
Dasar-dasar Jaringan Neural Berulang: Yang Perlu Anda Ketahui
Diterbitkan: 2024-09-19Jaringan saraf berulang (RNN) adalah metode penting dalam bidang analisis data, pembelajaran mesin (ML), dan pembelajaran mendalam. Artikel ini bertujuan untuk mengeksplorasi RNN dan merinci fungsionalitas, aplikasi, serta kelebihan dan kekurangannya dalam konteks pembelajaran mendalam yang lebih luas.
Daftar isi
Apa itu RNN?
Cara kerja RNN
Jenis RNN
RNN vs. transformator dan CNN
Penerapan RNN
Keuntungan
Kekurangan
Apa itu jaringan saraf berulang?
Jaringan saraf berulang adalah jaringan saraf dalam yang dapat memproses data berurutan dengan memelihara memori internal, memungkinkannya melacak masukan masa lalu untuk menghasilkan keluaran. RNN adalah komponen dasar pembelajaran mendalam dan sangat cocok untuk tugas-tugas yang melibatkan data berurutan.
Kata "berulang" dalam "jaringan saraf berulang" mengacu pada bagaimana model menggabungkan informasi dari masukan masa lalu dengan masukan saat ini. Informasi dari masukan lama disimpan dalam semacam memori internal, yang disebut “keadaan tersembunyi”. Hal ini berulang—memuat kembali perhitungan sebelumnya untuk menciptakan aliran informasi yang berkesinambungan.
Mari kita tunjukkan dengan sebuah contoh: Misalkan kita ingin menggunakan RNN untuk mendeteksi sentimen (baik positif atau negatif) dari kalimat “Dia makan pai dengan gembira.” RNN akan memproses katahe, memperbarui status tersembunyinya untuk memasukkan kata tersebut, dan kemudian melanjutkan keate, menggabungkannya dengan apa yang dipelajari darihe, dan seterusnya dengan setiap kata hingga kalimat selesai. Sebagai gambaran, manusia yang membaca kalimat ini akan memperbarui pemahamannya pada setiap kata. Setelah mereka membaca dan memahami keseluruhan kalimat, manusia dapat mengatakan kalimat tersebut positif atau negatif. Proses pemahaman manusia inilah yang coba didekati oleh keadaan tersembunyi.
RNN adalah salah satu model pembelajaran mendalam yang mendasar. Mereka telah melakukan tugas pemrosesan bahasa alami (NLP) dengan sangat baik, meskipun transformator telah menggantikannya. Transformer adalah arsitektur jaringan saraf canggih yang meningkatkan kinerja RNN dengan, misalnya, memproses data secara paralel dan mampu menemukan hubungan antara kata-kata yang berjauhan dalam teks sumber (menggunakan mekanisme perhatian). Namun, RNN masih berguna untuk data deret waktu dan untuk situasi di mana model yang lebih sederhana sudah cukup.
Cara kerja RNN
Untuk menjelaskan secara rinci cara kerja RNN, mari kita kembali ke contoh tugas sebelumnya: Mengklasifikasikan sentimen kalimat “Dia makan pai dengan gembira.”
Kita mulai dengan RNN terlatih yang menerima masukan teks dan mengembalikan keluaran biner (1 mewakili positif dan 0 mewakili negatif). Sebelum masukan diberikan ke model, keadaan tersembunyi bersifat umum—dipelajari dari proses pelatihan namun belum spesifik untuk masukan.
Kata pertama,He, dimasukkan ke dalam model. Di dalam RNN, status tersembunyinya kemudian diperbarui (menjadi status tersembunyi h1) untuk memasukkan kataHe. Selanjutnya, kataatediteruskan ke RNN, dan h1 diperbarui (menjadi h2) untuk memasukkan kata baru ini. Proses ini berulang hingga kata terakhir dimasukkan. Status tersembunyi (h4) diperbarui untuk menyertakan kata terakhir. Kemudian status tersembunyi yang diperbarui digunakan untuk menghasilkan 0 atau 1.
