
¿Qué es el sobreajuste en el aprendizaje automático?
Publicado: 2024-10-15El sobreajuste es un problema común que surge al entrenar modelos de aprendizaje automático (ML). Puede afectar negativamente la capacidad de un modelo para generalizar más allá de los datos de entrenamiento, lo que genera predicciones inexactas en escenarios del mundo real. En este artículo, exploraremos qué es el sobreajuste, cómo ocurre, las causas comunes detrás de él y formas efectivas de detectarlo y prevenirlo.
Tabla de contenido
- ¿Qué es el sobreajuste?
- Cómo ocurre el sobreajuste
- Sobreajuste versus desajuste
- ¿Qué causa el sobreajuste?
- Cómo detectar el sobreajuste
- Cómo evitar el sobreajuste
- Ejemplos de sobreajuste
¿Qué es el sobreajuste?
El sobreajuste ocurre cuando un modelo de aprendizaje automático aprende los patrones subyacentes y el ruido en los datos de entrenamiento, volviéndose demasiado especializado en ese conjunto de datos específico. Este enfoque excesivo en los detalles de los datos de entrenamiento da como resultado un rendimiento deficiente cuando el modelo se aplica a datos nuevos e invisibles, ya que no logra generalizar más allá de los datos con los que fue entrenado.
¿Cómo ocurre el sobreajuste?
El sobreajuste ocurre cuando un modelo aprende demasiado de los detalles específicos y del ruido en los datos de entrenamiento, lo que lo hace demasiado sensible a patrones que no son significativos para la generalización. Por ejemplo, considere un modelo creado para predecir el desempeño de los empleados basándose en evaluaciones históricas. Si el modelo se ajusta demasiado, podría centrarse demasiado en detalles específicos y no generalizables, como el estilo de calificación único de un ex gerente o circunstancias particulares durante un ciclo de revisión anterior. En lugar de aprender los factores más amplios y significativos que contribuyen al desempeño (como las habilidades, la experiencia o los resultados del proyecto), el modelo puede tener dificultades para aplicar su conocimiento a nuevos empleados o desarrollar criterios de evaluación. Esto conduce a predicciones menos precisas cuando el modelo se aplica a datos que difieren del conjunto de entrenamiento.
Sobreajuste versus desajuste
A diferencia del sobreajuste, el desajuste se produce cuando un modelo es demasiado simple para capturar los patrones subyacentes en los datos. Como resultado, tiene un rendimiento deficiente tanto en el entrenamiento como en los datos nuevos, y no logra hacer predicciones precisas.
Para visualizar la diferencia entre desajuste y sobreajuste, imaginemos que intentamos predecir el rendimiento deportivo en función del nivel de estrés de una persona. Podemos trazar los datos y mostrar tres modelos que intentan predecir esta relación:

1 Ajuste insuficiente:en el primer ejemplo, el modelo utiliza una línea recta para hacer predicciones, mientras que los datos reales siguen una curva. El modelo es demasiado simple y no logra captar la complejidad de la relación entre el nivel de estrés y el rendimiento deportivo. Como resultado, las predicciones son en su mayoría inexactas, incluso para los datos de entrenamiento. Esto es insuficiente.
2Ajuste óptimo:el segundo ejemplo muestra un modelo que logra el equilibrio adecuado. Capta la tendencia subyacente en los datos sin complicarla demasiado. Este modelo se generaliza bien a datos nuevos porque no intenta adaptarse a cada pequeña variación en los datos de entrenamiento, solo al patrón central.
3Sobreajuste:en el ejemplo final, el modelo utiliza una curva ondulada muy compleja para ajustar los datos de entrenamiento. Si bien esta curva es muy precisa para los datos de entrenamiento, también captura ruido aleatorio y valores atípicos que no representan la relación real. Este modelo está sobreajustado porque está tan ajustado a los datos de entrenamiento que es probable que haga predicciones deficientes sobre datos nuevos e invisibles.
Causas comunes de sobreajuste
Ahora que sabemos qué es el sobreajuste y por qué ocurre, exploremos algunas causas comunes con más detalle:
- Datos de entrenamiento insuficientes
- Datos inexactos, erróneos o irrelevantes
- pesos grandes
- Sobreentrenamiento
- La arquitectura del modelo es demasiado sofisticada.
