
¿Qué es un árbol de decisión en el aprendizaje automático?
Publicado: 2024-08-14Los árboles de decisión son una de las herramientas más comunes en el conjunto de herramientas de aprendizaje automático de un analista de datos. En esta guía, aprenderá qué son los árboles de decisión, cómo se construyen, diversas aplicaciones, beneficios y más.
Tabla de contenido
- ¿Qué es un árbol de decisión?
- Terminología del árbol de decisión
- Tipos de árboles de decisión
- Cómo funcionan los árboles de decisión
- Aplicaciones
- Ventajas
- Desventajas
¿Qué es un árbol de decisión?
En el aprendizaje automático (ML), un árbol de decisiones es un algoritmo de aprendizaje supervisado que se asemeja a un diagrama de flujo o diagrama de decisiones. A diferencia de muchos otros algoritmos de aprendizaje supervisado, los árboles de decisión se pueden utilizar tanto para tareas de clasificación como de regresión. Los científicos y analistas de datos suelen utilizar árboles de decisión cuando exploran nuevos conjuntos de datos porque son fáciles de construir e interpretar. Además, los árboles de decisión pueden ayudar a identificar características de datos importantes que pueden resultar útiles al aplicar algoritmos de aprendizaje automático más complejos.
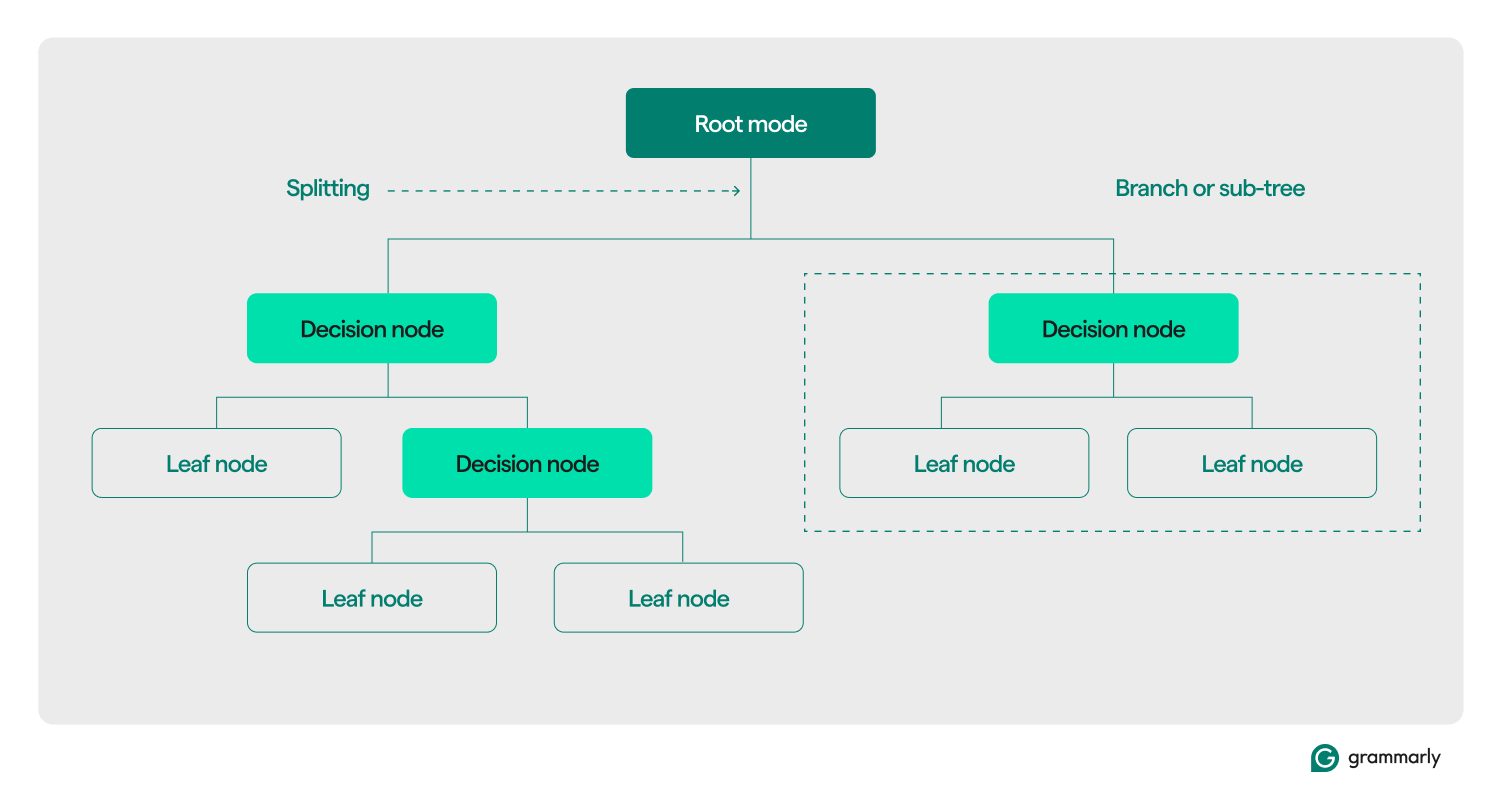
Terminología del árbol de decisión
Estructuralmente, un árbol de decisión normalmente consta de tres componentes: un nodo raíz, nodos hoja y nodos de decisión (o internos). Al igual que los diagramas de flujo o los árboles en otros dominios, las decisiones en un árbol generalmente se mueven en una dirección (hacia abajo o hacia arriba), comenzando desde el nodo raíz, pasando por algunos nodos de decisión y terminando en un nodo hoja específico. Cada nodo hoja conecta un subconjunto de datos de entrenamiento a una etiqueta. El árbol se ensambla mediante un proceso de optimización y capacitación de ML y, una vez creado, se puede aplicar a varios conjuntos de datos.
Aquí hay una inmersión más profunda en el resto de la terminología:
