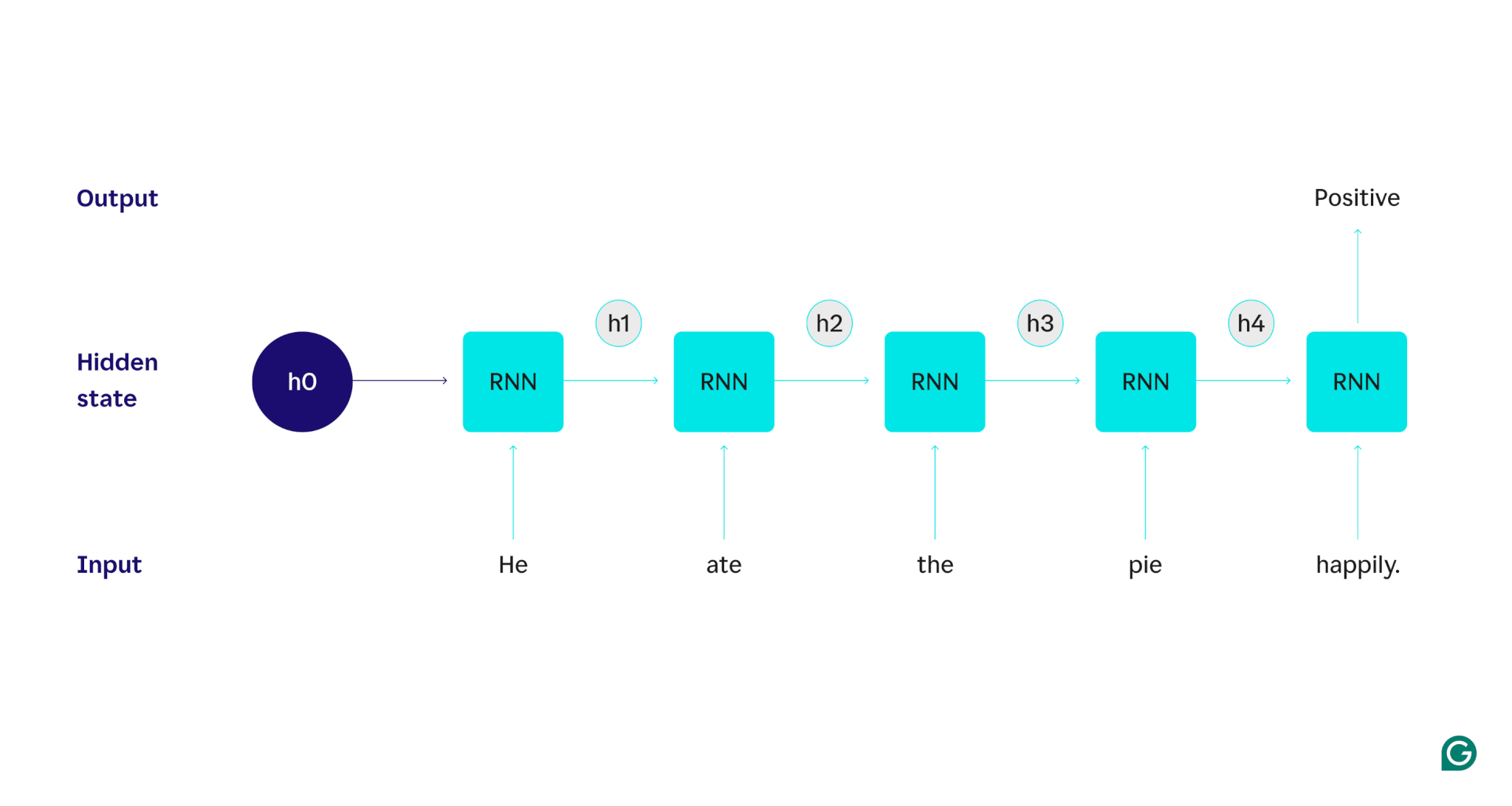
Esa recurrencia es el núcleo de la RNN, pero hay algunas otras consideraciones:
- Incrustación de texto:el RNN no puede procesar texto directamente ya que solo funciona en representaciones numéricas. El texto debe convertirse en incrustaciones antes de que un RNN pueda procesarlo.
