
Bosques aleatorios en el aprendizaje automático: lo que son y cómo funcionan
Publicado: 2025-02-03Los bosques aleatorios son una técnica poderosa y versátil en el aprendizaje automático (ML). Esta guía lo ayudará a comprender los bosques aleatorios, cómo funcionan y sus aplicaciones, beneficios y desafíos.
Tabla de contenido
- ¿Qué es un bosque aleatorio?
- Árboles de decisión versus bosque aleatorio: ¿Cuál es la diferencia?
- Cómo funcionan los bosques al azar
- Aplicaciones prácticas de bosques aleatorios
- Ventajas de bosques aleatorios
- Desventajas de bosques aleatorios
¿Qué es un bosque aleatorio?
Un bosque aleatorio es un algoritmo de aprendizaje automático que utiliza múltiples árboles de decisión para hacer predicciones. Es un método de aprendizaje supervisado diseñado para tareas de clasificación y regresión. Al combinar los resultados de muchos árboles, un bosque aleatorio mejora la precisión, reduce el sobreajuste y proporciona predicciones más estables en comparación con un solo árbol de decisión.
Árboles de decisión versus bosque aleatorio: ¿Cuál es la diferencia?
Aunque los bosques aleatorios se basan en árboles de decisión, los dos algoritmos difieren significativamente en la estructura y la aplicación:
Árboles de decisión
Un árbol de decisión consta de tres componentes principales: un nodo raíz, nodos de decisión (nodos internos) y nodos de hoja. Al igual que un diagrama de flujo, el proceso de decisión comienza en el nodo raíz, fluye a través de los nodos de decisión en función de las condiciones y termina en un nodo de hoja que representa el resultado. Si bien los árboles de decisión son fáciles de interpretar y conceptualizar, también son propensos a un sobreajuste, especialmente con conjuntos de datos complejos o ruidosos.
Bosques aleatorios
Un bosque aleatorio es un conjunto de árboles de decisión que combina sus resultados para mejorar las predicciones. Cada árbol está entrenado en una muestra de arranque única (un subconjunto de muestras de muestras aleatorias del conjunto de datos original con reemplazo) y evalúa las divisiones de decisión utilizando un subconjunto de características seleccionado al azar en cada nodo. Este enfoque, conocido como bolsas de características, introduce diversidad entre los árboles. Al agregar las predicciones, utilizando la mayoría de la mayoría de la clasificación o promedios para la regresión, los bosques remunerados producen resultados más precisos y estables que cualquier árbol de decisión en el conjunto.
Cómo funcionan los bosques al azar
Los bosques aleatorios operan combinando múltiples árboles de decisión para crear un modelo de predicción robusto y preciso.
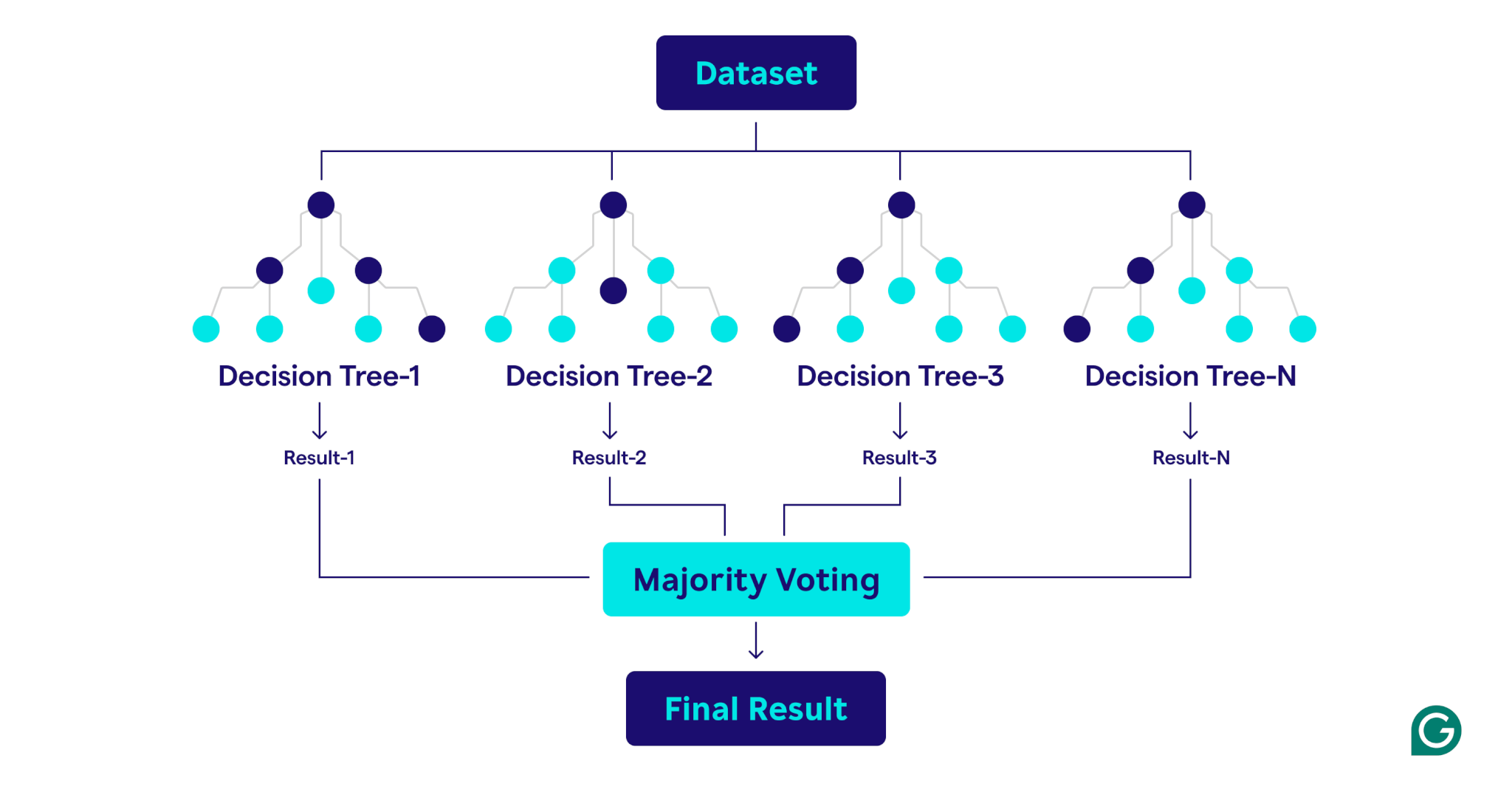
Aquí hay una explicación paso a paso del proceso:
1. Configuración de hiperparámetros
El primer paso es definir los hiperparámetros del modelo. Estos incluyen:
- Número de árboles:determina el tamaño del bosque
- Profundidad máxima para cada árbol:controla qué tan profundo puede crecer cada árbol de decisión
- Número de características consideradas en cada división:limita el número de características evaluadas al crear divisiones
Estos hiperparámetros permiten ajustar la complejidad del modelo y optimizar el rendimiento para conjuntos de datos específicos.
