
Bases du réseau contradictoire génératif : ce que vous devez savoir
Publié: 2024-10-08Les réseaux contradictoires génératifs (GAN) sont un puissant outil d'intelligence artificielle (IA) avec de nombreuses applications en apprentissage automatique (ML). Ce guide explore les GAN, leur fonctionnement, leurs applications, ainsi que leurs avantages et inconvénients.
Table des matières
- Qu’est-ce qu’un GAN ?
- GAN contre CNN
- Comment fonctionnent les GAN
- Types de GAN
- Applications des GAN
- Avantages des GAN
- Inconvénients des GAN
Qu’est-ce qu’un réseau contradictoire génératif ?
Un réseau contradictoire génératif, ou GAN, est un type de modèle d'apprentissage profond généralement utilisé dans l'apprentissage automatique non supervisé, mais également adaptable pour l'apprentissage semi-supervisé et supervisé. Les GAN sont utilisés pour générer des données de haute qualité similaires à l'ensemble de données de formation. En tant que sous-ensemble de l'IA générative, les GAN sont composés de deux sous-modèles : le générateur et le discriminateur.
1 Générateur :Le générateur crée des données synthétiques.
2 Discriminateur :le discriminateur évalue la sortie du générateur, en distinguant les données réelles de l'ensemble d'apprentissage et les données synthétiques créées par le générateur.
Les deux modèles s'engagent dans une compétition : le générateur tente de tromper le discriminateur en lui faisant classer les données générées comme réelles, tandis que le discriminateur améliore continuellement sa capacité à détecter les données synthétiques. Ce processus contradictoire se poursuit jusqu'à ce que le discriminateur ne puisse plus faire la distinction entre les données réelles et générées. À ce stade, le GAN est capable de générer des images, des vidéos et d’autres types de données réalistes.
GAN contre CNN
Les GAN et les réseaux de neurones convolutifs (CNN) sont des types puissants de réseaux de neurones utilisés dans l'apprentissage profond, mais ils diffèrent considérablement en termes de cas d'utilisation et d'architecture.
Cas d'utilisation
- GAN :se spécialisent dans la génération de données synthétiques réalistes basées sur des données de formation. Cela rend les GAN bien adaptés aux tâches telles que la génération d’images, le transfert de styles d’images et l’augmentation des données. Les GAN ne sont pas supervisés, ce qui signifie qu'ils peuvent être appliqués à des scénarios dans lesquels les données étiquetées sont rares ou indisponibles.
- CNN :principalement utilisés pour les tâches de classification de données structurées, telles que l'analyse des sentiments, la catégorisation de sujets et la traduction linguistique. En raison de leurs capacités de classification, les CNN servent également de bons discriminateurs dans les GAN. Cependant, comme les CNN nécessitent des données de formation structurées et annotées par l'homme, ils sont limités aux scénarios d'apprentissage supervisé.
Architecture
- GAN :se composent de deux modèles : un discriminateur et un générateur – qui s'engagent dans un processus concurrentiel. Le générateur crée des images, tandis que le discriminateur les évalue, poussant le générateur à produire des images de plus en plus réalistes au fil du temps.
- CNN :utilisez des couches d'opérations convolutionnelles et de pooling pour extraire et analyser les caractéristiques des images. Cette architecture à modèle unique se concentre sur la reconnaissance des modèles et des structures au sein des données.
Dans l’ensemble, alors que les CNN se concentrent sur l’analyse des données structurées existantes, les GAN visent à créer de nouvelles données réalistes.
Comment fonctionnent les GAN
À un niveau élevé, un GAN fonctionne en opposant deux réseaux neuronaux : le générateur et le discriminateur. Les GAN ne nécessitent pas de type particulier d'architecture de réseau neuronal pour aucun de leurs deux composants, à condition que les architectures sélectionnées se complètent. Par exemple, si un CNN est utilisé comme discriminateur pour la génération d'images, le générateur peut alors être un réseau neuronal déconvolutionnel (deCNN), qui exécute le processus CNN à l'envers. Chaque composant a un objectif différent :
- Générateur :produire des données d'une qualité telle que le discriminateur est amené à les classer comme réelles.
