
Réseaux de neurones : tout ce que vous devez savoir
Publié: 2024-06-26Dans cet article, nous plongerons dans le monde des réseaux de neurones, en explorant leur fonctionnement interne, leurs types, leurs applications et les défis auxquels ils sont confrontés.
Table des matières
- Qu'est-ce qu'un réseau de neurones ?
- Comment sont structurés les réseaux de neurones
- Comment fonctionnent les réseaux de neurones
- Comment les réseaux de neurones génèrent des réponses
- Types de réseaux de neurones
- Applications
- Défis
- L'avenir des réseaux de neurones
- Conclusion
Qu'est-ce qu'un réseau de neurones ?
Un réseau de neurones est un type de modèle d’apprentissage profond dans le domaine plus large de l’apprentissage automatique (ML) qui simule le cerveau humain. Il traite les données via des nœuds ou neurones interconnectés disposés en couches : entrée, cachée et sortie. Chaque nœud effectue des calculs simples, contribuant à la capacité du modèle à reconnaître des modèles et à faire des prédictions.
Les réseaux neuronaux d’apprentissage profond sont particulièrement efficaces pour gérer des tâches complexes telles que la reconnaissance d’images et de parole, constituant un élément crucial de nombreuses applications d’IA. Les progrès récents dans les architectures de réseaux neuronaux et les techniques de formation ont considérablement amélioré les capacités des systèmes d’IA.
Comment sont structurés les réseaux de neurones
Comme son nom l’indique, un modèle de réseau neuronal s’inspire des neurones, les éléments constitutifs du cerveau. Les humains adultes possèdent environ 85 milliards de neurones, chacun étant connecté à environ 1 000 autres. Une cellule cérébrale communique avec une autre en envoyant des produits chimiques appelés neurotransmetteurs. Si la cellule réceptrice reçoit suffisamment de ces produits chimiques, elle s’excite et envoie ses propres produits chimiques à une autre cellule.
L'unité fondamentale de ce qu'on appelle parfois un réseau neuronal artificiel (ANN) est unnœudqui, au lieu d'être une cellule, est une fonction mathématique. Tout comme les neurones, ils communiquent avec d’autres nœuds s’ils reçoivent suffisamment d’informations.
C’est à peu près là que s’arrêtent les similitudes. Les réseaux de neurones sont structurés beaucoup plus simplement que le cerveau, avec des couches bien définies : entrée, cachée et sortie. Une collection de ces couches est appelée unmodèle.Ils apprennent ous’entraînenten essayant à plusieurs reprises de générer artificiellement des résultats ressemblant le plus aux résultats souhaités. (Plus d'informations à ce sujet dans une minute.)
