
¿Qué es el desajuste en el aprendizaje automático?
Publicado: 2024-10-16El ajuste insuficiente es un problema común que se encuentra durante el desarrollo de modelos de aprendizaje automático (ML). Ocurre cuando un modelo no puede aprender eficazmente de los datos de entrenamiento, lo que resulta en un rendimiento deficiente. En este artículo, exploraremos qué es el desajuste, cómo ocurre y las estrategias para evitarlo.
Tabla de contenido
- ¿Qué es el desajuste?
- Cómo se produce el desajuste
- Desajuste versus sobreajuste
- Causas comunes de desajuste
- Cómo detectar el desajuste
- Técnicas para prevenir el desajuste
- Ejemplos prácticos de desajuste
¿Qué es el desajuste?
El desajuste se produce cuando un modelo de aprendizaje automático no logra capturar los patrones subyacentes en los datos de entrenamiento, lo que genera un rendimiento deficiente tanto en los datos de entrenamiento como en los de prueba. Cuando esto ocurre, significa que el modelo es demasiado simple y no representa bien las relaciones más importantes de los datos. Como resultado, el modelo tiene dificultades para hacer predicciones precisas sobre todos los datos, tanto los datos vistos durante el entrenamiento como los datos nuevos no vistos.
¿Cómo se produce el desajuste?
El desajuste ocurre cuando un algoritmo de aprendizaje automático produce un modelo que no logra capturar las propiedades más importantes de los datos de entrenamiento; Los modelos que fallan de esta manera se consideran demasiado simples. Por ejemplo, imagine que está utilizando la regresión lineal para predecir las ventas en función del gasto en marketing, la demografía de los clientes y la estacionalidad. La regresión lineal supone que la relación entre estos factores y las ventas se puede representar como una combinación de líneas rectas.
Aunque la relación real entre el gasto en marketing y las ventas puede ser curva o incluir múltiples interacciones (por ejemplo, las ventas aumentan rápidamente al principio y luego se estabilizan), el modelo lineal se simplificará demasiado al trazar una línea recta. Esta simplificación omite matices importantes, lo que conduce a predicciones y rendimiento general deficientes.
Este problema es común en muchos modelos de ML donde un alto sesgo (supuestos rígidos) impide que el modelo aprenda patrones esenciales, lo que hace que tenga un rendimiento deficiente tanto en los datos de entrenamiento como en los de prueba. El desajuste se suele observar cuando el modelo es demasiado simple para representar la verdadera complejidad de los datos.
Desajuste versus sobreajuste
En ML, el ajuste insuficiente y excesivo son problemas comunes que pueden afectar negativamente la capacidad de un modelo para realizar predicciones precisas. Comprender la diferencia entre los dos es crucial para construir modelos que se generalicen bien a datos nuevos.
- El desajusteocurre cuando un modelo es demasiado simple y no logra capturar los patrones clave en los datos. Esto conduce a predicciones inexactas tanto para los datos de entrenamiento como para los datos nuevos.
- El sobreajusteocurre cuando un modelo se vuelve demasiado complejo, ajustando no solo los patrones verdaderos sino también el ruido en los datos de entrenamiento. Esto hace que el modelo funcione bien en el conjunto de entrenamiento pero mal con datos nuevos e invisibles.
Para ilustrar mejor estos conceptos, considere un modelo que predice el rendimiento deportivo en función de los niveles de estrés. Los puntos azules en el gráfico representan los puntos de datos del conjunto de entrenamiento, mientras que las líneas muestran las predicciones del modelo después de haber sido entrenado con esos datos. 
1 Ajuste insuficiente:en este caso, el modelo utiliza una línea recta simple para predecir el rendimiento, aunque la relación real es curva. Dado que la línea no se ajusta bien a los datos, el modelo es demasiado simple y no logra capturar patrones importantes, lo que genera predicciones deficientes. Esto es un desajuste, donde el modelo no logra aprender las propiedades más útiles de los datos.
2 Ajuste óptimo:aquí, el modelo se ajusta a la curva de los datos de forma suficientemente adecuada. Capta la tendencia subyacente sin ser demasiado sensible a puntos de datos o ruido específicos. Este es el escenario deseado, donde el modelo se generaliza razonablemente bien y puede hacer predicciones precisas sobre datos nuevos y similares. Sin embargo, la generalización puede seguir siendo un desafío cuando se trata de conjuntos de datos muy diferentes o más complejos.
