
Qu'est-ce qu'un arbre de décision dans l'apprentissage automatique ?
Publié: 2024-08-14Les arbres de décision sont l'un des outils les plus courants de la boîte à outils d'apprentissage automatique d'un analyste de données. Dans ce guide, vous découvrirez ce que sont les arbres de décision, comment ils sont construits, diverses applications, avantages et bien plus encore.
Table des matières
- Qu'est-ce qu'un arbre de décision ?
- Terminologie de l'arbre de décision
- Types d'arbres de décision
- Comment fonctionnent les arbres de décision
- Applications
- Avantages
- Inconvénients
Qu'est-ce qu'un arbre de décision ?
En apprentissage automatique (ML), un arbre de décision est un algorithme d'apprentissage supervisé qui ressemble à un organigramme ou à un tableau de décision. Contrairement à de nombreux autres algorithmes d’apprentissage supervisé, les arbres de décision peuvent être utilisés à la fois pour des tâches de classification et de régression. Les data scientists et les analystes utilisent souvent des arbres de décision lorsqu'ils explorent de nouveaux ensembles de données, car ils sont faciles à construire et à interpréter. De plus, les arbres de décision peuvent aider à identifier les caractéristiques de données importantes qui peuvent être utiles lors de l'application d'algorithmes de ML plus complexes.
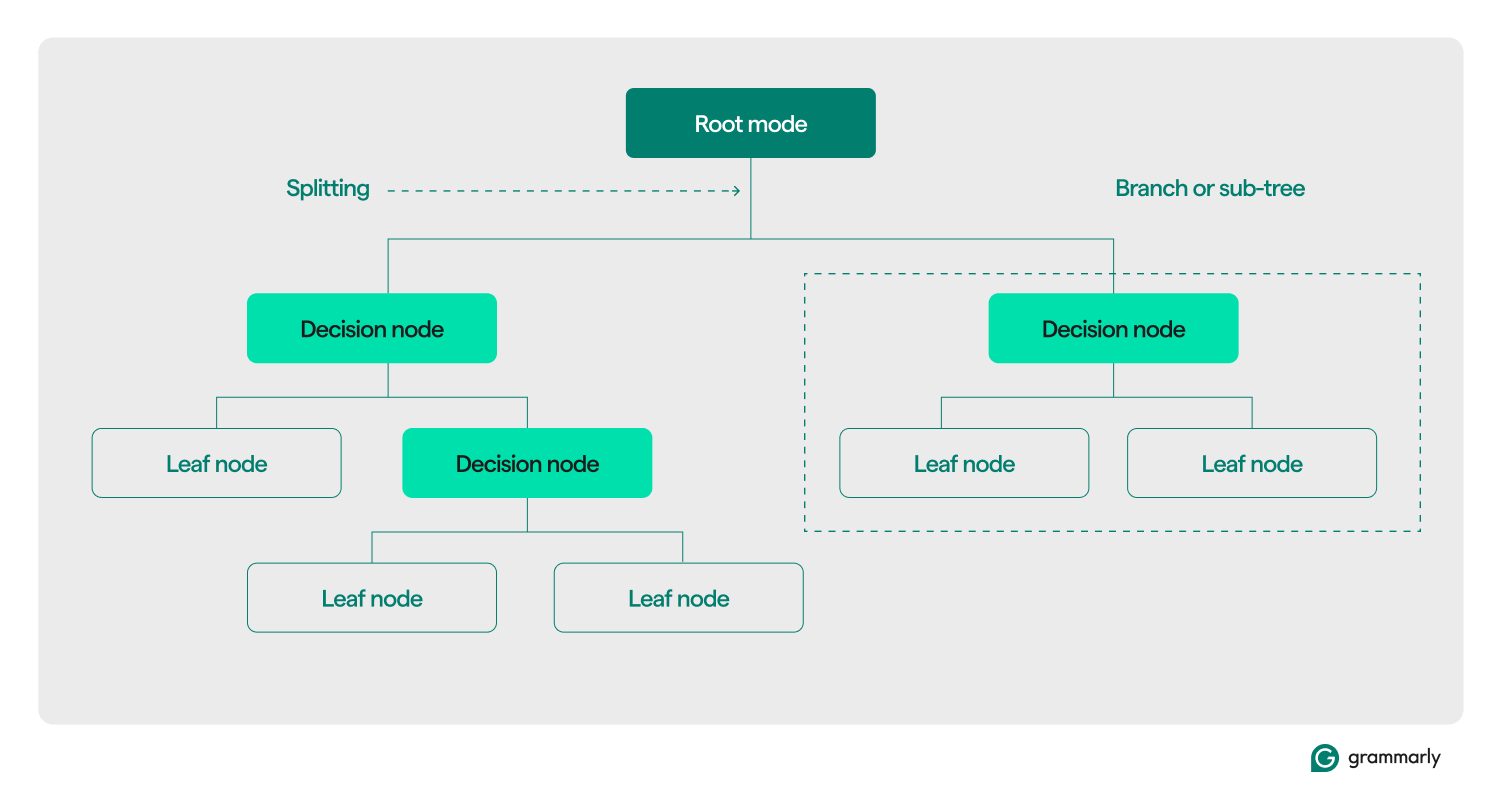
Terminologie de l'arbre de décision
Structurellement, un arbre de décision se compose généralement de trois composants : un nœud racine, des nœuds feuilles et des nœuds de décision (ou internes). Tout comme les organigrammes ou les arbres dans d'autres domaines, les décisions dans un arbre se déplacent généralement dans une direction (vers le bas ou vers le haut), en commençant par le nœud racine, en passant par certains nœuds de décision et en se terminant à un nœud feuille spécifique. Chaque nœud feuille connecte un sous-ensemble des données d'entraînement à une étiquette. L'arborescence est assemblée via un processus de formation et d'optimisation ML, et une fois construite, elle peut être appliquée à divers ensembles de données.
Voici une analyse plus approfondie du reste de la terminologie :