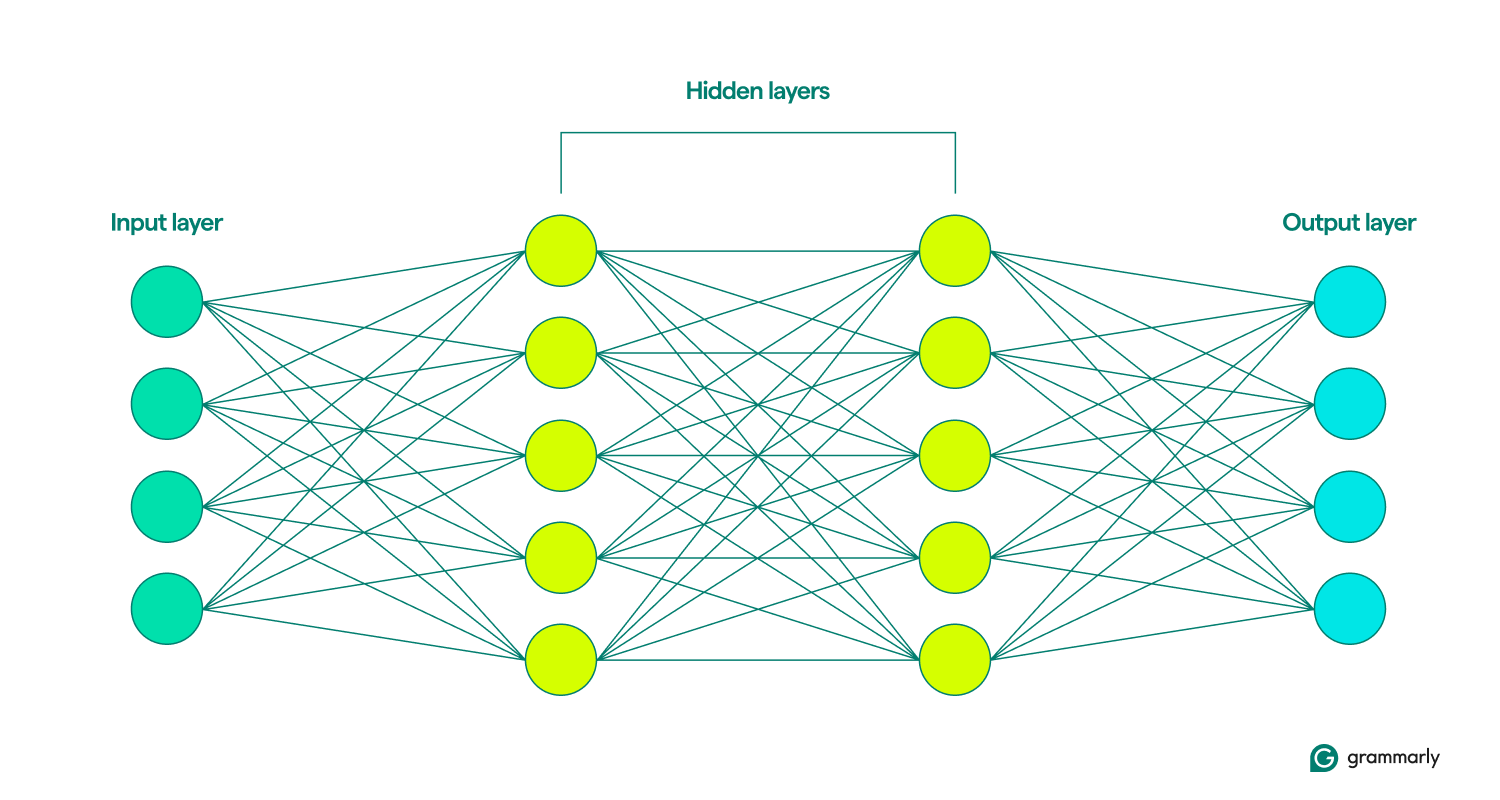
Les couches d’entrée et de sortie sont assez explicites. La plupart des activités des réseaux de neurones se déroulent dans les couches cachées. Lorsqu'un nœud est activé par l'entrée d'une couche précédente, il effectue ses calculs et décide s'il doit transmettre la sortie aux nœuds de la couche suivante. Ces couches sont ainsi nommées car leurs opérations sont invisibles pour l'utilisateur final, bien qu'il existe des techniques permettant aux ingénieurs de voir ce qui se passe dans les couches dites cachées.
Lorsque les réseaux de neurones incluent plusieurs couches cachées, on les appelle réseaux d’apprentissage profond. Les réseaux de neurones profonds modernes comportent généralement de nombreuses couches, y compris des sous-couches spécialisées qui remplissent des fonctions distinctes. Par exemple, certaines sous-couches améliorent la capacité du réseau à prendre en compte les informations contextuelles au-delà de l'entrée immédiate analysée.
Comment fonctionnent les réseaux de neurones
Pensez à la façon dont les bébés apprennent. Ils essaient quelque chose, échouent et réessayent d’une manière différente. La boucle continue encore et encore jusqu'à ce qu'ils aient perfectionné le comportement. C’est aussi plus ou moins ainsi que les réseaux de neurones apprennent.
Au tout début de leur formation, les réseaux de neurones font des suppositions aléatoires. Un nœud de la couche d'entrée décide de manière aléatoire lequel des nœuds de la première couche cachée doit être activé, puis ces nœuds activent de manière aléatoire les nœuds de la couche suivante, et ainsi de suite, jusqu'à ce que ce processus aléatoire atteigne la couche de sortie. (Les grands modèles de langage tels que GPT-4 comportent environ 100 couches, avec des dizaines ou des centaines de milliers de nœuds dans chaque couche.)
Compte tenu de tout le caractère aléatoire, le modèle compare ses résultats – ce qui est probablement terrible – et détermine à quel point il était erroné. Il ajuste ensuite la connexion de chaque nœud aux autres nœuds, modifiant ainsi leur tendance à s'activer en fonction d'une entrée donnée. Il le fait à plusieurs reprises jusqu'à ce que ses résultats soient aussi proches des réponses souhaitées.
