
Apa Itu Pohon Keputusan dalam Pembelajaran Mesin?
Diterbitkan: 2024-08-14Pohon keputusan adalah salah satu alat paling umum dalam perangkat pembelajaran mesin analis data. Dalam panduan ini, Anda akan mempelajari apa itu pohon keputusan, cara pembuatannya, berbagai penerapan, manfaat, dan banyak lagi.
Daftar isi
- Apa itu pohon keputusan?
- Terminologi pohon keputusan
- Jenis pohon keputusan
- Cara kerja pohon keputusan
- Aplikasi
- Keuntungan
- Kekurangan
Apa itu pohon keputusan?
Dalam pembelajaran mesin (ML), pohon keputusan adalah algoritma pembelajaran terawasi yang menyerupai diagram alur atau diagram keputusan. Tidak seperti banyak algoritme pembelajaran terawasi lainnya, pohon keputusan dapat digunakan untuk tugas klasifikasi dan regresi. Ilmuwan dan analis data sering kali menggunakan pohon keputusan saat mengeksplorasi kumpulan data baru karena mudah dibuat dan diinterpretasikan. Selain itu, pohon keputusan dapat membantu mengidentifikasi fitur data penting yang mungkin berguna saat menerapkan algoritme ML yang lebih kompleks.
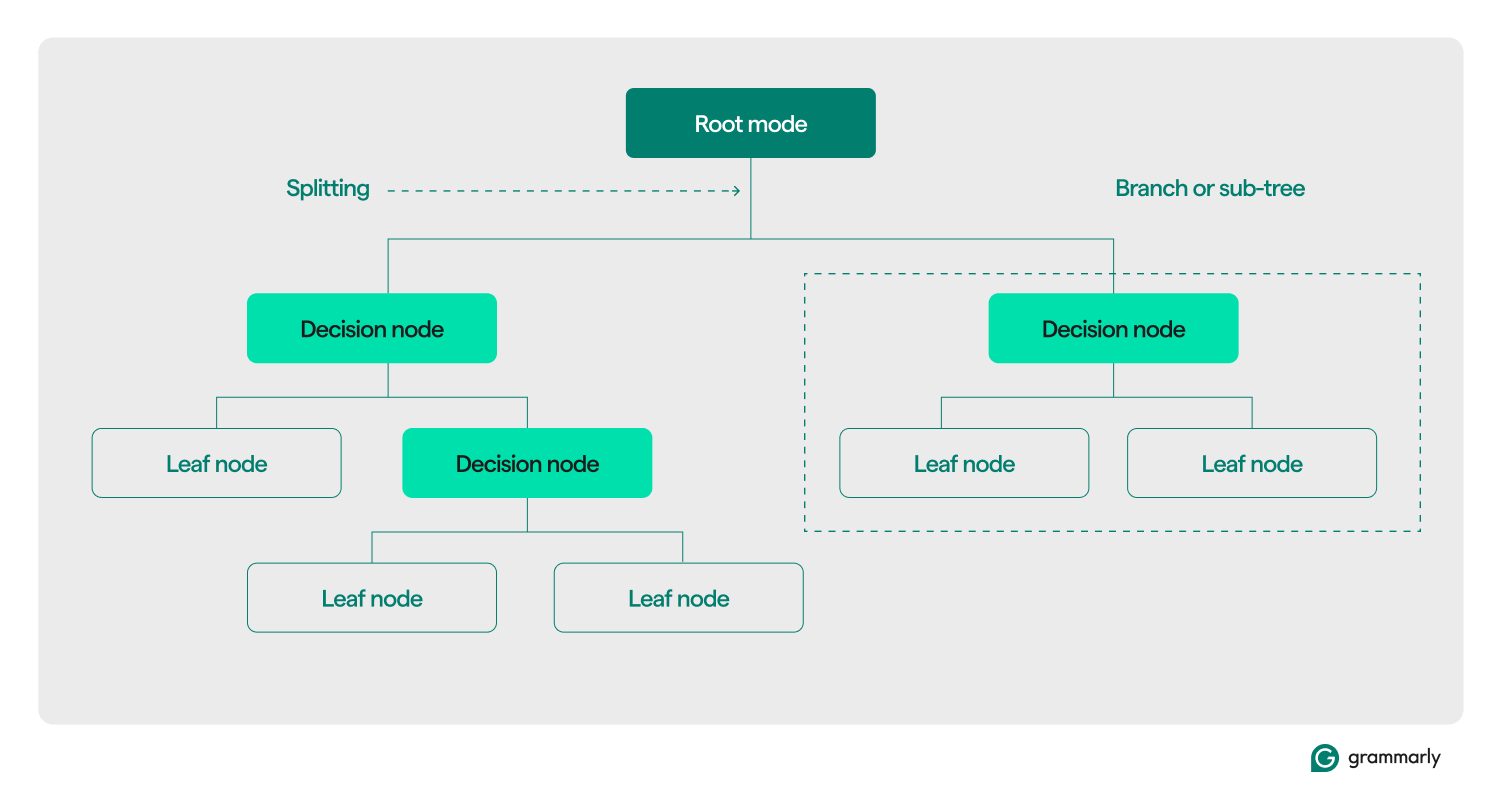
Terminologi pohon keputusan
Secara struktural, pohon keputusan biasanya terdiri dari tiga komponen: simpul akar, simpul daun, dan simpul keputusan (atau internal). Sama seperti flowchart atau pohon pada domain lain, keputusan dalam sebuah pohon biasanya bergerak dalam satu arah (baik ke bawah maupun ke atas), dimulai dari simpul akar, melewati beberapa simpul keputusan, dan berakhir pada simpul daun tertentu. Setiap node daun menghubungkan subset data pelatihan ke label. Pohon tersebut dirakit melalui proses pelatihan dan pengoptimalan ML, dan setelah dibuat, pohon tersebut dapat diterapkan ke berbagai kumpulan data.
