
Apa itu Jaringan Syaraf Tiruan?
Diterbitkan: 2024-06-26Apa itu jaringan saraf?
Jaringan saraf adalah jenis model pembelajaran mendalam dalam bidang pembelajaran mesin (ML) yang lebih luas yang mensimulasikan otak manusia. Ia memproses data melalui node atau neuron yang saling berhubungan yang disusun berlapis-lapis—input, tersembunyi, dan output. Setiap node melakukan komputasi sederhana, sehingga berkontribusi pada kemampuan model untuk mengenali pola dan membuat prediksi.
Jaringan saraf pembelajaran mendalam sangat efektif dalam menangani tugas-tugas kompleks seperti pengenalan gambar dan ucapan, yang merupakan komponen penting dari banyak aplikasi AI. Kemajuan terkini dalam arsitektur jaringan saraf dan teknik pelatihan telah meningkatkan kemampuan sistem AI secara signifikan.
Bagaimana jaringan saraf disusun
Sesuai dengan namanya, model jaringan saraf mengambil inspirasi dari neuron, bahan penyusun otak. Manusia dewasa memiliki sekitar 85 miliar neuron, masing-masing terhubung dengan sekitar 1.000 neuron lainnya. Satu sel otak berkomunikasi dengan sel lainnya dengan mengirimkan bahan kimia yang disebut neurotransmiter. Jika sel penerima mendapat cukup bahan kimia ini, sel tersebut akan tereksitasi dan mengirimkan bahan kimianya sendiri ke sel lain.
Unit dasar dari apa yang kadang-kadang disebut jaringan syaraf tiruan (JST) adalah sebuahsimpul, yang bukan berupa sel, namun merupakan fungsi matematika. Sama seperti neuron, mereka berkomunikasi dengan node lain jika mendapat masukan yang cukup.
Di situlah kesamaannya berakhir. Jaringan saraf memiliki struktur yang jauh lebih sederhana daripada otak, dengan lapisan yang terdefinisi dengan rapi: masukan, tersembunyi, dan keluaran. Kumpulan lapisan-lapisan ini disebutmodel.Mereka belajar atauberlatihdengan berulang kali mencoba menghasilkan keluaran buatan yang paling mirip dengan hasil yang diinginkan. (Lebih lanjut tentang itu sebentar lagi.)
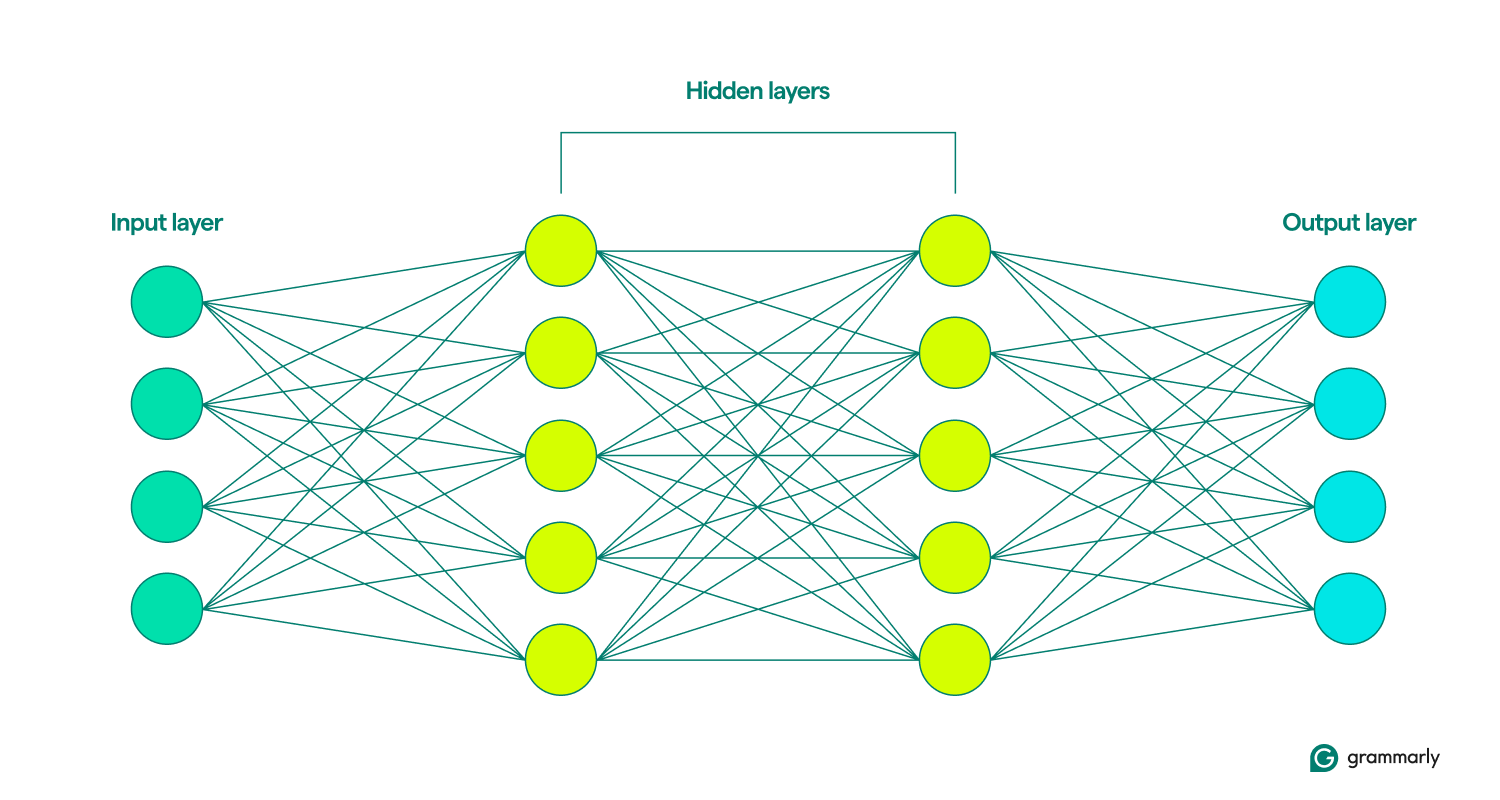
Lapisan masukan dan keluaran cukup jelas. Sebagian besar aktivitas jaringan saraf terjadi di lapisan tersembunyi. Ketika sebuah node diaktifkan oleh input dari lapisan sebelumnya, ia melakukan perhitungannya dan memutuskan apakah akan meneruskan output ke node di lapisan berikutnya. Lapisan ini dinamakan demikian karena operasinya tidak terlihat oleh pengguna akhir, meskipun ada teknik bagi para insinyur untuk melihat apa yang terjadi di lapisan yang disebut lapisan tersembunyi.
