
Forêts aléatoires dans l'apprentissage automatique: ce qu'ils sont et comment ils fonctionnent
Publié: 2025-02-03Les forêts aléatoires sont une technique puissante et polyvalente de l'apprentissage automatique (ML). Ce guide vous aidera à comprendre les forêts aléatoires, comment elles fonctionnent et leurs applications, avantages et défis.
Table des matières
- Qu'est-ce qu'une forêt aléatoire?
- Arbres de décision contre Forest aléatoire: Quelle est la différence?
- Comment fonctionnent les forêts aléatoires
- Applications pratiques des forêts aléatoires
- Avantages des forêts aléatoires
- Inconvénients des forêts aléatoires
Qu'est-ce qu'une forêt aléatoire?
Une forêt aléatoire est un algorithme d'apprentissage automatique qui utilise plusieurs arbres de décision pour faire des prédictions. Il s'agit d'une méthode d'apprentissage supervisée conçue à la fois pour les tâches de classification et de régression. En combinant les résultats de nombreux arbres, une forêt aléatoire améliore la précision, réduit le sur-ajustement et fournit des prédictions plus stables par rapport à un seul arbre de décision.
Arbres de décision contre Forest aléatoire: Quelle est la différence?
Bien que les forêts aléatoires soient construites sur des arbres de décision, les deux algorithmes diffèrent considérablement par la structure et l'application:
Arbres de décision
Un arbre de décision se compose de trois composants principaux: un nœud racine, des nœuds de décision (nœuds internes) et des nœuds de feuilles. Comme un organigramme, le processus de décision commence au nœud racine, circule à travers les nœuds de décision en fonction des conditions et se termine à un nœud feuille représentant le résultat. Bien que les arbres de décision soient faciles à interpréter et à conceptualiser, ils sont également sujets à un sur-ajustement, en particulier avec des ensembles de données complexes ou bruyants.
Forêts aléatoires
Une forêt aléatoire est un ensemble d'arbres de décision qui combinent leurs résultats pour des prédictions améliorées. Chaque arbre est formé sur un échantillon de bootstrap unique (un sous-ensemble échantillonné au hasard de l'ensemble de données d'origine par le remplacement) et évalue les divisions de décision à l'aide d'un sous-ensemble de fonctionnalités sélectionné au hasard à chaque nœud. Cette approche, connue sous le nom de traits, introduit la diversité parmi les arbres. En agrégeant les prédictions - en utilisant la majorité de vote pour la classification ou les moyennes de régression - les forêts aléatoires produisent des résultats plus précis et stables que tout arbre de décision dans l'ensemble.
Comment fonctionnent les forêts aléatoires
Les forêts aléatoires fonctionnent en combinant plusieurs arbres de décision pour créer un modèle de prédiction robuste et précis.