Berikut penjelasan lebih dalam tentang terminologi lainnya:
- Node akar:Node yang menampung pertanyaan pertama dari serangkaian pertanyaan yang akan ditanyakan oleh pohon keputusan tentang data. Node tersebut akan terhubung ke setidaknya satu (tetapi biasanya dua atau lebih) node keputusan atau node daun.
- Node keputusan (atau node internal):Node tambahan yang berisi pertanyaan. Node keputusan akan berisi satu pertanyaan tentang data dan mengarahkan aliran data ke salah satu turunannya berdasarkan respons.
- Anak-anak:Satu atau lebih simpul yang ditunjuk oleh akar atau simpul keputusan. Mereka mewakili daftar pilihan berikutnya yang dapat diambil oleh proses pengambilan keputusan saat menganalisis data.
- Node daun (atau node terminal):Node yang menunjukkan proses pengambilan keputusan telah selesai. Setelah proses pengambilan keputusan mencapai node daun, proses tersebut akan mengembalikan nilai dari node daun sebagai outputnya.
- Label (kelas, kategori):Umumnya, string yang diasosiasikan oleh node daun dengan beberapa data pelatihan. Misalnya, sebuah daun mungkin mengaitkan label “Pelanggan yang puas” dengan sekumpulan pelanggan tertentu yang disajikan dengan algoritma pelatihan ML pohon keputusan.
- Cabang (atau sub-pohon):Ini adalah kumpulan node yang terdiri dari node keputusan di titik mana pun di pohon, bersama dengan semua turunannya dan turunannya, hingga ke node daun.
- Pemangkasan:Operasi pengoptimalan yang biasanya dilakukan pada pohon untuk membuatnya lebih kecil dan membantunya mengembalikan keluaran lebih cepat. Pemangkasan biasanya mengacu pada “pasca pemangkasan”, yang melibatkan penghapusan node atau cabang secara algoritmik setelah proses pelatihan ML membangun pohon. “Pra-pemangkasan” mengacu pada penetapan batas sewenang-wenang mengenai seberapa dalam atau besar pohon keputusan dapat tumbuh selama pelatihan. Kedua proses tersebut menerapkan kompleksitas maksimum untuk pohon keputusan, biasanya diukur dengan kedalaman atau tinggi maksimumnya. Pengoptimalan yang kurang umum termasuk membatasi jumlah maksimum simpul keputusan atau simpul daun.
- Pemisahan:Langkah transformasi inti yang dilakukan pada pohon keputusan selama pelatihan. Ini melibatkan pembagian akar atau simpul keputusan menjadi dua atau lebih sub-node.
- Klasifikasi:Algoritme ML yang mencoba mencari tahu mana (dari daftar kelas, kategori, atau label yang konstan dan terpisah) yang paling mungkin diterapkan pada suatu data. Ini mungkin mencoba menjawab pertanyaan seperti “Hari apa dalam seminggu yang terbaik untuk memesan penerbangan?” Lebih lanjut tentang klasifikasi di bawah.
- Regresi:Algoritme ML yang mencoba memprediksi nilai kontinu, yang mungkin tidak selalu memiliki batas. Ini mungkin mencoba menjawab (atau memprediksi jawabannya) atas pertanyaan seperti “Berapa banyak orang yang kemungkinan akan memesan penerbangan Selasa depan?” Kita akan membahas lebih lanjut tentang pohon regresi di bagian berikutnya.
