
Qu’est-ce que le surapprentissage dans l’apprentissage automatique ?
Publié: 2024-10-15Le surajustement est un problème courant qui survient lors de la formation de modèles d’apprentissage automatique (ML). Cela peut avoir un impact négatif sur la capacité d'un modèle à généraliser au-delà des données d'entraînement, conduisant à des prédictions inexactes dans des scénarios réels. Dans cet article, nous explorerons ce qu'est le surapprentissage, comment il se produit, ses causes courantes et les moyens efficaces de le détecter et de le prévenir.
Table des matières
- Qu’est-ce que le surapprentissage ?
- Comment se produit le surapprentissage
- Surapprentissage ou sous-apprentissage
- Quelles sont les causes du surapprentissage ?
- Comment détecter le surapprentissage
- Comment éviter le surapprentissage
- Exemples de surapprentissage
Qu’est-ce que le surapprentissage ?
Le surajustement se produit lorsqu'un modèle d'apprentissage automatique apprend les modèles sous-jacents et le bruit dans les données d'entraînement, devenant ainsi trop spécialisé dans cet ensemble de données spécifique. Cette focalisation excessive sur les détails des données d'entraînement entraîne de mauvaises performances lorsque le modèle est appliqué à de nouvelles données invisibles, car il ne parvient pas à généraliser au-delà des données sur lesquelles il a été entraîné.
Comment se produit le surapprentissage ?
Le surajustement se produit lorsqu'un modèle apprend trop des détails spécifiques et du bruit des données d'entraînement, ce qui le rend trop sensible aux modèles qui ne sont pas significatifs pour la généralisation. Par exemple, considérons un modèle conçu pour prédire les performances des employés sur la base d'évaluations historiques. Si le modèle est trop adapté, il risque de trop se concentrer sur des détails spécifiques et non généralisables, tels que le style de notation unique d'un ancien manager ou des circonstances particulières au cours d'un cycle d'évaluation antérieur. Plutôt que d'apprendre les facteurs plus larges et significatifs qui contribuent à la performance, comme les compétences, l'expérience ou les résultats du projet, le modèle peut avoir du mal à appliquer ses connaissances aux nouveaux employés ou à faire évoluer les critères d'évaluation. Cela conduit à des prédictions moins précises lorsque le modèle est appliqué à des données différentes de l'ensemble d'apprentissage.
Surapprentissage ou sous-apprentissage
Contrairement au surapprentissage, le sous-apprentissage se produit lorsqu'un modèle est trop simple pour capturer les modèles sous-jacents dans les données. En conséquence, il fonctionne mal sur la formation ainsi que sur les nouvelles données, ne parvenant pas à faire des prédictions précises.
Pour visualiser la différence entre le sous-entraînement et le surentraînement, imaginez que nous essayons de prédire les performances sportives en fonction du niveau de stress d'une personne. Nous pouvons tracer les données et montrer trois modèles qui tentent de prédire cette relation :

1 Sous-ajustement :dans le premier exemple, le modèle utilise une ligne droite pour faire des prédictions, tandis que les données réelles suivent une courbe. Le modèle est trop simple et ne parvient pas à saisir la complexité de la relation entre le niveau de stress et la performance sportive. En conséquence, les prédictions sont pour la plupart inexactes, même pour les données d’entraînement. C’est un sous-ajustement.
2Ajustement optimal :Le deuxième exemple montre un modèle qui trouve le bon équilibre. Il capture la tendance sous-jacente des données sans la compliquer trop. Ce modèle se généralise bien aux nouvelles données, car il ne tente pas de s'adapter à toutes les petites variations des données d'entraînement, mais uniquement au modèle de base.
3Surajustement :dans le dernier exemple, le modèle utilise une courbe ondulée très complexe pour ajuster les données d'entraînement. Bien que cette courbe soit très précise pour les données d'entraînement, elle capture également le bruit aléatoire et les valeurs aberrantes qui ne représentent pas la relation réelle. Ce modèle est surajusté car il est si finement adapté aux données d'entraînement qu'il est susceptible de faire de mauvaises prédictions sur de nouvelles données invisibles.
