
Skor F1 dalam Pembelajaran Mesin: Cara Menghitung, Menerapkan, dan Menggunakannya Secara Efektif
Diterbitkan: 2025-02-10Skor F1 adalah metrik yang kuat untuk mengevaluasi model Machine Learning (ML) yang dirancang untuk melakukan klasifikasi biner atau multiclass. Artikel ini akan menjelaskan apa skor F1, mengapa ini penting, bagaimana hal itu dihitung, dan penerapannya, manfaat, dan keterbatasan.
Daftar isi
- Apa itu skor F1?
- Cara menghitung skor F1
- Skor f1 vs akurasi
- Aplikasi skor F1
- Manfaat dari skor F1
- Keterbatasan skor F1
Apa itu skor F1?
Praktisi ML menghadapi tantangan umum ketika membangun model klasifikasi: melatih model untuk menangkap semua kasus sambil menghindari alarm palsu. Ini sangat penting dalam aplikasi penting seperti deteksi penipuan keuangan dan diagnosis medis, di mana alarm palsu dan klasifikasi penting yang hilang memiliki konsekuensi serius. Mencapai keseimbangan yang tepat sangat penting ketika berhadapan dengan dataset yang tidak seimbang, di mana kategori seperti transaksi penipuan jauh lebih jarang daripada kategori lainnya (transaksi yang sah).
Ketepatan dan penarikan
Untuk mengukur kualitas kinerja model, skor F1 menggabungkan dua metrik terkait:
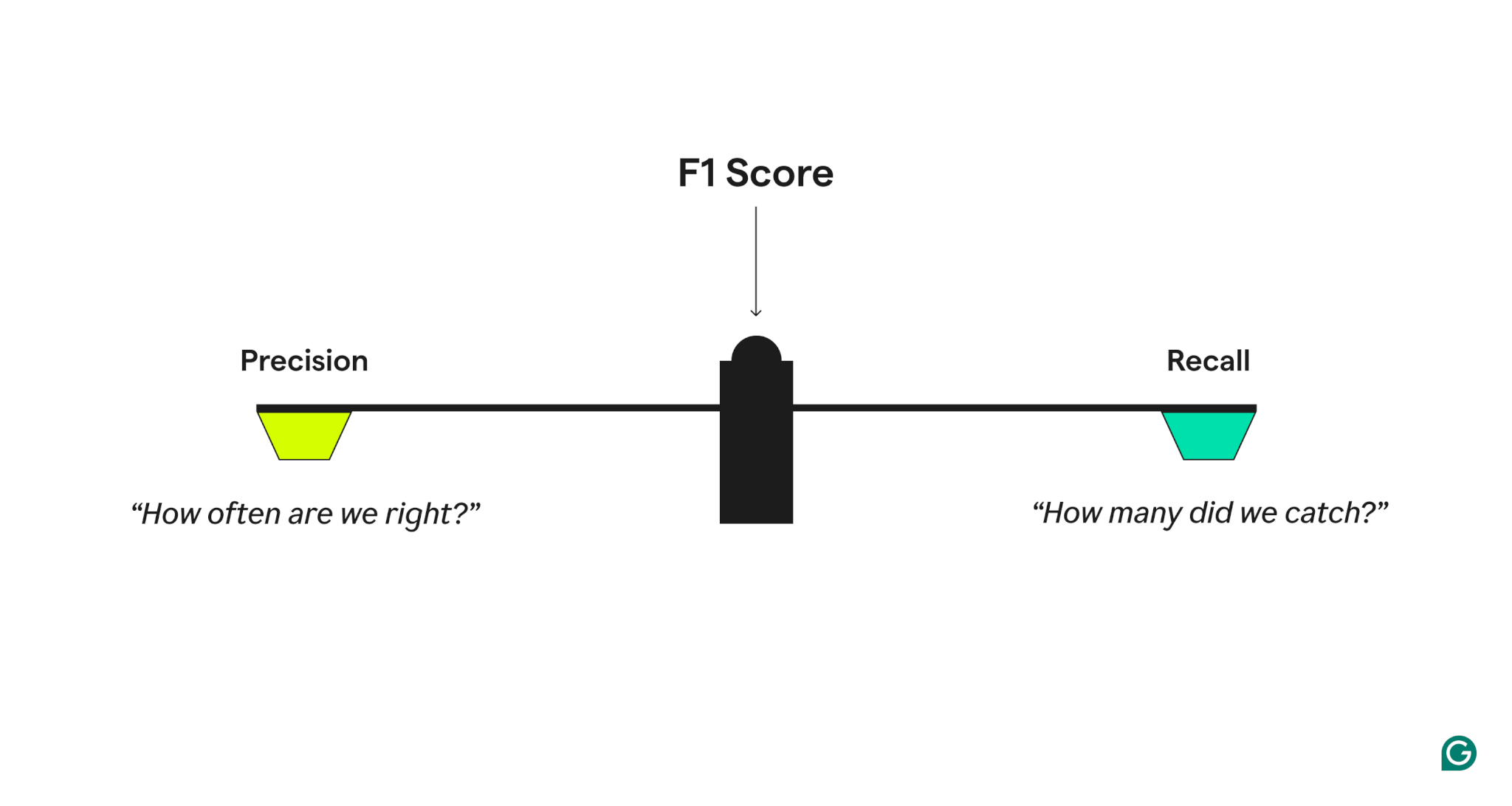
- Presisi, jawaban mana, “Ketika model memprediksi kasus positif, seberapa sering itu benar?”
- Ingat, jawaban mana, “Dari semua kasus positif yang sebenarnya, berapa banyak model yang diidentifikasi dengan benar?”
Sebuah model dengan presisi tinggi tetapi penarikan rendah terlalu hati -hati, kehilangan banyak positif sejati, sementara satu dengan penarikan tinggi tetapi presisi rendah terlalu agresif, menghasilkan banyak positif palsu. Skor F1 memberikan keseimbangan dengan mengambil rata -rata harmonik dari presisi dan penarikan, yang memberi bobot lebih banyak untuk nilai yang lebih rendah dan memastikan bahwa model berkinerja baik pada kedua metrik daripada unggul hanya dalam satu.
