
Apa itu Overfitting dalam Pembelajaran Mesin?
Diterbitkan: 2024-10-15Overfitting adalah masalah umum yang muncul saat melatih model pembelajaran mesin (ML). Hal ini dapat berdampak negatif pada kemampuan model untuk melakukan generalisasi di luar data pelatihan, sehingga menyebabkan prediksi yang tidak akurat dalam skenario dunia nyata. Dalam artikel ini, kita akan membahas apa itu overfitting, bagaimana hal itu terjadi, penyebab umum di baliknya, dan cara efektif untuk mendeteksi dan mencegahnya.
Daftar isi
- Apa itu overfitting?
- Bagaimana overfitting terjadi
- Overfitting vs. underfitting
- Apa yang menyebabkan overfitting?
- Cara mendeteksi overfitting
- Bagaimana menghindari overfitting
- Contoh overfitting
Apa itu overfitting?
Overfitting terjadi ketika model pembelajaran mesin mempelajari pola mendasar dan gangguan dalam data pelatihan, sehingga menjadi terlalu terspesialisasi dalam kumpulan data spesifik tersebut. Fokus yang berlebihan pada detail data pelatihan ini menghasilkan performa yang buruk ketika model diterapkan pada data baru yang belum terlihat, karena model tersebut gagal melakukan generalisasi di luar data yang telah dilatihnya.
Bagaimana overfitting bisa terjadi?
Overfitting terjadi ketika model belajar terlalu banyak dari detail spesifik dan gangguan dalam data pelatihan, sehingga terlalu sensitif terhadap pola yang tidak berguna untuk generalisasi. Misalnya, pertimbangkan model yang dibangun untuk memprediksi kinerja karyawan berdasarkan evaluasi historis. Jika modelnya terlalu cocok, maka model tersebut mungkin terlalu berfokus pada detail yang spesifik dan tidak dapat digeneralisasikan, seperti gaya pemeringkatan yang unik dari mantan manajer atau keadaan tertentu selama siklus peninjauan yang lalu. Daripada mempelajari faktor-faktor yang lebih luas dan bermakna yang berkontribusi terhadap kinerja—seperti keterampilan, pengalaman, atau hasil proyek—model tersebut mungkin kesulitan menerapkan pengetahuannya kepada karyawan baru atau mengembangkan kriteria evaluasi. Hal ini menyebabkan prediksi menjadi kurang akurat ketika model diterapkan pada data yang berbeda dari set pelatihan.
Overfitting vs. underfitting
Berbeda dengan overfitting, underfitting terjadi ketika model terlalu sederhana untuk menangkap pola dasar data. Akibatnya, kinerjanya buruk pada pelatihan dan data baru, sehingga gagal membuat prediksi yang akurat.
Untuk memvisualisasikan perbedaan antara underfitting dan overfitting, bayangkan kita mencoba memprediksi performa atlet berdasarkan tingkat stres seseorang. Kita dapat memplot data dan menunjukkan tiga model yang mencoba memprediksi hubungan ini:

1 Underfitting:Pada contoh pertama, model menggunakan garis lurus untuk membuat prediksi, sedangkan data aktual mengikuti kurva. Model ini terlalu sederhana dan gagal menangkap kompleksitas hubungan antara tingkat stres dan performa atletik. Akibatnya, sebagian besar prediksi tidak akurat, bahkan untuk data pelatihan. Ini tidak sesuai.
2Kesesuaian optimal:Contoh kedua menunjukkan model yang memberikan keseimbangan yang tepat. Ini menangkap tren mendasar dalam data tanpa membuatnya terlalu rumit. Model ini dapat digeneralisasi dengan baik pada data baru karena tidak berupaya menyesuaikan setiap variasi kecil dalam data pelatihan—hanya pola inti.
3Overfitting:Pada contoh terakhir, model menggunakan kurva bergelombang yang sangat kompleks agar sesuai dengan data pelatihan. Meskipun kurva ini sangat akurat untuk data pelatihan, kurva ini juga menangkap noise acak dan outlier yang tidak mewakili hubungan sebenarnya. Model ini overfitting karena sangat disesuaikan dengan data pelatihan sehingga kemungkinan menghasilkan prediksi yang buruk terhadap data baru yang tidak terlihat.
Penyebab umum overfitting
Sekarang kita sudah tahu apa itu overfitting dan mengapa hal itu terjadi, mari kita telusuri beberapa penyebab umum secara lebih detail:
- Data pelatihan tidak mencukupi
- Data yang tidak akurat, salah, atau tidak relevan
- Beban besar
- Latihan berlebihan
- Arsitektur model terlalu canggih
Data pelatihan tidak mencukupi
Jika dataset pelatihan Anda terlalu kecil, data tersebut mungkin hanya mewakili beberapa skenario yang akan ditemui model di dunia nyata. Selama pelatihan, model mungkin cocok dengan data dengan baik. Namun, Anda mungkin melihat ketidakakuratan yang signifikan setelah mengujinya pada data lain. Kumpulan data yang kecil membatasi kemampuan model untuk menggeneralisasi situasi yang tidak terlihat, sehingga rentan terhadap overfitting.