Datos de entrenamiento insuficientes
Si su conjunto de datos de entrenamiento es demasiado pequeño, es posible que represente solo algunos de los escenarios que encontrará el modelo en el mundo real. Durante el entrenamiento, el modelo puede ajustarse bien a los datos. Sin embargo, es posible que vea imprecisiones importantes una vez que lo pruebe con otros datos. El pequeño conjunto de datos limita la capacidad del modelo para generalizar a situaciones invisibles, lo que lo hace propenso al sobreajuste.
Datos inexactos, erróneos o irrelevantes
Incluso si su conjunto de datos de entrenamiento es grande, puede contener errores. Estos errores pueden surgir de diversas fuentes, como que los participantes proporcionen información falsa en las encuestas o lecturas defectuosas de los sensores. Si el modelo intenta aprender de estas imprecisiones, se adaptará a patrones que no reflejan las verdaderas relaciones subyacentes, lo que conducirá a un sobreajuste.
pesos grandes
En los modelos de aprendizaje automático, los pesos son valores numéricos que representan la importancia asignada a características específicas de los datos al realizar predicciones. Cuando las ponderaciones se vuelven desproporcionadamente grandes, el modelo puede sobreajustarse y volverse demasiado sensible a ciertas características, incluido el ruido en los datos. Esto sucede porque el modelo se vuelve demasiado dependiente de características particulares, lo que perjudica su capacidad de generalizar a nuevos datos.
Sobreentrenamiento
Durante el entrenamiento, el algoritmo procesa datos en lotes, calcula el error de cada lote y ajusta los pesos del modelo para mejorar su precisión.
¿Es buena idea seguir entrenando el mayor tiempo posible? ¡No precisamente! El entrenamiento prolongado con los mismos datos puede hacer que el modelo memorice puntos de datos específicos, lo que limita su capacidad de generalizar a datos nuevos o invisibles, que es la esencia del sobreajuste. Este tipo de sobreajuste se puede mitigar mediante el uso de técnicas de parada temprana o monitoreando el desempeño del modelo en un conjunto de validación durante el entrenamiento. Discutiremos cómo funciona esto más adelante en el artículo.
La arquitectura del modelo es demasiado compleja.
La arquitectura de un modelo de aprendizaje automático se refiere a cómo se estructuran sus capas y neuronas y cómo interactúan para procesar la información.

Las arquitecturas más complejas pueden capturar patrones detallados en los datos de entrenamiento. Sin embargo, esta complejidad aumenta la probabilidad de sobreajuste, ya que el modelo también puede aprender a capturar ruido o detalles irrelevantes que no contribuyen a predicciones precisas sobre nuevos datos. Simplificar la arquitectura o utilizar técnicas de regularización puede ayudar a reducir el riesgo de sobreajuste.
Cómo detectar el sobreajuste
Detectar el sobreajuste puede ser complicado porque puede parecer que todo va bien durante el entrenamiento, incluso cuando se produce un sobreajuste. La tasa de pérdida (o error), una medida de la frecuencia con la que el modelo se equivoca, seguirá disminuyendo, incluso en un escenario de sobreajuste. Entonces, ¿cómo podemos saber si se ha producido un sobreajuste? Necesitamos una prueba confiable.
Un método eficaz es utilizar una curva de aprendizaje, un gráfico que sigue una medida llamada pérdida. La pérdida representa la magnitud del error que está cometiendo el modelo. Sin embargo, no solo realizamos un seguimiento de la pérdida de datos de entrenamiento; También medimos la pérdida de datos invisibles, llamados datos de validación. Es por eso que la curva de aprendizaje suele tener dos líneas: pérdida de entrenamiento y pérdida de validación.