Berikut representasi visual cara kerja proses RNN:
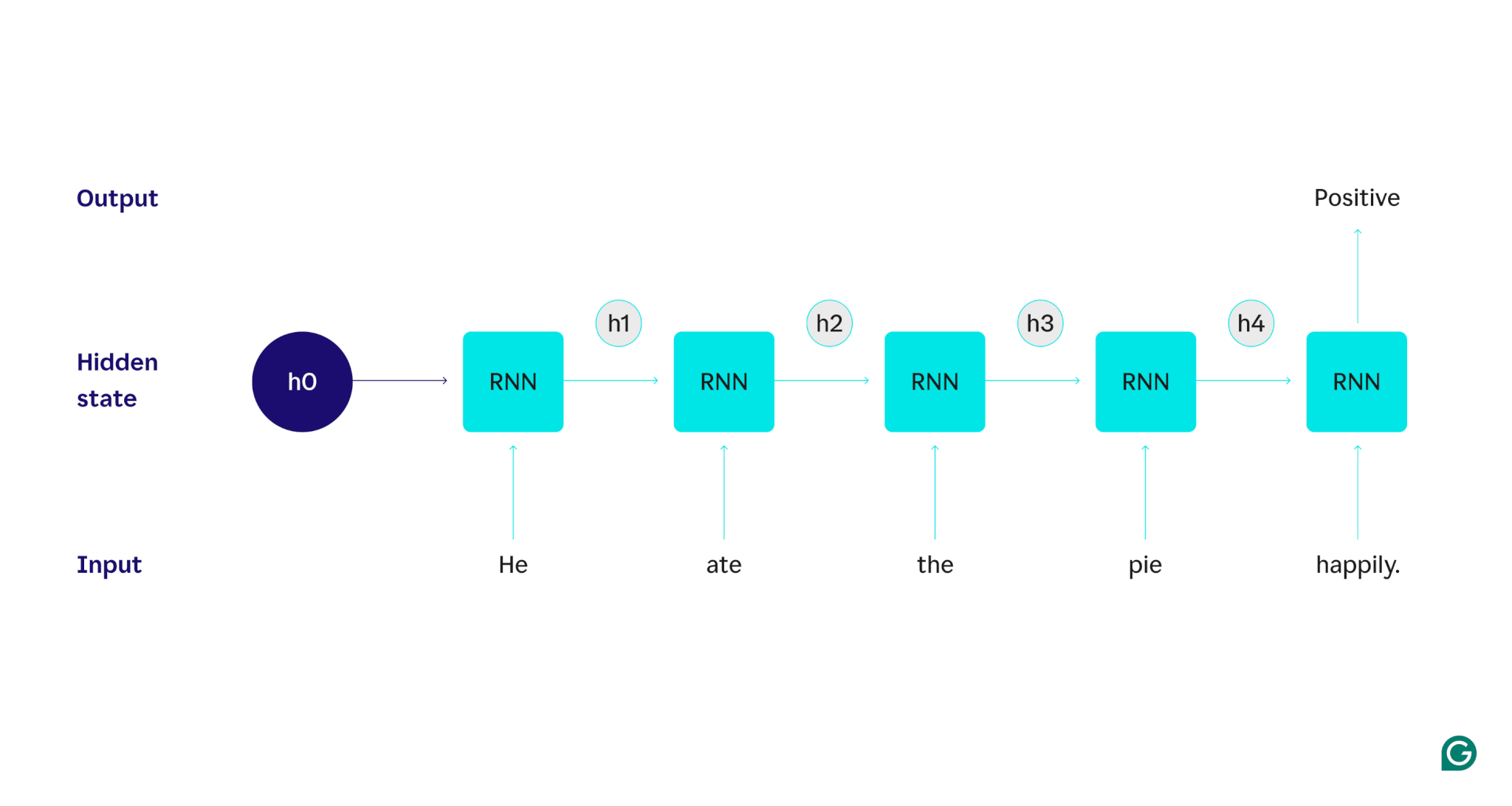
Pengulangan tersebut adalah inti dari RNN, namun ada beberapa pertimbangan lain:
- Penyematan teks:RNN tidak dapat memproses teks secara langsung karena hanya berfungsi pada representasi numerik. Teks harus diubah menjadi embeddings sebelum dapat diproses oleh RNN.