- Discriminateur :pour classer avec précision un échantillon de données donné comme réel (à partir de l'ensemble de données d'entraînement) ou faux (généré par le générateur).
Cette compétition est la mise en œuvre d’un jeu à somme nulle, dans lequel une récompense accordée à un modèle est également une pénalité pour l’autre modèle. Pour le générateur, réussir à tromper le discriminateur entraîne une mise à jour du modèle qui améliore sa capacité à générer des données réalistes. A l’inverse, lorsque le discriminateur identifie correctement les fausses données, il reçoit une mise à jour qui améliore ses capacités de détection. Mathématiquement, le discriminateur vise à minimiser l'erreur de classification, tandis que le générateur cherche à la maximiser.
Le processus de formation GAN
La formation des GAN implique une alternance entre le générateur et le discriminateur sur plusieurs époques. Les époques sont des cycles de formation complets sur l'ensemble de données. Ce processus se poursuit jusqu'à ce que le générateur produise des données synthétiques qui trompent le discriminateur environ 50 % du temps. Bien que les deux modèles utilisent des algorithmes similaires pour l’évaluation et l’amélioration des performances, leurs mises à jour s’effectuent indépendamment. Ces mises à jour sont effectuées à l'aide d'une méthode appelée rétropropagation, qui mesure l'erreur de chaque modèle et ajuste les paramètres pour améliorer les performances. Un algorithme d'optimisation ajuste ensuite les paramètres de chaque modèle indépendamment.
Voici une représentation visuelle de l'architecture GAN, illustrant la compétition entre le générateur et le discriminateur :
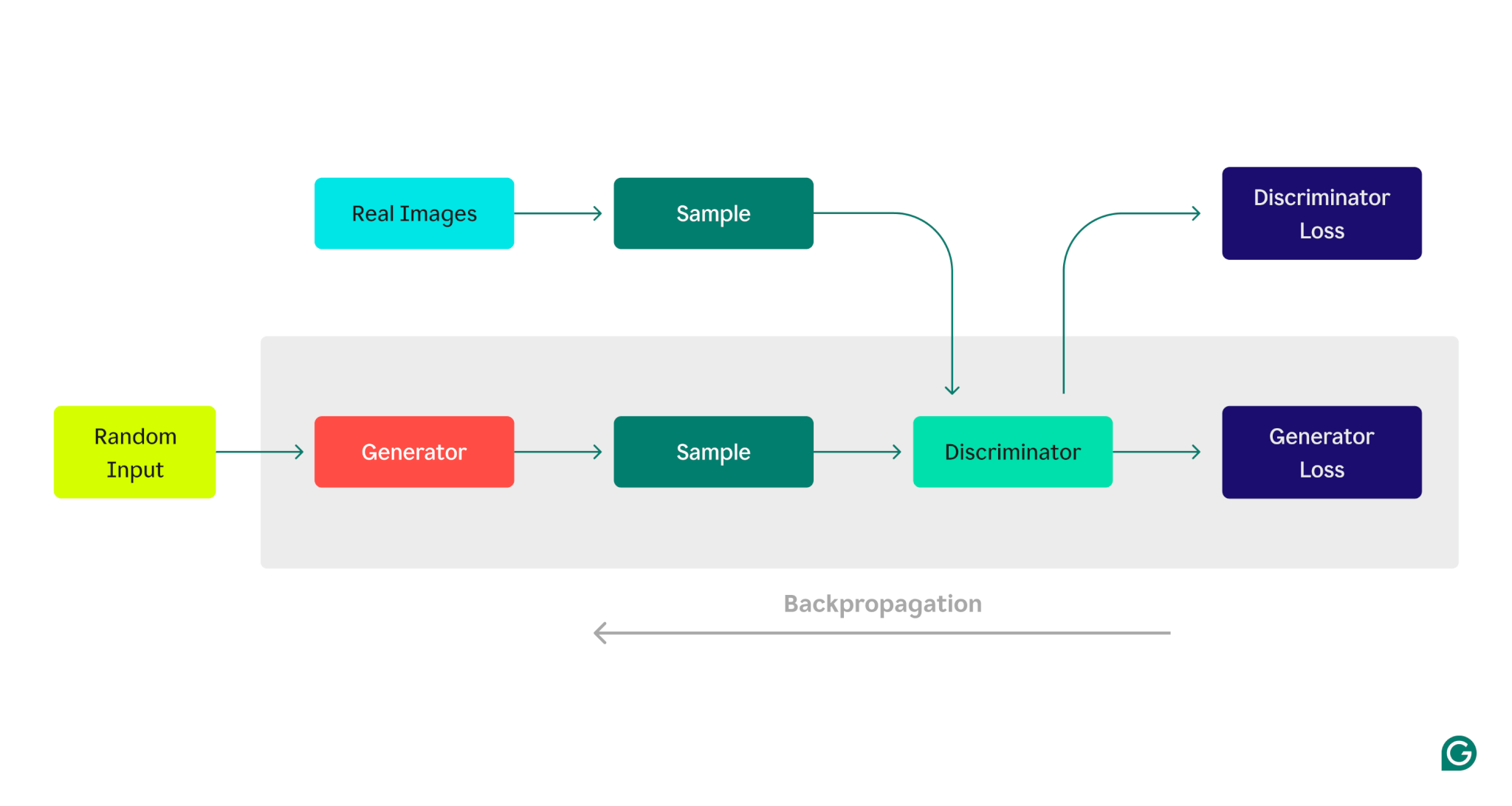
Phase de formation du générateur :
1 Le générateur crée des échantillons de données, en commençant généralement par un bruit aléatoire en entrée.
