
Qu’est-ce que le sous-apprentissage dans l’apprentissage automatique ?
Publié: 2024-10-16Le sous-ajustement est un problème courant rencontré lors du développement de modèles d’apprentissage automatique (ML). Cela se produit lorsqu'un modèle est incapable d'apprendre efficacement à partir des données d'entraînement, ce qui entraîne des performances médiocres. Dans cet article, nous explorerons ce qu'est le sous-apprentissage, comment il se produit et les stratégies pour l'éviter.
Table des matières
- Qu’est-ce que le sous-apprentissage ?
- Comment se produit le sous-apprentissage
- Sous-apprentissage ou surapprentissage
- Causes courantes de sous-ajustement
- Comment détecter le sous-apprentissage
- Techniques pour prévenir le sous-ajustement
- Exemples pratiques de sous-ajustement
Qu’est-ce que le sous-apprentissage ?
Le sous-ajustement se produit lorsqu'un modèle d'apprentissage automatique ne parvient pas à capturer les modèles sous-jacents dans les données d'entraînement, ce qui entraîne de mauvaises performances sur les données d'entraînement et de test. Lorsque cela se produit, cela signifie que le modèle est trop simple et ne représente pas correctement les relations les plus importantes des données. En conséquence, le modèle a du mal à faire des prédictions précises sur toutes les données, qu’il s’agisse des données vues pendant l’entraînement ou de toute nouvelle donnée invisible.
Comment se produit le sous-apprentissage ?
Le sous-ajustement se produit lorsqu'un algorithme d'apprentissage automatique produit un modèle qui ne parvient pas à capturer les propriétés les plus importantes des données d'entraînement ; les modèles qui échouent de cette manière sont considérés comme trop simples. Par exemple, imaginez que vous utilisez la régression linéaire pour prédire les ventes en fonction des dépenses marketing, des données démographiques des clients et de la saisonnalité. La régression linéaire suppose que la relation entre ces facteurs et les ventes peuvent être représentées par un mélange de lignes droites.
Bien que la relation réelle entre les dépenses marketing et les ventes puisse être courbée ou inclure de multiples interactions (par exemple, les ventes augmentent rapidement au début, puis plafonnent), le modèle linéaire simplifiera à l'extrême en traçant une ligne droite. Cette simplification passe à côté de nuances importantes, ce qui conduit à de mauvaises prévisions et performances globales.
Ce problème est courant dans de nombreux modèles de ML où un biais élevé (hypothèses rigides) empêche le modèle d'apprendre des modèles essentiels, ce qui entraîne de mauvaises performances sur les données d'entraînement et de test. Le sous-ajustement est généralement observé lorsque le modèle est trop simple pour représenter la véritable complexité des données.
Sous-apprentissage ou surapprentissage
En ML, le sous-apprentissage et le surapprentissage sont des problèmes courants qui peuvent affecter négativement la capacité d'un modèle à faire des prédictions précises. Comprendre la différence entre les deux est crucial pour créer des modèles qui se généralisent bien aux nouvelles données.
- Le sous-ajustementse produit lorsqu'un modèle est trop simple et ne parvient pas à capturer les modèles clés des données. Cela conduit à des prédictions inexactes à la fois pour les données d'entraînement et les nouvelles données.
- Le surajustementse produit lorsqu'un modèle devient trop complexe, s'adaptant non seulement aux véritables modèles, mais également au bruit présent dans les données d'entraînement. Cela entraîne de bonnes performances du modèle sur l'ensemble d'entraînement, mais de mauvaises performances sur de nouvelles données invisibles.
Pour mieux illustrer ces concepts, considérons un modèle qui prédit la performance sportive en fonction des niveaux de stress. Les points bleus dans le graphique représentent les points de données de l'ensemble d'entraînement, tandis que les lignes montrent les prédictions du modèle après avoir été entraîné sur ces données. 
1 Sous-ajustement :dans ce cas, le modèle utilise une simple ligne droite pour prédire les performances, même si la relation réelle est courbe. Étant donné que la courbe ne correspond pas bien aux données, le modèle est trop simple et ne parvient pas à capturer des modèles importants, ce qui entraîne de mauvaises prévisions. Il s'agit d'un sous-ajustement, lorsque le modèle ne parvient pas à apprendre les propriétés les plus utiles des données.
2 Ajustement optimal :ici, le modèle s'adapte de manière suffisamment appropriée à la courbe des données. Il capture la tendance sous-jacente sans être trop sensible à des points de données ou à du bruit spécifiques. Il s’agit du scénario souhaité, dans lequel le modèle généralise raisonnablement bien et peut faire des prédictions précises sur de nouvelles données similaires. Cependant, la généralisation peut encore s’avérer difficile face à des ensembles de données très différents ou plus complexes.