- Pembuatan keluaran:Keluaran akan dihasilkan oleh RNN di setiap langkah. Namun, keluarannya mungkin tidak terlalu akurat sampai sebagian besar sumber data diproses. Misalnya, setelah hanya memproses bagian kalimat “Dia makan”, RNN mungkin tidak yakin apakah kalimat tersebut mewakili sentimen positif atau negatif— “Dia makan” mungkin terkesan netral. Hanya setelah memproses kalimat lengkap, keluaran RNN akan akurat.
- Melatih RNN:RNN harus dilatih untuk melakukan analisis sentimen secara akurat. Pelatihan melibatkan penggunaan banyak contoh berlabel (misalnya, “Dia memakan pai dengan marah,” diberi label negatif), menjalankannya melalui RNN, dan menyesuaikan model berdasarkan seberapa jauh prediksinya. Proses ini menetapkan nilai default dan mekanisme perubahan untuk status tersembunyi, memungkinkan RNN mempelajari kata mana yang penting untuk dilacak di seluruh masukan.
Jenis jaringan saraf berulang
Ada beberapa jenis RNN, masing-masing memiliki struktur dan penerapan yang berbeda-beda. RNN dasar sebagian besar berbeda dalam ukuran masukan dan keluarannya. RNN tingkat lanjut, seperti jaringan memori jangka pendek panjang (LSTM), mengatasi beberapa keterbatasan RNN dasar.
RNN dasar
RNN satu-ke-satu:RNN ini menerima masukan dengan panjang satu dan mengembalikan keluaran dengan panjang satu. Oleh karena itu, tidak ada pengulangan yang benar-benar terjadi, menjadikannya jaringan saraf standar, bukan RNN. Contoh RNN satu-ke-satu adalah pengklasifikasi gambar, yang masukannya berupa gambar tunggal dan keluarannya berupa label (misalnya, “burung”).
RNN satu-ke-banyak:RNN ini menerima input dengan panjang satu dan mengembalikan output multi-bagian. Misalnya, dalam tugas pembuatan teks gambar, masukannya berupa satu gambar, dan keluarannya berupa rangkaian kata yang mendeskripsikan gambar tersebut (misalnya, “Seekor burung melintasi sungai di hari yang cerah”).
RNN Banyak-ke-satu:RNN ini menerima masukan multi-bagian (misalnya kalimat, rangkaian gambar, atau data rangkaian waktu) dan mengembalikan keluaran dengan panjang satu. Misalnya pengklasifikasi sentimen kalimat (seperti yang telah kita bahas), yang masukannya berupa kalimat dan keluarannya berupa label sentimen tunggal (positif atau negatif).
RNN Banyak-ke-banyak:RNN ini mengambil masukan multi-bagian dan mengembalikan keluaran multi-bagian. Contohnya adalah model pengenalan suara, dimana masukannya berupa rangkaian bentuk gelombang audio dan keluarannya berupa rangkaian kata yang mewakili konten yang diucapkan.
RNN tingkat lanjut: Memori jangka pendek panjang (LSTM)
Jaringan memori jangka pendek dirancang untuk mengatasi masalah signifikan dengan RNN standar: Jaringan tersebut melupakan informasi melalui input yang panjang. Dalam RNN standar, status tersembunyi sangat dipengaruhi oleh bagian masukan terkini. Dalam masukan yang panjangnya ribuan kata, RNN akan melupakan detail penting dari kalimat pembuka. LSTM memiliki arsitektur khusus untuk mengatasi masalah lupa ini. Mereka memiliki modul yang memilih informasi mana yang perlu diingat dan dilupakan secara eksplisit. Jadi informasi terkini namun tidak berguna akan dilupakan, sedangkan informasi lama namun relevan akan dipertahankan. Hasilnya, LSTM jauh lebih umum dibandingkan RNN standar—mereka bekerja lebih baik pada tugas yang kompleks dan panjang. Namun, mereka tidak sempurna karena mereka masih memilih untuk melupakan barang-barang tersebut.

RNN vs. transformator dan CNN
Dua model pembelajaran mendalam umum lainnya adalah jaringan saraf konvolusional (CNN) dan transformator. Apa perbedaannya?
RNN vs. transformator
Baik RNN dan transformator banyak digunakan di NLP. Namun, keduanya berbeda secara signifikan dalam arsitektur dan pendekatan pemrosesan input.