- Nœud racine :nœud contenant la première d’une série de questions que l’arbre de décision posera sur les données. Le nœud sera connecté à au moins un (mais généralement deux ou plus) nœuds de décision ou feuilles.
- Nœuds de décision (ou nœuds internes) :nœuds supplémentaires contenant des questions. Un nœud de décision contiendra exactement une question sur les données et dirigera le flux de données vers l'un de ses enfants en fonction de la réponse.
- Enfants : un ou plusieurs nœuds vers lesquels pointe une racine ou un nœud de décision. Ils représentent une liste des prochaines options que le processus décisionnel peut adopter lors de l'analyse des données.
- Nœuds feuilles (ou nœuds terminaux) :nœuds qui indiquent que le processus de décision est terminé. Une fois que le processus de décision atteint un nœud feuille, il renverra la ou les valeurs du nœud feuille comme sortie.
- Étiquette (classe, catégorie) :généralement, une chaîne associée par un nœud feuille à certaines données d'entraînement. Par exemple, une feuille peut associer l'étiquette « Client satisfait » à un ensemble de clients spécifiques avec lesquels l'algorithme de formation ML de l'arbre de décision a été présenté.
- Branche (ou sous-arbre) :Il s'agit de l'ensemble de nœuds constitué d'un nœud de décision en tout point de l'arbre, ainsi que de tous ses enfants et de leurs enfants, jusqu'aux nœuds feuilles.
- Élagage :opération d'optimisation généralement effectuée sur l'arborescence pour la rendre plus petite et l'aider à renvoyer les résultats plus rapidement. L'élagage fait généralement référence au « post-élagage », qui implique la suppression algorithmique de nœuds ou de branches une fois que le processus de formation ML a construit l'arborescence. Le « pré-élagage » fait référence à la définition d'une limite arbitraire sur la profondeur ou la taille d'un arbre de décision qui peut croître pendant la formation. Les deux processus imposent une complexité maximale à l’arbre de décision, généralement mesurée par sa profondeur ou sa hauteur maximale. Des optimisations moins courantes incluent la limitation du nombre maximum de nœuds de décision ou de nœuds feuilles.
- Fractionnement : l'étape de transformation principale effectuée sur un arbre de décision pendant la formation. Cela implique de diviser une racine ou un nœud de décision en deux ou plusieurs sous-nœuds.
