
Dasar-dasar Jaringan Adversarial Generatif: Yang Perlu Anda Ketahui
Diterbitkan: 2024-10-08Jaringan permusuhan generatif (GAN) adalah alat kecerdasan buatan (AI) yang kuat dengan banyak aplikasi dalam pembelajaran mesin (ML). Panduan ini membahas GAN, cara kerjanya, aplikasinya, serta kelebihan dan kekurangannya.
Daftar isi
- Apa itu GAN?
- GAN vs. CNN
- Cara kerja GAN
- Jenis GAN
- Penerapan GAN
- Keuntungan GAN
- Kekurangan GAN
Apa itu jaringan permusuhan generatif?
Jaringan permusuhan generatif, atau GAN, adalah jenis model pembelajaran mendalam yang biasanya digunakan dalam pembelajaran mesin tanpa pengawasan tetapi juga dapat disesuaikan untuk pembelajaran semi-diawasi dan diawasi. GAN digunakan untuk menghasilkan data berkualitas tinggi yang serupa dengan kumpulan data pelatihan. Sebagai bagian dari AI generatif, GAN terdiri dari dua submodel: generator dan diskriminator.
1 Generator:Generator membuat data sintetis.
2 Diskriminator:Diskriminator mengevaluasi keluaran generator, membedakan antara data nyata dari set pelatihan dan data sintetis yang dibuat oleh generator.
Kedua model terlibat dalam kompetisi: generator mencoba mengelabui diskriminator agar mengklasifikasikan data yang dihasilkan sebagai data nyata, sementara diskriminator terus meningkatkan kemampuannya untuk mendeteksi data sintetis. Proses permusuhan ini berlanjut hingga diskriminator tidak dapat lagi membedakan antara data nyata dan data yang dihasilkan. Pada titik ini, GAN mampu menghasilkan gambar, video, dan jenis data lainnya yang realistis.
GAN vs. CNN
GAN dan jaringan saraf konvolusional (CNN) adalah jenis jaringan saraf canggih yang digunakan dalam pembelajaran mendalam, namun keduanya berbeda secara signifikan dalam hal kasus penggunaan dan arsitektur.
Kasus penggunaan
- GAN:Mengkhususkan diri dalam menghasilkan data sintetis realistis berdasarkan data pelatihan. Hal ini membuat GAN sangat cocok untuk tugas-tugas seperti pembuatan gambar, transfer gaya gambar, dan augmentasi data. GAN tidak diawasi, artinya GAN dapat diterapkan pada skenario ketika data berlabel langka atau tidak tersedia.
- CNN:Terutama digunakan untuk tugas klasifikasi data terstruktur, seperti analisis sentimen, kategorisasi topik, dan terjemahan bahasa. Karena kemampuan klasifikasinya, CNN juga berfungsi sebagai diskriminator yang baik di GAN. Namun, karena CNN memerlukan data pelatihan yang terstruktur dan dianotasi oleh manusia, CNN terbatas pada skenario pembelajaran yang diawasi.
Arsitektur
- GAN:Terdiri dari dua model—diskriminator dan generator—yang terlibat dalam proses kompetitif. Generator menciptakan gambar, sementara diskriminator mengevaluasinya, mendorong generator untuk menghasilkan gambar yang semakin realistis seiring berjalannya waktu.
- CNN:Memanfaatkan lapisan operasi konvolusional dan pengumpulan untuk mengekstrak dan menganalisis fitur dari gambar. Arsitektur model tunggal ini berfokus pada pengenalan pola dan struktur dalam data.
Secara keseluruhan, meskipun CNN berfokus pada analisis data terstruktur yang ada, GAN diarahkan untuk membuat data baru yang realistis.
Cara kerja GAN
Pada tingkat tinggi, GAN bekerja dengan mengadu dua jaringan saraf—generator dan diskriminator—satu sama lain. GAN tidak memerlukan jenis arsitektur jaringan saraf tertentu untuk salah satu dari dua komponennya, selama arsitektur yang dipilih saling melengkapi. Misalnya, jika CNN digunakan sebagai diskriminator untuk menghasilkan gambar, maka generatornya mungkin berupa jaringan saraf de-konvolusional (deCNN), yang menjalankan proses CNN secara terbalik. Setiap komponen memiliki tujuan yang berbeda:
- Generator:Untuk menghasilkan data berkualitas tinggi sehingga diskriminator tertipu dan mengklasifikasikannya sebagai data nyata.
