
¿Qué es un codificador automático? Una guía para principiantes
Publicado: 2024-10-28Los codificadores automáticos son un componente esencial del aprendizaje profundo, particularmente en tareas de aprendizaje automático no supervisadas. En este artículo, exploraremos cómo funcionan los codificadores automáticos, su arquitectura y los distintos tipos disponibles. También descubrirá sus aplicaciones en el mundo real, junto con las ventajas y desventajas que implica su uso.
Tabla de contenido
- ¿Qué es un codificador automático?
- Arquitectura del codificador automático
- Tipos de codificadores automáticos
- Solicitud
- Ventajas
- Desventajas
¿Qué es un codificador automático?
Los codificadores automáticos son un tipo de red neuronal que se utiliza en el aprendizaje profundo para aprender representaciones eficientes de dimensiones inferiores de los datos de entrada, que luego se utilizan para reconstruir los datos originales. Al hacerlo, esta red aprende las características más esenciales de los datos durante el entrenamiento sin requerir etiquetas explícitas, lo que lo convierte en parte del aprendizaje autosupervisado. Los codificadores automáticos se aplican ampliamente en tareas como la eliminación de ruido de imágenes, la detección de anomalías y la compresión de datos, donde su capacidad para comprimir y reconstruir datos es valiosa.
Arquitectura del codificador automático
Un codificador automático se compone de tres partes: un codificador, un cuello de botella (también conocido como espacio latente o código) y un decodificador. Estos componentes trabajan juntos para capturar las características clave de los datos de entrada y utilizarlas para generar reconstrucciones precisas.
Los codificadores automáticos optimizan su salida ajustando los pesos tanto del codificador como del decodificador, con el objetivo de producir una representación comprimida de la entrada que preserve las características críticas. Esta optimización minimiza el error de reconstrucción, que representa la diferencia entre los datos de entrada y salida.
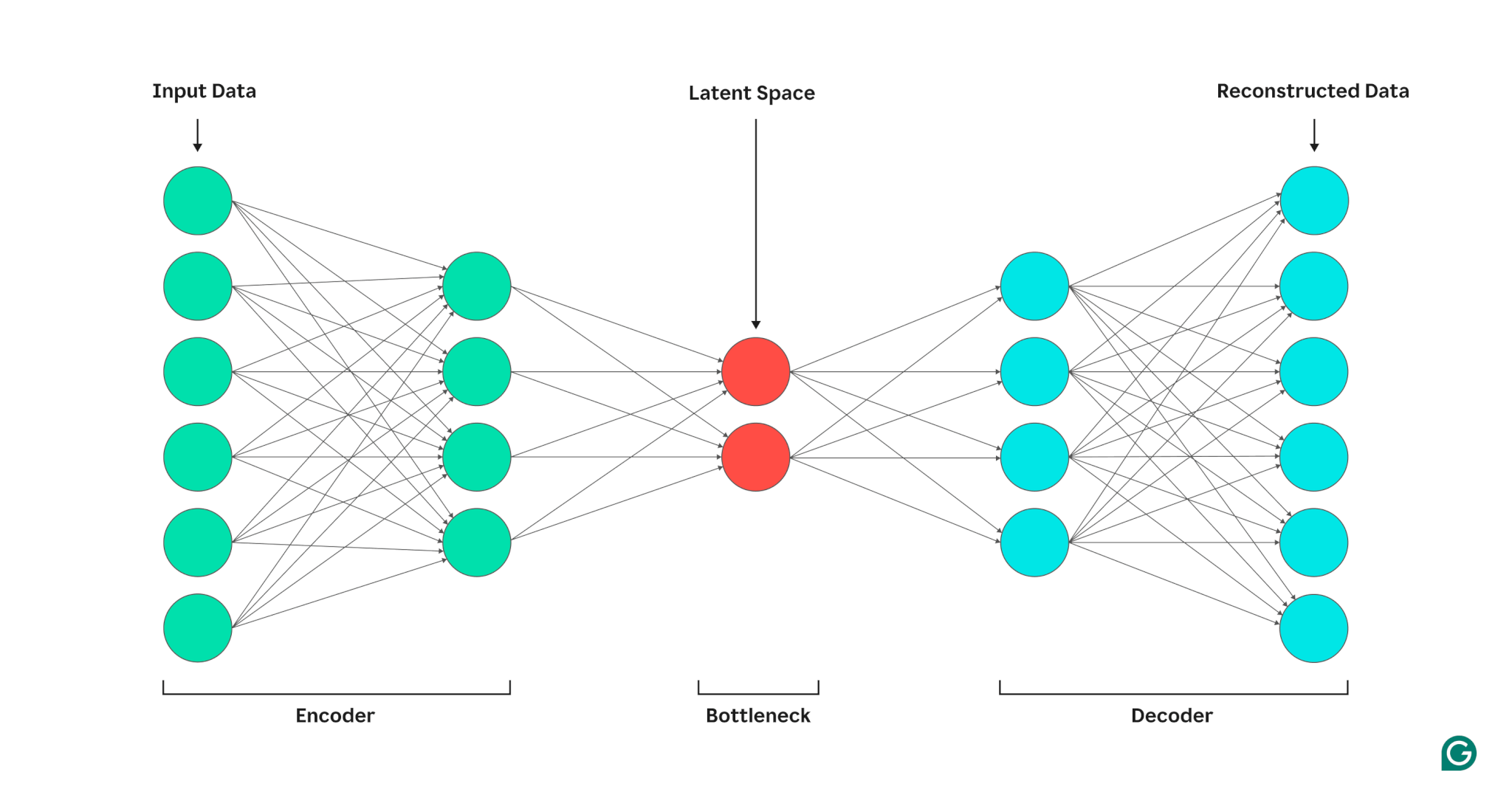
Codificador
