
Qu'est-ce qu'un auto-encodeur ? Un guide du débutant
Publié: 2024-10-28Les auto-encodeurs sont un composant essentiel du deep learning, en particulier dans les tâches d'apprentissage automatique non supervisées. Dans cet article, nous explorerons le fonctionnement des encodeurs automatiques, leur architecture et les différents types disponibles. Vous découvrirez également leurs applications réelles, ainsi que les avantages et les compromis liés à leur utilisation.
Table des matières
- Qu'est-ce qu'un auto-encodeur ?
- Architecture de l'encodeur automatique
- Types d'auto-encodeurs
- Application
- Avantages
- Inconvénients
Qu'est-ce qu'un auto-encodeur ?
Les auto-encodeurs sont un type de réseau neuronal utilisé dans l'apprentissage profond pour apprendre des représentations efficaces et de moindre dimension des données d'entrée, qui sont ensuite utilisées pour reconstruire les données d'origine. Ce faisant, ce réseau apprend les caractéristiques les plus essentielles des données pendant la formation sans nécessiter d'étiquettes explicites, ce qui en fait une partie de l'apprentissage auto-supervisé. Les auto-encodeurs sont largement utilisés dans des tâches telles que le débruitage d'images, la détection d'anomalies et la compression de données, où leur capacité à compresser et à reconstruire les données est précieuse.
Architecture de l'encodeur automatique
Un auto-encodeur est composé de trois parties : un encodeur, un goulot d'étranglement (également appelé espace latent ou code) et un décodeur. Ces composants fonctionnent ensemble pour capturer les caractéristiques clés des données d'entrée et les utiliser pour générer des reconstructions précises.
Les auto-encodeurs optimisent leur sortie en ajustant les poids de l'encodeur et du décodeur, dans le but de produire une représentation compressée de l'entrée qui préserve les caractéristiques critiques. Cette optimisation minimise l'erreur de reconstruction, qui représente la différence entre les données d'entrée et de sortie.
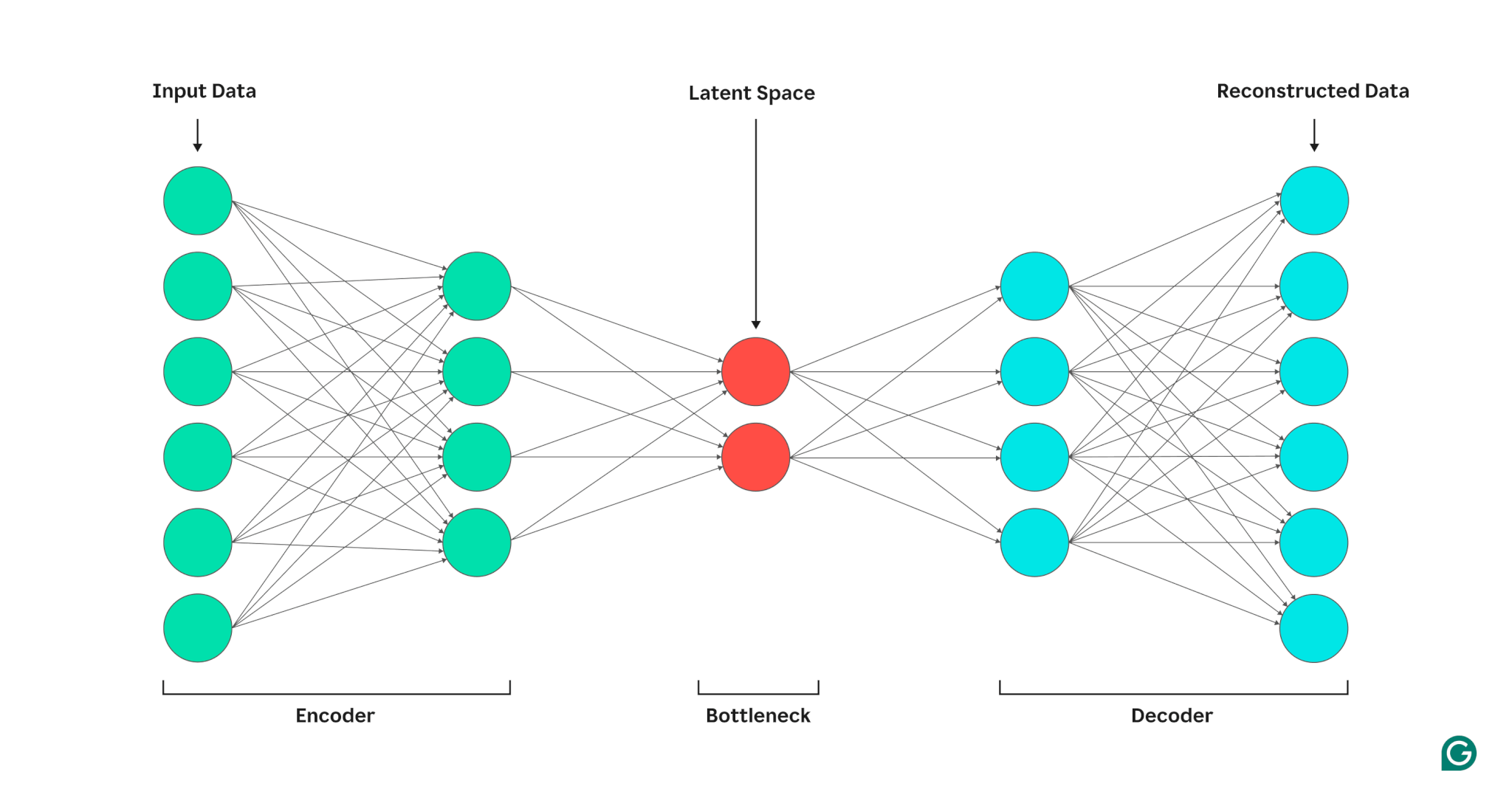
Encodeur