- Diskriminator:Untuk mengklasifikasikan sampel data tertentu secara akurat sebagai nyata (dari kumpulan data pelatihan) atau palsu (dihasilkan oleh generator).
Kompetisi ini merupakan implementasi dari zero-sum game, dimana reward yang diberikan kepada salah satu model juga merupakan penalti bagi model lainnya. Bagi generator, keberhasilan mengelabui diskriminator akan menghasilkan pembaruan model yang meningkatkan kemampuannya dalam menghasilkan data yang realistis. Sebaliknya, ketika diskriminator mengidentifikasi data palsu dengan benar, ia menerima pembaruan yang meningkatkan kemampuan pendeteksiannya. Secara matematis, diskriminator bertujuan untuk meminimalkan kesalahan klasifikasi, sedangkan generator berupaya memaksimalkannya.
Proses pelatihan GAN
Pelatihan GAN melibatkan pergantian antara generator dan diskriminator dalam beberapa periode. Epoch adalah pelatihan lengkap yang dijalankan pada seluruh kumpulan data. Proses ini berlanjut hingga generator menghasilkan data sintetis yang sekitar 50% menipu diskriminator. Meskipun kedua model menggunakan algoritme serupa untuk evaluasi dan peningkatan kinerja, pembaruannya terjadi secara independen. Pembaruan ini dilakukan menggunakan metode yang disebut backpropagation, yang mengukur kesalahan setiap model dan menyesuaikan parameter untuk meningkatkan kinerja. Algoritme pengoptimalan kemudian menyesuaikan parameter setiap model secara independen.
Berikut representasi visual arsitektur GAN yang menggambarkan persaingan antara generator dan diskriminator:
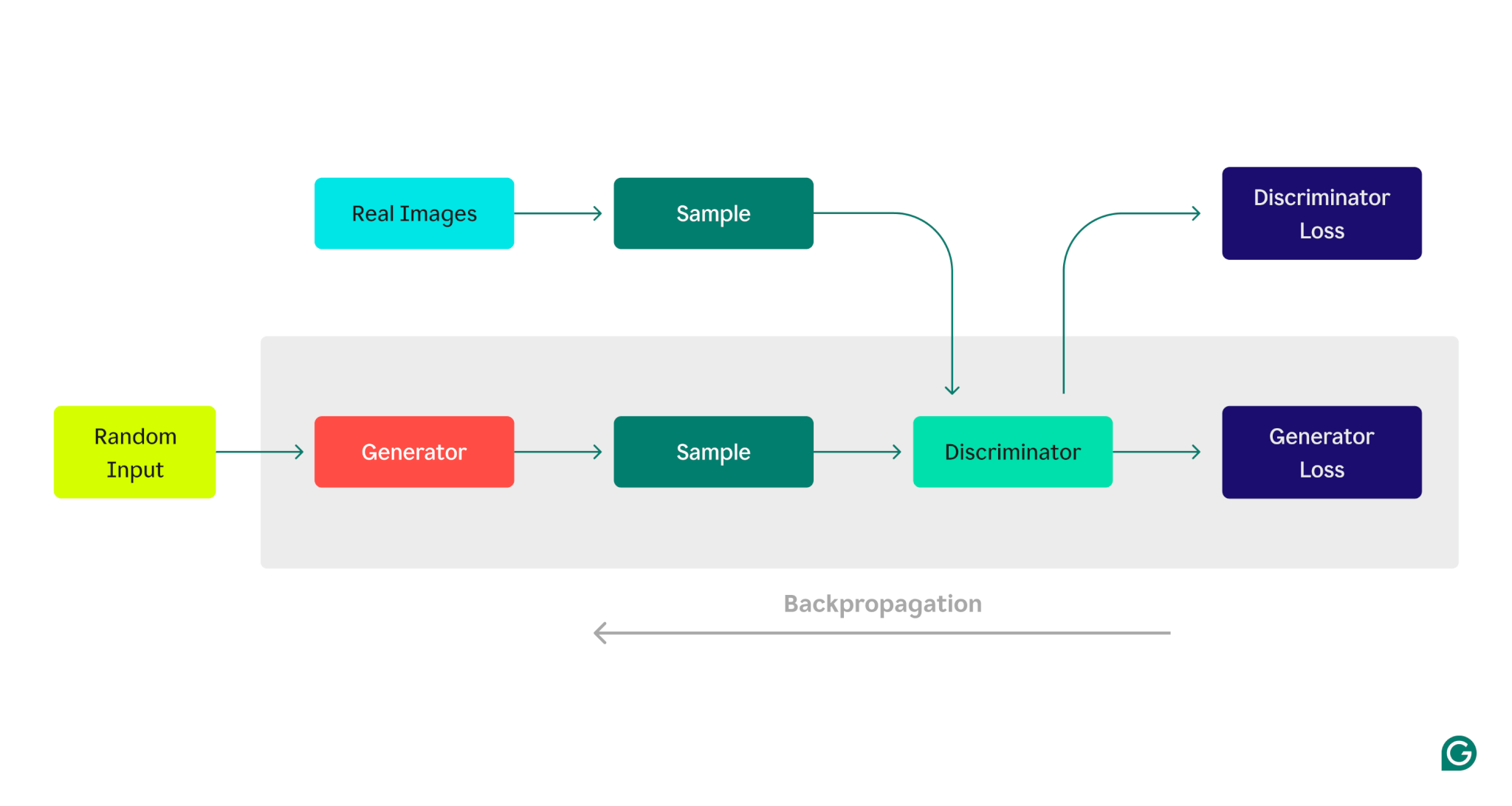
Fase pelatihan generator:
1 Generator membuat sampel data, biasanya dimulai dengan noise acak sebagai masukan.