Primero, el codificador comprime los datos de entrada en una representación más eficiente. Los codificadores generalmente constan de varias capas con menos nodos en cada capa. A medida que los datos se procesan a través de cada capa, la cantidad reducida de nodos obliga a la red a aprender las características más importantes de los datos para crear una representación que se pueda almacenar en cada capa. Este proceso, conocido como reducción de dimensionalidad, transforma la entrada en un resumen compacto de las características clave de los datos. Los hiperparámetros clave en el codificador incluyen el número de capas y neuronas por capa, que determinan la profundidad y granularidad de la compresión, y la función de activación, que dicta cómo se representan y transforman las características de los datos en cada capa.
Embotellamiento
El cuello de botella, también conocido como espacio latente o código, es donde se almacena la representación comprimida de los datos de entrada durante el procesamiento. El cuello de botella tiene una pequeña cantidad de nodos; esto limita la cantidad de datos que se pueden almacenar y determina el nivel de compresión. La cantidad de nodos en el cuello de botella es un hiperparámetro ajustable que permite a los usuarios controlar el equilibrio entre compresión y retención de datos. Si el cuello de botella es demasiado pequeño, el codificador automático puede reconstruir los datos incorrectamente debido a la pérdida de detalles importantes. Por otro lado, si el cuello de botella es demasiado grande, el codificador automático puede simplemente copiar los datos de entrada en lugar de aprender una representación general significativa.
Descifrador
En este paso final, el decodificador recrea los datos originales a partir del formulario comprimido utilizando las características clave aprendidas durante el proceso de codificación. La calidad de esta descompresión se cuantifica mediante el error de reconstrucción, que es esencialmente una medida de qué tan diferentes son los datos reconstruidos de los de entrada. El error de reconstrucción generalmente se calcula utilizando el error cuadrático medio (MSE). Debido a que MSE mide la diferencia al cuadrado entre los datos originales y reconstruidos, proporciona una forma matemáticamente sencilla de penalizar más los errores de reconstrucción más grandes.