3 Surajustement :dans le scénario de surajustement, le modèle suit de près presque tous les points de données, y compris le bruit et les fluctuations aléatoires des données d'entraînement. Bien que le modèle fonctionne extrêmement bien sur l'ensemble d'entraînement, il est trop spécifique aux données d'entraînement et sera donc moins efficace lors de la prédiction de nouvelles données. Il a du mal à se généraliser et fera probablement des prédictions inexactes lorsqu’il sera appliqué à des scénarios invisibles.
Causes courantes de sous-ajustement
Il existe de nombreuses causes potentielles de sous-apprentissage. Les quatre plus courants sont :
- L'architecture du modèle est trop simple.
- Mauvaise sélection de fonctionnalités
- Données de formation insuffisantes
- Pas assez de formation
Examinons-les un peu plus pour les comprendre.
L'architecture du modèle est trop simple
L'architecture du modèle fait référence à la combinaison de l'algorithme utilisé pour entraîner le modèle et de la structure du modèle. Si l'architecture est trop simple, elle pourrait avoir du mal à capturer les propriétés de haut niveau des données d'entraînement, ce qui entraînerait des prédictions inexactes.
Par exemple, si un modèle tente d'utiliser une seule ligne droite pour modéliser des données qui suivent un motif courbe, il sera systématiquement sous-ajusté. En effet, une ligne droite ne peut pas représenter avec précision la relation de haut niveau dans les données courbes, ce qui rend l'architecture du modèle inadaptée à la tâche.
Mauvaise sélection de fonctionnalités
La sélection des fonctionnalités implique de choisir les bonnes variables pour le modèle ML pendant la formation. Par exemple, vous pouvez demander à un algorithme ML d'examiner l'année de naissance, la couleur des yeux, l'âge ou les trois d'une personne pour prédire si une personne appuiera sur le bouton d'achat sur un site Web de commerce électronique.
S'il y a trop de fonctionnalités ou si les fonctionnalités sélectionnées ne sont pas fortement corrélées avec la variable cible, le modèle ne disposera pas de suffisamment d'informations pertinentes pour faire des prédictions précises. La couleur des yeux peut ne pas avoir d’importance pour la conversion, et l’âge capture une grande partie des mêmes informations que l’année de naissance.
Données de formation insuffisantes
Lorsqu’il y a trop peu de points de données, le modèle peut être sous-adapté car les données ne capturent pas les propriétés les plus importantes du problème. Cela peut se produire soit en raison d'un manque de données, soit en raison d'un biais d'échantillonnage, dans lequel certaines sources de données sont exclues ou sous-représentées, empêchant le modèle d'apprendre des modèles importants.

Pas assez de formation
La formation d'un modèle ML implique d'ajuster ses paramètres internes (pondérations) en fonction de la différence entre ses prédictions et les résultats réels. Plus le modèle subit d’itérations de formation, mieux il peut s’ajuster aux données. Si le modèle est entraîné avec trop peu d’itérations, il risque de ne pas avoir suffisamment d’opportunités pour apprendre des données, ce qui entraînera un sous-ajustement.
Comment détecter le sous-apprentissage
Une façon de détecter le sous-ajustement consiste à analyser les courbes d'apprentissage, qui représentent les performances du modèle (généralement une perte ou une erreur) en fonction du nombre d'itérations d'entraînement. Une courbe d'apprentissage montre comment le modèle s'améliore (ou ne parvient pas à s'améliorer) au fil du temps sur les ensembles de données de formation et de validation.
La perte est l'ampleur de l'erreur du modèle pour un ensemble de données donné. La perte de formation mesure cela pour les données de formation et la perte de validation pour les données de validation. Les données de validation sont un ensemble de données distinct utilisé pour tester les performances du modèle. Il est généralement produit en divisant aléatoirement un ensemble de données plus important en données de formation et de validation.
En cas de sous-ajustement, vous remarquerez les modèles clés suivants :
- Perte d'entraînement élevée :si la perte d'entraînement du modèle reste élevée et stable au début du processus, cela suggère que le modèle n'apprend pas à partir des données d'entraînement. C’est un signe clair de sous-ajustement, car le modèle est trop simple pour s’adapter à la complexité des données.
- Perte de formation et de validation similaire :si la perte de formation et de validation est élevée et reste proche l'une de l'autre tout au long du processus de formation, cela signifie que le modèle est sous-performant sur les deux ensembles de données. Cela indique que le modèle ne capture pas suffisamment d’informations à partir des données pour faire des prédictions précises, ce qui indique un sous-ajustement.
