
Apa itu Autoencoder? Panduan Pemula
Diterbitkan: 2024-10-28Autoencoder adalah komponen penting dari pembelajaran mendalam, khususnya dalam tugas pembelajaran mesin tanpa pengawasan. Dalam artikel ini, kita akan mempelajari cara kerja autoencoder, arsitekturnya, dan berbagai jenis yang tersedia. Anda juga akan menemukan penerapannya di dunia nyata, beserta keuntungan dan keuntungan yang ada dalam penggunaannya.
Daftar isi
- Apa itu autoencoder?
- Arsitektur autoencoder
- Jenis autoencoder
- Aplikasi
- Keuntungan
- Kekurangan
Apa itu autoencoder?
Autoencoder adalah jenis jaringan saraf yang digunakan dalam pembelajaran mendalam untuk mempelajari representasi data masukan berdimensi lebih rendah yang efisien, yang kemudian digunakan untuk merekonstruksi data asli. Dengan melakukan hal ini, jaringan ini mempelajari fitur data yang paling penting selama pelatihan tanpa memerlukan label eksplisit, sehingga menjadikannya bagian dari pembelajaran yang diawasi sendiri. Autoencoder diterapkan secara luas dalam tugas-tugas seperti denoising gambar, deteksi anomali, dan kompresi data, yang mana kemampuannya untuk mengompresi dan merekonstruksi data sangat berharga.
Arsitektur autoencoder
Autoencoder terdiri dari tiga bagian: encoder, bottleneck (juga dikenal sebagai ruang atau kode laten), dan decoder. Komponen-komponen ini bekerja sama untuk menangkap fitur-fitur utama dari data masukan dan menggunakannya untuk menghasilkan rekonstruksi yang akurat.
Autoencoder mengoptimalkan keluarannya dengan menyesuaikan bobot encoder dan decoder, yang bertujuan untuk menghasilkan representasi terkompresi dari masukan yang mempertahankan fitur-fitur penting. Optimalisasi ini meminimalkan kesalahan rekonstruksi, yang merupakan perbedaan antara data masukan dan keluaran.
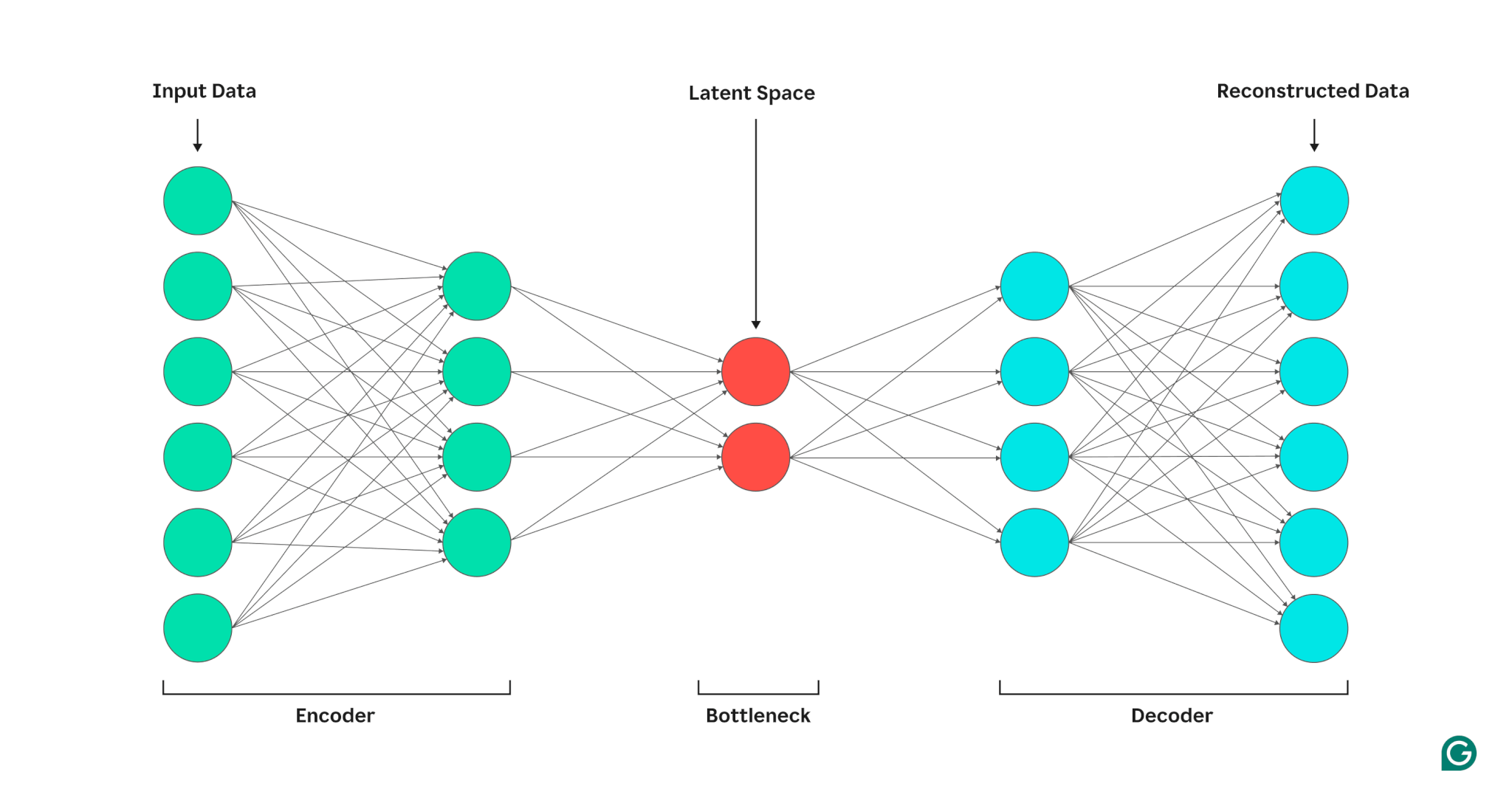
Pembuat enkode