Data yang tidak akurat, salah, atau tidak relevan
Meskipun kumpulan data pelatihan Anda besar, mungkin terdapat kesalahan. Kesalahan ini dapat timbul dari berbagai sumber, seperti peserta yang memberikan informasi palsu dalam survei atau kesalahan pembacaan sensor. Jika model mencoba belajar dari ketidakakuratan ini, model akan beradaptasi dengan pola yang tidak mencerminkan hubungan mendasar yang sebenarnya, sehingga menyebabkan overfitting.
Beban besar
Dalam model pembelajaran mesin, bobot adalah nilai numerik yang mewakili pentingnya fitur tertentu dalam data saat membuat prediksi. Ketika bobot menjadi terlalu besar secara tidak proporsional, model mungkin mengalami overfit, sehingga menjadi terlalu sensitif terhadap fitur tertentu, termasuk noise dalam data. Hal ini terjadi karena model menjadi terlalu bergantung pada fitur tertentu, sehingga mengganggu kemampuannya untuk menggeneralisasi data baru.
Latihan berlebihan
Selama pelatihan, algoritme memproses data dalam beberapa batch, menghitung kesalahan untuk setiap batch, dan menyesuaikan bobot model untuk meningkatkan akurasinya.
Apakah sebaiknya melanjutkan pelatihan selama mungkin? Tidak terlalu! Pelatihan yang berkepanjangan pada data yang sama dapat menyebabkan model mengingat titik data tertentu, sehingga membatasi kemampuannya untuk menggeneralisasi data baru atau yang tidak terlihat, yang merupakan inti dari overfitting. Jenis overfitting ini dapat dikurangi dengan menggunakan teknik penghentian awal atau memantau performa model pada set validasi selama pelatihan. Kami akan membahas cara kerjanya nanti di artikel.
Arsitektur model terlalu rumit
Arsitektur model pembelajaran mesin mengacu pada bagaimana lapisan dan neuronnya terstruktur dan bagaimana mereka berinteraksi untuk memproses informasi.

Arsitektur yang lebih kompleks dapat menangkap pola detail dalam data pelatihan. Namun, kompleksitas ini meningkatkan kemungkinan terjadinya overfitting, karena model juga dapat belajar menangkap noise atau detail tidak relevan yang tidak berkontribusi pada prediksi akurat pada data baru. Menyederhanakan arsitektur atau menggunakan teknik regularisasi dapat membantu mengurangi risiko overfitting.
Cara mendeteksi overfitting
Mendeteksi overfitting bisa jadi rumit karena semuanya tampak berjalan baik selama pelatihan, bahkan ketika overfitting sedang terjadi. Tingkat kerugian (atau kesalahan)—ukuran seberapa sering model salah—akan terus menurun, bahkan dalam skenario overfitting. Jadi, bagaimana kita bisa mengetahui jika telah terjadi overfitting? Kita memerlukan tes yang dapat diandalkan.
Salah satu metode yang efektif adalah menggunakan kurva pembelajaran, yaitu bagan yang melacak suatu ukuran yang disebut kerugian. Kerugian tersebut mewakili besarnya kesalahan yang dibuat model. Namun, kami tidak hanya melacak hilangnya data pelatihan; kami juga mengukur kerugian pada data yang tidak terlihat, yang disebut data validasi. Inilah sebabnya mengapa kurva pembelajaran biasanya memiliki dua garis: kerugian pelatihan dan kerugian validasi.