Causes courantes de surapprentissage
Maintenant que nous savons ce qu'est le surapprentissage et pourquoi il se produit, explorons plus en détail quelques causes courantes :
- Données de formation insuffisantes
- Données inexactes, erronées ou non pertinentes
- Gros poids
- Surentraînement
- L'architecture du modèle est trop sophistiquée
Données de formation insuffisantes
Si votre ensemble de données d'entraînement est trop petit, il peut ne représenter que certains des scénarios que le modèle rencontrera dans le monde réel. Pendant la formation, le modèle peut bien s'adapter aux données. Cependant, vous pourriez constater des inexactitudes importantes une fois que vous le testerez sur d’autres données. Le petit ensemble de données limite la capacité du modèle à généraliser à des situations invisibles, ce qui le rend sujet au surajustement.
Données inexactes, erronées ou non pertinentes
Même si votre ensemble de données d'entraînement est volumineux, il peut contenir des erreurs. Ces erreurs peuvent provenir de diverses sources, telles que des participants fournissant de fausses informations dans des enquêtes ou des lectures de capteurs erronées. Si le modèle tente de tirer des leçons de ces inexactitudes, il s’adaptera à des modèles qui ne reflètent pas les véritables relations sous-jacentes, ce qui entraînera un surajustement.
Gros poids
Dans les modèles d'apprentissage automatique, les pondérations sont des valeurs numériques qui représentent l'importance accordée à des caractéristiques spécifiques des données lors de l'élaboration de prédictions. Lorsque les pondérations deviennent disproportionnées, le modèle peut être surajusté et devenir trop sensible à certaines caractéristiques, notamment au bruit dans les données. Cela se produit parce que le modèle devient trop dépendant de fonctionnalités particulières, ce qui nuit à sa capacité à généraliser à de nouvelles données.
Surentraînement
Pendant la formation, l'algorithme traite les données par lots, calcule l'erreur pour chaque lot et ajuste les pondérations du modèle pour améliorer sa précision.
Est-ce une bonne idée de continuer à s’entraîner le plus longtemps possible ? Pas vraiment! Un entraînement prolongé sur les mêmes données peut amener le modèle à mémoriser des points de données spécifiques, limitant sa capacité à généraliser à des données nouvelles ou invisibles, ce qui est l'essence même du surajustement. Ce type de surajustement peut être atténué en utilisant des techniques d'arrêt précoce ou en surveillant les performances du modèle sur un ensemble de validation pendant la formation. Nous verrons comment cela fonctionne plus loin dans l'article.
L'architecture du modèle est trop complexe
L'architecture d'un modèle d'apprentissage automatique fait référence à la manière dont ses couches et ses neurones sont structurés et à la manière dont ils interagissent pour traiter les informations.

Des architectures plus complexes peuvent capturer des modèles détaillés dans les données de formation. Cependant, cette complexité augmente la probabilité de surajustement, car le modèle peut également apprendre à capturer du bruit ou des détails non pertinents qui ne contribuent pas à des prédictions précises sur de nouvelles données. Simplifier l'architecture ou utiliser des techniques de régularisation peut aider à réduire le risque de surajustement.
Comment détecter le surapprentissage
Détecter le surapprentissage peut être délicat car tout peut sembler bien se passer pendant l'entraînement, même en cas de surapprentissage. Le taux de perte (ou d'erreur), qui mesure la fréquence des erreurs du modèle, continuera de diminuer, même dans un scénario de surapprentissage. Alors, comment pouvons-nous savoir si un surapprentissage s’est produit ? Nous avons besoin d'un test fiable.
Une méthode efficace consiste à utiliser une courbe d’apprentissage, un graphique qui suit une mesure appelée perte. La perte représente l’ampleur de l’erreur commise par le modèle. Cependant, nous ne suivons pas seulement la perte des données d’entraînement ; nous mesurons également la perte sur des données invisibles, appelées données de validation. C'est pourquoi la courbe d'apprentissage comporte généralement deux lignes : la perte de formation et la perte de validation.