Pertama, encoder memampatkan data masukan menjadi representasi yang lebih efisien. Encoder umumnya terdiri dari beberapa lapisan dengan lebih sedikit node di setiap lapisan. Saat data diproses melalui setiap lapisan, berkurangnya jumlah node memaksa jaringan mempelajari fitur terpenting dari data untuk membuat representasi yang dapat disimpan di setiap lapisan. Proses ini, yang dikenal sebagai reduksi dimensi, mengubah masukan menjadi ringkasan ringkas mengenai karakteristik utama data. Hyperparameter utama dalam encoder mencakup jumlah lapisan dan neuron per lapisan, yang menentukan kedalaman dan granularitas kompresi, dan fungsi aktivasi, yang menentukan bagaimana fitur data direpresentasikan dan diubah di setiap lapisan.
Kemacetan
Kemacetan, juga dikenal sebagai ruang laten atau kode, adalah tempat penyimpanan representasi terkompresi dari data masukan selama pemrosesan. Kemacetan memiliki jumlah node yang sedikit; ini membatasi jumlah data yang dapat disimpan dan menentukan tingkat kompresi. Jumlah node dalam kemacetan adalah hyperparameter yang dapat disesuaikan, memungkinkan pengguna mengontrol trade-off antara kompresi dan retensi data. Jika hambatannya terlalu kecil, autoencoder mungkin salah merekonstruksi data karena hilangnya detail penting. Di sisi lain, jika hambatannya terlalu besar, autoencoder mungkin hanya menyalin data masukan alih-alih mempelajari representasi umum yang bermakna.
Dekoder
Pada langkah terakhir ini, dekoder membuat ulang data asli dari bentuk terkompresi menggunakan fitur utama yang dipelajari selama proses pengkodean. Kualitas dekompresi ini diukur menggunakan kesalahan rekonstruksi, yang pada dasarnya merupakan ukuran seberapa berbedanya data yang direkonstruksi dengan masukan. Kesalahan rekonstruksi umumnya dihitung menggunakan mean squared error (MSE). Karena MSE mengukur selisih kuadrat antara data asli dan data yang direkonstruksi, MSE memberikan cara yang mudah secara matematis untuk memberikan sanksi yang lebih berat terhadap kesalahan rekonstruksi yang lebih besar.