Jenis pohon keputusan
Pohon keputusan biasanya dikelompokkan menjadi dua kategori: pohon klasifikasi dan pohon regresi. Pohon tertentu dapat dibuat untuk diterapkan pada klasifikasi, regresi, atau kedua kasus penggunaan. Kebanyakan pohon keputusan modern menggunakan algoritma CART (Classification and Regression Trees), yang dapat melakukan kedua jenis tugas tersebut.
Pohon klasifikasi
Pohon klasifikasi, jenis pohon keputusan yang paling umum, berupaya memecahkan masalah klasifikasi. Dari daftar kemungkinan jawaban atas sebuah pertanyaan (sering kali sesederhana “ya” atau “tidak”), pohon klasifikasi akan memilih jawaban yang paling mungkin setelah menanyakan beberapa pertanyaan tentang data yang disajikan. Mereka biasanya diimplementasikan sebagai pohon biner, yang berarti setiap simpul keputusan mempunyai tepat dua anak.
Pohon klasifikasi mungkin mencoba menjawab pertanyaan pilihan ganda seperti “Apakah pelanggan ini puas?” atau “Toko fisik manakah yang kemungkinan besar akan dikunjungi oleh klien ini?” atau “Apakah besok adalah hari yang baik untuk pergi ke lapangan golf?”
Dua metode paling umum untuk mengukur kualitas pohon klasifikasi didasarkan pada perolehan informasi dan entropi:
- Perolehan informasi:Efisiensi sebuah pohon meningkat ketika ia menanyakan lebih sedikit pertanyaan sebelum mencapai sebuah jawaban. Perolehan informasi mengukur seberapa “cepat” sebuah pohon dapat memperoleh jawaban dengan mengevaluasi seberapa banyak informasi yang dipelajari tentang sepotong data di setiap simpul keputusan. Ini menilai apakah pertanyaan yang paling penting dan berguna ditanyakan terlebih dahulu di pohon.
- Entropi:Akurasi sangat penting untuk label pohon keputusan. Metrik entropi mengukur akurasi ini dengan mengevaluasi label yang dihasilkan oleh pohon. Mereka menilai seberapa sering suatu data acak berakhir dengan label yang salah dan kesamaan di antara semua data pelatihan yang menerima label yang sama.
Pengukuran kualitas pohon yang lebih maju mencakupindeks gini,rasio penguatan,evaluasi chi-kuadrat, dan berbagai pengukuran untuk pengurangan varians.
Pohon regresi
Pohon regresi biasanya digunakan dalam analisis regresi untuk analisis statistik tingkat lanjut atau untuk memprediksi data dari rentang yang berkelanjutan dan berpotensi tidak terbatas. Mengingat serangkaian pilihan yang berkesinambungan (misalnya, nol hingga tak terhingga pada skala bilangan real), pohon regresi mencoba memprediksi kecocokan yang paling mungkin untuk suatu data tertentu setelah mengajukan serangkaian pertanyaan. Setiap pertanyaan mempersempit kemungkinan jawaban. Misalnya, pohon regresi dapat digunakan untuk memprediksi skor kredit, pendapatan dari suatu lini bisnis, atau jumlah interaksi pada video pemasaran.
Keakuratan pohon regresi biasanya dievaluasi menggunakan metrik sepertimean square errorataumean absolute error, yang menghitung seberapa jauh selisih serangkaian prediksi tertentu dibandingkan dengan nilai sebenarnya.
Cara kerja pohon keputusan
Sebagai contoh pembelajaran yang diawasi, pohon keputusan mengandalkan data yang diformat dengan baik untuk pelatihan. Sumber data biasanya berisi daftar nilai yang harus dipelajari model untuk diprediksi atau diklasifikasi. Setiap nilai harus memiliki label terlampir dan daftar fitur terkait—properti yang harus dipelajari model untuk dikaitkan dengan label.

Bangunan atau pelatihan
Selama proses pelatihan, node keputusan di pohon keputusan dipecah secara rekursif menjadi node yang lebih spesifik berdasarkan satu atau lebih algoritma pelatihan. Deskripsi proses pada tingkat manusia mungkin terlihat seperti ini:
- Mulailah dengan simpul akaryang terhubung ke seluruh set pelatihan.