Jika kerugian pelatihan terus menurun seperti yang diharapkan, namun kerugian validasi meningkat, hal ini menunjukkan overfitting. Dengan kata lain, model menjadi terlalu terspesialisasi pada data pelatihan dan kesulitan untuk menggeneralisasi data baru yang tidak terlihat. Kurva pembelajarannya mungkin terlihat seperti ini:
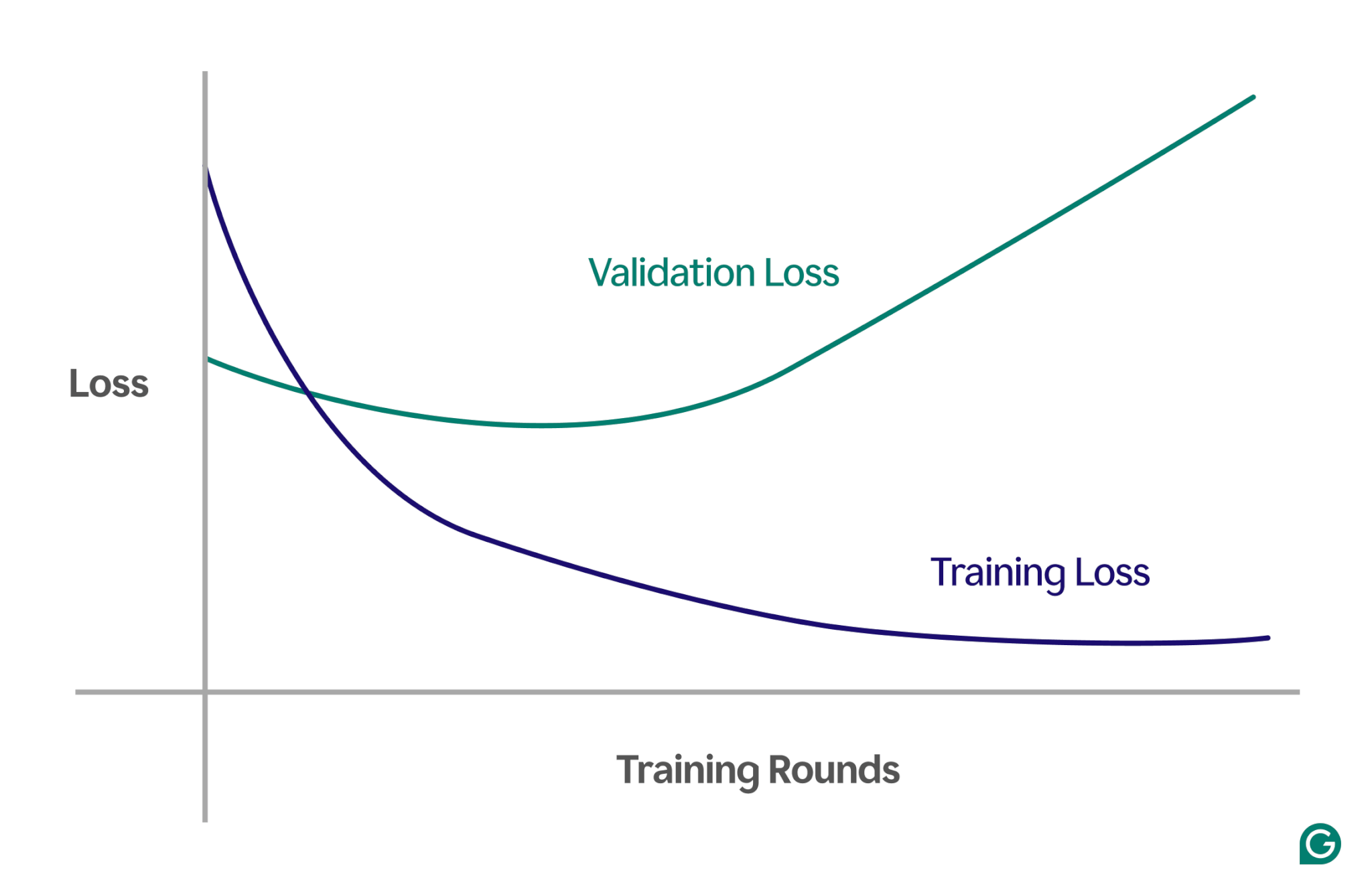
Dalam skenario ini, meskipun model mengalami peningkatan selama pelatihan, performanya buruk pada data yang tidak terlihat. Ini mungkin berarti telah terjadi overfitting.
Bagaimana menghindari overfitting
Overfitting dapat diatasi dengan beberapa teknik. Berikut beberapa metode yang paling umum:
Kurangi ukuran model
Sebagian besar arsitektur model memungkinkan Anda menyesuaikan jumlah bobot dengan mengubah jumlah lapisan, ukuran lapisan, dan parameter lain yang dikenal sebagai hyperparameter. Jika kompleksitas model menyebabkan overfitting, mengurangi ukurannya dapat membantu. Menyederhanakan model dengan mengurangi jumlah lapisan atau neuron dapat menurunkan risiko overfitting, karena model akan memiliki lebih sedikit peluang untuk mengingat data pelatihan.
Biasakan modelnya
Regularisasi melibatkan modifikasi model untuk mencegah bobot yang besar. Salah satu pendekatannya adalah dengan menyesuaikan fungsi kerugian sehingga dapat mengukur kesalahan dan menyertakan ukuran bobot.