Vous trouverez ci-dessous un exemple de graphique illustrant les courbes d'apprentissage dans un scénario de sous-apprentissage :
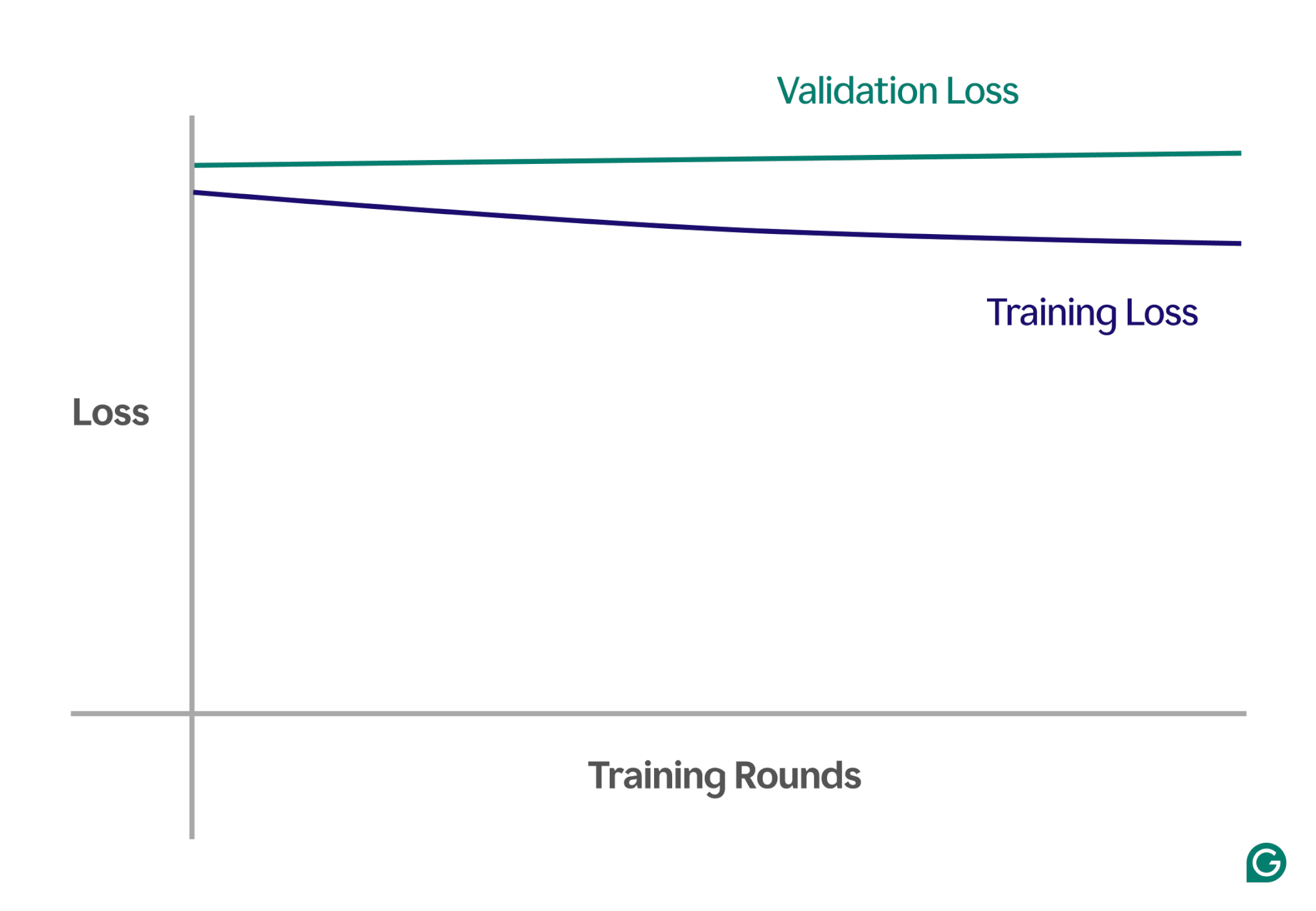
Dans cette représentation visuelle, le sous-ajustement est facile à repérer :
- Dans un modèle bien ajusté, la perte de formation diminue considérablement tandis que la perte de validation suit un schéma similaire, pour finalement se stabiliser.
- Dans un modèle sous-ajusté, la perte de formation et de validation commence à un niveau élevé et reste élevée, sans aucune amélioration significative.
En observant ces tendances, vous pouvez rapidement identifier si le modèle est trop simpliste et nécessite des ajustements pour augmenter sa complexité.
