
Bases des réseaux neuronaux récurrents : ce que vous devez savoir
Publié: 2024-09-19Les réseaux de neurones récurrents (RNN) sont des méthodes essentielles dans les domaines de l'analyse des données, de l'apprentissage automatique (ML) et de l'apprentissage profond. Cet article vise à explorer les RNN et à détailler leurs fonctionnalités, leurs applications, ainsi que leurs avantages et inconvénients dans le contexte plus large de l'apprentissage profond.
Table des matières
Qu’est-ce qu’un RNN ?
Comment fonctionnent les RNN
Types de RNN
RNN vs transformateurs et CNN
Applications des RNN
Avantages
Inconvénients
Qu'est-ce qu'un réseau de neurones récurrent ?
Un réseau neuronal récurrent est un réseau neuronal profond capable de traiter des données séquentielles en conservant une mémoire interne, lui permettant de garder une trace des entrées passées pour générer des sorties. Les RNN sont un élément fondamental de l’apprentissage profond et sont particulièrement adaptés aux tâches impliquant des données séquentielles.
Le « récurrent » dans « réseau neuronal récurrent » fait référence à la façon dont le modèle combine les informations des entrées passées avec les entrées actuelles. Les informations provenant des anciennes entrées sont stockées dans une sorte de mémoire interne, appelée « état caché ». Il est récurrent : il réinjecte les calculs antérieurs sur lui-même pour créer un flux continu d'informations.
Montrons avec un exemple : supposons que nous voulions utiliser un RNN pour détecter le sentiment (positif ou négatif) de la phrase « Il a mangé la tarte avec plaisir ». Le RNN traiterait le mothe, mettrait à jour son état caché pour incorporer ce mot, puis passerait àate, combinerait cela avec ce qu'il a appris dehe, et ainsi de suite avec chaque mot jusqu'à ce que la phrase soit terminée. Pour mettre les choses en perspective, un humain lisant cette phrase mettrait à jour sa compréhension à chaque mot. Une fois qu’il a lu et compris la phrase entière, l’humain peut dire que la phrase est positive ou négative. C’est à ce processus humain de compréhension que l’état caché tente de se rapprocher.
Les RNN sont l’un des modèles fondamentaux d’apprentissage profond. Ils ont très bien réussi dans les tâches de traitement du langage naturel (NLP), bien que les transformateurs les aient supplantés. Les transformateurs sont des architectures de réseaux neuronaux avancées qui améliorent les performances RNN, par exemple en traitant les données en parallèle et en étant capables de découvrir des relations entre des mots éloignés dans le texte source (à l'aide de mécanismes d'attention). Cependant, les RNN restent utiles pour les données de séries chronologiques et pour les situations où des modèles plus simples suffisent.
Comment fonctionnent les RNN
Pour décrire en détail le fonctionnement des RNN, revenons à l'exemple de tâche précédent : classer le sentiment de la phrase « Il a mangé la tarte avec plaisir ».
Nous commençons par un RNN formé qui accepte les entrées de texte et renvoie une sortie binaire (1 représentant le positif et 0 représentant le négatif). Avant que l'entrée ne soit transmise au modèle, l'état caché est générique : il a été appris lors du processus de formation mais n'est pas encore spécifique à l'entrée.
Le premier mot,He, est transmis au modèle. À l'intérieur du RNN, son état caché est ensuite mis à jour (vers l'état caché h1) pour incorporer le motHe. Ensuite, le motateest transmis au RNN et h1 est mis à jour (en h2) pour inclure ce nouveau mot. Ce processus se répète jusqu'à ce que le dernier mot soit transmis. L'état masqué (h4) est mis à jour pour inclure le dernier mot. Ensuite, l'état caché mis à jour est utilisé pour générer un 0 ou un 1.