- Classification :un algorithme de ML qui tente de déterminer laquelle (parmi une liste constante et discrète de classes, de catégories ou d'étiquettes) est la plus susceptible de s'appliquer à un élément de données. Il peut tenter de répondre à des questions telles que « Quel jour de la semaine est le meilleur pour réserver un vol ? » Plus d’informations sur la classification ci-dessous.
- Régression :algorithme de ML qui tente de prédire une valeur continue, qui n'a pas toujours de limites. Il pourrait tenter de répondre (ou prédire la réponse) à des questions telles que « Combien de personnes sont susceptibles de réserver un vol mardi prochain ? » Nous parlerons davantage des arbres de régression dans la section suivante.
Types d'arbres de décision
Les arbres de décision sont généralement regroupés en deux catégories : les arbres de classification et les arbres de régression. Un arbre spécifique peut être construit pour s'appliquer à la classification, à la régression ou aux deux cas d'utilisation. La plupart des arbres de décision modernes utilisent l'algorithme CART (Classification and Regression Trees), qui peut effectuer les deux types de tâches.
Arbres de classification
Les arbres de classification, le type d'arbre de décision le plus courant, tentent de résoudre un problème de classification. À partir d'une liste de réponses possibles à une question (souvent aussi simple que « oui » ou « non »), un arbre de classification choisira la plus probable après avoir posé quelques questions sur les données qui lui sont présentées. Ils sont généralement implémentés sous forme d’arbres binaires, ce qui signifie que chaque nœud de décision a exactement deux enfants.
Les arbres de classification peuvent tenter de répondre à des questions à choix multiples telles que « Ce client est-il satisfait ? » ou "Quel magasin physique est susceptible d'être visité par ce client ?" ou "Est-ce que demain sera un bon jour pour aller au golf ?"
Les deux méthodes les plus courantes pour mesurer la qualité d'un arbre de classification sont basées sur le gain d'information et l'entropie :
- Gain d'informations :l'efficacité d'un arbre est améliorée lorsqu'il pose moins de questions avant d'arriver à une réponse. Le gain d'informations mesure la « rapidité » avec laquelle un arbre peut obtenir une réponse en évaluant la quantité d'informations supplémentaires apprises sur un élément de données à chaque nœud de décision. Il évalue si les questions les plus importantes et les plus utiles sont posées en premier dans l'arbre.
- Entropie :la précision est cruciale pour les étiquettes des arbres de décision. Les métriques d'entropie mesurent cette précision en évaluant les étiquettes produites par l'arbre. Ils évaluent la fréquence à laquelle une donnée aléatoire se retrouve avec la mauvaise étiquette et la similarité entre toutes les données d'entraînement qui reçoivent la même étiquette.
Des mesures plus avancées de la qualité des arbres incluent l'indice de Gini,le rapport de gain,les évaluations du chi carréet diverses mesures de réduction de la variance.
Arbres de régression
Les arbres de régression sont généralement utilisés dans l'analyse de régression pour une analyse statistique avancée ou pour prédire des données à partir d'une plage continue et potentiellement illimitée. Étant donné une gamme d'options continues (par exemple, de zéro à l'infini sur l'échelle des nombres réels), l'arbre de régression tente de prédire la correspondance la plus probable pour une donnée donnée après avoir posé une série de questions. Chaque question réduit l’éventail potentiel de réponses. Par exemple, un arbre de régression peut être utilisé pour prédire les cotes de crédit, les revenus d'un secteur d'activité ou le nombre d'interactions sur une vidéo marketing.
La précision des arbres de régression est généralement évaluée à l'aide de mesures telles quel'erreur quadratique moyenneoul'erreur absolue moyenne, qui calculent la distance entre un ensemble spécifique de prédictions et les valeurs réelles.
Comment fonctionnent les arbres de décision
À titre d'exemple d'apprentissage supervisé, les arbres de décision s'appuient sur des données bien formatées pour la formation. Les données sources contiennent généralement une liste de valeurs que le modèle doit apprendre à prédire ou à classer. Chaque valeur doit avoir une étiquette attachée et une liste de fonctionnalités associées (propriétés que le modèle doit apprendre à associer à l'étiquette).

Construction ou formation
Au cours du processus de formation, les nœuds de décision dans l'arbre de décision sont divisés de manière récursive en nœuds plus spécifiques selon un ou plusieurs algorithmes de formation. Une description humaine du processus pourrait ressembler à ceci :
- Commencez par le nœud racineconnecté à l’ensemble de l’ensemble de formation.