Tipos de codificadores automáticos
Existen varios tipos de codificadores automáticos especializados, cada uno optimizado para aplicaciones específicas, similar a otras redes neuronales.
Codificadores automáticos de eliminación de ruido
Los codificadores automáticos con eliminación de ruido están diseñados para reconstruir datos limpios a partir de entradas ruidosas o corruptas. Durante el entrenamiento, se agrega ruido intencionalmente a los datos de entrada, lo que permite que el modelo aprenda características que permanecen consistentes a pesar del ruido. Luego, las salidas se comparan con las entradas limpias originales. Este proceso hace que los codificadores automáticos de eliminación de ruido sean muy efectivos en tareas de reducción de ruido de imagen y audio, incluida la eliminación del ruido de fondo en videoconferencias.
Codificadores automáticos dispersos
Los codificadores automáticos dispersos restringen la cantidad de neuronas activas en un momento dado, lo que anima a la red a aprender representaciones de datos más eficientes en comparación con los codificadores automáticos estándar. Esta restricción de escasez se aplica mediante una penalización que desalienta la activación de más neuronas que un umbral específico. Los codificadores automáticos dispersos simplifican los datos de alta dimensión al tiempo que preservan las características esenciales, lo que los hace valiosos para tareas como la extracción de características interpretables y la visualización de conjuntos de datos complejos.
Codificadores automáticos variacionales (VAE)
A diferencia de los codificadores automáticos típicos, los VAE generan nuevos datos codificando características de los datos de entrenamiento en una distribución de probabilidad, en lugar de un punto fijo. Al tomar muestras de esta distribución, los VAE pueden generar diversos datos nuevos, en lugar de reconstruir los datos originales a partir de la entrada. Esta capacidad hace que los VAE sean útiles para tareas generativas, incluida la generación de datos sintéticos. Por ejemplo, en la generación de imágenes, un VAE entrenado en un conjunto de datos de números escritos a mano puede crear dígitos nuevos y de apariencia realista basados en el conjunto de entrenamiento que no son réplicas exactas.

Autocodificadores contractivos
Los codificadores automáticos contractivos introducen un término de penalización adicional durante el cálculo del error de reconstrucción, lo que anima al modelo a aprender representaciones de características que sean resistentes al ruido. Esta penalización ayuda a prevenir el sobreajuste al promover el aprendizaje de funciones que es invariable ante pequeñas variaciones en los datos de entrada. Como resultado, los codificadores automáticos contractivos son más resistentes al ruido que los codificadores automáticos estándar.
Codificadores automáticos convolucionales (CAE)
Los CAE utilizan capas convolucionales para capturar jerarquías y patrones espaciales dentro de datos de alta dimensión. El uso de capas convolucionales hace que los CAE sean particularmente adecuados para procesar datos de imágenes. Los CAE se utilizan comúnmente en tareas como la compresión de imágenes y la detección de anomalías en imágenes.
Aplicaciones de codificadores automáticos en IA
Los codificadores automáticos tienen varias aplicaciones, como reducción de dimensionalidad, eliminación de ruido de imágenes y detección de anomalías.
Reducción de dimensionalidad
Los codificadores automáticos son herramientas eficaces para reducir la dimensionalidad de los datos de entrada y al mismo tiempo preservar las características clave. Este proceso es valioso para tareas como visualizar conjuntos de datos de alta dimensión y comprimir datos. Al simplificar los datos, la reducción de la dimensionalidad también mejora la eficiencia computacional, reduciendo tanto el tamaño como la complejidad.
Detección de anomalías
Al conocer las características clave de un conjunto de datos de destino, los codificadores automáticos pueden distinguir entre datos normales y anómalos cuando se les proporciona una nueva entrada. La desviación de lo normal se indica por tasas de error de reconstrucción más altas de lo normal. Como tal, los codificadores automáticos se pueden aplicar a diversos dominios como el mantenimiento predictivo y la seguridad de las redes informáticas.