- Pisahkan simpul akar:Dengan menggunakan pendekatan statistik, tetapkan keputusan ke simpul akar berdasarkan salah satu fitur data dan distribusikan data pelatihan ke setidaknya dua simpul daun terpisah, yang terhubung sebagai anak ke akar.
- Terapkan langkah kedua secara rekursifpada masing-masing anak, ubah mereka dari simpul daun menjadi simpul keputusan. Berhenti ketika batas tertentu tercapai (misalnya, tinggi/kedalaman pohon, ukuran kualitas anak-anak di setiap daun pada setiap simpul, dll.) atau jika Anda kehabisan data (misalnya, setiap daun berisi data poin yang berhubungan dengan tepat satu label).
Keputusan fitur mana yang perlu dipertimbangkan pada setiap node berbeda untuk klasifikasi, regresi, dan kasus penggunaan klasifikasi dan regresi gabungan. Ada banyak algoritma yang dapat dipilih untuk setiap skenario. Algoritma yang umum meliputi:
- ID3 (klasifikasi):Mengoptimalkan entropi dan perolehan informasi
- C4.5 (klasifikasi):Versi ID3 yang lebih kompleks, menambahkan normalisasi pada perolehan informasi
- CART (klasifikasi/regresi): “Pohon klasifikasi dan regresi”; algoritma serakah yang mengoptimalkan pengotor minimum dalam kumpulan hasil
- CHAID (klasifikasi/regresi): “Deteksi interaksi otomatis Chi-kuadrat”; menggunakan pengukuran chi-kuadrat, bukan entropi dan perolehan informasi
- MARS (klasifikasi/regresi): Menggunakan pendekatan linier sepotong-sepotong untuk menangkap non-linearitas
Rezim pelatihan yang umum adalah hutan acak. Hutan acak, atau hutan keputusan acak, adalah sistem yang membangun banyak pohon keputusan terkait. Beberapa versi pohon mungkin dilatih secara paralel menggunakan kombinasi algoritma pelatihan. Berdasarkan berbagai pengukuran kualitas pohon, sebagian dari pohon tersebut akan digunakan untuk menghasilkan jawaban. Untuk kasus penggunaan klasifikasi, kelas yang dipilih berdasarkan jumlah pohon terbanyak akan dikembalikan sebagai jawabannya. Untuk kasus penggunaan regresi, jawabannya dikumpulkan, biasanya sebagai rata-rata atau prediksi rata-rata dari masing-masing pohon.
Mengevaluasi dan menggunakan pohon keputusan
Setelah pohon keputusan dibangun, pohon keputusan dapat mengklasifikasikan data baru atau memprediksi nilai untuk kasus penggunaan tertentu. Penting untuk menjaga metrik pada kinerja pohon dan menggunakannya untuk mengevaluasi akurasi dan frekuensi kesalahan. Jika model menyimpang terlalu jauh dari performa yang diharapkan, mungkin ini saatnya untuk melatih ulang model tersebut pada data baru atau mencari sistem ML lain untuk diterapkan pada kasus penggunaan tersebut.
Penerapan pohon keputusan di ML
Pohon keputusan memiliki penerapan yang luas di berbagai bidang. Berikut beberapa contoh untuk menggambarkan keserbagunaannya:
Pengambilan keputusan pribadi yang terinformasi
Seseorang mungkin melacak data tentang, misalnya, restoran yang mereka kunjungi. Mereka mungkin melacak detail yang relevan—seperti waktu perjalanan, waktu tunggu, masakan yang ditawarkan, jam buka, skor ulasan rata-rata, biaya, dan kunjungan terakhir, ditambah dengan skor kepuasan atas kunjungan individu ke restoran tersebut. Pohon keputusan dapat dilatih berdasarkan data ini untuk memprediksi kemungkinan skor kepuasan untuk restoran baru.
Hitung probabilitas seputar perilaku pelanggan
Sistem dukungan pelanggan mungkin menggunakan pohon keputusan untuk memprediksi atau mengklasifikasikan kepuasan pelanggan. Pohon keputusan dapat dilatih untuk memprediksi kepuasan pelanggan berdasarkan berbagai faktor, seperti apakah pelanggan menghubungi dukungan atau melakukan pembelian berulang atau berdasarkan tindakan yang dilakukan dalam aplikasi. Selain itu, ini dapat mencakup hasil survei kepuasan atau umpan balik pelanggan lainnya.