- Diviser le nœud racine :à l'aide d'une approche statistique, attribuez une décision au nœud racine en fonction de l'une des caractéristiques des données et distribuez les données d'entraînement à au moins deux nœuds feuilles distincts, connectés en tant qu'enfants à la racine.
- Appliquez de manière récursive la deuxième étapeà chacun des enfants, en les transformant de nœuds feuilles en nœuds de décision. Arrêtez-vous lorsqu'une certaine limite est atteinte (par exemple, la hauteur/profondeur de l'arbre, une mesure de la qualité des enfants dans chaque feuille à chaque nœud, etc.) ou si vous êtes à court de données (c'est-à-dire que chaque feuille contient des données). points liés à exactement une étiquette).
La décision quant aux fonctionnalités à prendre en compte sur chaque nœud diffère pour les cas d'utilisation de classification, de régression et de classification et de régression combinées. Il existe de nombreux algorithmes parmi lesquels choisir pour chaque scénario. Les algorithmes typiques incluent :
- ID3 (classification) :optimise l'entropie et le gain d'informations
- C4.5 (classification) :Une version plus complexe d'ID3, ajoutant une normalisation au gain d'informations
- CART (classification/régression) : « Arbre de classification et de régression » ; un algorithme glouton qui optimise le minimum d'impuretés dans les ensembles de résultats
- CHAID (classification/régression) : « Détection automatique des interactions du Chi carré » ; utilise des mesures du chi carré au lieu de l'entropie et du gain d'informations
- MARS (classification/régression) : utilise des approximations linéaires par morceaux pour capturer les non-linéarités
Un régime de formation courant est la forêt aléatoire. Une forêt aléatoire, ou forêt de décisions aléatoires, est un système qui construit de nombreux arbres de décision liés. Plusieurs versions d'un arbre peuvent être entraînées en parallèle à l'aide de combinaisons d'algorithmes d'entraînement. Sur la base de diverses mesures de la qualité des arbres, un sous-ensemble de ces arbres sera utilisé pour produire une réponse. Pour les cas d'utilisation de classification, la classe sélectionnée par le plus grand nombre d'arbres est renvoyée comme réponse. Pour les cas d'utilisation de régression, la réponse est agrégée, généralement sous la forme d'une prédiction moyenne ou moyenne d'arbres individuels.
Évaluation et utilisation des arbres de décision
Une fois qu'un arbre de décision a été construit, il peut classer de nouvelles données ou prédire des valeurs pour un cas d'utilisation spécifique. Il est important de conserver des mesures sur les performances des arbres et de les utiliser pour évaluer la précision et la fréquence des erreurs. Si le modèle s'écarte trop des performances attendues, il est peut-être temps de le recycler sur de nouvelles données ou de trouver d'autres systèmes de ML à appliquer à ce cas d'utilisation.
Applications des arbres de décision en ML
Les arbres de décision ont un large éventail d’applications dans divers domaines. Voici quelques exemples pour illustrer leur polyvalence :
Prise de décision personnelle éclairée
Un individu peut conserver des données sur, par exemple, les restaurants qu'il a visités. Ils peuvent suivre tous les détails pertinents, tels que le temps de trajet, le temps d'attente, la cuisine proposée, les heures d'ouverture, la note moyenne des avis, le coût et la visite la plus récente, ainsi qu'un score de satisfaction pour la visite de l'individu dans ce restaurant. Un arbre de décision peut être formé sur ces données pour prédire le score de satisfaction probable pour un nouveau restaurant.
Calculer les probabilités autour du comportement des clients
Les systèmes de support client peuvent utiliser des arbres de décision pour prédire ou classer la satisfaction des clients. Un arbre de décision peut être formé pour prédire la satisfaction du client en fonction de divers facteurs, par exemple si le client a contacté l'assistance ou effectué un nouvel achat ou en fonction des actions effectuées dans une application. De plus, il peut intégrer les résultats d’enquêtes de satisfaction ou d’autres commentaires des clients.