Alors, comment les réseaux de neurones savent-ils ce qu’ils sont censés faire ? L’apprentissage automatique peut être divisé en différentes approches, notamment l’apprentissage supervisé et non supervisé. Dans l'apprentissage supervisé, le modèle est formé sur des données qui incluent des étiquettes ou des réponses explicites, comme des images associées à un texte descriptif. L’apprentissage non supervisé implique toutefois de fournir au modèle des données non étiquetées, lui permettant d’identifier des modèles et des relations de manière indépendante.
Un complément courant à cette formation est l’apprentissage par renforcement, où le modèle s’améliore en réponse aux commentaires. Souvent, cela est fourni par des évaluateurs humains (si vous avez déjà cliqué sur une suggestion d'un ordinateur en appuyant sur le pouce levé ou le pouce vers le bas, vous avez contribué à l'apprentissage par renforcement). Il existe néanmoins des moyens permettant aux modèles d’apprendre de manière itérative et indépendante.
Il est précis et instructif de considérer le résultat d’un réseau neuronal comme une prédiction. Qu’il s’agisse d’évaluer la solvabilité ou de générer une chanson, les modèles d’IA fonctionnent en devinant ce qui est le plus probable. L'IA générative, telle que ChatGPT, va encore plus loin dans la prédiction. Il fonctionne de manière séquentielle, en devinant ce qui devrait arriver après le résultat qu'il vient de produire. (Nous verrons pourquoi cela peut être problématique plus tard.)
Comment les réseaux de neurones génèrent des réponses
Une fois qu’un réseau est formé, comment traite-t-il les informations qu’il voit pour prédire la bonne réponse ? Lorsque vous tapez une invite telle que « Racontez-moi une histoire sur les fées » dans l'interface ChatGPT, comment ChatGPT décide-t-il comment répondre ?
La première étape consiste pour la couche d'entrée du réseau neuronal à diviser votre invite en petits morceaux d'informations, appelésjetons. Pour un réseau de reconnaissance d'images, les jetons peuvent être des pixels. Pour un réseau qui utilise le traitement du langage naturel (NLP), comme ChatGPT, un jeton est généralement un mot, une partie de mot ou une phrase très courte.
Une fois que le réseau a enregistré les jetons dans l'entrée, ces informations sont transmises via les couches cachées formées précédemment. Les nœuds qu'il transmet d'une couche à la suivante analysent des sections de plus en plus grandes de l'entrée. De cette façon, un réseau PNL peut éventuellement interpréter une phrase ou un paragraphe entier, et pas seulement un mot ou une lettre.
Le réseau peut désormais commencer à élaborer sa réponse, ce qu'il fait sous la forme d'une série de prédictions mot par mot de ce qui va suivre, en fonction de tout ce sur quoi il a été formé.
Considérez le message « Racontez-moi une histoire sur les fées ». Pour générer une réponse, le réseau neuronal analyse l'invite pour prédire le premier mot le plus probable. Par exemple, il peut déterminer qu'il y a 80 % de chances que "Le" soit le meilleur choix, 10 % de chances pour "A" et 10 % de chances pour "Une fois". Il sélectionne ensuite un nombre au hasard : Si le nombre est compris entre 1 et 8, il choisit « Le » ; si c'est 9, il choisit « A » ; et si c'est 10, il choisit « Une fois ». Supposons que le nombre aléatoire soit 4, ce qui correspond à « Le ». Le réseau met ensuite à jour l’invite en « Raconte-moi une histoire sur les fées. Le" et répète le processus pour prédire le mot suivant après "Le". Ce cycle se poursuit, avec chaque nouvelle prédiction de mot basée sur l'invite mise à jour, jusqu'à ce qu'une histoire complète soit générée.
Différents réseaux feront cette prédiction différemment. Par exemple, un modèle de reconnaissance d'image peut tenter de prédire quelle étiquette donner à l'image d'un chien et déterminer qu'il y a une probabilité de 70 % que l'étiquette correcte soit "chocolate Lab", 20 % pour "épagneul anglais" et 10 % pour « golden retriever ». Dans le cas de la classification, en général, le réseau optera pour le choix le plus probable plutôt que pour une supposition probabiliste.
Types de réseaux de neurones
Voici un aperçu des différents types de réseaux de neurones et de leur fonctionnement.