Voici une représentation visuelle du fonctionnement du processus RNN :
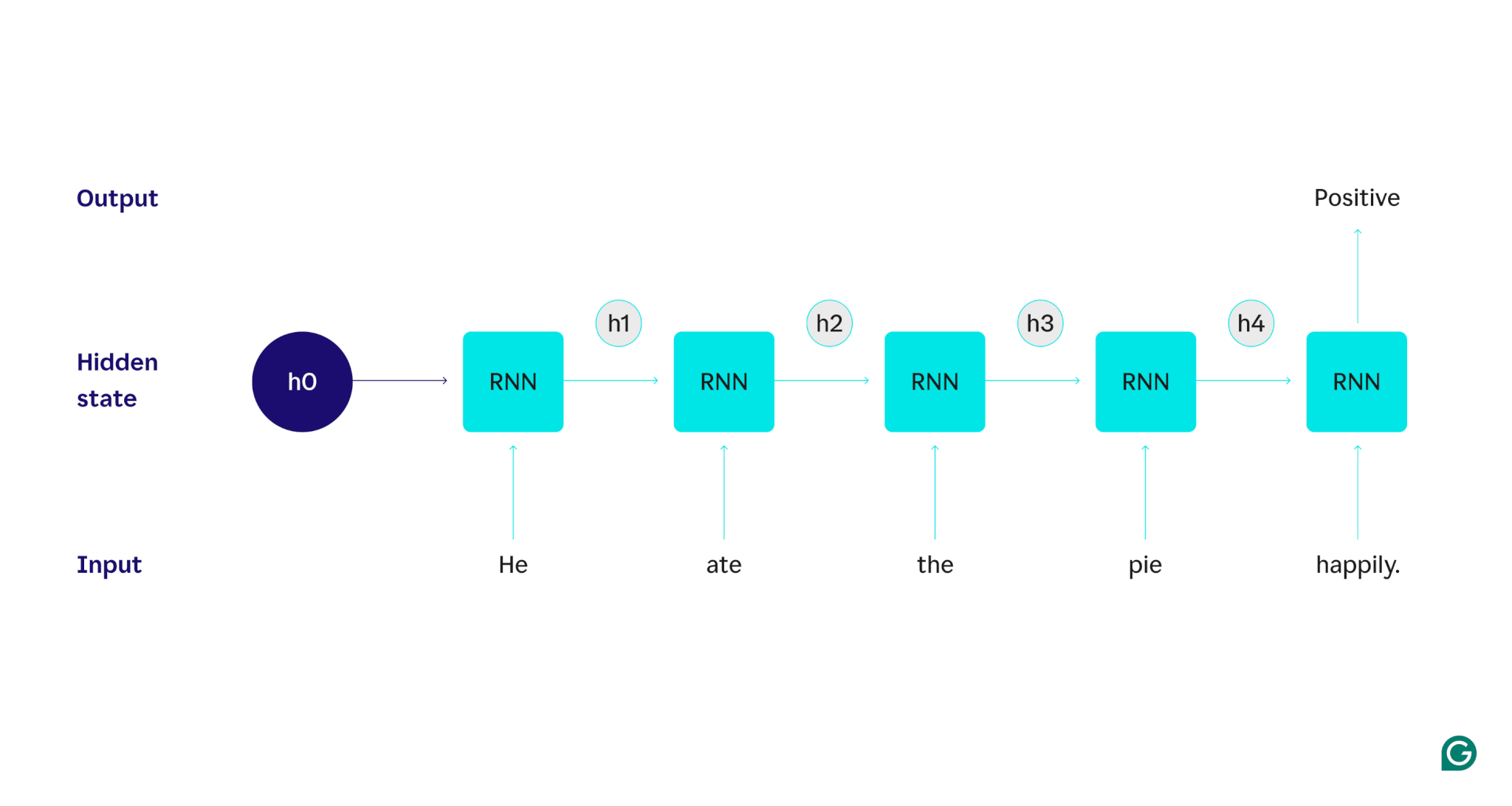
Cette récurrence est au cœur du RNN, mais il y a quelques autres considérations :
- Incorporation de texte :le RNN ne peut pas traiter le texte directement car il ne fonctionne que sur des représentations numériques. Le texte doit être converti en intégrations avant de pouvoir être traité par un RNN.