Aider à éclairer les décisions commerciales
Pour certaines décisions commerciales riches en données historiques, un arbre de décision peut fournir des estimations ou des prédictions pour les prochaines étapes. Par exemple, une entreprise qui collecte des informations démographiques et géographiques sur ses clients peut former un arbre de décision pour évaluer quels nouveaux emplacements géographiques sont susceptibles d'être rentables ou devraient être évités. Les arbres de décision peuvent également aider à déterminer les meilleures limites de classification pour les données démographiques existantes, par exemple en identifiant les tranches d'âge à prendre en compte séparément lors du regroupement des clients.
Sélection de fonctionnalités pour le ML avancé et d'autres cas d'utilisation
Les structures des arbres de décision sont lisibles et compréhensibles par l’homme. Une fois l’arborescence construite, il est possible d’identifier quelles caractéristiques sont les plus pertinentes pour l’ensemble de données et dans quel ordre. Ces informations peuvent guider le développement de systèmes de ML ou d’algorithmes de décision plus complexes. Par exemple, si une entreprise apprend d'un arbre de décision que les clients donnent la priorité au coût d'un produit par-dessus tout, elle peut concentrer des systèmes de ML plus complexes sur ces informations ou ignorer les coûts lors de l'exploration de fonctionnalités plus nuancées.
Avantages des arbres de décision en ML
Les arbres de décision offrent plusieurs avantages significatifs qui en font un choix populaire dans les applications ML. Voici quelques avantages clés :
Rapide et facile à construire
Les arbres de décision sont l'un des algorithmes de ML les plus matures et les mieux compris. Ils ne dépendent pas de calculs particulièrement complexes et peuvent être construits rapidement et facilement. Tant que les informations requises sont facilement disponibles, un arbre de décision est une première étape facile à franchir lors de l'examen de solutions ML à un problème.
Facile à comprendre pour les humains
Le résultat des arbres de décision est particulièrement facile à lire et à interpréter. La représentation graphique d'un arbre de décision ne dépend pas d'une compréhension avancée des statistiques. En tant que tels, les arbres de décision et leurs représentations peuvent être utilisés pour interpréter, expliquer et étayer les résultats d’analyses plus complexes. Les arbres de décision sont excellents pour trouver et mettre en évidence certaines des propriétés de haut niveau d'un ensemble de données donné.
Traitement minimal des données requis
Les arbres de décision peuvent être construits tout aussi facilement à partir de données incomplètes ou de données contenant des valeurs aberrantes. Étant donné que les données sont dotées de fonctionnalités intéressantes, les algorithmes d'arbre de décision ont tendance à ne pas être autant affectés que les autres algorithmes de ML s'ils reçoivent des données qui n'ont pas été prétraitées.
Inconvénients des arbres de décision en ML
Si les arbres de décision offrent de nombreux avantages, ils présentent également plusieurs inconvénients :
Sensible au surapprentissage
Les arbres de décision sont sujets au surajustement, qui se produit lorsqu'un modèle apprend le bruit et les détails des données d'entraînement, réduisant ainsi ses performances sur les nouvelles données. Par exemple, si les données d’entraînement sont incomplètes ou éparses, de petites modifications dans les données peuvent produire des arborescences très différentes. Des techniques avancées comme l’élagage ou la définition d’une profondeur maximale peuvent améliorer le comportement des arbres. En pratique, les arbres de décision doivent souvent être mis à jour avec de nouvelles informations, ce qui peut modifier considérablement leur structure.
Mauvaise évolutivité
En plus de leur tendance au surajustement, les arbres de décision sont confrontés à des problèmes plus avancés qui nécessitent beaucoup plus de données. Par rapport à d’autres algorithmes, le temps de formation des arbres de décision augmente rapidement à mesure que les volumes de données augmentent. Pour les ensembles de données plus volumineux pouvant avoir des propriétés de haut niveau importantes à détecter, les arbres de décision ne conviennent pas parfaitement.
Pas aussi efficace pour la régression ou les cas d'utilisation continue
Les arbres de décision n'apprennent pas très bien les distributions de données complexes. Ils divisent l’espace des fonctionnalités selon des lignes faciles à comprendre mais mathématiquement simples. Pour les problèmes complexes où les valeurs aberrantes sont pertinentes, la régression et les cas d'utilisation continue, cela se traduit souvent par des performances bien inférieures à celles des autres modèles et techniques de ML.