- Nodo raíz:un nodo que contiene la primera de una serie de preguntas que el árbol de decisión hará sobre los datos. El nodo estará conectado al menos a uno (pero normalmente dos o más) nodos de decisión o de hoja.
- Nodos de decisión (o nodos internos):Nodos adicionales que contienen preguntas. Un nodo de decisión contendrá exactamente una pregunta sobre los datos y dirigirá el flujo de datos a uno de sus hijos en función de la respuesta.
- Hijos:uno o más nodos a los que apunta un nodo raíz o de decisión. Representan una lista de las próximas opciones que puede tomar el proceso de toma de decisiones al analizar los datos.
- Nodos hoja (o nodos terminales):Nodos que indican que el proceso de decisión se ha completado. Una vez que el proceso de decisión llega a un nodo hoja, devolverá los valores del nodo hoja como salida.
- Etiqueta (clase, categoría):generalmente, una cadena asociada por un nodo hoja con algunos de los datos de entrenamiento. Por ejemplo, una hoja podría asociar la etiqueta "Cliente satisfecho" con un conjunto de clientes específicos que se presentó al algoritmo de entrenamiento de ML del árbol de decisiones.
- Rama (o subárbol):este es el conjunto de nodos que consta de un nodo de decisión en cualquier punto del árbol, junto con todos sus hijos y sus hijos, hasta los nodos hoja.
- Poda:una operación de optimización que normalmente se realiza en el árbol para hacerlo más pequeño y ayudarlo a generar resultados más rápido. La poda generalmente se refiere a la "poda posterior", que implica eliminar algorítmicamente nodos o ramas después de que el proceso de entrenamiento de ML haya construido el árbol. La “poda previa” se refiere a establecer un límite arbitrario sobre la profundidad o el tamaño que puede crecer un árbol de decisión durante el entrenamiento. Ambos procesos imponen una complejidad máxima para el árbol de decisión, generalmente medida por su profundidad o altura máxima. Las optimizaciones menos comunes incluyen limitar el número máximo de nodos de decisión o nodos hoja.
- División:el paso de transformación central realizado en un árbol de decisiones durante el entrenamiento. Implica dividir un nodo raíz o de decisión en dos o más subnodos.