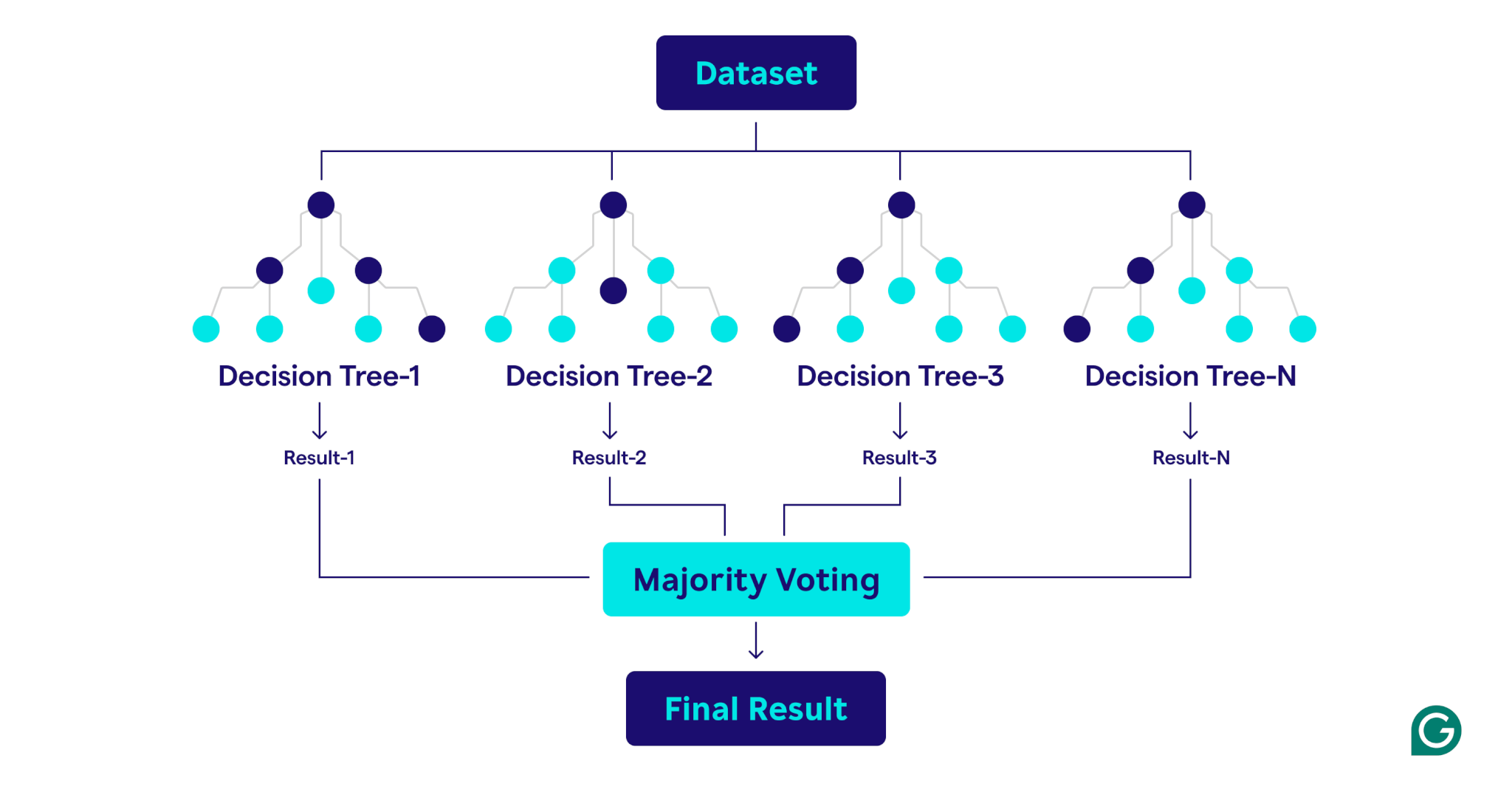
Voici une explication étape par étape du processus:
1. Établir des hyperparamètres
La première étape consiste à définir les hyperparamètres du modèle. Ceux-ci incluent:
- Nombre d'arbres:détermine la taille de la forêt
- Profondeur maximale pour chaque arbre:contrôle la profondeur de chaque arbre de décision
- Nombre de fonctionnalités considérées à chaque répartition:limite le nombre de fonctionnalités évaluées lors de la création de divisions
Ces hyperparamètres permettent de régler la complexité du modèle et d'optimiser les performances pour des ensembles de données spécifiques.
2. Échantillonnage de bootstrap
Une fois les hyperparamètres définis, le processus de formation commence par l'échantillonnage de bootstrap. Cela implique:
- Les points de données de l'ensemble de données d'origine sont sélectionnés au hasard pour créer des ensembles de données de formation (échantillons bootstrap) pour chaque arborescence de décision.
- Chaque échantillon de bootstrap est généralement environ les deux tiers de la taille de l'ensemble de données d'origine, avec certains points de données répétés et d'autres exclus.
- Le tiers restant des points de données, non inclus dans l'échantillon de bootstrap, est appelé les données hors sac (OOB).