- Réseaux de neurones feedforward (FNN) :dans ces modèles, les informations circulent dans une seule direction : de la couche d'entrée, à travers les couches cachées, et enfin vers la couche de sortie. Ce type de modèle est idéal pour les tâches de prédiction plus simples, telles que la détection de fraude par carte de crédit.
- Réseaux de neurones récurrents (RNN) :contrairement aux FNN, les RNN prennent en compte les entrées précédentes lors de la génération d'une prédiction. Cela les rend bien adaptés aux tâches de traitement du langage puisque la fin d’une phrase générée en réponse à une invite dépend de la façon dont la phrase a commencé.
- Réseaux de mémoire à long terme (LSTM) :les LSTM oublient sélectivement les informations, ce qui leur permet de travailler plus efficacement. Ceci est crucial pour traiter de grandes quantités de texte ; par exemple, la mise à niveau de Google Translate en 2016 vers la traduction automatique neuronale reposait sur les LSTM.
- Réseaux de neurones convolutifs (CNN) :les CNN fonctionnent mieux lors du traitement d'images. Ils utilisentdes couches convolutivespour numériser l’intégralité de l’image et rechercher des caractéristiques telles que des lignes ou des formes. Cela permet aux CNN de prendre en compte l'emplacement spatial, par exemple en déterminant si un objet est situé dans la moitié supérieure ou inférieure de l'image, et également d'identifier une forme ou un type d'objet quel que soit son emplacement.
- Réseaux contradictoires génératifs (GAN) :les GAN sont souvent utilisés pour générer de nouvelles images basées sur une description ou une image existante. Ils sont structurés comme une compétition entre deux réseaux de neurones : un réseaugénérateur, qui tente de tromper un réseaudiscriminateuren lui faisant croire qu'une fausse entrée est réelle.
- Transformateurs et réseaux d’attention :les transformateurs sont responsables de l’explosion actuelle des capacités de l’IA. Ces modèles intègrent un projecteur attentionnel qui leur permet de filtrer leurs entrées pour se concentrer sur les éléments les plus importants et sur la manière dont ces éléments sont liés les uns aux autres, même sur les pages de texte. Les transformateurs peuvent également s'entraîner sur d'énormes quantités de données, c'est pourquoi des modèles comme ChatGPT et Gemini sont appelés grands modèles de langage (LLM).

Applications des réseaux de neurones
Il y en a beaucoup trop pour les énumérer. Voici donc une sélection des façons dont les réseaux de neurones sont utilisés aujourd'hui, en mettant l'accent sur le langage naturel.
Aide à l’écriture :les Transformers ont transformé la façon dont les ordinateurs peuvent aider les gens à mieux écrire. Les outils d'écriture d'IA, tels que Grammarly, proposent des réécritures de phrases et de paragraphes pour améliorer le ton et la clarté. Ce type de modèle a également amélioré la rapidité et la précision des suggestions grammaticales de base. Apprenez-en davantage sur la façon dont Grammarly utilise l’IA.
Génération de contenu :si vous avez utilisé ChatGPT ou DALL-E, vous avez fait l'expérience de l'IA générative. Les transformateurs ont révolutionné la capacité des ordinateurs à créer des médias qui résonnent avec les humains, des histoires au coucher aux rendus architecturaux hyperréalistes.
Reconnaissance vocale :les ordinateurs s'améliorent chaque jour dans leur capacité à reconnaître la parole humaine. Avec des technologies plus récentes qui leur permettent de considérer davantage de contexte, les modèles sont devenus de plus en plus précis dans la reconnaissance de ce que l'orateur a l'intention de dire, même si les sons à eux seuls peuvent donner lieu à de multiples interprétations.
Diagnostic et recherche médicale :les réseaux neuronaux excellent dans la détection et la classification de modèles, qui sont de plus en plus utilisés pour aider les chercheurs et les prestataires de soins de santé à comprendre et à traiter les maladies. Par exemple, nous devons en partie à l’IA le développement rapide des vaccins contre la COVID-19.
Défis et limites des réseaux de neurones
Voici un bref aperçu de certains des problèmes soulevés par les réseaux de neurones, mais pas tous.
Biais :un réseau neuronal ne peut apprendre que de ce qui lui a été dit. S'il est exposé à un contenu sexiste ou raciste, son contenu sera probablement également sexiste ou raciste. Cela peut se produire lors de la traduction d’un langage non genré vers un langage genré, où les stéréotypes persistent sans identification explicite du genre.