2 Le discriminateur classe ces échantillons comme réels (à partir de l'ensemble de données d'entraînement) ou faux (générés par le générateur).
3 Sur la base de la réponse du discriminateur, les paramètres du générateur sont mis à jour par rétropropagation.
Phase de formation des discriminateurs :
1 De fausses données sont générées en utilisant l'état actuel du générateur.
2 Les échantillons générés sont fournis au discriminateur, avec des échantillons de l'ensemble de données de formation.
3 Grâce à la rétropropagation, les paramètres du discriminateur sont mis à jour en fonction de ses performances de classification.
Ce processus de formation itératif se poursuit, les paramètres de chaque modèle étant ajustés en fonction de ses performances, jusqu'à ce que le générateur produise systématiquement des données que le discriminateur ne peut pas distinguer de manière fiable des données réelles.
Types de GAN
S'appuyant sur l'architecture de base du GAN, souvent appelée GAN vanille, d'autres types spécialisés de GAN ont été développés et optimisés pour diverses tâches. Certaines des variantes les plus courantes sont décrites ci-dessous, bien qu'il ne s'agisse pas d'une liste exhaustive :
GAN conditionnel (cGAN)
Les GAN conditionnels, ou cGAN, utilisent des informations supplémentaires, appelées conditions, pour guider le modèle dans la génération de types de données spécifiques lors de l'entraînement sur un ensemble de données plus général. Une condition peut être une étiquette de classe, une description textuelle ou un autre type d’informations de classification pour les données. Par exemple, imaginez que vous deviez générer uniquement des images de chats siamois, mais que votre ensemble de données d'entraînement contient des images de toutes sortes de chats. Dans un cGAN, vous pouvez étiqueter les images d'entraînement avec le type de chat, et le modèle pourrait l'utiliser pour apprendre à générer uniquement des images de chats siamois.