- Clasificación:un algoritmo de aprendizaje automático que intenta determinar cuál (de una lista constante y discreta de clases, categorías o etiquetas) es la más probable de aplicar a un dato. Podría intentar responder preguntas como "¿Qué día de la semana es mejor para reservar un vuelo?" Más sobre la clasificación a continuación.
- Regresión:un algoritmo de aprendizaje automático que intenta predecir un valor continuo, que puede no siempre tener límites. Podría intentar responder (o predecir la respuesta) a preguntas como "¿Cuántas personas es probable que reserven un vuelo el próximo martes?" Hablaremos más sobre los árboles de regresión en la siguiente sección.
Tipos de árboles de decisión
Los árboles de decisión suelen agruparse en dos categorías: árboles de clasificación y árboles de regresión. Se puede crear un árbol específico para aplicarlo a casos de uso de clasificación, regresión o ambos. La mayoría de los árboles de decisión modernos utilizan el algoritmo CART (árboles de clasificación y regresión), que puede realizar ambos tipos de tareas.
Árboles de clasificación
Los árboles de clasificación, el tipo más común de árbol de decisión, intentan resolver un problema de clasificación. De una lista de posibles respuestas a una pregunta (a menudo tan simple como “sí” o “no”), un árbol de clasificación elegirá la más probable después de hacer algunas preguntas sobre los datos que se le presentan. Por lo general, se implementan como árboles binarios, lo que significa que cada nodo de decisión tiene exactamente dos hijos.
Los árboles de clasificación podrían intentar responder preguntas de opción múltiple como "¿Está satisfecho este cliente?" o "¿Qué tienda física es probable que visite este cliente?" o “¿Mañana será un buen día para ir al campo de golf?”
Los dos métodos más comunes para medir la calidad de un árbol de clasificación se basan en la ganancia de información y la entropía:
- Ganancia de información:la eficiencia de un árbol aumenta cuando hace menos preguntas antes de llegar a una respuesta. La ganancia de información mide qué tan "rápido" un árbol puede lograr una respuesta al evaluar cuánta información más se aprende sobre un dato en cada nodo de decisión. Evalúa si las preguntas más importantes y útiles se formulan primero en el árbol.
- Entropía:la precisión es crucial para las etiquetas de los árboles de decisión. Las métricas de entropía miden esta precisión evaluando las etiquetas producidas por el árbol. Evalúan la frecuencia con la que un dato aleatorio termina con la etiqueta incorrecta y la similitud entre todos los datos de entrenamiento que reciben la misma etiqueta.
Las medidas más avanzadas de la calidad de los árboles incluyen elíndice de Gini,el índice de ganancia,las evaluaciones de chi-cuadradoy varias medidas para la reducción de la varianza.
Árboles de regresión
Los árboles de regresión se utilizan normalmente en análisis de regresión para análisis estadísticos avanzados o para predecir datos de un rango continuo y potencialmente ilimitado. Dada una gama de opciones continuas (por ejemplo, de cero a infinito en la escala de números reales), el árbol de regresión intenta predecir la coincidencia más probable para un dato determinado después de formular una serie de preguntas. Cada pregunta reduce el rango potencial de respuestas. Por ejemplo, un árbol de regresión podría usarse para predecir puntajes crediticios, ingresos de una línea de negocio o la cantidad de interacciones en un video de marketing.
La precisión de los árboles de regresión generalmente se evalúa utilizando métricas comoel error cuadrático mediooel error absoluto medio, que calculan qué tan lejos se compara un conjunto específico de predicciones con los valores reales.
Cómo funcionan los árboles de decisión
Como ejemplo de aprendizaje supervisado, los árboles de decisión se basan en datos bien formateados para el entrenamiento. Los datos de origen suelen contener una lista de valores que el modelo debería aprender a predecir o clasificar. Cada valor debe tener una etiqueta adjunta y una lista de características asociadas (propiedades que el modelo debe aprender a asociar con la etiqueta).

Construcción o formación
Durante el proceso de entrenamiento, los nodos de decisión en el árbol de decisión se dividen recursivamente en nodos más específicos según uno o más algoritmos de entrenamiento. Una descripción del proceso a nivel humano podría verse así:
- Comience con el nodo raízconectado a todo el conjunto de entrenamiento.