Arsitektur dan pemrosesan
- RNN:RNN memproses masukan secara berurutan, satu kata pada satu waktu, mempertahankan keadaan tersembunyi yang membawa informasi dari kata-kata sebelumnya. Sifat berurutan ini berarti bahwa RNN dapat berjuang melawan ketergantungan jangka panjang karena lupa ini, yang mana informasi sebelumnya dapat hilang seiring dengan kemajuan rangkaian.
- Transformator:Transformator menggunakan mekanisme yang disebut “perhatian” untuk memproses masukan. Tidak seperti RNN, transformator melihat seluruh rangkaian secara bersamaan, membandingkan setiap kata dengan kata lainnya. Pendekatan ini menghilangkan masalah lupa, karena setiap kata memiliki akses langsung ke seluruh konteks masukan. Transformer telah menunjukkan kinerja unggul dalam tugas-tugas seperti pembuatan teks dan analisis sentimen karena kemampuan ini.
Paralelisasi
- RNN:Sifat RNN yang berurutan berarti model harus menyelesaikan pemrosesan satu bagian masukan sebelum melanjutkan ke bagian berikutnya. Hal ini sangat memakan waktu karena setiap langkah bergantung pada langkah sebelumnya.
- Transformer:Transformer memproses semua bagian masukan secara bersamaan, karena arsitekturnya tidak bergantung pada keadaan tersembunyi yang berurutan. Hal ini membuat mereka lebih dapat diparalelkan dan efisien. Misalnya, jika pemrosesan kalimat memerlukan waktu 5 detik per kata, RNN akan memerlukan waktu 25 detik untuk kalimat 5 kata, sedangkan transformator hanya memerlukan waktu 5 detik.
Implikasi praktis
Karena kelebihannya tersebut, trafo lebih banyak digunakan dalam industri. Namun, RNN, khususnya jaringan memori jangka pendek (LSTM), masih bisa efektif untuk tugas-tugas sederhana atau ketika berhadapan dengan urutan yang lebih pendek. LSTM sering digunakan sebagai modul penyimpanan memori penting dalam arsitektur pembelajaran mesin besar.
RNN vs. CNN
CNN pada dasarnya berbeda dari RNN dalam hal data yang ditangani dan mekanisme operasionalnya.
Tipe data
- RNN:RNN dirancang untuk data berurutan, seperti teks atau deret waktu, yang mengutamakan urutan titik data.
- CNN:CNN digunakan terutama untuk data spasial, seperti gambar, yang fokusnya adalah pada hubungan antara titik data yang berdekatan (misalnya, warna, intensitas, dan properti lain piksel dalam gambar berkaitan erat dengan properti piksel lain di dekatnya. piksel).
Operasi
- RNN:RNN menyimpan memori seluruh rangkaian, membuatnya cocok untuk tugas yang mengutamakan konteks dan urutan.
- CNN:CNN beroperasi dengan melihat wilayah input lokal (misalnya piksel tetangga) melalui lapisan konvolusional. Hal ini menjadikannya sangat efektif untuk pemrosesan gambar, namun kurang efektif untuk data sekuensial, karena ketergantungan jangka panjang mungkin lebih penting.
Panjang masukan
- RNN:RNN dapat menangani rangkaian masukan dengan panjang variabel dengan struktur yang kurang jelas, membuatnya fleksibel untuk tipe data sekuensial yang berbeda.
- CNN:CNN biasanya memerlukan input berukuran tetap, yang dapat menjadi batasan untuk menangani rangkaian dengan panjang variabel.
Penerapan RNN
RNN banyak digunakan di berbagai bidang karena kemampuannya menangani data sekuensial secara efektif.
Pemrosesan bahasa alami
Bahasa adalah bentuk data yang sangat berurutan, sehingga RNN bekerja dengan baik dalam tugas bahasa. RNN unggul dalam tugas-tugas seperti pembuatan teks, analisis sentimen, terjemahan, dan ringkasan. Dengan perpustakaan seperti PyTorch, seseorang dapat membuat chatbot sederhana menggunakan RNN dan beberapa gigabyte contoh teks.