Si la perte de formation continue de diminuer comme prévu, mais que la perte de validation augmente, cela suggère un surapprentissage. En d’autres termes, le modèle devient trop spécialisé dans les données d’entraînement et a du mal à se généraliser à de nouvelles données invisibles. La courbe d’apprentissage pourrait ressembler à ceci :
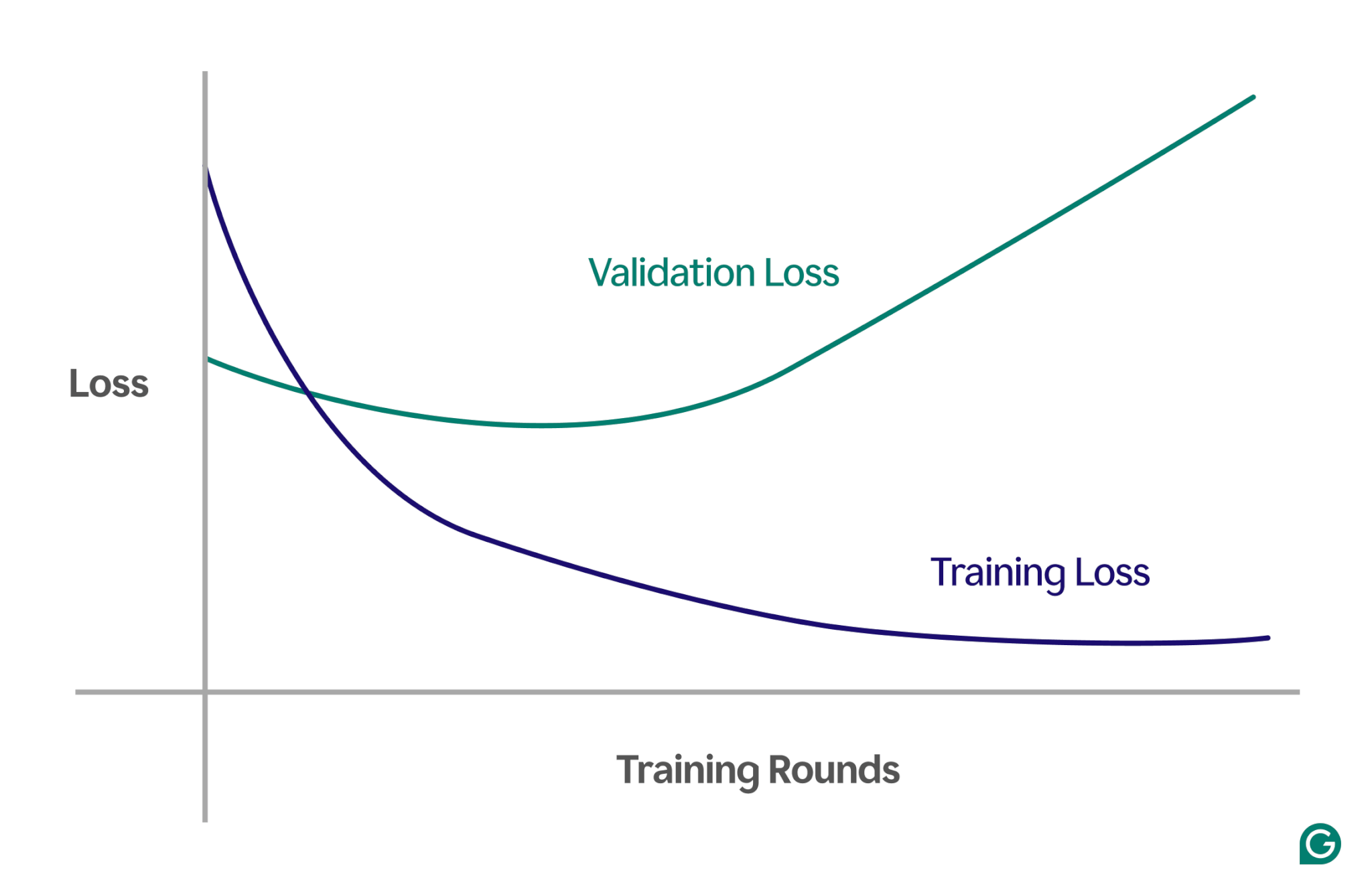
Dans ce scénario, même si le modèle s'améliore au cours de la formation, ses performances sont médiocres sur les données invisibles. Cela signifie probablement qu'un surapprentissage s'est produit.
Comment éviter le surapprentissage
Le surapprentissage peut être résolu à l’aide de plusieurs techniques. Voici quelques-unes des méthodes les plus courantes :
Réduire la taille du modèle
La plupart des architectures de modèles vous permettent d'ajuster le nombre de pondérations en modifiant le nombre de couches, la taille des couches et d'autres paramètres appelés hyperparamètres. Si la complexité du modèle entraîne un surajustement, réduire sa taille peut aider. Simplifier le modèle en réduisant le nombre de couches ou de neurones peut réduire le risque de surajustement, car le modèle aura moins de possibilités de mémoriser les données d'entraînement.
Régulariser le modèle
La régularisation implique de modifier le modèle pour décourager les poids importants. Une approche consiste à ajuster la fonction de perte afin qu'elle mesure l'erreur et inclue la taille des poids.