Eliminación de ruido
Los codificadores automáticos de eliminación de ruido pueden limpiar datos ruidosos aprendiendo a reconstruirlos a partir de entradas de entrenamiento ruidosas. Esta capacidad hace que los codificadores automáticos de eliminación de ruido sean valiosos para tareas como la optimización de imágenes, incluida la mejora de la calidad de fotografías borrosas. Los codificadores automáticos con eliminación de ruido también son útiles en el procesamiento de señales, donde pueden limpiar señales ruidosas para un procesamiento y análisis más eficientes.
Ventajas de los codificadores automáticos
Los codificadores automáticos tienen una serie de ventajas clave. Estos incluyen la capacidad de aprender a partir de datos sin etiquetar, aprender características automáticamente sin instrucciones explícitas y extraer características no lineales.
Capaz de aprender de datos sin etiquetar
Los codificadores automáticos son un modelo de aprendizaje automático no supervisado, lo que significa que pueden aprender características de datos subyacentes a partir de datos sin etiquetar. Esta capacidad significa que los codificadores automáticos se pueden aplicar a tareas donde los datos etiquetados pueden ser escasos o no estar disponibles.
Aprendizaje automático de funciones
Las técnicas estándar de extracción de características, como el análisis de componentes principales (PCA), suelen resultar poco prácticas cuando se trata de manejar conjuntos de datos complejos y/o grandes. Debido a que los codificadores automáticos se diseñaron teniendo en cuenta tareas como la reducción de dimensionalidad, pueden aprender automáticamente características y patrones clave en los datos sin un diseño manual de características.
Extracción de características no lineales
Los codificadores automáticos pueden manejar relaciones no lineales en los datos de entrada, lo que permite que el modelo capture características clave de representaciones de datos más complejas. Esta capacidad significa que los codificadores automáticos tienen una ventaja sobre los modelos que solo pueden funcionar con datos lineales, ya que pueden manejar conjuntos de datos más complejos.
Limitaciones de los codificadores automáticos
Al igual que otros modelos de ML, los codificadores automáticos tienen sus propias desventajas. Estos incluyen la falta de interpretabilidad, la necesidad de grandes conjuntos de datos de entrenamiento para funcionar bien y capacidades de generalización limitadas.
Falta de interpretabilidad
Al igual que otros modelos complejos de ML, los codificadores automáticos adolecen de falta de interpretabilidad, lo que significa que es difícil comprender la relación entre los datos de entrada y la salida del modelo. En los codificadores automáticos, esta falta de interpretabilidad se produce porque los codificadores automáticos aprenden funciones automáticamente, a diferencia de los modelos tradicionales, donde las funciones se definen explícitamente. Esta representación de características generada por máquina suele ser muy abstracta y tiende a carecer de características interpretables por humanos, lo que dificulta la comprensión de lo que significa cada componente de la representación.
Requerir grandes conjuntos de datos de entrenamiento
Los codificadores automáticos normalmente requieren grandes conjuntos de datos de entrenamiento para aprender representaciones generalizables de características de datos clave. Dados conjuntos de datos de entrenamiento pequeños, los codificadores automáticos pueden tender a sobreajustarse, lo que lleva a una generalización deficiente cuando se les presentan datos nuevos. Por otro lado, los conjuntos de datos grandes proporcionan la diversidad necesaria para que el codificador automático aprenda características de los datos que se pueden aplicar en una amplia gama de escenarios.
Generalización limitada sobre nuevos datos.
Los codificadores automáticos entrenados en un conjunto de datos a menudo tienen capacidades de generalización limitadas, lo que significa que no logran adaptarse a nuevos conjuntos de datos. Esta limitación se produce porque los codificadores automáticos están orientados a la reconstrucción de datos en función de características destacadas de un conjunto de datos determinado. Como tal, los codificadores automáticos generalmente descartan detalles más pequeños de los datos durante el entrenamiento y no pueden manejar datos que no se ajustan a la representación de características generalizadas.