- Generación de salida:el RNN generará una salida en cada paso. Sin embargo, es posible que el resultado no sea muy preciso hasta que se procese la mayor parte de los datos de origen. Por ejemplo, después de procesar solo la parte "Él comió" de la oración, el RNN podría no estar seguro de si representa un sentimiento positivo o negativo; "Él comió" podría parecer neutral. Sólo después de procesar la oración completa la salida del RNN sería precisa.
- Entrenamiento del RNN:el RNN debe estar entrenado para realizar análisis de sentimiento con precisión. El entrenamiento implica el uso de muchos ejemplos etiquetados (por ejemplo, "Se comió el pastel enojado", etiquetado como negativo), ejecutarlos a través del RNN y ajustar el modelo en función de qué tan lejos están sus predicciones. Este proceso establece el valor predeterminado y el mecanismo de cambio para el estado oculto, lo que permite al RNN aprender qué palabras son importantes para el seguimiento a lo largo de la entrada.
Tipos de redes neuronales recurrentes
Hay varios tipos diferentes de RNN, cada uno de los cuales varía en su estructura y aplicación. Los RNN básicos difieren principalmente en el tamaño de sus entradas y salidas. Los RNN avanzados, como las redes de memoria a corto plazo (LSTM), abordan algunas de las limitaciones de los RNN básicos.
RNN básicos
RNN uno a uno:este RNN toma una entrada de longitud uno y devuelve una salida de longitud uno. Por lo tanto, en realidad no ocurre ninguna recurrencia, lo que la convierte en una red neuronal estándar en lugar de una RNN. Un ejemplo de un RNN uno a uno sería un clasificador de imágenes, donde la entrada es una única imagen y la salida es una etiqueta (por ejemplo, "pájaro").
RNN uno a muchos:este RNN toma una entrada de longitud uno y devuelve una salida multiparte. Por ejemplo, en una tarea de subtítulos de imágenes, la entrada es una imagen y la salida es una secuencia de palabras que describen la imagen (por ejemplo, “Un pájaro cruza un río en un día soleado”).
RNN de muchos a uno:este RNN toma una entrada de varias partes (por ejemplo, una oración, una serie de imágenes o datos de series de tiempo) y devuelve una salida de longitud uno. Por ejemplo, un clasificador de sentimiento de oración (como el que analizamos), donde la entrada es una oración y la salida es una etiqueta de sentimiento única (ya sea positiva o negativa).
RNN de muchos a muchos:este RNN toma una entrada multiparte y devuelve una salida multiparte. Un ejemplo es un modelo de reconocimiento de voz, donde la entrada es una serie de formas de onda de audio y la salida es una secuencia de palabras que representan el contenido hablado.
RNN avanzado: memoria larga a corto plazo (LSTM)
Las redes de memoria larga a corto plazo están diseñadas para abordar un problema importante con los RNN estándar: olvidan información en entradas largas. En los RNN estándar, el estado oculto tiene una gran influencia en las partes recientes de la entrada. En una entrada de miles de palabras, el RNN olvidará detalles importantes de las oraciones iniciales. Los LSTM tienen una arquitectura especial para solucionar este problema de olvido. Tienen módulos que seleccionan qué información recordar y olvidar explícitamente. Por lo tanto, se olvidará la información reciente pero inútil, mientras que se conservará la información antigua pero relevante. Como resultado, los LSTM son mucho más comunes que los RNN estándar; simplemente funcionan mejor en tareas complejas o largas. Sin embargo, no son perfectos ya que todavía optan por olvidar elementos.