GAN convolutif profond (DCGAN)
Un GAN convolutif profond, ou DCGAN, est optimisé pour la génération d'images. Dans un DCGAN, le générateur est un réseau neuronal convolutif à intégration profonde (deCNN) et le discriminateur est un CNN profond. Les CNN sont mieux adaptés pour travailler et générer des images en raison de leur capacité à capturer des hiérarchies et des modèles spatiaux. Le générateur d'un DCGAN utilise des couches de suréchantillonnage et de convolution transposées pour créer des images de meilleure qualité qu'un perceptron multicouche (un simple réseau neuronal qui prend des décisions en pesant les caractéristiques d'entrée) pourrait générer. De même, le discriminateur utilise des couches convolutives pour extraire les caractéristiques des échantillons d'images et les classer avec précision comme réelles ou fausses.
CycleGAN
CycleGAN est un type de GAN conçu pour générer un type d'image à partir d'un autre. Par exemple, un CycleGAN peut transformer l’image d’une souris en rat ou d’un chien en coyote. Les CycleGAN sont capables d'effectuer cette traduction d'image à image sans formation sur des ensembles de données appariés, c'est-à-dire des ensembles de données contenant à la fois l'image de base et la transformation souhaitée. Cette capacité est obtenue en utilisant deux générateurs et deux discriminateurs au lieu de la seule paire utilisée par un GAN vanille. Dans CycleGAN, un générateur convertit les images de l'image de base en version transformée, tandis que l'autre générateur effectue une conversion dans le sens opposé. De même, chaque discriminateur vérifie un type d’image particulier pour déterminer si elle est réelle ou fausse. CycleGAN utilise ensuite un contrôle de cohérence pour s'assurer que la conversion d'une image dans l'autre style et inversement aboutit à l'image d'origine.
Applications des GAN
En raison de leur architecture distinctive, les GAN ont été appliqués à une gamme de cas d'utilisation innovants, bien que leurs performances dépendent fortement de tâches spécifiques et de la qualité des données. Certaines des applications les plus puissantes incluent la génération de texte en image, l'augmentation des données, ainsi que la génération et la manipulation de vidéos.
Génération de texte en image
Les GAN peuvent générer des images à partir d'une description textuelle. Cette application est précieuse dans les industries créatives, car elle permet aux auteurs et aux concepteurs de visualiser les scènes et les personnages décrits dans le texte. Alors que les GAN sont souvent utilisés pour de telles tâches, d'autres modèles d'IA générative, comme le DALL-E d'OpenAI, utilisent des architectures basées sur des transformateurs pour obtenir des résultats similaires.
Augmentation des données
Les GAN sont utiles pour l'augmentation des données car ils peuvent générer des données synthétiques qui ressemblent à des données de formation réelles, bien que le degré de précision et de réalisme puisse varier en fonction du cas d'utilisation spécifique et de la formation du modèle. Cette capacité est particulièrement précieuse dans l’apprentissage automatique pour étendre des ensembles de données limités et améliorer les performances des modèles. De plus, les GAN offrent une solution pour maintenir la confidentialité des données. Dans des domaines sensibles comme la santé et la finance, les GAN peuvent produire des données synthétiques qui préservent les propriétés statistiques de l'ensemble de données d'origine sans compromettre les informations sensibles.
Génération et manipulation de vidéos
Les GAN se sont montrés prometteurs dans certaines tâches de génération et de manipulation de vidéos. Par exemple, les GAN peuvent être utilisés pour générer de futures images à partir d’une séquence vidéo initiale, facilitant ainsi des applications telles que la prévision des mouvements des piétons ou la prévision des dangers routiers pour les véhicules autonomes. Cependant, ces applications font encore l’objet de recherches et de développements actifs. Les GAN peuvent également être utilisés pour générer du contenu vidéo entièrement synthétique et améliorer les vidéos avec des effets spéciaux réalistes.
Avantages des GAN
Les GAN offrent plusieurs avantages distincts, notamment la possibilité de générer des données synthétiques réalistes, d'apprendre à partir de données non appariées et d'effectuer une formation non supervisée.