Tout d’abord, l’encodeur compresse les données d’entrée en une représentation plus efficace. Les encodeurs sont généralement constitués de plusieurs couches avec moins de nœuds dans chaque couche. Au fur et à mesure que les données sont traitées à travers chaque couche, le nombre réduit de nœuds oblige le réseau à apprendre les caractéristiques les plus importantes des données pour créer une représentation pouvant être stockée dans chaque couche. Ce processus, connu sous le nom de réduction de dimensionnalité, transforme l'entrée en un résumé compact des caractéristiques clés des données. Les hyperparamètres clés de l'encodeur incluent le nombre de couches et de neurones par couche, qui déterminent la profondeur et la granularité de la compression, ainsi que la fonction d'activation, qui dicte la manière dont les caractéristiques des données sont représentées et transformées à chaque couche.
Goulot
Le goulot d'étranglement, également appelé espace latent ou code, est l'endroit où la représentation compressée des données d'entrée est stockée pendant le traitement. Le goulot d'étranglement comporte un petit nombre de nœuds ; cela limite la quantité de données pouvant être stockées et détermine le niveau de compression. Le nombre de nœuds dans le goulot d'étranglement est un hyperparamètre réglable, permettant aux utilisateurs de contrôler le compromis entre compression et conservation des données. Si le goulot d'étranglement est trop petit, l'auto-encodeur peut reconstruire les données de manière incorrecte en raison de la perte de détails importants. D’un autre côté, si le goulot d’étranglement est trop important, l’auto-encodeur peut simplement copier les données d’entrée au lieu d’apprendre une représentation générale significative.
Décodeur
Dans cette étape finale, le décodeur recrée les données originales à partir du formulaire compressé en utilisant les fonctionnalités clés apprises au cours du processus de codage. La qualité de cette décompression est quantifiée à l’aide de l’erreur de reconstruction, qui est essentiellement une mesure de la différence entre les données reconstruites et l’entrée. L'erreur de reconstruction est généralement calculée à l'aide de l'erreur quadratique moyenne (MSE). Étant donné que MSE mesure la différence au carré entre les données originales et reconstruites, il fournit un moyen mathématiquement simple de pénaliser plus lourdement les erreurs de reconstruction plus importantes.
Types d'auto-encodeurs
Il existe plusieurs types d'auto-encodeurs spécialisés, chacun optimisé pour des applications spécifiques, similaires à d'autres réseaux de neurones.