Contoh presisi dan recall
Untuk lebih memahami ketepatan dan penarikan kembali, pertimbangkan sistem deteksi spam. Jika sistem memiliki tingkat tinggi email yang ditandai dengan benar sebagai spam, ini berarti memiliki presisi tinggi. Misalnya, jika sistem menandai 100 email sebagai spam, dan 90 di antaranya sebenarnya spam, presisi adalah 90%. Penarikan yang tinggi, di sisi lain, berarti sistem menangkap sebagian besar email spam yang sebenarnya. Misalnya, jika ada 200 email spam aktual dan sistem kami menangkap 90 dari mereka, penarikan kembali adalah 45%.
Varian skor F1
Dalam sistem klasifikasi multiclass atau skenario dengan kebutuhan spesifik, skor F1 dapat dihitung dengan cara yang berbeda, tergantung pada faktor apa yang penting:
- Makro-F1:Menghitung skor F1 secara terpisah untuk setiap kelas dan mengambil rata-rata
- Micro-F1:Menghitung penarikan dan ketepatan atas semua prediksi
- Weighted-F1: Mirip dengan makro-F1, tetapi kelas tertimbang berdasarkan frekuensi
Di luar skor F1: keluarga f-score
Skor F1 adalah bagian dari keluarga metrik yang lebih besar yang disebut F-Scores. Skor ini menawarkan berbagai cara untuk berbobot presisi dan penarikan kembali:
- F2:menempatkan penekanan yang lebih besar pada penarikan kembali, yang berguna saat negatif palsu mahal
- F0.5:menempatkan penekanan yang lebih besar pada presisi, yang berguna saat positif palsu mahal
Cara menghitung skor F1
Skor F1 secara matematis didefinisikan sebagai rata -rata harmonik presisi dan penarikan. Meskipun ini mungkin terdengar kompleks, proses perhitungan langsung ketika dipecah menjadi langkah yang jelas.