2 Diskriminator mengklasifikasikan sampel ini sebagai sampel asli (dari kumpulan data pelatihan) atau palsu (dihasilkan oleh generator).
3 Berdasarkan respon diskriminator, parameter generator diperbarui menggunakan propagasi mundur.
Fase pelatihan diskriminator:
1 Data palsu dihasilkan menggunakan status generator saat ini.
2 Sampel yang dihasilkan diberikan kepada diskriminator, bersama dengan sampel dari kumpulan data pelatihan.
3 Dengan menggunakan propagasi mundur, parameter diskriminator diperbarui berdasarkan kinerja klasifikasinya.
Proses pelatihan berulang ini berlanjut, dengan setiap parameter model disesuaikan berdasarkan performanya, hingga generator secara konsisten menghasilkan data yang tidak dapat dibedakan secara andal oleh diskriminator dari data sebenarnya.
Jenis GAN
Berdasarkan arsitektur dasar GAN yang sering disebut sebagai vanilla GAN, jenis GAN khusus lainnya telah dikembangkan dan dioptimalkan untuk berbagai tugas. Beberapa variasi yang paling umum dijelaskan di bawah ini, meskipun ini bukan daftar yang lengkap:
GAN Bersyarat (cGAN)
GAN bersyarat, atau cGAN, menggunakan informasi tambahan, yang disebut kondisi, untuk memandu model dalam menghasilkan jenis data tertentu saat melatih kumpulan data yang lebih umum. Kondisi dapat berupa label kelas, deskripsi berbasis teks, atau tipe informasi klasifikasi lainnya untuk data. Misalnya, bayangkan Anda hanya perlu membuat gambar kucing siam, tetapi kumpulan data pelatihan Anda berisi gambar semua jenis kucing. Di cGAN, Anda dapat memberi label pada gambar pelatihan dengan jenis kucing, dan model dapat menggunakan ini untuk mempelajari cara menghasilkan gambar kucing siam saja.