Encodeurs automatiques débruitants
Les auto-encodeurs de débruitage sont conçus pour reconstruire des données propres à partir d'entrées bruyantes ou corrompues. Pendant l'entraînement, du bruit est intentionnellement ajouté aux données d'entrée, permettant au modèle d'apprendre des fonctionnalités qui restent cohérentes malgré le bruit. Les sorties sont ensuite comparées aux entrées propres d’origine. Ce processus rend les auto-encodeurs de débruitage très efficaces dans les tâches de réduction du bruit d'image et audio, y compris la suppression du bruit de fond lors des vidéoconférences.
Encodeurs automatiques clairsemés
Les auto-encodeurs clairsemés limitent le nombre de neurones actifs à un moment donné, encourageant le réseau à apprendre des représentations de données plus efficaces par rapport aux auto-encodeurs standard. Cette contrainte de parcimonie est appliquée par une pénalité qui décourage l'activation de plus de neurones qu'un seuil spécifié. Les auto-encodeurs clairsemés simplifient les données de grande dimension tout en préservant les fonctionnalités essentielles, ce qui les rend utiles pour des tâches telles que l'extraction de fonctionnalités interprétables et la visualisation d'ensembles de données complexes.
Auto-encodeurs variationnels (VAE)
Contrairement aux auto-encodeurs classiques, les VAE génèrent de nouvelles données en codant les caractéristiques des données d'entraînement dans une distribution de probabilité, plutôt qu'un point fixe. En échantillonnant à partir de cette distribution, les VAE peuvent générer diverses nouvelles données, au lieu de reconstruire les données originales à partir de l'entrée. Cette capacité rend les VAE utiles pour les tâches génératives, notamment la génération de données synthétiques. Par exemple, dans la génération d’images, un VAE formé sur un ensemble de données de nombres manuscrits peut créer de nouveaux chiffres d’apparence réaliste basés sur l’ensemble d’entraînement qui ne sont pas des répliques exactes.

Auto-encodeurs contractifs
Les auto-encodeurs contractifs introduisent un terme de pénalité supplémentaire lors du calcul de l'erreur de reconstruction, encourageant le modèle à apprendre des représentations de caractéristiques robustes au bruit. Cette pénalité permet d'éviter le surapprentissage en favorisant l'apprentissage des fonctionnalités qui est invariant aux petites variations des données d'entrée. En conséquence, les auto-encodeurs contractifs sont plus robustes au bruit que les auto-encodeurs standard.
Auto-encodeurs convolutifs (CAE)
Les CAE utilisent des couches convolutives pour capturer des hiérarchies et des modèles spatiaux au sein de données de grande dimension. L'utilisation de couches convolutives rend les CAE particulièrement bien adaptés au traitement des données d'image. Les CAE sont couramment utilisés dans des tâches telles que la compression d’images et la détection d’anomalies dans les images.
Applications des auto-encodeurs en IA
Les auto-encodeurs ont plusieurs applications, telles que la réduction de dimensionnalité, le débruitage d'image et la détection d'anomalies.
Réduction de dimensionnalité
Les encodeurs automatiques sont des outils efficaces pour réduire la dimensionnalité des données d'entrée tout en préservant les fonctionnalités clés. Ce processus est utile pour des tâches telles que la visualisation d'ensembles de données de grande dimension et la compression des données. En simplifiant les données, la réduction de dimensionnalité améliore également l'efficacité des calculs, réduisant à la fois la taille et la complexité.
Détection d'anomalies
En apprenant les principales caractéristiques d'un ensemble de données cible, les auto-encodeurs peuvent faire la distinction entre les données normales et anormales lorsqu'ils reçoivent une nouvelle entrée. Un écart par rapport à la normale est indiqué par des taux d’erreur de reconstruction supérieurs à la normale. En tant que tels, les auto-encodeurs peuvent être appliqués à divers domaines tels que la maintenance prédictive et la sécurité des réseaux informatiques.