Surajustement :un modèle mal entraîné peut lire trop de données dans les données qui lui ont été fournies et avoir du mal à gérer de nouvelles entrées. Par exemple, un logiciel de reconnaissance faciale formé principalement sur des personnes d’une certaine ethnie pourrait avoir de mauvais résultats avec des visages d’autres races. Ou encore, un filtre anti-spam peut passer à côté d'une nouvelle variété de courrier indésirable parce qu'il est trop axé sur des modèles déjà observés.
Hallucinations :une grande partie de l'IA générative actuelle utilise la probabilité dans une certaine mesure pour choisir ce qu'elle doit produire plutôt que de toujours sélectionner le choix le mieux classé. Cette approche l’aide à être plus créatif et à produire un texte qui semble plus naturel, mais elle peut aussi l’amener à faire des déclarations tout simplement fausses. (C'est aussi la raison pour laquelle les LLM se trompent parfois en mathématiques de base.) Malheureusement, ces hallucinations sont difficiles à détecter à moins que vous ne connaissiez mieux ou que vous ne vérifiiez les faits auprès d'autres sources.
Interprétabilité :il est souvent impossible de savoir exactement comment un réseau neuronal fait des prédictions. Bien que cela puisse être frustrant du point de vue de quelqu'un qui tente d'améliorer le modèle, cela peut également avoir des conséquences, car on s'appuie de plus en plus sur l'IA pour prendre des décisions qui ont un impact considérable sur la vie des gens. Certains modèles utilisés aujourd'hui ne sont pas basés sur des réseaux de neurones précisément parce que leurs créateurs souhaitent pouvoir inspecter et comprendre chaque étape du processus.
Propriété intellectuelle :Beaucoup pensent que les LLM violent le droit d'auteur en incorporant des écrits et d'autres œuvres d'art sans autorisation. Bien qu'ils aient tendance à ne pas reproduire directement des œuvres protégées par le droit d'auteur, ces modèles sont connus pour créer des images ou des phrases probablement dérivées d'artistes spécifiques ou même pour créer des œuvres dans le style distinctif d'un artiste lorsque vous y êtes invité.
Consommation d'énergie :toute cette formation et ce fonctionnement des modèles de transformateurs consomment énormément d'énergie. En fait, d’ici quelques années, l’IA pourrait consommer autant d’énergie que la Suède ou l’Argentine. Cela souligne l’importance croissante de prendre en compte les sources d’énergie et l’efficacité dans le développement de l’IA.
L'avenir des réseaux de neurones
Il est notoirement difficile de prédire l’avenir de l’IA. En 1970, l’un des meilleurs chercheurs en IA prédisait que « dans trois à huit ans, nous aurons une machine dotée de l’intelligence générale d’un être humain moyen ». (Nous ne sommes pas encore très proches de l’intelligence artificielle générale (AGI). Du moins, la plupart des gens ne le pensent pas.)
Nous pouvons néanmoins souligner quelques tendances à surveiller. Des modèles plus efficaces réduiraient la consommation d’énergie et exécuteraient des réseaux neuronaux plus puissants directement sur des appareils comme les smartphones. De nouvelles techniques de formation pourraient permettre des prédictions plus utiles avec moins de données de formation. Une percée dans l’interprétabilité pourrait accroître la confiance et ouvrir de nouvelles voies pour améliorer la production des réseaux neuronaux. Enfin, la combinaison de l’informatique quantique et des réseaux neuronaux pourrait conduire à des innovations que nous ne pouvons que commencer à imaginer.
Conclusion
Les réseaux de neurones, inspirés de la structure et du fonctionnement du cerveau humain, sont fondamentaux pour l’intelligence artificielle moderne. Ils excellent dans les tâches de reconnaissance de formes et de prédiction, qui sous-tendent de nombreuses applications d'IA actuelles, de la reconnaissance d'images et de la parole au traitement du langage naturel. Grâce aux progrès de l’architecture et des techniques de formation, les réseaux de neurones continuent de générer des améliorations significatives des capacités de l’IA.
Malgré leur potentiel, les réseaux de neurones sont confrontés à des défis tels que les biais, le surapprentissage et la consommation d'énergie élevée. Il est crucial de résoudre ces problèmes à mesure que l’IA continue d’évoluer. À l’avenir, les innovations en matière d’efficacité des modèles, d’interprétabilité et d’intégration avec l’informatique quantique promettent d’élargir encore les possibilités des réseaux neuronaux, conduisant potentiellement à des applications encore plus transformatrices.