Génération de données synthétiques de haute qualité
L'architecture des GAN leur permet de produire des données synthétiques qui peuvent se rapprocher des données du monde réel dans des applications telles que l'augmentation des données et la création vidéo, bien que la qualité et la précision de ces données puissent dépendre fortement des conditions d'entraînement et des paramètres du modèle. Par exemple, les DCGAN, qui utilisent les CNN pour un traitement d'image optimal, excellent dans la génération d'images réalistes.
Capable d’apprendre à partir de données non appariées
Contrairement à certains modèles de ML, les GAN peuvent apprendre à partir d'ensembles de données sans exemples appariés d'entrées et de sorties. Cette flexibilité permet aux GAN d'être utilisés dans un large éventail de tâches où les données couplées sont rares ou indisponibles. Par exemple, dans les tâches de traduction d'image en image, les modèles traditionnels nécessitent souvent un ensemble de données d'images et leurs transformations pour la formation. En revanche, les GAN peuvent exploiter une plus grande variété d’ensembles de données potentiels pour la formation.
Apprentissage non supervisé
Les GAN sont une méthode d'apprentissage automatique non supervisée, ce qui signifie qu'ils peuvent être formés sur des données non étiquetées sans instruction explicite. Ceci est particulièrement avantageux car l’étiquetage des données est un processus long et coûteux. La capacité des GAN à apprendre à partir de données non étiquetées les rend utiles pour les applications où les données étiquetées sont limitées ou difficiles à obtenir. Les GAN peuvent également être adaptés pour un apprentissage semi-supervisé et supervisé, leur permettant également d'utiliser des données étiquetées.
Inconvénients des GAN
Bien que les GAN soient un outil puissant d’apprentissage automatique, leur architecture crée un ensemble unique d’inconvénients. Ces inconvénients incluent la sensibilité aux hyperparamètres, les coûts de calcul élevés, l'échec de la convergence et un phénomène appelé effondrement de mode.
Sensibilité des hyperparamètres
Les GAN sont sensibles aux hyperparamètres, qui sont des paramètres définis avant la formation et non appris à partir des données. Les exemples incluent les architectures de réseau et le nombre d’exemples de formation utilisés en une seule itération. De petits changements dans ces paramètres peuvent affecter de manière significative le processus de formation et les résultats du modèle, nécessitant des ajustements approfondis pour des applications pratiques.
Coût de calcul élevé
En raison de leur architecture complexe, de leur processus de formation itératif et de leur sensibilité aux hyperparamètres, les GAN entraînent souvent des coûts de calcul élevés. La formation réussie d’un GAN nécessite du matériel spécialisé et coûteux, ainsi que beaucoup de temps, ce qui peut constituer un obstacle pour de nombreuses organisations cherchant à utiliser les GAN.
Échec de la convergence
Les ingénieurs et les chercheurs peuvent passer beaucoup de temps à expérimenter les configurations de formation avant qu'elles n'atteignent un taux acceptable auquel la sortie du modèle devient stable et précise, connue sous le nom de taux de convergence. La convergence des GAN peut être très difficile à réaliser et pourrait ne pas durer très longtemps. L'échec de la convergence se produit lorsque le discriminateur ne parvient pas à choisir suffisamment entre les données réelles et fausses, ce qui entraîne une précision d'environ 50 % car il n'a pas acquis la capacité d'identifier les données réelles, contrairement à l'équilibre prévu atteint lors d'un entraînement réussi. Certains GAN peuvent ne jamais atteindre la convergence et peuvent nécessiter une analyse spécialisée pour être réparés.
Réduire le mode
Les GAN sont sujets à un problème appelé effondrement de mode, dans lequel le générateur crée une gamme limitée de sorties et ne parvient pas à refléter la diversité des distributions de données du monde réel. Ce problème vient de l'architecture GAN, car le générateur se concentre trop sur la production de données susceptibles de tromper le discriminateur, l'amenant à générer des exemples similaires.