Si la pérdida de entrenamiento continúa disminuyendo como se esperaba, pero la pérdida de validación aumenta, esto sugiere un sobreajuste. En otras palabras, el modelo se está volviendo demasiado especializado en los datos de entrenamiento y tiene dificultades para generalizarse a datos nuevos e invisibles. La curva de aprendizaje podría verse así:
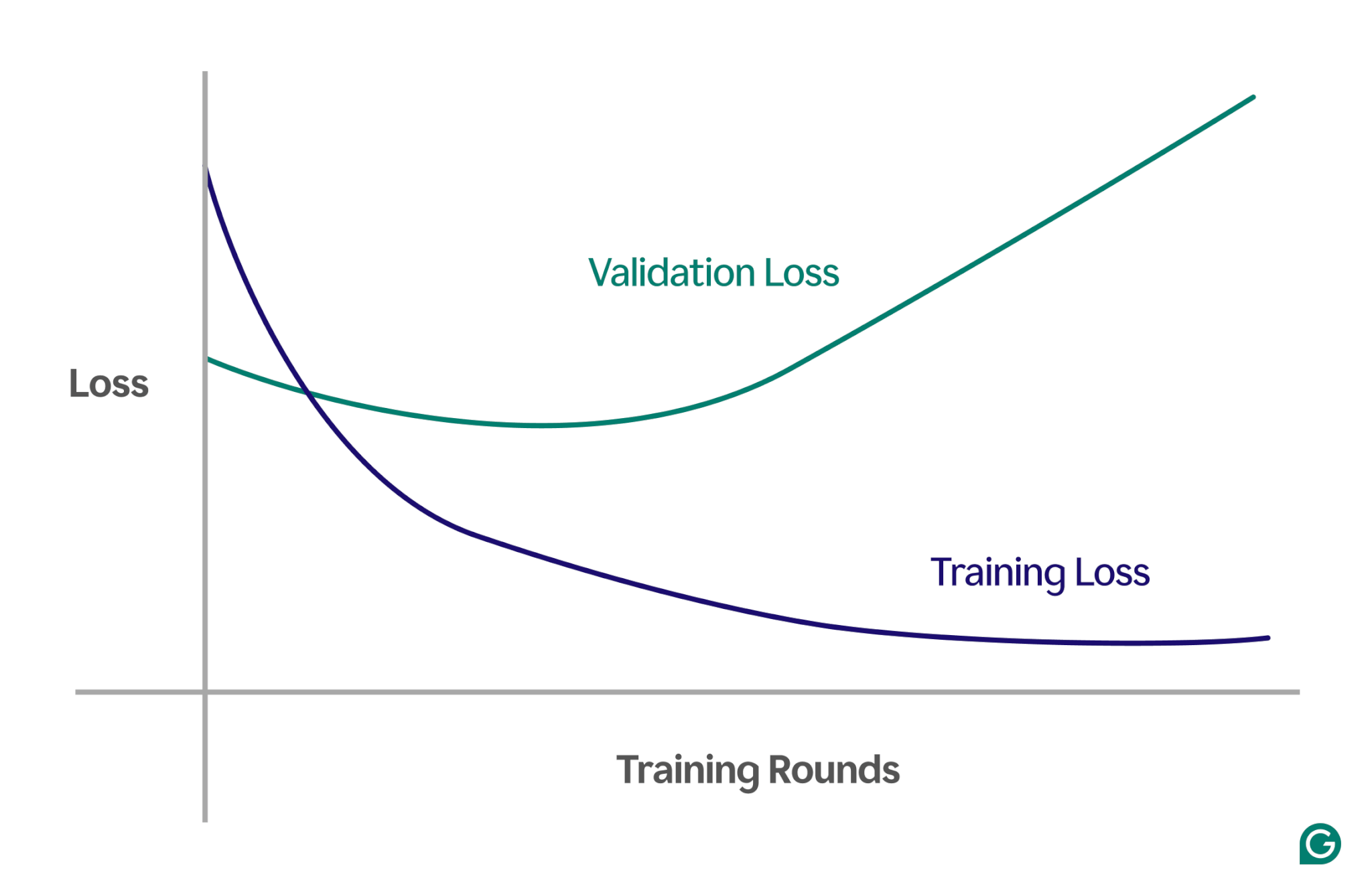
En este escenario, si bien el modelo mejora durante el entrenamiento, su rendimiento es deficiente con datos invisibles. Esto probablemente significa que se ha producido un sobreajuste.
Cómo evitar el sobreajuste
El sobreajuste se puede abordar mediante varias técnicas. Éstos son algunos de los métodos más comunes:
Reducir el tamaño del modelo.
La mayoría de las arquitecturas de modelos le permiten ajustar la cantidad de pesos cambiando la cantidad de capas, el tamaño de las capas y otros parámetros conocidos como hiperparámetros. Si la complejidad del modelo provoca un sobreajuste, reducir su tamaño puede resultar útil. Simplificar el modelo reduciendo el número de capas o neuronas puede reducir el riesgo de sobreajuste, ya que el modelo tendrá menos oportunidades de memorizar los datos de entrenamiento.