3. Construire des arbres de décision
Chaque arbre de décision de la forêt aléatoire est formé sur son échantillon de bootstrap correspondant en utilisant un processus unique:
- Esachage des fonctionnalités:À chaque scission, un sous-ensemble aléatoire de fonctionnalités est sélectionné, garantissant la diversité parmi les arbres.
- Clissage du nœud:la meilleure fonctionnalité du sous-ensemble est utilisée pour diviser le nœud:
- Pour les tâches de classification, des critères comme l'impureté Gini (une mesure de la fréquence à laquelle un élément choisi au hasard serait incorrectement classé s'il était étiqueté au hasard en fonction de la distribution des étiquettes de classe dans le nœud) mesurent que la division sépare les classes.
- Pour les tâches de régression, des techniques telles que la réduction de la variance (une méthode qui mesure la division d'un nœud diminue la variance des valeurs cibles, conduisant à des prédictions plus précises) évaluer dans quelle mesure la division réduit l'erreur de prédiction.
- L'arbre se développe récursivement jusqu'à ce qu'il remplisse les conditions d'arrêt, telles qu'une profondeur maximale ou un nombre minimum de points de données par nœud.
4. Évaluation des performances
Au fur et à mesure que chaque arbre est construite, les performances du modèle sont estimées à l'aide des données OOB:
- L'estimation des erreurs OOB fournit une mesure impartiale des performances du modèle, éliminant la nécessité d'un ensemble de données de validation séparé.
- En agrégeant les prédictions de tous les arbres, la forêt aléatoire permet une meilleure précision et réduit le sur-ajustement par rapport aux arbres de décision individuels.

Applications pratiques des forêts aléatoires
Comme les arbres de décision sur lesquels ils sont construits, des forêts aléatoires peuvent être appliquées aux problèmes de classification et de régression dans une grande variété de secteurs, tels que les soins de santé et la finance.
Classifier les conditions des patients
Dans les soins de santé, les forêts aléatoires sont utilisées pour classer les conditions des patients en fonction des informations telles que les antécédents médicaux, la démographie et les résultats des tests. Par exemple, pour prédire si un patient est susceptible de développer une condition spécifique comme le diabète, chaque arbre de décision classe le patient comme à risque ou non sur la base de données pertinentes, et la forêt aléatoire fait la détermination finale sur la base d'un vote majoritaire. Cette approche signifie que les forêts aléatoires sont particulièrement bien adaptées aux ensembles de données complexes riches en fonctionnalités trouvés dans les soins de santé.
Prédire les défauts de prêt
Les banques et les grandes institutions financières utilisent largement les forêts aléatoires pour déterminer l'admissibilité au prêt et mieux comprendre les risques. Le modèle utilise des facteurs tels que le revenu et la cote de crédit pour déterminer le risque. Parce que le risque est mesuré comme une valeur numérique continue, la forêt aléatoire effectue une régression au lieu de la classification. Chaque arbre de décision, formé sur des échantillons de bootstrap légèrement différents, produit un score de risque prévu. Ensuite, la forêt aléatoire fait en moyenne toutes les prédictions individuelles, ce qui entraîne une estimation de risque holistique robuste.
Prédire la perte du client
Dans le marketing, des forêts aléatoires sont souvent utilisées pour prédire la probabilité qu'un client interrompre l'utilisation d'un produit ou d'un service. Cela implique d'analyser les modèles de comportement des clients, tels que la fréquence d'achat et les interactions avec le service client. En identifiant ces modèles, les forêts aléatoires peuvent classer les clients à risque de partir. Avec ces informations, les entreprises peuvent prendre des étapes proactives et axées sur les données pour conserver les clients, tels que l'offre de programmes de fidélité ou de promotions ciblées.