Dengan regularisasi, algoritme pelatihan meminimalkan kesalahan dan ukuran bobot, mengurangi kemungkinan bobot yang besar kecuali bobot tersebut memberikan keuntungan yang jelas pada model. Hal ini membantu mencegah overfitting dengan menjaga model lebih umum.
Tambahkan lebih banyak data pelatihan
Meningkatkan ukuran set data pelatihan juga dapat membantu mencegah overfitting. Dengan lebih banyak data, kecil kemungkinan model akan terpengaruh oleh gangguan atau ketidakakuratan dalam kumpulan data. Mengekspos model pada contoh yang lebih bervariasi akan mengurangi kecenderungan menghafal titik data individual dan malah mempelajari pola yang lebih luas.
Terapkan pengurangan dimensi
Terkadang, data mungkin berisi fitur (atau dimensi) yang berkorelasi, artinya beberapa fitur terkait dalam beberapa cara. Model pembelajaran mesin memperlakukan dimensi sebagai sesuatu yang independen, jadi jika fitur berkorelasi, model mungkin terlalu fokus pada dimensi tersebut, sehingga menyebabkan overfitting.
Teknik statistik, seperti analisis komponen utama (PCA), dapat mengurangi korelasi ini. PCA menyederhanakan data dengan mengurangi jumlah dimensi dan menghilangkan korelasi, sehingga mengurangi kemungkinan terjadinya overfitting. Dengan berfokus pada fitur yang paling relevan, model menjadi lebih baik dalam menggeneralisasi data baru.
Contoh praktis dari overfitting
Untuk lebih memahami overfitting, mari kita jelajahi beberapa contoh praktis di berbagai bidang di mana overfitting dapat menyebabkan hasil yang menyesatkan.
Klasifikasi gambar
Pengklasifikasi gambar dirancang untuk mengenali objek dalam gambar—misalnya, apakah gambar berisi burung atau anjing.
Detail lain mungkin berkorelasi dengan apa yang Anda coba deteksi dalam gambar ini. Misalnya, foto anjing sering kali memiliki latar belakang rumput, sedangkan foto burung sering kali menampilkan langit atau puncak pohon sebagai latar belakang.
Jika semua gambar pelatihan memiliki detail latar belakang yang konsisten, model pembelajaran mesin mungkin mulai mengandalkan latar belakang untuk mengenali hewan tersebut, daripada berfokus pada fitur sebenarnya dari hewan itu sendiri. Akibatnya, saat model diminta untuk mengklasifikasikan gambar burung yang bertengger di halaman, model tersebut mungkin salah mengklasifikasikannya sebagai anjing karena terlalu sesuai dengan informasi latar belakang. Ini adalah kasus overfitting pada data pelatihan.
Pemodelan keuangan
Katakanlah Anda memperdagangkan saham di waktu luang, dan Anda yakin bahwa pergerakan harga dapat diprediksi berdasarkan tren penelusuran Google untuk kata kunci tertentu. Anda menyiapkan model pembelajaran mesin menggunakan data Google Trends untuk ribuan kata.
Karena ada begitu banyak kata, beberapa kemungkinan akan menunjukkan korelasi dengan harga saham Anda semata-mata karena kebetulan. Model tersebut mungkin terlalu cocok dengan korelasi yang kebetulan ini, sehingga menghasilkan prediksi yang buruk terhadap data di masa depan karena kata-kata tersebut tidak dapat memprediksi harga saham dengan relevan.
Saat membangun model untuk aplikasi keuangan, penting untuk memahami dasar teori hubungan dalam data. Memasukkan kumpulan data yang besar ke dalam model tanpa pemilihan fitur yang cermat dapat meningkatkan risiko overfitting, terutama ketika model mengidentifikasi korelasi palsu yang terjadi secara kebetulan dalam data pelatihan.
Takhayul olahraga
Meskipun tidak sepenuhnya terkait dengan pembelajaran mesin, takhayul olahraga dapat menggambarkan konsep overfitting—terutama ketika hasil dikaitkan dengan data yang secara logis tidak ada hubungannya dengan hasil.
Selama kejuaraan sepak bola UEFA Euro 2008 dan Piala Dunia FIFA 2010, seekor gurita bernama Paul terkenal digunakan untuk memprediksi hasil pertandingan yang melibatkan Jerman. Paul mendapatkan empat dari enam prediksi yang benar pada tahun 2008 dan ketujuh prediksi tersebut pada tahun 2010.
Jika Anda hanya mempertimbangkan “data pelatihan” dari prediksi Paul di masa lalu, model yang sesuai dengan pilihan Paul akan terlihat memprediksi hasil dengan sangat baik. Namun, model ini tidak dapat digeneralisasi dengan baik untuk pertandingan di masa depan, karena pilihan gurita merupakan alat prediksi hasil pertandingan yang tidak dapat diandalkan.