2. Muestreo de bootstrap
Una vez que se establecen los hiperparámetros, el proceso de capacitación comienza con el muestreo de bootstrap. Esto implica:
- Los puntos de datos del conjunto de datos original se seleccionan al azar para crear conjuntos de datos de entrenamiento (muestras de bootstrap) para cada árbol de decisión.
- Cada muestra de arranque es típicamente aproximadamente dos tercios del tamaño del conjunto de datos original, con algunos puntos de datos repetidos y otros excluidos.
- El tercio restante de los puntos de datos, no incluidos en la muestra de arranque, se conoce como datos fuera de bolsa (OOB).
3. Construcción de árboles de decisión
Cada árbol de decisión en el bosque aleatorio está entrenado en su muestra de arranque correspondiente utilizando un proceso único:
- Bolsaje de características:en cada división, se selecciona un subconjunto aleatorio de características, asegurando la diversidad entre los árboles.
- División de nodo:la mejor característica del subconjunto se usa para dividir el nodo:
- Para las tareas de clasificación, los criterios como la impureza de Gini (una medida de la frecuencia con la que un elemento elegido al azar se clasificaría incorrectamente si se etiquetara al azar de acuerdo con la distribución de etiquetas de clase en el nodo) mida qué tan bien la división separa las clases.
- Para las tareas de regresión, las técnicas como la reducción de la varianza (un método que mide cuánto división un nodo disminuye la varianza de los valores objetivo, lo que lleva a predicciones más precisas) evalúa cuánto reduce la división el error de predicción.
- El árbol crece de manera recursiva hasta que cumple con las condiciones de detención, como una profundidad máxima o un número mínimo de puntos de datos por nodo.
4. Evaluación del rendimiento
A medida que se construye cada árbol, el rendimiento del modelo se estima utilizando los datos OOB:
- La estimación de error OOB proporciona una medida imparcial del rendimiento del modelo, eliminando la necesidad de un conjunto de datos de validación por separado.
- Al agregar predicciones de todos los árboles, el bosque aleatorio logra una mayor precisión y reduce el sobreajuste en comparación con los árboles de decisión individuales.

Aplicaciones prácticas de bosques aleatorios
Al igual que los árboles de decisión en los que se construyen, los bosques aleatorios se pueden aplicar a problemas de clasificación y regresión en una amplia variedad de sectores, como la atención médica y las finanzas.
Clasificación de afecciones del paciente
En la atención médica, los bosques aleatorios se utilizan para clasificar las condiciones del paciente en función de la información como el historial médico, la demografía y los resultados de las pruebas. Por ejemplo, para predecir si es probable que un paciente desarrolle una condición específica como la diabetes, cada árbol de decisión clasifica al paciente como en riesgo o no en función de datos relevantes, y el bosque aleatorio realiza la determinación final basada en un voto mayoritario. Este enfoque significa que los bosques aleatorios son particularmente adecuados para los conjuntos de datos complejos y ricos en características que se encuentran en la atención médica.