- Génération de sortie :une sortie sera générée par le RNN à chaque étape. Cependant, le résultat peut ne pas être très précis tant que la plupart des données sources n'ont pas été traitées. Par exemple, après avoir traité uniquement la partie « Il a mangé » de la phrase, le RNN peut ne pas savoir si elle représente un sentiment positif ou négatif : « Il a mangé » peut apparaître comme neutre. Ce n'est qu'après avoir traité la phrase complète que le résultat du RNN serait précis.
- Formation du RNN :Le RNN doit être formé pour effectuer une analyse des sentiments avec précision. La formation implique d'utiliser de nombreux exemples étiquetés (par exemple, « Il a mangé la tarte avec colère », étiquetés comme négatifs), de les exécuter dans le RNN et d'ajuster le modèle en fonction de l'écart entre ses prédictions. Ce processus définit la valeur par défaut et le mécanisme de modification de l'état caché, permettant au RNN d'apprendre quels mots sont importants pour le suivi tout au long de l'entrée.
Types de réseaux de neurones récurrents
Il existe plusieurs types de RNN, chacun variant dans sa structure et son application. Les RNN de base diffèrent principalement par la taille de leurs entrées et sorties. Les RNN avancés, tels que les réseaux à mémoire à long terme (LSTM), répondent à certaines des limites des RNN de base.
RNN de base
RNN un-à-un :ce RNN reçoit une entrée de longueur un et renvoie une sortie de longueur un. Par conséquent, aucune récidive ne se produit réellement, ce qui en fait un réseau neuronal standard plutôt qu’un RNN. Un exemple de RNN un-à-un serait un classificateur d'images, où l'entrée est une image unique et la sortie est une étiquette (par exemple, « oiseau »).
RNN un-à-plusieurs :ce RNN accepte une entrée de longueur un et renvoie une sortie en plusieurs parties. Par exemple, dans une tâche de sous-titrage d'image, l'entrée est une image et la sortie est une séquence de mots décrivant l'image (par exemple, « Un oiseau traverse une rivière par une journée ensoleillée »).
RNN plusieurs-à-un :ce RNN prend en compte une entrée en plusieurs parties (par exemple, une phrase, une série d'images ou des données de séries chronologiques) et renvoie une sortie d'une longueur d'un. Par exemple, un classificateur de sentiments de phrase (comme celui dont nous avons discuté), où l'entrée est une phrase et la sortie est une seule étiquette de sentiment (positive ou négative).
RNN plusieurs-à-plusieurs :ce RNN prend une entrée en plusieurs parties et renvoie une sortie en plusieurs parties. Un exemple est un modèle de reconnaissance vocale, dans lequel l'entrée est une série de formes d'onde audio et la sortie est une séquence de mots représentant le contenu parlé.
RNN avancé : mémoire à long terme (LSTM)
Les réseaux de mémoire à long terme sont conçus pour résoudre un problème important avec les RNN standard : ils oublient des informations sur de longues entrées. Dans les RNN standard, l’état caché est fortement axé sur les parties récentes de l’entrée. Dans une entrée de plusieurs milliers de mots, le RNN oubliera les détails importants des phrases d'ouverture. Les LSTM ont une architecture spéciale pour contourner ce problème d'oubli. Ils ont des modules qui sélectionnent les informations à mémoriser et à oublier explicitement. Ainsi les informations récentes mais inutiles seront oubliées, tandis que les informations anciennes mais pertinentes seront conservées. En conséquence, les LSTM sont beaucoup plus courants que les RNN standards : ils fonctionnent simplement mieux sur des tâches complexes ou longues. Cependant, ils ne sont pas parfaits puisqu’ils choisissent toujours d’oublier des objets.
RNN vs transformateurs et CNN
Deux autres modèles d'apprentissage profond courants sont les réseaux de neurones convolutifs (CNN) et les transformateurs. En quoi diffèrent-ils ?

