
Puntuación de F1 en el aprendizaje automático: cómo calcular, aplicarlo y usarlo de manera efectiva
Publicado: 2025-02-10La puntuación F1 es una métrica poderosa para evaluar los modelos de aprendizaje automático (ML) diseñados para realizar una clasificación binaria o multiclase. Este artículo explicará cuál es el puntaje F1, por qué es importante, cómo se calcula y sus aplicaciones, beneficios y limitaciones.
Tabla de contenido
- ¿Qué es un puntaje F1?
- Cómo calcular una puntuación F1
- Puntaje F1 vs. precisión
- Aplicaciones del puntaje F1
- Beneficios del puntaje F1
- Limitaciones de la puntuación F1
¿Qué es un puntaje F1?
Los practicantes de ML enfrentan un desafío común al construir modelos de clasificación: capacitar al modelo para atrapar todos los casos mientras evitan falsas alarmas. Esto es particularmente importante en aplicaciones críticas como la detección de fraude financiero y el diagnóstico médico, donde las falsas alarmas y la falta de clasificaciones importantes tienen graves consecuencias. Lograr el equilibrio correcto es particularmente importante cuando se trata de conjuntos de datos desequilibrados, donde una categoría como las transacciones fraudulentas es mucho más raramente que la otra categoría (transacciones legítimas).
Precisión y retiro
Para medir la calidad del rendimiento del modelo, la puntuación F1 combina dos métricas relacionadas:
- Precisión, qué respuestas, "Cuando el modelo predice un caso positivo, ¿con qué frecuencia es correcta?"
- Recuerde, qué respuestas, "de todos los casos positivos reales, ¿cuántos identificó correctamente el modelo?"
Un modelo con alta precisión pero bajo retiro es demasiado cauteloso, le faltan muchos aspectos positivos verdaderos, mientras que uno con alto recuerdo, pero la baja precisión es demasiado agresiva, generando muchos falsos positivos. El puntaje F1 entienda un equilibrio al tomar la media armónica de precisión y retiro, lo que da más peso a valores más bajos y asegura que un modelo funcione bien en ambas métricas en lugar de sobresalir en una sola.
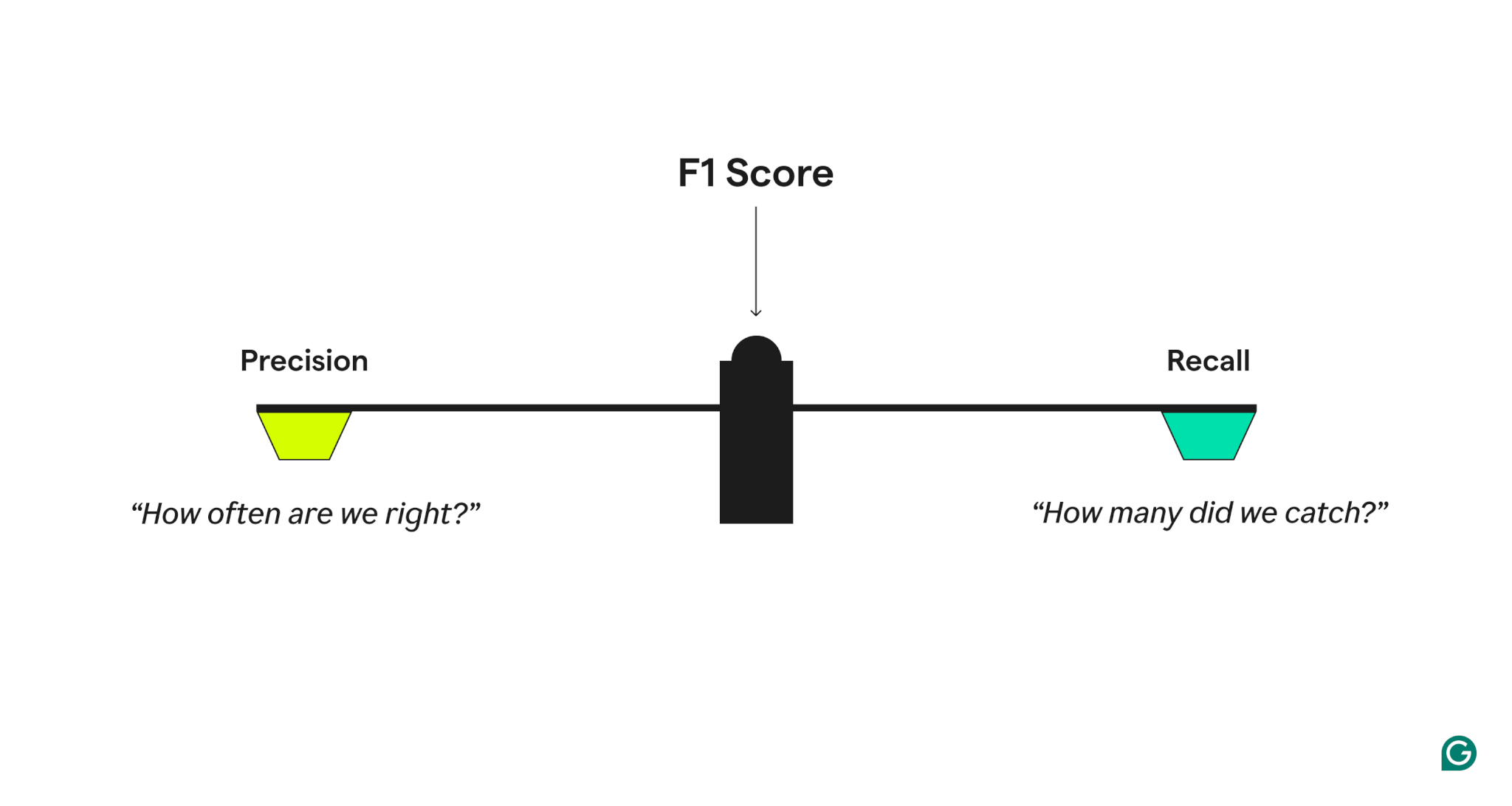
Ejemplo de precisión y recuerdo
Para comprender mejor la precisión y el recuerdo, considere un sistema de detección de spam. Si el sistema tiene una alta tasa de correos electrónicos correctamente marcados como spam, esto significa que tiene una alta precisión. Por ejemplo, si el sistema marca 100 correos electrónicos como spam, y 90 de ellos son realmente spam, la precisión es del 90%. Alto retiro, por otro lado, significa que el sistema atrapa la mayoría de los correos electrónicos de spam reales. Por ejemplo, si hay 200 correos electrónicos spam reales y nuestro sistema atrapa a 90 de ellos, el retiro es del 45%.