Predecir los incumplimientos del préstamo
Los bancos y las principales instituciones financieras utilizan ampliamente bosques aleatorios para determinar la elegibilidad de los préstamos y comprender mejor el riesgo. El modelo utiliza factores como ingresos y puntaje de crédito para determinar el riesgo. Debido a que el riesgo se mide como un valor numérico continuo, el bosque aleatorio realiza regresión en lugar de clasificación. Cada árbol de decisión, entrenado en muestras de arranque ligeramente diferentes, genera una puntuación de riesgo prevista. Luego, el bosque aleatorio promedia todas las predicciones individuales, lo que resulta en una estimación de riesgo sólida y holística.
Predecir la pérdida de clientes
En marketing, los bosques aleatorios a menudo se usan para predecir la probabilidad de que un cliente que descontinice el uso de un producto o servicio. Esto implica analizar los patrones de comportamiento del cliente, como la frecuencia de compra e interacciones con el servicio al cliente. Al identificar estos patrones, los bosques aleatorios pueden clasificar a los clientes en riesgo de irse. Con estas ideas, las empresas pueden tomar medidas proactivas basadas en datos para retener a los clientes, como ofrecer programas de fidelización o promociones dirigidas.
Predecir los precios inmobiliarios
Los bosques aleatorios pueden usarse para predecir los precios inmobiliarios, que es una tarea de regresión. Para hacer la predicción, el bosque aleatorio utiliza datos históricos que incluyen factores como la ubicación geográfica, el metro cuadrado y las ventas recientes en el área. El proceso de promedio del bosque aleatorio da como resultado una predicción de precios más confiable y estable que la de un árbol de decisión individual, que es útil en los mercados inmobiliarios altamente volátiles.
Ventajas de bosques aleatorios
Los bosques aleatorios ofrecen numerosas ventajas, que incluyen precisión, robustez, versatilidad y la capacidad de estimar la importancia.
Precisión y robustez
Los bosques aleatorios son más precisos y robustos que los árboles de decisión individuales. Esto se logra combinando las salidas de múltiples árboles de decisión entrenados en diferentes muestras de arranque del conjunto de datos original. La diversidad resultante significa que los bosques aleatorios son menos propensos al sobreajuste que los árboles de decisión individuales. Este enfoque de conjunto significa que los bosques aleatorios son buenos para manejar datos ruidosos, incluso en conjuntos de datos complejos.
Versatilidad
Al igual que los árboles de decisión en los que se construyen, los bosques aleatorios son altamente versátiles. Pueden manejar tareas de regresión y clasificación, haciéndolas aplicables a una amplia gama de problemas. Los bosques aleatorios también funcionan bien con conjuntos de datos grandes ricos en características y pueden manejar datos numéricos y categóricos.
Importancia
Los bosques aleatorios tienen una capacidad incorporada para estimar la importancia de características particulares. Como parte del proceso de entrenamiento, los bosques aleatorios obtienen una puntuación que mide cuánto cambia la precisión del modelo si se elimina una característica particular. Al promediar los puntajes para cada característica, los bosques aleatorios pueden proporcionar una medida cuantificable de importancia de la característica. Se pueden eliminar características menos importantes para crear árboles y bosques más eficientes.
Desventajas de bosques aleatorios
Si bien los bosques aleatorios ofrecen muchos beneficios, son más difíciles de interpretar y más costosos de entrenar que un solo árbol de decisión, y pueden generar predicciones más lentamente que otros modelos.
Complejidad
Mientras que los bosques aleatorios y los árboles de decisión tienen mucho en común, los bosques aleatorios son más difíciles de interpretar y visualizar. Esta complejidad surge porque los bosques aleatorios usan cientos o miles de árboles de decisión. La naturaleza de la "caja negra" de los bosques aleatorios es un inconveniente grave cuando la explicabilidad del modelo es un requisito.
Costo computacional
La capacitación de cientos o miles de árboles de decisión requiere mucho más poder y memoria de procesamiento que capacitar a un solo árbol de decisión. Cuando se involucran grandes conjuntos de datos, el costo computacional puede ser aún mayor. Este gran requisito de recursos puede dar lugar a un costo monetario más alto y tiempos de entrenamiento más largos. Como resultado, los bosques aleatorios pueden no ser prácticos en escenarios como la computación de borde, donde la potencia de cálculo y la memoria son escasas. Sin embargo, los bosques aleatorios pueden ser paralelos, lo que puede ayudar a reducir el costo de cálculo.
Tiempo de predicción más lento
El proceso de predicción de un bosque aleatorio implica atravesar cada árbol en el bosque y agregar sus resultados, que es inherentemente más lento que usar un solo modelo. Este proceso puede dar lugar a tiempos de predicción más lentos que los modelos más simples como la regresión logística o las redes neuronales, especialmente para bosques grandes que contienen árboles profundos. Para los casos de uso en los que el tiempo es de la esencia, como el comercio de alta frecuencia o los vehículos autónomos, este retraso puede ser prohibitivo.