RNN vs transformateurs
Les RNN et les transformateurs sont largement utilisés en PNL. Cependant, ils diffèrent considérablement dans leurs architectures et leurs approches du traitement des entrées.
Architecture et traitement
- RNN :les RNN traitent la saisie de manière séquentielle, un mot à la fois, en maintenant un état caché qui transporte les informations des mots précédents. Cette nature séquentielle signifie que les RNN peuvent être confrontés à des dépendances à long terme en raison de cet oubli, dans lequel des informations antérieures peuvent être perdues au fur et à mesure que la séquence progresse.
- Transformateurs :les transformateurs utilisent un mécanisme appelé « attention » pour traiter les entrées. Contrairement aux RNN, les transformateurs examinent simultanément la séquence entière, comparant chaque mot avec tous les autres mots. Cette approche élimine le problème de l'oubli, car chaque mot a un accès direct à l'ensemble du contexte d'entrée. Les transformateurs ont montré des performances supérieures dans des tâches telles que la génération de texte et l'analyse des sentiments grâce à cette capacité.
Parallélisation
- RNN :la nature séquentielle des RNN signifie que le modèle doit terminer le traitement d’une partie de l’entrée avant de passer à la suivante. Cela prend beaucoup de temps, car chaque étape dépend de la précédente.
- Transformateurs :les transformateurs traitent toutes les parties de l'entrée simultanément, car leur architecture ne repose pas sur un état caché séquentiel. Cela les rend beaucoup plus parallélisables et efficaces. Par exemple, si le traitement d’une phrase prend 5 secondes par mot, un RNN prendrait 25 secondes pour une phrase de 5 mots, alors qu’un transformateur ne prendrait que 5 secondes.
Implications pratiques
En raison de ces avantages, les transformateurs sont plus largement utilisés dans l’industrie. Cependant, les RNN, en particulier les réseaux à mémoire longue et à court terme (LSTM), peuvent toujours être efficaces pour des tâches plus simples ou lorsqu'il s'agit de séquences plus courtes. Les LSTM sont souvent utilisés comme modules de stockage de mémoire critiques dans les grandes architectures d'apprentissage automatique.
RNN contre CNN
Les CNN sont fondamentalement différents des RNN en termes de données qu'ils traitent et de leurs mécanismes opérationnels.
Type de données
- RNN :les RNN sont conçus pour les données séquentielles, telles que du texte ou des séries chronologiques, où l'ordre des points de données est important.
- CNN :les CNN sont principalement utilisés pour les données spatiales, comme les images, où l'accent est mis sur les relations entre les points de données adjacents (par exemple, la couleur, l'intensité et d'autres propriétés d'un pixel dans une image sont étroitement liées aux propriétés d'autres points de données proches). pixels).
Opération
- RNN :les RNN conservent une mémoire de la séquence entière, ce qui les rend adaptés aux tâches où le contexte et la séquence sont importants.
- CNN :les CNN fonctionnent en examinant les régions locales de l'entrée (par exemple, les pixels voisins) à travers des couches convolutives. Cela les rend très efficaces pour le traitement d’images, mais moins pour les données séquentielles, où les dépendances à long terme peuvent être plus importantes.
Longueur d'entrée
- RNN :les RNN peuvent gérer des séquences d’entrée de longueur variable avec une structure moins définie, ce qui les rend flexibles pour différents types de données séquentielles.
- CNN :les CNN nécessitent généralement des entrées de taille fixe, ce qui peut constituer une limitation pour la gestion des séquences de longueur variable.
Applications des RNN
Les RNN sont largement utilisés dans divers domaines en raison de leur capacité à gérer efficacement les données séquentielles.
Traitement du langage naturel
Le langage est une forme de données hautement séquentielle, les RNN fonctionnent donc bien dans les tâches linguistiques. Les RNN excellent dans des tâches telles que la génération de texte, l'analyse des sentiments, la traduction et le résumé. Avec des bibliothèques comme PyTorch, quelqu'un pourrait créer un simple chatbot en utilisant un RNN et quelques gigaoctets d'exemples de texte.