3 Sobreajuste:en el escenario de sobreajuste, el modelo sigue de cerca casi todos los puntos de datos, incluido el ruido y las fluctuaciones aleatorias en los datos de entrenamiento. Si bien el modelo funciona extremadamente bien en el conjunto de entrenamiento, es demasiado específico para los datos de entrenamiento y, por lo tanto, será menos efectivo al predecir datos nuevos. Le cuesta generalizar y probablemente hará predicciones inexactas cuando se aplique a escenarios invisibles.
Causas comunes de desajuste
Hay muchas causas potenciales de desajuste. Los cuatro más comunes son:
- La arquitectura del modelo es demasiado simple.
- Mala selección de funciones
- Datos de entrenamiento insuficientes
- No hay suficiente entrenamiento
Profundicemos un poco más en ellos para comprenderlos.
La arquitectura del modelo es demasiado simple.
La arquitectura del modelo se refiere a la combinación del algoritmo utilizado para entrenar el modelo y la estructura del modelo. Si la arquitectura es demasiado simple, podría tener problemas para capturar las propiedades de alto nivel de los datos de entrenamiento, lo que generaría predicciones inexactas.
Por ejemplo, si un modelo intenta utilizar una única línea recta para modelar datos que siguen un patrón curvo, constantemente se ajustará por debajo de lo esperado. Esto se debe a que una línea recta no puede representar con precisión la relación de alto nivel en datos curvos, lo que hace que la arquitectura del modelo sea inadecuada para la tarea.
Mala selección de funciones
La selección de funciones implica elegir las variables adecuadas para el modelo ML durante el entrenamiento. Por ejemplo, podría pedirle a un algoritmo de aprendizaje automático que observe el año de nacimiento, el color de ojos, la edad o los tres de una persona al predecir si una persona presionará el botón de compra en un sitio web de comercio electrónico.
Si hay demasiadas funciones o las funciones seleccionadas no se correlacionan fuertemente con la variable objetivo, el modelo no tendrá suficiente información relevante para hacer predicciones precisas. El color de ojos puede ser irrelevante para la conversión y la edad captura gran parte de la misma información que el año de nacimiento.
Datos de entrenamiento insuficientes
Cuando hay muy pocos puntos de datos, el modelo puede no ajustarse porque los datos no capturan las propiedades más importantes del problema. Esto puede suceder debido a una falta de datos o a un sesgo de muestreo, donde ciertas fuentes de datos están excluidas o subrepresentadas, lo que impide que el modelo aprenda patrones importantes.

No hay suficiente entrenamiento
Entrenar un modelo de ML implica ajustar sus parámetros internos (ponderaciones) en función de la diferencia entre sus predicciones y los resultados reales. Cuantas más iteraciones de entrenamiento sufra el modelo, mejor podrá ajustarse para ajustarse a los datos. Si el modelo se entrena con muy pocas iteraciones, es posible que no tenga suficientes oportunidades para aprender de los datos, lo que genera un desajuste.
Cómo detectar el desajuste
Una forma de detectar el desajuste es analizando las curvas de aprendizaje, que trazan el rendimiento del modelo (normalmente pérdida o error) frente al número de iteraciones de entrenamiento. Una curva de aprendizaje muestra cómo el modelo mejora (o no mejora) con el tiempo en los conjuntos de datos de entrenamiento y validación.
La pérdida es la magnitud del error del modelo para un conjunto de datos determinado. La pérdida de entrenamiento mide esto para los datos de entrenamiento y la pérdida de validación para los datos de validación. Los datos de validación son un conjunto de datos separado que se utiliza para probar el rendimiento del modelo. Por lo general, se produce dividiendo aleatoriamente un conjunto de datos más grande en datos de entrenamiento y validación.
En el caso de un ajuste insuficiente, notará los siguientes patrones clave:
- Alta pérdida de entrenamiento:si la pérdida de entrenamiento del modelo sigue siendo alta y se estabiliza al principio del proceso, sugiere que el modelo no está aprendiendo de los datos de entrenamiento. Esta es una clara señal de desajuste, ya que el modelo es demasiado simple para adaptarse a la complejidad de los datos.
- Pérdida de capacitación y validación similar:si tanto la pérdida de capacitación como la de validación son altas y permanecen cercanas entre sí durante todo el proceso de capacitación, significa que el modelo tiene un rendimiento inferior en ambos conjuntos de datos. Esto indica que el modelo no captura suficiente información de los datos para hacer predicciones precisas, lo que apunta a un ajuste insuficiente.