Débruitage
Les auto-encodeurs de débruitage peuvent nettoyer les données bruyantes en apprenant à les reconstruire à partir d'entrées d'entraînement bruyantes. Cette capacité rend les auto-encodeurs de débruitage précieux pour des tâches telles que l'optimisation des images, notamment l'amélioration de la qualité des photographies floues. Les auto-encodeurs de débruitage sont également utiles dans le traitement du signal, où ils peuvent nettoyer les signaux bruyants pour un traitement et une analyse plus efficaces.
Avantages des encodeurs automatiques
Les auto-encodeurs présentent un certain nombre d’avantages clés. Celles-ci incluent la possibilité d'apprendre à partir de données non étiquetées, d'apprendre automatiquement des fonctionnalités sans instruction explicite et d'extraire des fonctionnalités non linéaires.
Capable d’apprendre à partir de données non étiquetées
Les encodeurs automatiques sont un modèle d'apprentissage automatique non supervisé, ce qui signifie qu'ils peuvent apprendre les caractéristiques des données sous-jacentes à partir de données non étiquetées. Cette fonctionnalité signifie que les auto-encodeurs peuvent être appliqués à des tâches pour lesquelles les données étiquetées peuvent être rares ou indisponibles.
Apprentissage automatique des fonctionnalités
Les techniques standard d’extraction de caractéristiques, telles que l’analyse en composantes principales (ACP), sont souvent peu pratiques lorsqu’il s’agit de gérer des ensembles de données complexes et/ou volumineux. Étant donné que les encodeurs automatiques ont été conçus pour des tâches telles que la réduction de dimensionnalité, ils peuvent automatiquement apprendre les caractéristiques et les modèles clés des données sans conception manuelle des caractéristiques.
Extraction de caractéristiques non linéaires
Les encodeurs automatiques peuvent gérer des relations non linéaires dans les données d'entrée, permettant au modèle de capturer les caractéristiques clés de représentations de données plus complexes. Cette capacité signifie que les auto-encodeurs ont un avantage sur les modèles qui ne peuvent fonctionner qu'avec des données linéaires, car ils peuvent gérer des ensembles de données plus complexes.
Limites des auto-encodeurs
Comme les autres modèles ML, les encodeurs automatiques présentent leurs propres inconvénients. Ceux-ci incluent le manque d'interprétabilité, la nécessité de disposer d'un grand ensemble de données de formation pour fonctionner correctement et des capacités de généralisation limitées.
Manque d'interprétabilité
À l’instar d’autres modèles ML complexes, les auto-encodeurs souffrent d’un manque d’interprétabilité, ce qui signifie qu’il est difficile de comprendre la relation entre les données d’entrée et la sortie du modèle. Dans les auto-encodeurs, ce manque d'interprétabilité se produit parce que les auto-encodeurs apprennent automatiquement les fonctionnalités, contrairement aux modèles traditionnels, où les fonctionnalités sont explicitement définies. Cette représentation de caractéristiques générée par machine est souvent très abstraite et a tendance à manquer de caractéristiques interprétables par l'homme, ce qui rend difficile la compréhension de la signification de chaque composant de la représentation.
Nécessite de grands ensembles de données de formation
Les encodeurs automatiques nécessitent généralement de grands ensembles de données de formation pour apprendre des représentations généralisables des caractéristiques de données clés. Étant donné les petits ensembles de données de formation, les auto-encodeurs peuvent avoir tendance à être surajustés, ce qui conduit à une mauvaise généralisation lorsqu'ils sont présentés avec de nouvelles données. En revanche, les grands ensembles de données offrent la diversité nécessaire à l'auto-encodeur pour apprendre les fonctionnalités de données qui peuvent être appliquées dans un large éventail de scénarios.
Généralisation limitée sur de nouvelles données
Les auto-encodeurs formés sur un seul ensemble de données ont souvent des capacités de généralisation limitées, ce qui signifie qu'ils ne parviennent pas à s'adapter aux nouveaux ensembles de données. Cette limitation se produit parce que les encodeurs automatiques sont orientés vers la reconstruction de données basée sur les caractéristiques importantes d'un ensemble de données donné. En tant que tels, les encodeurs automatiques suppriment généralement les détails les plus petits des données pendant la formation et ne peuvent pas gérer les données qui ne correspondent pas à la représentation généralisée des fonctionnalités.