Formula untuk skor F1:

Sebelum menyelam ke langkah -langkah untuk menghitung F1, penting untuk memahami komponen kunci dari apa yang disebutmatriks kebingungan, yang digunakan untuk mengatur hasil klasifikasi:
- True Positif (TP):Jumlah kasus yang diidentifikasi dengan benar sebagai positif
- False Positif (FP):Jumlah kasus yang salah diidentifikasi sebagai positif
- False Negatives (FN):Jumlah kasus yang terlewatkan (positif aktual yang tidak diidentifikasi)
Proses umum melibatkan pelatihan model, menguji prediksi dan mengatur hasil, menghitung presisi dan penarikan, dan menghitung skor F1.
Langkah 1: Latih model klasifikasi
Pertama, model harus dilatih untuk membuat klasifikasi biner atau multiclass. Ini berarti bahwa model harus dapat mengklasifikasikan kasus sebagai milik salah satu dari dua kategori. Contohnya termasuk "spam/bukan spam" dan "penipuan/bukan penipuan."
Langkah 2: Prediksi tes dan mengatur hasil
Selanjutnya, gunakan model untuk melakukan klasifikasi pada dataset terpisah yang tidak digunakan sebagai bagian dari pelatihan. Mengatur hasil ke dalam matriks kebingungan. Matriks ini menunjukkan:
- TP: Berapa banyak prediksi yang benar
- FP: Berapa banyak prediksi positif yang salah
- FN: Berapa banyak kasus positif yang terlewatkan
Matriks kebingungan memberikan gambaran tentang kinerja model.
Langkah 3: Hitung presisi
Menggunakan matriks kebingungan, presisi dihitung dengan rumus ini:

Misalnya, jika model deteksi spam mengidentifikasi 90 email spam (TP) dengan benar tetapi secara tidak benar menandai 10 email nonspam (FP), presisi adalah 0,90.

Langkah 4: Hitung Recall
Selanjutnya, hitung penarikan menggunakan rumus:

Menggunakan contoh deteksi spam, jika ada 200 total email spam, dan model menangkap 90 dari mereka (TP) sementara hilang 110 (FN), penarikan kembali 0,45.

Langkah 5: Hitung skor F1
Dengan nilai presisi dan penarikan di tangan, skor F1 dapat dihitung.
Skor F1 berkisar dari 0 hingga 1. Saat menafsirkan skor, pertimbangkan tolok ukur umum ini:
- 0.9 atau lebih tinggi:Model ini berkinerja hebat, tetapi harus diperiksa untuk overfitting.
- 0,7 hingga 0,9:kinerja yang baik untuk sebagian besar aplikasi
- 0,5 hingga 0,7:Kinerja OK, tetapi model dapat menggunakan peningkatan.
- 0,5 atau kurang:Model berkinerja buruk dan membutuhkan perbaikan serius.
Menggunakan contoh deteksi spam perhitungan untuk presisi dan penarikan, skor F1 akan 0,60 atau 60%.


Dalam hal ini, skor F1 menunjukkan bahwa, bahkan dengan presisi tinggi, penarikan yang lebih rendah mempengaruhi kinerja keseluruhan. Ini menunjukkan bahwa ada ruang untuk perbaikan dalam menangkap lebih banyak email spam.
Skor f1 vs akurasi
Sementara F1 danakurasimengukur kinerja model, skor F1 memberikan ukuran yang lebih bernuansa. Akurasi hanya menghitung persentase prediksi yang benar. Namun, hanya mengandalkan keakuratan untuk mengukur kinerja model dapat menjadi masalah ketika jumlah contoh satu kategori dalam dataset secara signifikan mengalahkan kategori lainnya. Masalah ini disebut sebagaiparadoks akurasi.