A continuación se muestra un gráfico de ejemplo que muestra las curvas de aprendizaje en un escenario de desajuste:
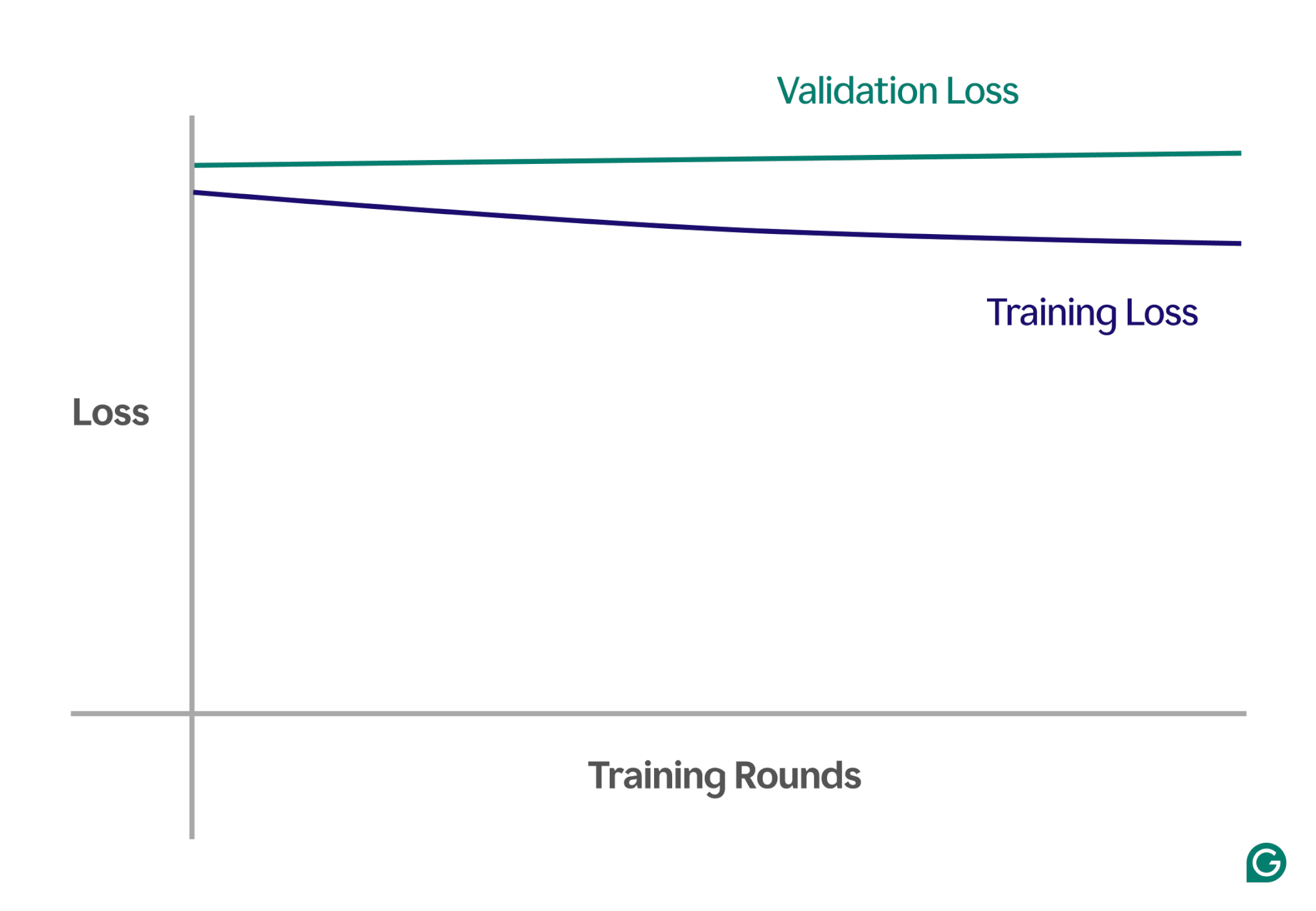
En esta representación visual, el desajuste es fácil de detectar:
- En un modelo bien ajustado, la pérdida de entrenamiento disminuye significativamente mientras que la pérdida de validación sigue un patrón similar y finalmente se estabiliza.
- En un modelo insuficientemente adaptado, tanto la pérdida de entrenamiento como la de validación comienzan siendo altas y se mantienen altas, sin ninguna mejora significativa.