- Divida el nodo raíz:utilizando un enfoque estadístico, asigne una decisión al nodo raíz en función de una de las características de los datos y distribuya los datos de entrenamiento a al menos dos nodos hoja separados, conectados como hijos a la raíz.
- Aplique recursivamente el paso dosa cada uno de los hijos, convirtiéndolos de nodos de hoja en nodos de decisión. Deténgase cuando se alcance algún límite (por ejemplo, la altura/profundidad del árbol, una medida de la calidad de los hijos en cada hoja en cada nodo, etc.) o si se ha quedado sin datos (es decir, cada hoja contiene datos puntos que están relacionados exactamente con una etiqueta).
La decisión sobre qué características considerar en cada nodo difiere para los casos de uso de clasificación, regresión y clasificación y regresión combinadas. Hay muchos algoritmos para elegir para cada escenario. Los algoritmos típicos incluyen:
- ID3 (clasificación):Optimiza la entropía y la ganancia de información.
- C4.5 (clasificación):una versión más compleja de ID3, que agrega normalización a la ganancia de información
- CART (clasificación/regresión): “Árbol de clasificación y regresión”; un algoritmo codicioso que optimiza la impureza mínima en los conjuntos de resultados
- CHAID (clasificación/regresión): “Detección automática de interacción Chi-cuadrado”; utiliza medidas de chi-cuadrado en lugar de entropía y ganancia de información
- MARS (clasificación/regresión): utiliza aproximaciones lineales por partes para capturar no linealidades
Un régimen de entrenamiento común es el bosque aleatorio. Un bosque aleatorio, o bosque de decisión aleatoria, es un sistema que construye muchos árboles de decisión relacionados. Se pueden entrenar varias versiones de un árbol en paralelo utilizando combinaciones de algoritmos de entrenamiento. Con base en varias mediciones de la calidad de los árboles, se utilizará un subconjunto de estos árboles para generar una respuesta. Para los casos de uso de clasificación, la clase seleccionada por la mayor cantidad de árboles se devuelve como respuesta. Para los casos de uso de regresión, la respuesta se agrega, generalmente como la predicción media o promedio de árboles individuales.
Evaluación y uso de árboles de decisión.
Una vez que se ha construido un árbol de decisión, puede clasificar nuevos datos o predecir valores para un caso de uso específico. Es importante mantener métricas sobre el rendimiento de los árboles y utilizarlas para evaluar la precisión y la frecuencia de errores. Si el modelo se desvía demasiado del rendimiento esperado, podría ser el momento de volver a entrenarlo con nuevos datos o encontrar otros sistemas de aprendizaje automático para aplicar a ese caso de uso.
Aplicaciones de árboles de decisión en ML
Los árboles de decisión tienen una amplia gama de aplicaciones en diversos campos. A continuación se muestran algunos ejemplos para ilustrar su versatilidad:
Toma de decisiones personales informadas
Un individuo podría realizar un seguimiento de los datos sobre, por ejemplo, los restaurantes que ha estado visitando. Podrían realizar un seguimiento de cualquier detalle relevante, como tiempo de viaje, tiempo de espera, cocina ofrecida, horario de apertura, puntuación promedio de reseñas, costo y visita más reciente, junto con una puntuación de satisfacción por la visita del individuo a ese restaurante. Se puede entrenar un árbol de decisiones con estos datos para predecir la puntuación de satisfacción probable de un nuevo restaurante.
Calcule probabilidades en torno al comportamiento del cliente
Los sistemas de atención al cliente pueden utilizar árboles de decisión para predecir o clasificar la satisfacción del cliente. Se puede entrenar un árbol de decisiones para predecir la satisfacción del cliente en función de varios factores, como si el cliente se puso en contacto con el servicio de asistencia técnica o realizó una compra repetida o en función de las acciones realizadas dentro de una aplicación. Además, puede incorporar resultados de encuestas de satisfacción u otros comentarios de los clientes.