Jika jaringan saraf menyertakan beberapa lapisan tersembunyi, jaringan tersebut disebut jaringan pembelajaran mendalam. Jaringan neural dalam modern biasanya memiliki banyak lapisan, termasuk sub-lapisan khusus yang menjalankan fungsi berbeda. Misalnya, beberapa sub-lapisan meningkatkan kemampuan jaringan untuk mempertimbangkan informasi kontekstual di luar masukan langsung yang dianalisis.
Cara kerja jaringan saraf
Pikirkan bagaimana bayi belajar. Mereka mencoba sesuatu, gagal, dan mencoba lagi dengan cara yang berbeda. Perulangan ini terus berlanjut hingga mereka menyempurnakan perilakunya. Kurang lebih itulah cara jaringan saraf belajar juga.
Pada awal pelatihannya, jaringan saraf membuat tebakan acak. Sebuah node pada lapisan input secara acak memutuskan node mana di lapisan tersembunyi pertama yang akan diaktifkan, dan kemudian node tersebut secara acak mengaktifkan node di lapisan berikutnya, dan seterusnya, hingga proses acak ini mencapai lapisan output. (Model bahasa besar seperti GPT-4 memiliki sekitar 100 lapisan, dengan puluhan atau ratusan ribu node di setiap lapisan.)
Mempertimbangkan semua keacakan tersebut, model tersebut membandingkan keluarannya—yang mungkin buruk—dan mencari tahu seberapa salah keluarannya. Ia kemudian menyesuaikan koneksi masing-masing node ke node lain, mengubah seberapa rentan node tersebut untuk diaktifkan berdasarkan input yang diberikan. Hal ini dilakukan berulang kali hingga keluarannya mendekati jawaban yang diinginkan.
Jadi, bagaimana jaringan saraf mengetahui apa yang seharusnya mereka lakukan? Pembelajaran mesin (ML) dapat dibagi menjadi beberapa pendekatan, termasuk pembelajaran yang diawasi dan tanpa pengawasan. Dalam pembelajaran terawasi, model dilatih pada data yang menyertakan label atau jawaban eksplisit, seperti gambar yang dipasangkan dengan teks deskriptif. Namun, pembelajaran tanpa pengawasan melibatkan penyediaan data tanpa label kepada model, sehingga memungkinkannya mengidentifikasi pola dan hubungan secara mandiri.