GAN konvolusional mendalam (DCGAN)
GAN konvolusional mendalam, atau DCGAN, dioptimalkan untuk pembuatan gambar. Dalam DCGAN, generatornya adalah jaringan saraf konvolusional yang tertanam dalam (deCNN), dan diskriminatornya adalah CNN yang dalam. CNN lebih cocok untuk bekerja dengan dan menghasilkan gambar karena kemampuannya menangkap hierarki dan pola spasial. Generator di DCGAN menggunakan lapisan konvolusional upsampling dan transposisi untuk menghasilkan gambar berkualitas lebih tinggi daripada yang dapat dihasilkan oleh perceptron berlapis-lapis (jaringan saraf sederhana yang membuat keputusan dengan menimbang fitur masukan). Demikian pula, diskriminator menggunakan lapisan konvolusional untuk mengekstrak fitur dari sampel gambar dan mengklasifikasikannya secara akurat sebagai asli atau palsu.
SiklusGAN
CycleGAN adalah jenis GAN yang dirancang untuk menghasilkan satu jenis gambar dari jenis gambar lainnya. Misalnya, CycleGAN dapat mengubah gambar tikus menjadi tikus, atau anjing menjadi anjing hutan. CycleGAN dapat melakukan terjemahan gambar-ke-gambar ini tanpa pelatihan pada kumpulan data berpasangan, yaitu kumpulan data yang berisi gambar dasar dan transformasi yang diinginkan. Kemampuan ini dicapai dengan menggunakan dua generator dan dua diskriminator, bukan pasangan tunggal yang digunakan vanilla GAN. Di CycleGAN, satu generator mengonversi gambar dari gambar dasar ke versi transformasi, sementara generator lainnya melakukan konversi ke arah yang berlawanan. Demikian pula, setiap diskriminator memeriksa jenis gambar tertentu untuk menentukan apakah gambar tersebut asli atau palsu. CycleGAN kemudian menggunakan pemeriksaan konsistensi untuk memastikan bahwa mengonversi gambar ke gaya lain dan mengembalikannya menghasilkan gambar asli.
Penerapan GAN
Karena arsitekturnya yang khas, GAN telah diterapkan pada berbagai kasus penggunaan inovatif, meskipun kinerjanya sangat bergantung pada tugas tertentu dan kualitas data. Beberapa aplikasi yang lebih canggih mencakup pembuatan teks-ke-gambar, augmentasi data, serta pembuatan dan manipulasi video.
Pembuatan teks-ke-gambar
GAN dapat menghasilkan gambar dari deskripsi tekstual. Aplikasi ini berharga dalam industri kreatif, memungkinkan penulis dan desainer memvisualisasikan adegan dan karakter yang dijelaskan dalam teks. Meskipun GAN sering digunakan untuk tugas-tugas tersebut, model AI generatif lainnya, seperti DALL-E OpenAI, menggunakan arsitektur berbasis transformator untuk mencapai hasil serupa.
Augmentasi data
GAN berguna untuk augmentasi data karena dapat menghasilkan data sintetik yang menyerupai data pelatihan nyata, meskipun tingkat akurasi dan realisme dapat bervariasi bergantung pada kasus penggunaan spesifik dan pelatihan model. Kemampuan ini sangat berharga dalam pembelajaran mesin untuk memperluas kumpulan data terbatas dan meningkatkan performa model. Selain itu, GAN menawarkan solusi untuk menjaga privasi data. Di bidang sensitif seperti layanan kesehatan dan keuangan, GAN dapat menghasilkan data sintetis yang mempertahankan properti statistik dari kumpulan data asli tanpa mengorbankan informasi sensitif.
Pembuatan dan manipulasi video
GAN telah menunjukkan harapan dalam pembuatan video dan tugas manipulasi tertentu. Misalnya, GAN dapat digunakan untuk menghasilkan frame masa depan dari rangkaian video awal, membantu aplikasi seperti memprediksi pergerakan pejalan kaki atau memperkirakan bahaya di jalan raya untuk kendaraan otonom. Namun, aplikasi ini masih dalam penelitian dan pengembangan aktif. GAN juga dapat digunakan untuk menghasilkan konten video yang sepenuhnya sintetis dan menyempurnakan video dengan efek khusus yang realistis.
Keuntungan GAN
GAN menawarkan beberapa keuntungan berbeda, termasuk kemampuan untuk menghasilkan data sintetik yang realistis, belajar dari data yang tidak berpasangan, dan melakukan pelatihan tanpa pengawasan.