Untuk memahami masalah ini, pertimbangkan contoh sistem deteksi spam. Misalkan sistem email menerima 1.000 email setiap hari, tetapi hanya 10 di antaranya yang sebenarnya spam. Jika deteksi spam hanya mengklasifikasikan setiap email sebagai bukan spam, itu masih akan mencapai akurasi 99%. Ini karena 990 prediksi dari 1.000 benar, meskipun modelnya sebenarnya tidak berguna dalam hal deteksi spam. Jelas, akurasi tidak memberikan gambaran yang akurat tentang kualitas model.
Skor F1 menghindari masalah ini dengan menggabungkan pengukuran presisi dan penarikan. Oleh karena itu, F1 harus digunakan alih -alih akurasi dalam kasus -kasus berikut:
- Datasetnya tidak seimbang.Ini umum di bidang seperti diagnosis kondisi medis yang tidak jelas atau deteksi spam, di mana satu kategori relatif jarang.
- FN dan FP keduanya penting.Misalnya, tes skrining medis berupaya menyeimbangkan masalah aktual dengan tidak mengangkat alarm palsu.
- Model perlu mencapai keseimbangan antara terlalu agresif dan terlalu berhati -hati.Misalnya, dalam penyaringan spam, filter yang terlalu hati -hati mungkin membiarkan terlalu banyak spam (penarikan rendah) tetapi jarang membuat kesalahan (presisi tinggi). Di sisi lain, filter yang terlalu agresif dapat memblokir email nyata (presisi rendah) bahkan jika itu menangkap semua spam (penarikan tinggi).
Aplikasi skor F1
Skor F1 memiliki berbagai aplikasi di berbagai industri di mana klasifikasi seimbang sangat penting. Aplikasi ini termasuk deteksi penipuan keuangan, diagnosis medis, dan moderasi konten.
Deteksi Penipuan Keuangan
Model yang dirancang untuk mendeteksi penipuan keuangan adalah kategori sistem yang cocok untuk pengukuran menggunakan skor F1. Perusahaan keuangan sering memproses jutaan atau miliaran transaksi setiap hari, dengan kasus penipuan yang sebenarnya relatif jarang. Untuk alasan ini, sistem deteksi penipuan perlu menangkap sebanyak mungkin transaksi curang sambil secara bersamaan meminimalkan jumlah alarm palsu dan mengakibatkan ketidaknyamanan bagi pelanggan. Mengukur skor F1 dapat membantu lembaga keuangan menentukan seberapa baik sistem mereka menyeimbangkan pilar kembar pencegahan penipuan dan pengalaman pelanggan yang baik.
Diagnosis medis
Dalam diagnosis dan pengujian medis, FN dan FP keduanya memiliki konsekuensi serius. Pertimbangkan contoh model yang dirancang untuk mendeteksi bentuk kanker langka. Salah mendiagnosis pasien yang sehat dapat menyebabkan stres dan perawatan yang tidak perlu, sementara kehilangan kasus kanker yang sebenarnya akan memiliki konsekuensi yang mengerikan bagi pasien. Dengan kata lain, model perlu memiliki presisi tinggi dan penarikan tinggi, yang merupakan sesuatu yang dapat diukur oleh skor F1.
Moderasi konten
Konten moderat adalah tantangan umum di forum online, platform media sosial, dan pasar online. Untuk mencapai keselamatan platform tanpa overcensoring, sistem ini harus menyeimbangkan presisi dan penarikan kembali. Skor F1 dapat membantu platform menentukan seberapa baik sistem mereka menyeimbangkan kedua faktor ini.
Manfaat dari skor F1
Selain secara umum memberikan tampilan yang lebih bernuansa kinerja model daripada akurasi, skor F1 memberikan beberapa keunggulan utama saat mengevaluasi kinerja model klasifikasi. Manfaat ini termasuk pelatihan dan optimalisasi model yang lebih cepat, pengurangan biaya pelatihan, dan menangkap overfitting lebih awal.