RNN frente a transformadores y CNN
Otros dos modelos comunes de aprendizaje profundo son las redes neuronales convolucionales (CNN) y los transformadores. ¿En qué se diferencian?

RNN frente a transformadores
Tanto los RNN como los transformadores se utilizan mucho en PNL. Sin embargo, difieren significativamente en sus arquitecturas y enfoques para procesar la entrada.
Arquitectura y procesamiento
- RNN:los RNN procesan la entrada de forma secuencial, una palabra a la vez, manteniendo un estado oculto que transporta información de palabras anteriores. Esta naturaleza secuencial significa que los RNN pueden tener dificultades con dependencias a largo plazo debido a este olvido, en el que la información anterior puede perderse a medida que avanza la secuencia.
- Transformadores:Los transformadores utilizan un mecanismo llamado "atención" para procesar la entrada. A diferencia de los RNN, los transformadores observan la secuencia completa simultáneamente, comparando cada palabra con todas las demás. Este enfoque elimina el problema del olvido, ya que cada palabra tiene acceso directo a todo el contexto de entrada. Los transformadores han mostrado un rendimiento superior en tareas como generación de texto y análisis de sentimientos debido a esta capacidad.
Paralelización
- RNN:la naturaleza secuencial de los RNN significa que el modelo debe completar el procesamiento de una parte de la entrada antes de pasar a la siguiente. Esto lleva mucho tiempo, ya que cada paso depende del anterior.
- Transformadores:Los transformadores procesan todas las partes de la entrada simultáneamente, ya que su arquitectura no depende de un estado oculto secuencial. Esto los hace mucho más paralelizables y eficientes. Por ejemplo, si procesar una oración toma 5 segundos por palabra, un RNN tomaría 25 segundos para una oración de 5 palabras, mientras que un transformador tomaría solo 5 segundos.
Implicaciones prácticas
Debido a estas ventajas, los transformadores se utilizan más ampliamente en la industria. Sin embargo, las RNN, en particular las redes de memoria a corto plazo (LSTM), aún pueden ser efectivas para tareas más simples o cuando se trata de secuencias más cortas. Los LSTM se utilizan a menudo como módulos de almacenamiento de memoria críticos en grandes arquitecturas de aprendizaje automático.
RNN frente a CNN
Las CNN son fundamentalmente diferentes de las RNN en términos de los datos que manejan y sus mecanismos operativos.
tipo de datos
- RNN:los RNN están diseñados para datos secuenciales, como texto o series de tiempo, donde el orden de los puntos de datos es importante.
- CNN:las CNN se utilizan principalmente para datos espaciales, como imágenes, donde la atención se centra en las relaciones entre puntos de datos adyacentes (por ejemplo, el color, la intensidad y otras propiedades de un píxel en una imagen están estrechamente relacionadas con las propiedades de otros píxeles cercanos). píxeles).
Operación
- RNN:los RNN mantienen una memoria de toda la secuencia, lo que los hace adecuados para tareas donde el contexto y la secuencia importan.
- CNN:las CNN operan observando regiones locales de la entrada (por ejemplo, píxeles vecinos) a través de capas convolucionales. Esto los hace muy efectivos para el procesamiento de imágenes, pero menos para datos secuenciales, donde las dependencias a largo plazo podrían ser más importantes.
Longitud de entrada
- RNN:los RNN pueden manejar secuencias de entrada de longitud variable con una estructura menos definida, lo que las hace flexibles para diferentes tipos de datos secuenciales.
- CNN:las CNN generalmente requieren entradas de tamaño fijo, lo que puede ser una limitación para manejar secuencias de longitud variable.
Aplicaciones de RNN
Los RNN se utilizan ampliamente en diversos campos debido a su capacidad para manejar datos secuenciales de manera efectiva.