Ayude a informar las decisiones comerciales
Para determinadas decisiones comerciales con una gran cantidad de datos históricos, un árbol de decisiones puede proporcionar estimaciones o predicciones para los siguientes pasos. Por ejemplo, una empresa que recopila información demográfica y geográfica sobre sus clientes puede formar un árbol de decisiones para evaluar qué nuevas ubicaciones geográficas probablemente sean rentables o deberían evitarse. Los árboles de decisión también pueden ayudar a determinar los mejores límites de clasificación para los datos demográficos existentes, como identificar rangos de edad para considerar por separado al agrupar clientes.
Selección de funciones para ML avanzado y otros casos de uso
Las estructuras de los árboles de decisión son legibles y comprensibles para los humanos. Una vez que se construye un árbol, es posible identificar qué características son más relevantes para el conjunto de datos y en qué orden. Esta información puede guiar el desarrollo de sistemas de aprendizaje automático o algoritmos de decisión más complejos. Por ejemplo, si una empresa aprende de un árbol de decisiones que los clientes priorizan el costo de un producto por encima de todo, puede centrar sistemas de aprendizaje automático más complejos en esta información o ignorar el costo al explorar características más matizadas.
Ventajas de los árboles de decisión en ML
Los árboles de decisión ofrecen varias ventajas importantes que los convierten en una opción popular en aplicaciones de aprendizaje automático. Éstos son algunos de los beneficios clave:
Rápido y fácil de construir
Los árboles de decisión son uno de los algoritmos de aprendizaje automático más maduros y mejor comprendidos. No dependen de cálculos particularmente complejos y se pueden construir rápida y fácilmente. Siempre que la información requerida esté disponible, un árbol de decisiones es un primer paso fácil de tomar al considerar soluciones de ML a un problema.
Fácil de entender para los humanos.
El resultado de los árboles de decisión es particularmente fácil de leer e interpretar. La representación gráfica de un árbol de decisión no depende de un conocimiento avanzado de estadística. Como tales, los árboles de decisión y sus representaciones pueden usarse para interpretar, explicar y respaldar los resultados de análisis más complejos. Los árboles de decisión son excelentes para encontrar y resaltar algunas de las propiedades de alto nivel de un conjunto de datos determinado.
Se requiere un procesamiento mínimo de datos
Los árboles de decisión se pueden construir con la misma facilidad a partir de datos incompletos o datos que incluyan valores atípicos. Dados los datos decorados con características interesantes, los algoritmos del árbol de decisión tienden a no verse tan afectados como otros algoritmos de ML si reciben datos que no han sido preprocesados.
Desventajas de los árboles de decisión en ML
Si bien los árboles de decisión ofrecen muchos beneficios, también presentan varios inconvenientes:
Susceptible al sobreajuste
Los árboles de decisión son propensos al sobreajuste, lo que ocurre cuando un modelo aprende el ruido y los detalles de los datos de entrenamiento, lo que reduce su rendimiento con datos nuevos. Por ejemplo, si los datos de entrenamiento están incompletos o son escasos, pequeños cambios en los datos pueden producir estructuras de árbol significativamente diferentes. Técnicas avanzadas como podar o establecer una profundidad máxima pueden mejorar el comportamiento de los árboles. En la práctica, los árboles de decisión a menudo necesitan actualizarse con nueva información, lo que puede alterar significativamente su estructura.
Poca escalabilidad
Además de su tendencia a sobreajustarse, los árboles de decisión luchan con problemas más avanzados que requieren muchos más datos. En comparación con otros algoritmos, el tiempo de entrenamiento de los árboles de decisión aumenta rápidamente a medida que crecen los volúmenes de datos. Para conjuntos de datos más grandes que podrían tener importantes propiedades de alto nivel para detectar, los árboles de decisión no son una buena opción.
No es tan eficaz para casos de uso continuo o de regresión
Los árboles de decisión no aprenden muy bien las distribuciones de datos complejas. Dividen el espacio de características según líneas que son fáciles de entender pero matemáticamente simples. Para problemas complejos donde los valores atípicos son relevantes, regresión y casos de uso continuo, esto a menudo se traduce en un rendimiento mucho peor que otros modelos y técnicas de ML.