Jenis autoencoder
Ada beberapa jenis autoencoder khusus, masing-masing dioptimalkan untuk aplikasi tertentu, mirip dengan jaringan saraf lainnya.
Menyangkal autoencoder
Autoencoder denoising dirancang untuk merekonstruksi data bersih dari input yang berisik atau rusak. Selama pelatihan, noise sengaja ditambahkan ke data masukan, sehingga memungkinkan model mempelajari fitur-fitur yang tetap konsisten meskipun ada noise. Keluaran kemudian dibandingkan dengan masukan bersih asli. Proses ini menjadikan autoencoder denoising sangat efektif dalam tugas pengurangan noise gambar dan audio, termasuk menghilangkan kebisingan latar belakang dalam konferensi video.
Autoencoder yang jarang
Autoencoder renggang membatasi jumlah neuron aktif pada waktu tertentu, sehingga mendorong jaringan untuk mempelajari representasi data yang lebih efisien dibandingkan dengan autoencoder standar. Batasan ketersebaran ini diterapkan melalui penalti yang menghambat pengaktifan lebih banyak neuron daripada ambang batas yang ditentukan. Autoencoder renggang menyederhanakan data berdimensi tinggi sekaligus mempertahankan fitur-fitur penting, menjadikannya berharga untuk tugas-tugas seperti ekstraksi fitur yang dapat diinterpretasikan dan visualisasi kumpulan data yang kompleks.
Autoencoder variasional (VAE)
Tidak seperti autoencoder pada umumnya, VAE menghasilkan data baru dengan mengkodekan fitur dari data pelatihan ke dalam distribusi probabilitas, bukan titik tetap. Dengan mengambil sampel dari distribusi ini, VAE dapat menghasilkan beragam data baru, alih-alih merekonstruksi data asli dari masukan. Kemampuan ini membuat VAE berguna untuk tugas generatif, termasuk pembuatan data sintetik. Misalnya, dalam pembuatan gambar, VAE yang dilatih pada kumpulan data angka tulisan tangan dapat membuat digit baru yang tampak realistis berdasarkan kumpulan pelatihan yang bukan merupakan replika persis.

Autoencoder kontraktif
Autoencoder kontraktif memperkenalkan istilah penalti tambahan selama penghitungan kesalahan rekonstruksi, sehingga mendorong model untuk mempelajari representasi fitur yang tahan terhadap noise. Penalti ini membantu mencegah overfitting dengan mendorong pembelajaran fitur yang invarian terhadap variasi kecil dalam data masukan. Hasilnya, autoencoder kontraktif lebih tahan terhadap noise dibandingkan autoencoder standar.
Autoencoder konvolusional (CAE)
CAE menggunakan lapisan konvolusional untuk menangkap hierarki dan pola spasial dalam data berdimensi tinggi. Penggunaan lapisan konvolusional membuat CAE sangat cocok untuk memproses data gambar. CAE biasanya digunakan dalam tugas-tugas seperti kompresi gambar dan deteksi anomali pada gambar.
Penerapan autoencoder di AI
Autoencoder memiliki beberapa aplikasi, seperti reduksi dimensi, denoising gambar, dan deteksi anomali.
Pengurangan dimensi
Autoencoder adalah alat yang efektif untuk mengurangi dimensi data masukan sambil mempertahankan fitur-fitur utama. Proses ini berguna untuk tugas-tugas seperti memvisualisasikan kumpulan data berdimensi tinggi dan mengompresi data. Dengan menyederhanakan data, pengurangan dimensi juga meningkatkan efisiensi komputasi, menurunkan ukuran dan kompleksitas.
Deteksi anomali
Dengan mempelajari fitur-fitur utama kumpulan data target, pembuat enkode otomatis dapat membedakan antara data normal dan anomali saat diberikan masukan baru. Penyimpangan dari kondisi normal ditandai dengan tingkat kesalahan rekonstruksi yang lebih tinggi dari normalnya. Dengan demikian, autoencoder dapat diterapkan pada beragam domain seperti pemeliharaan prediktif dan keamanan jaringan komputer.