Procesamiento del lenguaje natural
El lenguaje es una forma de datos altamente secuencial, por lo que los RNN funcionan bien en tareas de lenguaje. Los RNN se destacan en tareas como generación de texto, análisis de sentimientos, traducción y resumen. Con bibliotecas como PyTorch, alguien podría crear un chatbot simple usando un RNN y algunos gigabytes de ejemplos de texto.
reconocimiento de voz
El reconocimiento de voz es el lenguaje en esencia y, por lo tanto, también es altamente secuencial. Para esta tarea se podría utilizar un RNN de muchos a muchos. En cada paso, el RNN toma el estado oculto anterior y la forma de onda, generando la palabra asociada con la forma de onda (según el contexto de la oración hasta ese punto).
generacion musical
La música también es muy secuencial. Los tiempos anteriores de una canción influyen fuertemente en los tiempos futuros. Un RNN de muchos a muchos podría tomar algunos tiempos iniciales como entrada y luego generar tiempos adicionales según lo desee el usuario. Alternativamente, podría tomar una entrada de texto como “jazz melódico” y generar su mejor aproximación a los ritmos del jazz melódico.
Ventajas de los RNN
Aunque los RNN ya no son el modelo de PNL de facto, todavía tienen algunos usos debido a algunos factores.
Buen rendimiento secuencial
Los RNN, especialmente los LSTM, funcionan bien con datos secuenciales. Los LSTM, con su arquitectura de memoria especializada, pueden gestionar entradas secuenciales largas y complejas. Por ejemplo, Google Translate solía ejecutarse en un modelo LSTM antes de la era de los transformadores. Los LSTM se pueden utilizar para agregar módulos de memoria estratégicos cuando se combinan redes basadas en transformadores para formar arquitecturas más avanzadas.
Modelos más pequeños y simples
Los RNN suelen tener menos parámetros de modelo que los transformadores. Las capas de atención y retroalimentación en los transformadores requieren más parámetros para funcionar de manera efectiva. Los RNN se pueden entrenar con menos ejecuciones y ejemplos de datos, lo que los hace más eficientes para casos de uso más simples. Esto da como resultado modelos más pequeños, menos costosos y más eficientes que aún tienen un rendimiento suficiente.
Desventajas de los RNN
Los RNN han caído en desgracia por una razón: los transformadores, a pesar de su mayor tamaño y proceso de entrenamiento, no tienen los mismos defectos que los RNN.
Memoria limitada
El estado oculto en los RNN estándar sesga fuertemente las entradas recientes, lo que dificulta retener dependencias de largo alcance. Las tareas con entradas largas no funcionan tan bien con los RNN. Si bien los LSTM tienen como objetivo abordar este problema, solo lo mitigan y no lo resuelven por completo. Muchas tareas de IA requieren manejar entradas largas, lo que hace que la memoria limitada sea un inconveniente importante.
No paralelizable
Cada ejecución del modelo RNN depende del resultado de la ejecución anterior, específicamente del estado oculto actualizado. Como resultado, todo el modelo debe procesarse secuencialmente para cada parte de una entrada. Por el contrario, los transformadores y las CNN pueden procesar toda la entrada simultáneamente. Esto permite el procesamiento paralelo en múltiples GPU, lo que acelera significativamente el cálculo. La falta de paralelización de los RNN conduce a un entrenamiento más lento, una generación de resultados más lenta y una cantidad máxima menor de datos de los que se puede aprender.
Problemas de gradiente
Entrenar RNN puede ser un desafío porque el proceso de retropropagación debe pasar por cada paso de entrada (retropropagación a través del tiempo). Debido a los muchos pasos de tiempo, los gradientes (que indican cómo se debe ajustar cada parámetro del modelo) pueden degradarse y volverse ineficaces. Los gradientes pueden fallar al desaparecer, lo que significa que se vuelven muy pequeños y el modelo ya no puede usarlos para aprender, o al explotar, donde los gradientes se vuelven muy grandes y el modelo sobrepasa sus actualizaciones, lo que hace que el modelo sea inutilizable. Equilibrar estas cuestiones es difícil.