Membantu menginformasikan keputusan bisnis
Untuk keputusan bisnis tertentu yang memiliki banyak data historis, pohon keputusan dapat memberikan perkiraan atau prediksi untuk langkah selanjutnya. Misalnya, sebuah bisnis yang mengumpulkan informasi demografis dan geografis tentang pelanggannya dapat melatih pohon keputusan untuk mengevaluasi lokasi geografis baru mana yang mungkin menguntungkan atau sebaiknya dihindari. Pohon keputusan juga dapat membantu menentukan batasan klasifikasi terbaik untuk data demografi yang ada, seperti mengidentifikasi rentang usia yang perlu dipertimbangkan secara terpisah saat mengelompokkan pelanggan.
Pemilihan fitur untuk ML tingkat lanjut dan kasus penggunaan lainnya
Struktur pohon keputusan dapat dibaca dan dipahami manusia. Setelah pohon dibuat, dimungkinkan untuk mengidentifikasi fitur mana yang paling relevan dengan kumpulan data dan urutannya. Informasi ini dapat memandu pengembangan sistem ML atau algoritma keputusan yang lebih kompleks. Misalnya, jika sebuah bisnis belajar dari pohon keputusan bahwa pelanggan memprioritaskan biaya suatu produk di atas segalanya, bisnis tersebut dapat memfokuskan sistem ML yang lebih kompleks pada wawasan ini atau mengabaikan biaya saat mengeksplorasi fitur yang lebih beragam.
Keuntungan pohon keputusan di ML
Pohon keputusan menawarkan beberapa keuntungan signifikan yang menjadikannya pilihan populer dalam aplikasi ML. Berikut adalah beberapa manfaat utama:
Cepat dan mudah dibuat
Pohon keputusan adalah salah satu algoritma ML yang paling matang dan dipahami dengan baik. Mereka tidak bergantung pada perhitungan yang rumit, dan dapat dibuat dengan cepat dan mudah. Selama informasi yang diperlukan tersedia, pohon keputusan adalah langkah pertama yang mudah untuk diambil ketika mempertimbangkan solusi ML untuk suatu masalah.
Mudah dipahami manusia
Keluaran dari pohon keputusan sangat mudah dibaca dan diinterpretasikan. Representasi grafis dari pohon keputusan tidak bergantung pada pemahaman statistik tingkat lanjut. Dengan demikian, pohon keputusan dan representasinya dapat digunakan untuk menafsirkan, menjelaskan, dan mendukung hasil analisis yang lebih kompleks. Pohon keputusan sangat baik dalam menemukan dan menyoroti beberapa properti tingkat tinggi dari kumpulan data tertentu.
Diperlukan pemrosesan data minimal
Pohon keputusan dapat dibangun dengan mudah pada data yang tidak lengkap atau data yang menyertakan outlier. Mengingat data dihiasi dengan fitur-fitur menarik, algoritme pohon keputusan cenderung tidak terpengaruh sebanyak algoritme ML lainnya jika algoritme tersebut memasukkan data yang belum diproses sebelumnya.
Kekurangan pohon keputusan di ML
Meskipun pohon keputusan menawarkan banyak manfaat, pohon keputusan juga memiliki beberapa kelemahan:
Rentan terhadap overfitting
Pohon keputusan rentan terhadap overfitting, yang terjadi saat model mempelajari noise dan detail dalam data pelatihan, sehingga mengurangi performanya pada data baru. Misalnya, jika data pelatihan tidak lengkap atau jarang, perubahan kecil pada data dapat menghasilkan struktur pohon yang berbeda secara signifikan. Teknik tingkat lanjut seperti pemangkasan atau pengaturan kedalaman maksimum dapat meningkatkan perilaku pohon. Dalam praktiknya, pohon keputusan sering kali perlu diperbarui dengan informasi baru, yang dapat mengubah strukturnya secara signifikan.
Skalabilitas yang buruk
Selain kecenderungannya untuk melakukan overfit, pohon keputusan juga menghadapi permasalahan lebih lanjut yang memerlukan lebih banyak data secara signifikan. Dibandingkan dengan algoritme lain, waktu pelatihan untuk pohon keputusan meningkat pesat seiring bertambahnya volume data. Untuk kumpulan data yang lebih besar yang mungkin memiliki properti tingkat tinggi yang signifikan untuk dideteksi, pohon keputusan bukanlah pilihan yang tepat.
Tidak efektif untuk regresi atau kasus penggunaan berkelanjutan
Pohon keputusan tidak mempelajari distribusi data yang kompleks dengan baik. Mereka membagi ruang fitur menurut garis yang mudah dipahami tetapi sederhana secara matematis. Untuk masalah kompleks di mana outlier relevan, regresi, dan kasus penggunaan berkelanjutan, hal ini sering kali menghasilkan performa yang jauh lebih buruk dibandingkan model dan teknik ML lainnya.