Variantes de la puntuación F1
En los sistemas o escenarios de clasificación multiclase con necesidades específicas, la puntuación F1 se puede calcular de diferentes maneras, dependiendo de los factores importantes:
- Macro-F1:calcula la puntuación F1 por separado para cada clase y toma el promedio
- Micro-F1:calcula el recuerdo y la precisión sobre todas las predicciones
- Peso-F1: similar a macro-F1, pero las clases se ponderan en función de la frecuencia
Más allá del puntaje F1: la familia de puntaje F
El puntaje F1 es parte de una familia más grande de métricas llamada F-puntajes F. Estos puntajes ofrecen diferentes formas de peso y recuperación:
- F2:pone mayor énfasis en el recuerdo, que es útil cuando los falsos negativos son costosos
- F0.5:pone mayor énfasis en la precisión, lo cual es útil cuando los falsos positivos son costosos
Cómo calcular una puntuación F1
La puntuación F1 se define matemáticamente como la media armónica de precisión y retiro. Si bien esto puede sonar complejo, el proceso de cálculo es sencillo cuando se descompone en pasos claros.
La fórmula para la puntuación F1:

Antes de sumergirse en los pasos para calcular F1, es importante comprender los componentes clave de lo que se llamamatriz de confusión, que se utiliza para organizar los resultados de clasificación:
- Verdaderos positivos (TP):el número de casos identificados correctamente como positivo
- Falsos positivos (FP):el número de casos identificados incorrectamente como positivo
- Falsos negativos (FN):el número de casos perdidos (positivos reales que no fueron identificados)
El proceso general implica capacitar el modelo, probar predicciones y organizar resultados, calcular la precisión y el recuerdo, y calcular la puntuación F1.
Paso 1: Entrenar un modelo de clasificación
Primero, un modelo debe ser entrenado para hacer clasificaciones binarias o multiclase. Esto significa que el modelo debe poder clasificar los casos como pertenecientes a una de las dos categorías. Los ejemplos incluyen "spam/no spam" y "fraude/no fraude".
Paso 2: Prueba predicciones y organiza resultados
A continuación, use el modelo para realizar clasificaciones en un conjunto de datos separado que no se usara como parte de la capacitación. Organice los resultados en la matriz de confusión. Esta matriz muestra:
- TP: ¿Cuántas predicciones eran realmente correctas?
- FP: ¿Cuántas predicciones positivas fueron incorrectas?
- FN: ¿Cuántos casos positivos se perdieron?
La matriz de confusión proporciona una visión general de cómo está funcionando el modelo.