Suplemen umum untuk pelatihan ini adalah pembelajaran penguatan, di mana model menjadi lebih baik sebagai respons terhadap umpan balik. Seringkali, hal ini diberikan oleh evaluator manusia (jika Anda pernah mengklik jempol ke atas atau jempol ke bawah pada saran komputer, Anda telah berkontribusi pada pembelajaran penguatan). Namun, ada juga cara bagi model untuk belajar secara mandiri secara berulang.
Memikirkan keluaran jaringan saraf sebagai prediksi adalah hal yang akurat dan instruktif. Baik menilai kelayakan kredit atau membuat lagu, model AI bekerja dengan menebak mana yang paling mungkin benar. AI generatif, seperti ChatGPT, membawa prediksi selangkah lebih maju. Ia bekerja secara berurutan, membuat tebakan tentang apa yang akan terjadi setelah keluaran yang baru saja dibuat. (Kita akan membahas mengapa hal ini bisa menjadi masalah nanti.)
Bagaimana jaringan saraf menghasilkan jawaban
Setelah jaringan dilatih, bagaimana jaringan memproses informasi yang dilihatnya untuk memprediksi respons yang benar? Saat Anda mengetik perintah seperti “Ceritakan cerita tentang peri” ke antarmuka ChatGPT, bagaimana ChatGPT memutuskan cara meresponsnya?
Langkah pertama adalah lapisan masukan jaringan saraf memecah perintah Anda menjadi potongan-potongan kecil informasi, yang dikenal sebagaitoken. Untuk jaringan pengenalan gambar, token mungkin berupa piksel. Untuk jaringan yang menggunakan pemrosesan bahasa alami (NLP), seperti ChatGPT, token biasanya berupa kata, bagian kata, atau frasa yang sangat pendek.
Setelah jaringan mendaftarkan token pada masukan, informasi tersebut diteruskan melalui lapisan tersembunyi yang telah dilatih sebelumnya. Node yang dilewatinya dari satu lapisan ke lapisan berikutnya menganalisis bagian masukan yang semakin besar. Dengan cara ini, jaringan NLP pada akhirnya dapat menafsirkan seluruh kalimat atau paragraf, bukan hanya sebuah kata atau huruf.
Kini jaringan dapat mulai menyusun responsnya, yang dilakukan sebagai serangkaian prediksi kata demi kata tentang apa yang akan terjadi selanjutnya berdasarkan semua hal yang telah dilatihnya.
Pertimbangkan perintah, “Ceritakan sebuah cerita tentang peri.” Untuk menghasilkan respons, jaringan saraf menganalisis perintah untuk memprediksi kata pertama yang paling mungkin. Misalnya, sistem ini mungkin menentukan bahwa ada peluang 80% bahwa “The” adalah pilihan terbaik, peluang 10% untuk “A”, dan peluang 10% untuk “Sekali”. Kemudian secara acak memilih sebuah nomor: Jika nomor tersebut antara 1 dan 8, ia memilih “The”; jika 9, ia memilih “A”; dan jika 10, ia memilih “Sekali”. Misalkan angka acaknya adalah 4, yang sesuai dengan “The.” Jaringan kemudian memperbarui perintah menjadi “Ceritakan sebuah cerita tentang peri. The” dan ulangi proses untuk memprediksi kata berikutnya setelah “The.” Siklus ini berlanjut, dengan setiap prediksi kata baru berdasarkan perintah yang diperbarui, hingga cerita lengkap dihasilkan.
Jaringan yang berbeda akan membuat prediksi ini secara berbeda. Misalnya, model pengenalan gambar mungkin mencoba memprediksi label mana yang akan diberikan pada gambar anjing dan menentukan bahwa terdapat 70% kemungkinan bahwa label yang benar adalah “Lab coklat”, 20% untuk “Spaniel Inggris”, dan 10% untuk “golden retriever.” Dalam hal klasifikasi, umumnya jaringan akan memilih pilihan yang paling mungkin, bukan tebakan probabilistik.
Jenis jaringan saraf
Berikut ini ikhtisar berbagai jenis jaringan saraf dan cara kerjanya.
- Jaringan saraf umpan maju (FNN): Dalam model ini, informasi mengalir dalam satu arah: dari lapisan masukan, melalui lapisan tersembunyi, dan akhirnya ke lapisan keluaran.Jenis model ini paling cocok untuk tugas prediksi yang lebih sederhana, seperti mendeteksi penipuan kartu kredit.