Regularizar el modelo
La regularización implica modificar el modelo para desalentar pesos grandes. Un enfoque es ajustar la función de pérdida para que mida el error e incluya el tamaño de las ponderaciones.
Con la regularización, el algoritmo de entrenamiento minimiza tanto el error como el tamaño de los pesos, reduciendo la probabilidad de pesos grandes a menos que proporcionen una ventaja clara al modelo. Esto ayuda a evitar el sobreajuste manteniendo el modelo más generalizado.
Añadir más datos de entrenamiento
Aumentar el tamaño del conjunto de datos de entrenamiento también puede ayudar a evitar el sobreajuste. Con más datos, es menos probable que el modelo se vea influenciado por el ruido o las imprecisiones en el conjunto de datos. Exponer el modelo a ejemplos más variados lo hará menos propenso a memorizar puntos de datos individuales y, en cambio, aprenderá patrones más amplios.
Aplicar reducción de dimensionalidad
A veces, los datos pueden contener características (o dimensiones) correlacionadas, lo que significa que varias características están relacionadas de alguna manera. Los modelos de aprendizaje automático tratan las dimensiones como independientes, por lo que si las características están correlacionadas, el modelo podría centrarse demasiado en ellas, lo que provocaría un sobreajuste.
Las técnicas estadísticas, como el análisis de componentes principales (PCA), pueden reducir estas correlaciones. PCA simplifica los datos al reducir la cantidad de dimensiones y eliminar correlaciones, lo que hace menos probable el sobreajuste. Al centrarse en las características más relevantes, el modelo mejora su generalización a nuevos datos.
Ejemplos prácticos de sobreajuste
Para comprender mejor el sobreajuste, exploremos algunos ejemplos prácticos en diferentes campos en los que el sobreajuste puede generar resultados engañosos.
Clasificación de imágenes
Los clasificadores de imágenes están diseñados para reconocer objetos en imágenes; por ejemplo, si una imagen contiene un pájaro o un perro.
Otros detalles pueden correlacionarse con lo que intentas detectar en estas imágenes. Por ejemplo, las fotografías de perros suelen tener hierba de fondo, mientras que las fotografías de pájaros suelen tener un cielo o copas de árboles de fondo.
Si todas las imágenes de entrenamiento tienen estos detalles de fondo consistentes, el modelo de aprendizaje automático puede comenzar a depender del fondo para reconocer al animal, en lugar de centrarse en las características reales del animal en sí. Como resultado, cuando se le pide al modelo que clasifique una imagen de un pájaro posado en un césped, es posible que lo clasifique incorrectamente como un perro porque se ajusta demasiado a la información de fondo. Este es un caso de sobreajuste de los datos de entrenamiento.
Modelado financiero
Supongamos que está negociando acciones en su tiempo libre y cree que es posible predecir movimientos de precios basándose en las tendencias de las búsquedas en Google de determinadas palabras clave. Configura un modelo de aprendizaje automático utilizando datos de Google Trends para miles de palabras.
Dado que hay tantas palabras, es probable que algunas muestren una correlación con los precios de sus acciones por pura casualidad. El modelo puede sobreajustar estas correlaciones coincidentes, haciendo malas predicciones sobre datos futuros porque las palabras no son predictores relevantes de los precios de las acciones.
Al crear modelos para aplicaciones financieras, es importante comprender la base teórica de las relaciones en los datos. Introducir grandes conjuntos de datos en un modelo sin una cuidadosa selección de características puede aumentar el riesgo de sobreajuste, especialmente cuando el modelo identifica correlaciones falsas que existen puramente por casualidad en los datos de entrenamiento.
Superstición deportiva
Aunque no están estrictamente relacionadas con el aprendizaje automático, las supersticiones deportivas pueden ilustrar el concepto de sobreajuste, especialmente cuando los resultados están vinculados a datos que lógicamente no tienen conexión con el resultado.
Durante la Eurocopa de fútbol de 2008 y la Copa Mundial de la FIFA de 2010, se utilizó un pulpo llamado Paul para predecir los resultados de los partidos en los que participaba Alemania. Paul acertó cuatro de seis predicciones en 2008 y las siete en 2010.
Si sólo se consideran los “datos de entrenamiento” de las predicciones pasadas de Paul, un modelo que concuerde con las elecciones de Paul parecería predecir muy bien los resultados. Sin embargo, este modelo no se generalizaría bien a juegos futuros, ya que las elecciones del pulpo no son predictores confiables de los resultados de los partidos.