Mencela
Autoencoder yang menolak noise dapat membersihkan data yang berisik dengan belajar merekonstruksinya dari input pelatihan yang berisik. Kemampuan ini menjadikan denoising autoencoder berguna untuk tugas-tugas seperti pengoptimalan gambar, termasuk meningkatkan kualitas foto buram. Autoencoder denoising juga berguna dalam pemrosesan sinyal, di mana mereka dapat membersihkan sinyal-sinyal yang berisik untuk pemrosesan dan analisis yang lebih efisien.
Keuntungan dari autoencoder
Autoencoder memiliki sejumlah keunggulan utama. Ini termasuk kemampuan untuk belajar dari data yang tidak berlabel, mempelajari fitur secara otomatis tanpa instruksi eksplisit, dan mengekstrak fitur nonlinier.
Mampu belajar dari data yang tidak berlabel
Autoencoder adalah model pembelajaran mesin tanpa pengawasan, yang berarti bahwa mereka dapat mempelajari fitur data mendasar dari data yang tidak berlabel. Kemampuan ini berarti bahwa autoencoder dapat diterapkan pada tugas-tugas yang data berlabelnya mungkin langka atau tidak tersedia.
Pembelajaran fitur otomatis
Teknik ekstraksi fitur standar, seperti analisis komponen utama (PCA), seringkali tidak praktis ketika menangani kumpulan data yang kompleks dan/atau besar. Karena autoencoder dirancang dengan mempertimbangkan tugas-tugas seperti pengurangan dimensi, autoencoder dapat secara otomatis mempelajari fitur dan pola utama dalam data tanpa desain fitur manual.
Ekstraksi fitur nonlinier
Autoencoder dapat menangani hubungan nonlinier dalam data masukan, memungkinkan model menangkap fitur-fitur utama dari representasi data yang lebih kompleks. Kemampuan ini berarti autoencoder memiliki keunggulan dibandingkan model yang hanya dapat bekerja dengan data linier, karena dapat menangani kumpulan data yang lebih kompleks.
Keterbatasan autoencoder
Seperti model ML lainnya, autoencoder memiliki kelemahannya sendiri. Hal ini mencakup kurangnya kemampuan interpretasi, kebutuhan akan kumpulan data pelatihan yang besar agar dapat bekerja dengan baik, dan terbatasnya kemampuan generalisasi.
Kurangnya interpretasi
Mirip dengan model ML kompleks lainnya, autoencoder mengalami kekurangan interpretasi, yang berarti sulit untuk memahami hubungan antara data masukan dan keluaran model. Dalam autoencoder, kurangnya interpretabilitas ini terjadi karena autoencoder secara otomatis mempelajari fitur dibandingkan dengan model tradisional, yang fiturnya ditentukan secara eksplisit. Representasi fitur yang dihasilkan mesin ini seringkali sangat abstrak dan cenderung tidak memiliki fitur yang dapat diinterpretasikan oleh manusia, sehingga sulit untuk memahami arti setiap komponen dalam representasi tersebut.
Memerlukan kumpulan data pelatihan yang besar
Autoencoder biasanya memerlukan kumpulan data pelatihan yang besar untuk mempelajari representasi fitur data utama yang dapat digeneralisasikan. Mengingat kumpulan data pelatihan yang kecil, pembuat enkode otomatis mungkin cenderung melakukan overfit, sehingga menghasilkan generalisasi yang buruk saat disajikan dengan data baru. Sebaliknya, kumpulan data yang besar memberikan keragaman yang diperlukan bagi autoencoder untuk mempelajari fitur data yang dapat diterapkan di berbagai skenario.
Generalisasi terbatas atas data baru
Autoencoder yang dilatih pada satu kumpulan data sering kali memiliki kemampuan generalisasi yang terbatas, artinya mereka gagal beradaptasi dengan kumpulan data baru. Keterbatasan ini terjadi karena autoencoder diarahkan pada rekonstruksi data berdasarkan fitur-fitur yang menonjol dari kumpulan data tertentu. Oleh karena itu, pembuat enkode otomatis umumnya membuang detail lebih kecil dari data selama pelatihan dan tidak dapat menangani data yang tidak sesuai dengan representasi fitur umum.