Paso 3: Calcular la precisión
Usando la matriz de confusión, la precisión se calcula con esta fórmula:

Por ejemplo, si un modelo de detección de spam identificaba correctamente 90 correos electrónicos de spam (TP) pero marcaba incorrectamente 10 correos electrónicos nopam (FP), la precisión es 0.90.

Paso 4: Calcular el recuerdo
A continuación, calcule el recuerdo usando la fórmula:

Usando el ejemplo de detección de spam, si hubiera 200 correos electrónicos de spam totales, y el modelo atrapó a 90 de ellos (TP) mientras faltaba 110 (FN), el retiro es 0.45.

Paso 5: Calcule la puntuación F1
Con los valores de precisión y recuperación en la mano, se puede calcular la puntuación F1.
El puntaje F1 varía de 0 a 1. Al interpretar el puntaje, considere estos puntos de referencia generales:
- 0.9 o superior:el modelo está funcionando muy bien, pero debe verificarse para el sobreajuste.
- 0.7 a 0.9:buen rendimiento para la mayoría de las aplicaciones
- 0.5 a 0.7:El rendimiento está bien, pero el modelo podría usar una mejora.
- 0.5 o menos:el modelo funciona mal y necesita una mejora seria.
Usando los cálculos de ejemplo de detección de spam para precisión y recuerdo, la puntuación F1 sería 0.60 o 60%.


En este caso, la puntuación F1 indica que, incluso con alta precisión, el recuerdo más bajo está afectando el rendimiento general. Esto sugiere que hay margen de mejora en la captura de más correos electrónicos de spam.
Puntaje F1 vs. precisión
Si bien tanto F1 comola precisióncuantifican el rendimiento del modelo, la puntuación F1 proporciona una medida más matizada. La precisión simplemente calcula el porcentaje de predicciones correctas. Sin embargo, solo confiar en la precisión para medir el rendimiento del modelo puede ser problemático cuando el número de instancias de una categoría en un conjunto de datos supera significativamente la otra categoría. Este problema se conoce como laparadoja de precisión.
Para comprender este problema, considere el ejemplo del sistema de detección de spam. Supongamos que un sistema de correo electrónico recibe 1,000 correos electrónicos todos los días, pero solo 10 de ellos son en realidad spam. Si la detección de spam simplemente clasifica cada correo electrónico como no spam, aún alcanzará una precisión del 99%. Esto se debe a que 990 predicciones de 1,000 eran correctas, a pesar de que el modelo es realmente inútil cuando se trata de detección de spam. Claramente, la precisión no da una imagen precisa de la calidad del modelo.
La puntuación F1 evita este problema combinando las mediciones de precisión y recuperación. Por lo tanto, F1 debe usarse en lugar de precisión en los siguientes casos:
- El conjunto de datos está desequilibrado.Esto es común en los campos como el diagnóstico de afecciones médicas oscuras o la detección de spam, donde una categoría es relativamente rara.
- FN y FP son importantes.Por ejemplo, las pruebas de detección médica buscan equilibrar problemas reales al no aumentar las falsas alarmas.
- El modelo debe lograr un equilibrio entre ser demasiado agresivo y demasiado cauteloso.Por ejemplo, en el filtrado de spam, un filtro demasiado cauteloso podría permitir que sea demasiado spam (bajo retiro) pero rara vez comete errores (alta precisión). Por otro lado, un filtro demasiado agresivo podría bloquear correos electrónicos reales (baja precisión) incluso si atrapa todo el spam (retiro alto).
Aplicaciones del puntaje F1
El puntaje F1 tiene una amplia gama de aplicaciones en varias industrias donde la clasificación equilibrada es crítica. Estas aplicaciones incluyen detección de fraude financiero, diagnóstico médico y moderación de contenido.
Detección de fraude financiero
Los modelos diseñados para detectar fraude financiero son una categoría de sistemas muy adecuados para la medición utilizando el puntaje F1. Las empresas financieras a menudo procesan millones o miles de millones de transacciones diariamente, con casos reales de fraude relativamente raros. Por esta razón, un sistema de detección de fraude necesita atrapar tantas transacciones fraudulentas como sea posible, al tiempo que minimiza simultáneamente el número de falsas alarmas e inconvenientes resultantes para los clientes. Medir el puntaje F1 puede ayudar a las instituciones financieras a determinar qué tan bien sus sistemas equilibran los pilares gemelos de la prevención de fraude y una buena experiencia del cliente.