Avec la régularisation, l'algorithme d'entraînement minimise à la fois l'erreur et la taille des poids, réduisant ainsi la probabilité d'obtenir des poids importants à moins qu'ils n'apportent un net avantage au modèle. Cela permet d'éviter le surajustement en gardant le modèle plus généralisé.
Ajouter plus de données d'entraînement
L'augmentation de la taille de l'ensemble de données d'entraînement peut également aider à éviter le surapprentissage. Avec plus de données, le modèle est moins susceptible d'être influencé par le bruit ou les inexactitudes de l'ensemble de données. Exposer le modèle à des exemples plus variés le rendra moins enclin à mémoriser des points de données individuels et à apprendre des modèles plus larges.
Appliquer la réduction de dimensionnalité
Parfois, les données peuvent contenir des caractéristiques (ou dimensions) corrélées, ce qui signifie que plusieurs caractéristiques sont liées d'une manière ou d'une autre. Les modèles d'apprentissage automatique traitent les dimensions comme indépendantes. Par conséquent, si les caractéristiques sont corrélées, le modèle peut trop se concentrer sur elles, entraînant un surajustement.
Les techniques statistiques, telles que l'analyse en composantes principales (ACP), peuvent réduire ces corrélations. La PCA simplifie les données en réduisant le nombre de dimensions et en supprimant les corrélations, ce qui rend le surajustement moins probable. En se concentrant sur les fonctionnalités les plus pertinentes, le modèle parvient mieux à généraliser à de nouvelles données.
Exemples pratiques de surapprentissage
Pour mieux comprendre le surajustement, explorons quelques exemples pratiques dans différents domaines où le surajustement peut conduire à des résultats trompeurs.
Classement des images
Les classificateurs d'images sont conçus pour reconnaître les objets dans les images, par exemple si une image contient un oiseau ou un chien.
D'autres détails peuvent être en corrélation avec ce que vous essayez de détecter sur ces images. Par exemple, les photos de chiens peuvent souvent avoir de l'herbe en arrière-plan, tandis que les photos d'oiseaux peuvent souvent avoir un ciel ou la cime des arbres en arrière-plan.
Si toutes les images d'entraînement comportent ces détails d'arrière-plan cohérents, le modèle d'apprentissage automatique peut commencer à s'appuyer sur l'arrière-plan pour reconnaître l'animal, plutôt que de se concentrer sur les caractéristiques réelles de l'animal lui-même. Par conséquent, lorsqu'il est demandé au modèle de classer l'image d'un oiseau perché sur une pelouse, il peut le classer à tort comme un chien, car il s'agit d'un surajustement par rapport aux informations de base. Il s'agit d'un cas de surajustement des données d'entraînement.
Modélisation financière
Disons que vous négociez des actions pendant votre temps libre et que vous pensez qu'il est possible de prédire les mouvements de prix en fonction des tendances des recherches Google pour certains mots clés. Vous configurez un modèle d'apprentissage automatique à l'aide des données Google Trends pour des milliers de mots.
Comme il y a tellement de mots, certains montreront probablement une corrélation avec le cours de vos actions, par simple hasard. Le modèle peut surajuster ces corrélations fortuites, produisant ainsi de mauvaises prédictions sur les données futures, car les mots ne sont pas des prédicteurs pertinents des cours boursiers.
Lors de la création de modèles pour des applications financières, il est important de comprendre la base théorique des relations entre les données. Introduire de grands ensembles de données dans un modèle sans sélection minutieuse des fonctionnalités peut augmenter le risque de surajustement, en particulier lorsque le modèle identifie de fausses corrélations qui existent purement par hasard dans les données d'entraînement.
Superstition sportive
Bien qu’elles ne soient pas strictement liées à l’apprentissage automatique, les superstitions sportives peuvent illustrer le concept de surapprentissage, en particulier lorsque les résultats sont liés à des données qui n’ont logiquement aucun lien avec le résultat.
Lors des championnats de football de l'UEFA Euro 2008 et de la Coupe du Monde de la FIFA 2010, une pieuvre nommée Paul a été utilisée pour prédire l'issue des matchs impliquant l'Allemagne. Paul a obtenu quatre prédictions correctes sur six en 2008 et les sept en 2010.
Si l'on considère uniquement les « données d'entraînement » des prédictions passées de Paul, un modèle qui concorde avec les choix de Paul semblerait très bien prédire les résultats. Cependant, ce modèle ne serait pas bien généralisé aux jeux futurs, car les choix de la pieuvre ne sont pas des prédicteurs fiables des résultats des matchs.