Pelatihan dan optimasi model yang lebih cepat
Skor F1 dapat membantu mempercepat pelatihan model dengan memberikan metrik referensi yang jelas yang dapat digunakan untuk memandu optimasi. Alih-alih tuning recall dan precision secara terpisah, yang umumnya melibatkan pertukaran yang kompleks, praktisi ML dapat fokus pada peningkatan skor F1. Dengan pendekatan ramping ini, parameter model optimal dapat diidentifikasi dengan cepat.
Mengurangi biaya pelatihan
Skor F1 dapat membantu praktisi ML membuat keputusan berdasarkan informasi tentang ketika model siap untuk ditempatkan dengan memberikan ukuran model model tunggal yang bernuansa. Dengan informasi ini, praktisi dapat menghindari siklus pelatihan yang tidak perlu, investasi dalam sumber daya komputasi, dan harus memperoleh atau membuat data pelatihan tambahan. Secara keseluruhan, ini dapat menyebabkan pengurangan biaya yang substansial ketika model klasifikasi pelatihan.
Menangkap overfitting lebih awal
Karena skor F1 mempertimbangkan presisi dan penarikan kembali, itu dapat membantu praktisi ML mengidentifikasi ketika model menjadi terlalu khusus dalam data pelatihan. Masalah ini, yang disebut overfitting, adalah masalah umum dengan model klasifikasi. Skor F1 memberi para praktisi peringatan dini bahwa mereka perlu menyesuaikan pelatihan sebelum model mencapai titik di mana ia tidak dapat menggeneralisasi data dunia nyata.
Keterbatasan skor F1
Terlepas dari banyak manfaatnya, skor F1 memiliki beberapa keterbatasan penting yang harus dipertimbangkan oleh para praktisi. Keterbatasan ini termasuk kurangnya sensitivitas terhadap negatif sejati, tidak cocok untuk beberapa dataset, dan lebih sulit untuk ditafsirkan untuk masalah multiclass.
Kurangnya sensitivitas terhadap negatif sejati
Skor F1 tidak memperhitungkan negatif sejati, yang berarti tidak cocok untuk aplikasi di mana mengukur ini penting. Misalnya, pertimbangkan sistem yang dirancang untuk mengidentifikasi kondisi mengemudi yang aman. Dalam hal ini, mengidentifikasi dengan benar ketika kondisinya benar -benar aman (negatif sejati) sama pentingnya dengan mengidentifikasi kondisi berbahaya. Karena tidak melacak FN, skor F1 tidak akan secara akurat menangkap aspek kinerja model keseluruhan ini.
Tidak cocok untuk beberapa set data
Skor F1 mungkin tidak cocok untuk set data di mana dampak FP dan FN berbeda secara signifikan. Pertimbangkan contoh model skrining kanker. Dalam situasi seperti itu, kehilangan kasus positif (FN) bisa mengancam jiwa, sementara secara salah menemukan kasus positif (FP) hanya mengarah pada pengujian tambahan. Jadi, menggunakan metrik yang dapat ditimbang untuk memperhitungkan biaya ini adalah pilihan yang lebih baik daripada skor F1.
Lebih sulit untuk ditafsirkan untuk masalah multiclass
Sementara variasi seperti skor mikro-F1 dan makro-F1 berarti bahwa skor F1 dapat digunakan untuk mengevaluasi sistem klasifikasi multiclass, menafsirkan metrik agregat ini seringkali lebih kompleks daripada skor F1 biner. Sebagai contoh, skor mikro-F1 mungkin menyembunyikan kinerja yang buruk dalam mengklasifikasikan kelas yang lebih jarang, sedangkan skor makro-F1 mungkin kelebihan berat kelas langka. Mengingat hal ini, bisnis perlu mempertimbangkan apakah perlakuan yang sama terhadap kelas atau kinerja tingkat instance secara keseluruhan lebih penting ketika memilih varian F1 yang tepat untuk model klasifikasi multiclass.