- Jaringan saraf berulang (RNN): Berbeda dengan FNN, RNN mempertimbangkan masukan sebelumnya saat membuat prediksi.Hal ini membuat mereka cocok untuk tugas pemrosesan bahasa karena akhir kalimat yang dihasilkan sebagai respons terhadap perintah bergantung pada bagaimana kalimat dimulai.
- Jaringan memori jangka pendek (LSTM): LSTM secara selektif melupakan informasi, sehingga memungkinkannya bekerja lebih efisien.Ini penting untuk memproses teks dalam jumlah besar; misalnya, peningkatan Google Terjemahan tahun 2016 ke terjemahan mesin saraf mengandalkan LSTM.
- Jaringan saraf konvolusional (CNN): CNN bekerja paling baik saat memproses gambar.Mereka menggunakanlapisan konvolusionaluntuk memindai seluruh gambar dan mencari fitur seperti garis atau bentuk. Hal ini memungkinkan CNN untuk mempertimbangkan lokasi spasial, seperti menentukan apakah suatu objek terletak di bagian atas atau bawah gambar, dan juga untuk mengidentifikasi bentuk atau jenis objek terlepas dari lokasinya.
- Jaringan permusuhan generatif (GAN): GAN sering kali digunakan untuk menghasilkan gambar baru berdasarkan deskripsi atau gambar yang sudah ada.Mereka disusun sebagai kompetisi antara dua jaringan saraf: jaringangenerator, yang mencoba mengelabui jaringandiskriminatoragar percaya bahwa masukan palsu itu nyata.
- Transformer dan jaringan perhatian: Transformer bertanggung jawab atas ledakan kemampuan AI saat ini.Model ini menggabungkan sorotan perhatian yang memungkinkan mereka memfilter masukan agar fokus pada elemen yang paling penting, dan bagaimana elemen tersebut berhubungan satu sama lain, bahkan di seluruh halaman teks. Transformer juga dapat melatih data dalam jumlah besar, sehingga model seperti ChatGPT dan Gemini disebutmodel bahasa besar (LLM).
Penerapan jaringan saraf
Ada terlalu banyak hal yang perlu disebutkan, berikut adalah pilihan cara jaringan saraf digunakan saat ini, dengan penekanan pada bahasa alami.

Bantuan menulis: Transformers telah mengubah cara komputer dapat membantu orang menulis dengan lebih baik.Alat penulisan AI, seperti Grammarly, menawarkan penulisan ulang kalimat dan paragraf untuk meningkatkan nada dan kejelasan. Tipe model ini juga meningkatkan kecepatan dan keakuratan saran tata bahasa dasar. Pelajari lebih lanjut tentang bagaimana Grammarly menggunakan AI.
Pembuatan konten: Jika Anda pernah menggunakan ChatGPT atau DALL-E, Anda pernah merasakan AI generatif secara langsung.Transformers telah merevolusi kapasitas komputer untuk menciptakan media yang sesuai dengan manusia, mulai dari cerita pengantar tidur hingga rendering arsitektur yang hiperrealistis.
Pengenalan ucapan: Komputer semakin baik setiap hari dalam mengenali ucapan manusia.Dengan teknologi baru yang memungkinkan mereka mempertimbangkan lebih banyak konteks, model menjadi semakin akurat dalam mengenali apa yang ingin disampaikan oleh pembicara, meskipun suaranya saja dapat memiliki banyak interpretasi.
Diagnosis dan penelitian medis: Jaringan saraf unggul dalam deteksi dan klasifikasi pola, yang semakin banyak digunakan untuk membantu peneliti dan penyedia layanan kesehatan memahami dan mengatasi penyakit.Misalnya, kita harus berterima kasih kepada AI atas pesatnya perkembangan vaksin COVID-19.
Tantangan dan keterbatasan jaringan saraf
Berikut sekilas beberapa, namun tidak semua, masalah yang ditimbulkan oleh jaringan saraf.
Bias: Jaringan saraf hanya dapat belajar dari apa yang diberitahukan kepadanya.Jika video tersebut terpapar konten seksis atau rasis, kemungkinan besar keluarannya juga akan bersifat seksis atau rasis. Hal ini dapat terjadi dalam penerjemahan dari bahasa non-gender ke bahasa gender, dimana stereotip tetap ada tanpa identifikasi gender yang jelas.