Techniques pour prévenir le sous-ajustement
Si vous rencontrez un sous-ajustement, vous pouvez utiliser plusieurs stratégies pour améliorer les performances du modèle :
- Plus de données d'entraînement :si possible, obtenez des données d'entraînement supplémentaires. Plus de données donnent au modèle des opportunités supplémentaires d'apprendre des modèles, à condition que les données soient de haute qualité et pertinentes pour le problème en question.
- Élargir la sélection de fonctionnalités :ajoutez au modèle les fonctionnalités les plus pertinentes. Choisissez des caractéristiques qui ont une relation étroite avec la variable cible, ce qui donne au modèle une meilleure chance de capturer des modèles importants qui étaient auparavant manqués.
- Augmenter la puissance architecturale :dans les modèles basés sur des réseaux de neurones, vous pouvez ajuster la structure architecturale en modifiant le nombre de poids, de couches ou d'autres hyperparamètres. Cela peut permettre au modèle d'être plus flexible et de trouver plus facilement les modèles de haut niveau dans les données.
- Choisissez un modèle différent :parfois, même après avoir réglé les hyperparamètres, un modèle spécifique peut ne pas être bien adapté à la tâche. Tester plusieurs algorithmes de modèle peut aider à trouver un modèle plus approprié et à améliorer les performances.
Exemples pratiques de sous-ajustement
Pour illustrer les effets du sous-ajustement, examinons des exemples concrets dans divers domaines où les modèles ne parviennent pas à capturer la complexité des données, ce qui conduit à des prédictions inexactes.
Prédire les prix de l'immobilier
Pour prédire avec précision le prix d’une maison, vous devez prendre en compte de nombreux facteurs, notamment l’emplacement, la taille, le type de maison, l’état et le nombre de chambres.
Si vous utilisez trop peu de fonctionnalités, comme uniquement la taille et le type de la maison, le modèle n'aura pas accès aux informations critiques. Par exemple, le modèle pourrait supposer qu’un petit studio est peu coûteux, sans savoir qu’il est situé à Mayfair, à Londres, une zone où les prix de l’immobilier sont élevés. Cela conduit à de mauvaises prévisions.
Pour résoudre ce problème, les data scientists doivent garantir une sélection appropriée des fonctionnalités. Cela implique d'inclure toutes les fonctionnalités pertinentes, à l'exclusion de celles qui ne le sont pas, et d'utiliser des données d'entraînement précises.
Reconnaissance vocale
La technologie de reconnaissance vocale est devenue de plus en plus courante dans la vie quotidienne. Par exemple, les assistants pour smartphone, les lignes d’assistance téléphonique et les technologies d’assistance pour les personnes handicapées utilisent tous la reconnaissance vocale. Lors de la formation de ces modèles, les données provenant d'échantillons de parole et leurs interprétations correctes sont utilisées.
Pour reconnaître la parole, le modèle convertit les ondes sonores capturées par un microphone en données. Si nous simplifions cela en fournissant uniquement la fréquence et le volume dominants de la voix à des intervalles spécifiques, nous réduisons la quantité de données que le modèle doit traiter.
Cependant, cette approche supprime les informations essentielles nécessaires pour bien comprendre le discours. Les données deviennent trop simplistes pour capturer la complexité de la parole humaine, comme les variations de ton, de hauteur et d'accent.
En conséquence, le modèle sera sous-adapté, ayant du mal à reconnaître même les commandes de mots de base, sans parler des phrases complètes. Même si le modèle est suffisamment complexe, le manque de données complètes conduit à un sous-ajustement.
Classement des images
Un classificateur d'images est conçu pour prendre une image en entrée et générer un mot pour la décrire. Supposons que vous construisiez un modèle pour détecter si une image contient une balle ou non. Vous entraînez le modèle à l'aide d'images étiquetées de balles et d'autres objets.
Si vous utilisez par erreur un simple réseau neuronal à deux couches au lieu d'un modèle plus approprié comme un réseau neuronal convolutif (CNN), le modèle aura des difficultés. Le réseau à deux couches aplatit l’image en une seule couche, perdant ainsi des informations spatiales importantes. De plus, avec seulement deux couches, le modèle n’a pas la capacité d’identifier des fonctionnalités complexes.
Cela conduit à un sous-ajustement, car le modèle ne parviendra pas à faire des prédictions précises, même sur les données d'entraînement. Les CNN résolvent ce problème en préservant la structure spatiale des images et en utilisant des couches convolutives avec des filtres qui apprennent automatiquement à détecter des caractéristiques importantes telles que les bords et les formes dans les premières couches et les objets plus complexes dans les couches ultérieures.