Pembuatan data sintetis berkualitas tinggi
Arsitektur GAN memungkinkan mereka menghasilkan data sintetis yang dapat mendekati data dunia nyata dalam aplikasi seperti augmentasi data dan pembuatan video, meskipun kualitas dan presisi data ini sangat bergantung pada kondisi pelatihan dan parameter model. Misalnya, DCGAN, yang memanfaatkan CNN untuk pemrosesan gambar optimal, unggul dalam menghasilkan gambar realistis.
Mampu belajar dari data yang tidak berpasangan
Tidak seperti beberapa model ML, GAN dapat belajar dari kumpulan data tanpa memasangkan contoh masukan dan keluaran. Fleksibilitas ini memungkinkan GAN digunakan dalam berbagai tugas ketika data berpasangan langka atau tidak tersedia. Misalnya, dalam tugas penerjemahan gambar-ke-gambar, model tradisional sering kali memerlukan kumpulan data gambar dan transformasinya untuk pelatihan. Sebaliknya, GAN dapat memanfaatkan lebih banyak variasi kumpulan data potensial untuk pelatihan.
Pembelajaran tanpa pengawasan
GAN adalah metode pembelajaran mesin tanpa pengawasan, artinya GAN dapat dilatih pada data tidak berlabel tanpa arahan eksplisit. Hal ini sangat menguntungkan karena pelabelan data merupakan proses yang memakan waktu dan mahal. Kemampuan GAN untuk belajar dari data yang tidak berlabel menjadikannya berharga untuk aplikasi yang data berlabelnya terbatas atau sulit diperoleh. GAN juga dapat diadaptasi untuk pembelajaran semi-supervisi dan terawasi, sehingga memungkinkan mereka juga menggunakan data berlabel.
Kekurangan GAN
Meskipun GAN adalah alat yang ampuh dalam pembelajaran mesin, arsitekturnya menimbulkan serangkaian kelemahan unik. Kerugian ini termasuk sensitivitas terhadap hyperparameter, biaya komputasi yang tinggi, kegagalan konvergensi, dan fenomena yang disebut mode collaps.
Sensitivitas hiperparameter
GAN sensitif terhadap hyperparameter, yaitu parameter yang ditetapkan sebelum pelatihan dan tidak dipelajari dari data. Contohnya termasuk arsitektur jaringan dan jumlah contoh pelatihan yang digunakan dalam satu iterasi. Perubahan kecil pada parameter ini dapat memengaruhi proses pelatihan dan keluaran model secara signifikan, sehingga memerlukan penyesuaian ekstensif untuk aplikasi praktis.
Biaya komputasi yang tinggi
Karena arsitekturnya yang kompleks, proses pelatihan berulang, dan sensitivitas hyperparameter, GAN sering kali menimbulkan biaya komputasi yang tinggi. Melatih GAN agar berhasil memerlukan perangkat keras yang khusus dan mahal, serta waktu yang lama, yang dapat menjadi penghalang bagi banyak organisasi yang ingin memanfaatkan GAN.
Kegagalan konvergensi
Insinyur dan peneliti dapat menghabiskan banyak waktu untuk bereksperimen dengan konfigurasi pelatihan sebelum mencapai tingkat yang dapat diterima sehingga keluaran model menjadi stabil dan akurat, yang dikenal sebagai tingkat konvergensi. Konvergensi dalam GAN bisa sangat sulit dicapai dan mungkin tidak akan bertahan lama. Kegagalan konvergensi adalah ketika diskriminator gagal dalam memutuskan secara memadai antara data asli dan palsu, sehingga menghasilkan akurasi sekitar 50% karena diskriminator belum memperoleh kemampuan untuk mengidentifikasi data nyata, tidak seperti keseimbangan yang diharapkan yang dicapai selama pelatihan yang berhasil. Beberapa GAN mungkin tidak pernah mencapai konvergensi dan memerlukan analisis khusus untuk memperbaikinya.
Mode runtuh
GAN rentan terhadap masalah yang disebut keruntuhan mode, yaitu generator menghasilkan rentang keluaran yang terbatas dan gagal mencerminkan keragaman distribusi data di dunia nyata. Masalah ini muncul dari arsitektur GAN, karena generator menjadi terlalu fokus dalam menghasilkan data yang dapat menipu pelaku diskriminator, sehingga menghasilkan contoh serupa.