Reconnaissance vocale
La reconnaissance vocale est à la base du langage et est donc également hautement séquentielle. Un RNN plusieurs-à-plusieurs pourrait être utilisé pour cette tâche. À chaque étape, le RNN reprend l'état caché précédent et la forme d'onde, produisant le mot associé à la forme d'onde (en fonction du contexte de la phrase jusqu'à ce point).
Génération de musique
La musique est également très séquentielle. Les rythmes précédents d’une chanson influencent fortement les rythmes futurs. Un RNN plusieurs-à-plusieurs pourrait prendre quelques battements de départ en entrée, puis générer des battements supplémentaires selon le souhait de l'utilisateur. Alternativement, il pourrait prendre une saisie de texte comme « jazz mélodique » et produire sa meilleure approximation des rythmes de jazz mélodique.
Avantages des RNN
Bien que les RNN ne soient plus le modèle de facto de la PNL, ils ont encore certaines utilisations en raison de plusieurs facteurs.
Bonnes performances séquentielles
Les RNN, en particulier les LSTM, fonctionnent bien avec les données séquentielles. Les LSTM, avec leur architecture de mémoire spécialisée, peuvent gérer des entrées séquentielles longues et complexes. Par exemple, Google Translate fonctionnait sur un modèle LSTM avant l’ère des transformateurs. Les LSTM peuvent être utilisés pour ajouter des modules de mémoire stratégiques lorsque des réseaux basés sur des transformateurs sont combinés pour former des architectures plus avancées.
Des modèles plus petits et plus simples
Les RNN ont généralement moins de paramètres de modèle que les transformateurs. Les couches d'attention et de rétroaction des transformateurs nécessitent davantage de paramètres pour fonctionner efficacement. Les RNN peuvent être formés avec moins d’exécutions et d’exemples de données, ce qui les rend plus efficaces pour des cas d’utilisation plus simples. Il en résulte des modèles plus petits, moins chers et plus efficaces, mais néanmoins suffisamment performants.
Inconvénients des RNN
Les RNN sont tombés en disgrâce pour une raison : les transformateurs, malgré leur plus grande taille et leur processus de formation, n'ont pas les mêmes défauts que les RNN.
Mémoire limitée
L'état caché des RNN standards biaise fortement les entrées récentes, ce qui rend difficile la conservation des dépendances à long terme. Les tâches avec des entrées longues ne fonctionnent pas aussi bien avec les RNN. Bien que les LSTM visent à résoudre ce problème, ils ne font que l’atténuer et ne le résolvent pas complètement. De nombreuses tâches d’IA nécessitent de gérer de longues entrées, ce qui fait de la mémoire limitée un inconvénient majeur.
Non parallélisable
Chaque exécution du modèle RNN dépend de la sortie de l'exécution précédente, en particulier de l'état caché mis à jour. Par conséquent, l’ensemble du modèle doit être traité séquentiellement pour chaque partie d’une entrée. En revanche, les transformateurs et les CNN peuvent traiter l’intégralité de l’entrée simultanément. Cela permet un traitement parallèle sur plusieurs GPU, accélérant considérablement le calcul. Le manque de parallélisabilité des RNN entraîne un apprentissage plus lent, une génération de sortie plus lente et une quantité maximale de données pouvant être apprises plus faible.
Problèmes de dégradé
La formation des RNN peut être difficile car le processus de rétropropagation doit passer par chaque étape d'entrée (rétropropagation dans le temps). En raison des nombreux pas de temps, les gradients, qui indiquent comment chaque paramètre du modèle doit être ajusté, peuvent se dégrader et devenir inefficaces. Les dégradés peuvent échouer en disparaissant, ce qui signifie qu'ils deviennent très petits et que le modèle ne peut plus les utiliser pour apprendre, ou en explosant, les dégradés devenant très importants et le modèle dépasse ses mises à jour, le rendant inutilisable. Il est difficile de trouver un équilibre entre ces questions.