Al observar estas tendencias, puede identificar rápidamente si el modelo es demasiado simplista y necesita ajustes para aumentar su complejidad.
Técnicas para prevenir el desajuste
Si encuentra un ajuste insuficiente, existen varias estrategias que puede utilizar para mejorar el rendimiento del modelo:
- Más datos de entrenamiento:si es posible, obtenga datos de entrenamiento adicionales. Más datos le dan al modelo oportunidades adicionales para aprender patrones, siempre que los datos sean de alta calidad y relevantes para el problema en cuestión.
- Ampliar la selección de funciones:agregue al modelo las funciones que sean más relevantes. Elija características que tengan una fuerte relación con la variable objetivo, lo que le dará al modelo una mejor oportunidad de capturar patrones importantes que anteriormente se pasaron por alto.
- Aumente el poder arquitectónico:en modelos basados en redes neuronales, puede ajustar la estructura arquitectónica cambiando la cantidad de pesos, capas u otros hiperparámetros. Esto puede permitir que el modelo sea más flexible y encuentre más fácilmente patrones de alto nivel en los datos.
- Elija un modelo diferente:a veces, incluso después de ajustar los hiperparámetros, es posible que un modelo específico no se adapte bien a la tarea. Probar varios algoritmos de modelos puede ayudar a encontrar un modelo más apropiado y mejorar el rendimiento.
Ejemplos prácticos de desajuste
Para ilustrar los efectos del desajuste, veamos ejemplos del mundo real en varios dominios donde los modelos no logran capturar la complejidad de los datos, lo que lleva a predicciones inexactas.
Predecir los precios de la vivienda
Para predecir con precisión el precio de una casa, es necesario considerar muchos factores, incluida la ubicación, el tamaño, el tipo de casa, el estado y la cantidad de dormitorios.
Si utiliza muy pocas funciones (como sólo el tamaño y el tipo de casa), el modelo no tendrá acceso a información crítica. Por ejemplo, el modelo podría suponer que un estudio pequeño es económico, sin saber que está ubicado en Mayfair, Londres, una zona con precios inmobiliarios elevados. Esto conduce a malas predicciones.
Para resolver esto, los científicos de datos deben garantizar la selección adecuada de funciones. Esto implica incluir todas las funciones relevantes, excluir las irrelevantes y utilizar datos de entrenamiento precisos.
reconocimiento de voz
La tecnología de reconocimiento de voz se ha vuelto cada vez más común en la vida diaria. Por ejemplo, los asistentes de teléfonos inteligentes, las líneas de ayuda de servicio al cliente y la tecnología de asistencia para discapacidades utilizan el reconocimiento de voz. Al entrenar estos modelos, se utilizan datos de muestras de voz y sus interpretaciones correctas.
Para reconocer el habla, el modelo convierte las ondas sonoras capturadas por un micrófono en datos. Si simplificamos esto proporcionando únicamente la frecuencia dominante y el volumen de la voz en intervalos específicos, reducimos la cantidad de datos que el modelo debe procesar.
Sin embargo, este enfoque elimina la información esencial necesaria para comprender completamente el discurso. Los datos se vuelven demasiado simplistas para captar la complejidad del habla humana, como las variaciones de tono, tono y acento.
Como resultado, el modelo no se adaptará bien y tendrá dificultades para reconocer incluso comandos de palabras básicos, y mucho menos oraciones completas. Incluso si el modelo es suficientemente complejo, la falta de datos completos conduce a un desajuste.
Clasificación de imágenes
Un clasificador de imágenes está diseñado para tomar una imagen como entrada y generar una palabra para describirla. Digamos que estás construyendo un modelo para detectar si una imagen contiene una pelota o no. Entrenas el modelo usando imágenes etiquetadas de pelotas y otros objetos.
Si utiliza por error una red neuronal simple de dos capas en lugar de un modelo más adecuado como una red neuronal convolucional (CNN), el modelo tendrá dificultades. La red de dos capas aplana la imagen en una sola capa, perdiendo información espacial importante. Además, con sólo dos capas, el modelo carece de la capacidad de identificar características complejas.
Esto conduce a un desajuste, ya que el modelo no podrá hacer predicciones precisas, ni siquiera sobre los datos de entrenamiento. Las CNN resuelven este problema preservando la estructura espacial de las imágenes y utilizando capas convolucionales con filtros que aprenden automáticamente a detectar características importantes como bordes y formas en las primeras capas y objetos más complejos en las capas posteriores.