Prédire les prix de l'immobilier
Des forêts aléatoires peuvent être utilisées pour prédire les prix de l'immobilier, qui est une tâche de régression. Pour faire la prédiction, la forêt aléatoire utilise des données historiques qui comprennent des facteurs tels que l'emplacement géographique, la superficie en pieds carrés et les ventes récentes dans la région. Le processus de moyenne de la forêt aléatoire se traduit par une prédiction de prix plus fiable et stable que celle d'un arbre de décision individuel, qui est utile sur les marchés immobiliers très volatils.
Avantages des forêts aléatoires
Les forêts aléatoires offrent de nombreux avantages, notamment la précision, la robustesse, la polyvalence et la capacité d'estimer l'importance des caractéristiques.
Précision et robustesse
Les forêts aléatoires sont plus précises et robustes que les arbres de décision individuels. Ceci est réalisé en combinant les sorties de plusieurs arbres de décision formés sur différents échantillons de bootstrap de l'ensemble de données d'origine. La diversité qui en résulte signifie que les forêts aléatoires sont moins sujettes à un sur-ajustement que les arbres de décision individuels. Cette approche d'ensemble signifie que les forêts aléatoires sont bonnes pour gérer des données bruyantes, même dans des ensembles de données complexes.
Versatilité
Comme les arbres de décision sur lesquels ils sont construits, les forêts aléatoires sont très polyvalentes. Ils peuvent gérer à la fois les tâches de régression et de classification, ce qui les rend applicables à un large éventail de problèmes. Les forêts aléatoires fonctionnent également bien avec de grands ensembles de données riches en fonctionnalités et peuvent gérer à la fois des données numériques et catégoriques.
Importance importante
Les forêts aléatoires ont une capacité intégrée à estimer l'importance de caractéristiques particulières. Dans le cadre du processus d'entraînement, les forêts aléatoires produisent un score qui mesure combien la précision du modèle change si une caractéristique particulière est supprimée. En faisant la moyenne des scores pour chaque fonctionnalité, les forêts aléatoires peuvent fournir une mesure quantifiable de l'importance des caractéristiques. Des caractéristiques moins importantes peuvent ensuite être retirées pour créer des arbres et des forêts plus efficaces.
Inconvénients des forêts aléatoires
Bien que les forêts aléatoires offrent de nombreux avantages, ils sont plus difficiles à interpréter et plus coûteux à former qu'un seul arbre de décision, et ils peuvent émettre des prédictions plus lentement que les autres modèles.
Complexité
Alors que les forêts aléatoires et les arbres de décision ont beaucoup en commun, les forêts aléatoires sont plus difficiles à interpréter et à visualiser. Cette complexité survient parce que les forêts aléatoires utilisent des centaines ou des milliers d'arbres de décision. La nature de la «boîte noire» des forêts aléatoires est un grave inconvénient lorsque l'explication du modèle est une exigence.
Coût de calcul
La formation de centaines ou de milliers d'arbres de décision nécessite beaucoup plus de puissance de traitement et de mémoire que de former un seul arbre de décision. Lorsque de grands ensembles de données sont impliqués, le coût de calcul peut être encore plus élevé. Cette grande exigence de ressources peut entraîner une augmentation des coûts monétaires et des temps de formation plus longs. En conséquence, les forêts aléatoires peuvent ne pas être pratiques dans des scénarios comme le calcul Edge, où la puissance de calcul et la mémoire sont rares. Cependant, les forêts aléatoires peuvent être parallélisées, ce qui peut aider à réduire le coût de calcul.
Temps de prédiction plus lent
Le processus de prédiction d'une forêt aléatoire consiste à traverser chaque arbre dans la forêt et à agréger leurs résultats, ce qui est intrinsèquement plus lent que d'utiliser un seul modèle. Ce processus peut entraîner des temps de prédiction plus lents que des modèles plus simples comme la régression logistique ou les réseaux de neurones, en particulier pour les grandes forêts contenant des arbres profonds. Pour les cas d'utilisation où le temps est de l'essence, tels que le trading haute fréquence ou les véhicules autonomes, ce retard peut être prohibitif.