Overfitting: Model yang tidak dilatih dengan benar dapat membaca terlalu banyak data yang diberikan dan kesulitan mendapatkan masukan baru.Misalnya, perangkat lunak pengenalan wajah yang sebagian besar dilatih pada orang-orang dari etnis tertentu mungkin tidak akan memberikan hasil yang baik pada wajah dari ras lain. Atau filter spam mungkin melewatkan jenis email sampah baru karena terlalu fokus pada pola yang pernah dilihat sebelumnya.
Halusinasi: Sebagian besar AI generatif saat ini menggunakan probabilitas sampai batas tertentu untuk memilih apa yang akan diproduksi daripada selalu memilih pilihan teratas.Pendekatan ini membantunya menjadi lebih kreatif dan menghasilkan teks yang terdengar lebih alami, namun juga dapat mengarahkannya untuk membuat pernyataan yang salah. (Ini juga mengapa LLM terkadang melakukan kesalahan matematika dasar.) Sayangnya, halusinasi ini sulit dideteksi kecuali Anda mengetahuinya lebih baik atau memeriksa fakta dengan sumber lain.
Interpretabilitas: Seringkali tidak mungkin mengetahui secara pasti bagaimana jaringan saraf membuat prediksi.Meskipun hal ini dapat membuat frustasi dari sudut pandang seseorang yang mencoba menyempurnakan model, hal ini juga dapat menjadi konsekuensi, karena AI semakin diandalkan untuk mengambil keputusan yang berdampak besar pada kehidupan manusia. Beberapa model yang digunakan saat ini tidak didasarkan pada jaringan saraf justru karena pembuatnya ingin dapat memeriksa dan memahami setiap tahapan proses.
Kekayaan intelektual: Banyak yang percaya bahwa LLM melanggar hak cipta dengan memasukkan tulisan dan karya seni lainnya tanpa izin.Meskipun mereka cenderung tidak mereproduksi karya berhak cipta secara langsung, model-model ini diketahui menciptakan gambar atau ungkapan yang kemungkinan besar berasal dari seniman tertentu atau bahkan menciptakan karya dengan gaya khas seniman ketika diminta.
Konsumsi daya: Semua pelatihan dan pengoperasian model transformator ini menggunakan energi yang sangat besar.Faktanya, dalam beberapa tahun, AI dapat mengonsumsi daya sebesar Swedia atau Argentina. Hal ini menyoroti semakin pentingnya mempertimbangkan sumber energi dan efisiensi dalam pengembangan AI.
Masa depan jaringan saraf
Memprediksi masa depan AI sangatlah sulit. Pada tahun 1970, salah satu peneliti AI terkemuka memperkirakan bahwa “dalam tiga hingga delapan tahun, kita akan memiliki mesin dengan kecerdasan umum seperti manusia pada umumnya.” (Kita masih belum terlalu dekat dengan kecerdasan umum buatan (AGI). Setidaknya kebanyakan orang tidak berpikir demikian.)
Namun, kami dapat menunjukkan beberapa tren yang perlu diwaspadai. Model yang lebih efisien akan mengurangi konsumsi daya dan menjalankan jaringan saraf yang lebih kuat secara langsung pada perangkat seperti ponsel pintar. Teknik pelatihan baru memungkinkan prediksi yang lebih berguna dengan data pelatihan yang lebih sedikit. Terobosan dalam interpretabilitas dapat meningkatkan kepercayaan dan membuka jalur baru untuk meningkatkan keluaran jaringan saraf. Terakhir, menggabungkan komputasi kuantum dan jaringan saraf dapat menghasilkan inovasi yang hanya dapat kita bayangkan.
Kesimpulan
Jaringan saraf, yang terinspirasi oleh struktur dan fungsi otak manusia, merupakan hal mendasar bagi kecerdasan buatan modern. Mereka unggul dalam tugas pengenalan pola dan prediksi, yang mendasari banyak aplikasi AI saat ini, mulai dari pengenalan gambar dan ucapan hingga pemrosesan bahasa alami. Dengan kemajuan dalam arsitektur dan teknik pelatihan, jaringan saraf terus mendorong peningkatan signifikan dalam kemampuan AI.
Terlepas dari potensinya, jaringan saraf menghadapi tantangan seperti bias, overfitting, dan konsumsi energi yang tinggi. Mengatasi masalah ini sangatlah penting seiring dengan terus berkembangnya AI. Ke depan, inovasi dalam efisiensi model, interpretabilitas, dan integrasi dengan komputasi kuantum menjanjikan untuk lebih memperluas kemungkinan jaringan saraf, yang berpotensi menghasilkan aplikasi yang lebih transformatif.