Diagnóstico médico
En el diagnóstico y las pruebas médicas, FN y FP tienen consecuencias graves. Considere el ejemplo de un modelo diseñado para detectar formas raras de cáncer. Diagnóstico incorrectamente a un paciente sano podría conducir a un estrés y tratamiento innecesarios, mientras que la falta de un caso de cáncer real tendrá consecuencias graves para el paciente. En otras palabras, el modelo debe tener una alta precisión y un alto retiro, que es algo que la puntuación F1 puede medir.
Moderación de contenido
La moderación del contenido es un desafío común en foros en línea, plataformas de redes sociales y mercados en línea. Para lograr la seguridad de la plataforma sin exceso de censura, estos sistemas deben equilibrar la precisión y el recuerdo. El puntaje F1 puede ayudar a las plataformas a determinar qué tan bien su sistema equilibra estos dos factores.
Beneficios del puntaje F1
Además de proporcionar generalmente una visión más matizada del rendimiento del modelo que la precisión, la puntuación F1 proporciona varias ventajas clave al evaluar el rendimiento del modelo de clasificación. Estos beneficios incluyen capacitación y optimización de modelos más rápidos, costos de capacitación reducidos y captura de sobreajuste temprano.
Entrenamiento y optimización de modelos más rápidos
La puntuación F1 puede ayudar a acelerar la capacitación del modelo proporcionando una métrica de referencia clara que se puede utilizar para guiar la optimización. En lugar de ajustar el recuerdo y la precisión por separado, que generalmente involucra compensaciones complejas, los practicantes de ML pueden centrarse en aumentar la puntuación F1. Con este enfoque optimizado, los parámetros del modelo óptimos se pueden identificar rápidamente.
Costos de capacitación reducidos
El puntaje de F1 puede ayudar a los profesionales de ML a tomar decisiones informadas sobre cuándo un modelo está listo para la implementación al proporcionar una medida única y matizada del rendimiento del modelo. Con esta información, los profesionales pueden evitar ciclos de capacitación innecesarios, inversiones en recursos computacionales y tener que adquirir o crear datos de capacitación adicionales. En general, esto puede conducir a reducciones sustanciales de costos cuando entrenan modelos de clasificación.
Atrapar el sobreajuste temprano
Dado que la puntuación F1 considera tanto la precisión como el retiro, puede ayudar a los profesionales de ML a identificar cuándo un modelo se está volviendo demasiado especializado en los datos de capacitación. Este problema, llamado sobreajuste, es un problema común con los modelos de clasificación. La puntuación F1 ofrece a los profesionales una advertencia temprana de que necesitan ajustar la capacitación antes de que el modelo llegue a un punto en el que no puede generalizar los datos del mundo real.
Limitaciones de la puntuación F1
A pesar de sus muchos beneficios, el puntaje F1 tiene varias limitaciones importantes que los profesionales deberían considerar. Estas limitaciones incluyen una falta de sensibilidad a los verdaderos negativos, no ser adecuados para algunos conjuntos de datos y ser más difícil de interpretar para los problemas multiclase.
Falta de sensibilidad a los verdaderos negativos
El puntaje F1 no tiene en cuenta los verdaderos negativos, lo que significa que no es muy adecuado para las aplicaciones donde la medición de esto es importante. Por ejemplo, considere un sistema diseñado para identificar condiciones de conducción seguras. En este caso, identificar correctamente cuándo las condiciones son realmente seguras (verdaderas negativas) es tan importante como la identificación de condiciones peligrosas. Debido a que no rastrea FN, la puntuación F1 no capturaría con precisión este aspecto del rendimiento general del modelo.
No adecuado para algunos conjuntos de datos
El puntaje F1 puede no ser adecuado para conjuntos de datos donde el impacto de FP y FN es significativamente diferente. Considere el ejemplo de un modelo de detección de cáncer. En tal situación, perder un caso positivo (FN) podría ser potencialmente mortal, mientras que encontrar erróneamente un caso positivo (FP) solo conduce a pruebas adicionales. Por lo tanto, usar una métrica que se pueda ponderar para tener en cuenta este costo es una mejor opción que el puntaje F1.
Más difícil de interpretar para problemas multiclase
Si bien las variaciones como las puntuaciones Micro-F1 y Macro-F1 significan que la puntuación F1 puede usarse para evaluar los sistemas de clasificación multiclase, interpretar estas métricas agregadas a menudo es más compleja que la puntuación binaria F1. Por ejemplo, la puntuación Micro-F1 podría ocultar un bajo rendimiento en la clasificación de clases menos frecuentes, mientras que la puntuación macro-F1 podría sobrepeso clases raras. Dado esto, las empresas deben considerar si el tratamiento igualitario de las clases o el rendimiento general a nivel de instancia es más importante al elegir la variante F1 correcta para los modelos de clasificación multiclase.