Pengenalan ucapan
Pengenalan ucapan adalah bahasa pada intinya dan juga sangat berurutan. RNN banyak ke banyak dapat digunakan untuk tugas ini. Pada setiap langkah, RNN mengambil keadaan tersembunyi dan bentuk gelombang sebelumnya, mengeluarkan kata yang terkait dengan bentuk gelombang tersebut (berdasarkan konteks kalimat hingga titik tersebut).
Generasi musik
Musik juga sangat berurutan. Ketukan sebelumnya dalam sebuah lagu sangat mempengaruhi ketukan selanjutnya. RNN many-to-many dapat mengambil beberapa ketukan awal sebagai masukan dan kemudian menghasilkan ketukan tambahan sesuai keinginan pengguna. Alternatifnya, dapat menggunakan masukan teks seperti “melodic jazz” dan mengeluarkan perkiraan terbaik dari irama jazz melodis.
Keuntungan RNN
Meskipun RNN bukan lagi model NLP de facto, RNN masih memiliki beberapa kegunaan karena beberapa faktor.
Performa sekuensial yang bagus
RNN, khususnya LSTM, bekerja dengan baik pada data sekuensial. LSTM, dengan arsitektur memori khusus, dapat mengelola input sekuensial yang panjang dan kompleks. Misalnya, Google Terjemahan dulunya berjalan pada model LSTM sebelum era transformator. LSTM dapat digunakan untuk menambahkan modul memori strategis ketika jaringan berbasis transformator digabungkan untuk membentuk arsitektur yang lebih maju.
Model yang lebih kecil dan sederhana
RNN biasanya memiliki parameter model yang lebih sedikit dibandingkan transformator. Lapisan perhatian dan umpan maju pada transformator memerlukan lebih banyak parameter agar dapat berfungsi secara efektif. RNN dapat dilatih dengan proses dan contoh data yang lebih sedikit, sehingga lebih efisien untuk kasus penggunaan yang lebih sederhana. Hal ini menghasilkan model yang lebih kecil, lebih murah, dan lebih efisien namun tetap memiliki performa yang cukup.
Kekurangan RNN
RNN tidak lagi disukai karena suatu alasan: Transformer, meskipun ukurannya lebih besar dan proses pelatihannya, tidak memiliki kelemahan yang sama seperti RNN.
Memori terbatas
Status tersembunyi dalam RNN standar sangat membiaskan masukan terbaru, sehingga sulit untuk mempertahankan ketergantungan jangka panjang. Tugas dengan masukan yang panjang tidak berfungsi dengan baik dengan RNN. Meskipun LSTM bertujuan untuk mengatasi masalah ini, LSTM hanya melakukan mitigasi dan tidak menyelesaikannya sepenuhnya. Banyak tugas AI memerlukan penanganan input yang panjang, sehingga memori yang terbatas menjadi kelemahan yang signifikan.
Tidak dapat diparalelkan
Setiap proses model RNN bergantung pada output proses sebelumnya, khususnya status tersembunyi yang diperbarui. Akibatnya, seluruh model harus diproses secara berurutan untuk setiap bagian masukan. Sebaliknya, transformator dan CNN dapat memproses seluruh masukan secara bersamaan. Hal ini memungkinkan pemrosesan paralel di beberapa GPU, sehingga mempercepat komputasi secara signifikan. Kurangnya kemampuan paralelisasi RNN menyebabkan pelatihan lebih lambat, pembangkitan keluaran lebih lambat, dan jumlah maksimum data yang dapat dipelajari lebih rendah.
Masalah gradien
Pelatihan RNN dapat menjadi tantangan karena proses propagasi mundur harus melalui setiap langkah masukan (propagasi mundur melalui waktu). Karena banyaknya langkah waktu, gradien—yang menunjukkan bagaimana setiap parameter model harus disesuaikan—dapat menurun dan menjadi tidak efektif. Gradien bisa gagal karena menghilang, yang berarti gradien menjadi sangat kecil dan model tidak dapat lagi menggunakannya untuk belajar, atau meledak, yang menyebabkan gradien menjadi sangat besar dan model melampaui pembaruannya, sehingga membuat model tidak dapat digunakan. Menyeimbangkan permasalahan ini sulit dilakukan.