
Hutan acak dalam pembelajaran mesin: apa mereka dan bagaimana mereka bekerja
Diterbitkan: 2025-02-03Hutan acak adalah teknik yang kuat dan serbaguna dalam pembelajaran mesin (ML). Panduan ini akan membantu Anda memahami hutan acak, bagaimana mereka bekerja dan aplikasi, manfaat, dan tantangan mereka.
Daftar isi
- Apa itu hutan acak?
- Pohon Keputusan vs Hutan Acak: Apa bedanya?
- Bagaimana hutan acak bekerja
- Aplikasi praktis hutan acak
- Keuntungan dari Hutan Acak
- Kerugian hutan acak
Apa itu hutan acak?
Hutan acak adalah algoritma pembelajaran mesin yang menggunakan beberapa pohon keputusan untuk membuat prediksi. Ini adalah metode pembelajaran yang diawasi yang dirancang untuk tugas klasifikasi dan regresi. Dengan menggabungkan output banyak pohon, hutan acak meningkatkan akurasi, mengurangi overfitting, dan memberikan prediksi yang lebih stabil dibandingkan dengan pohon keputusan tunggal.
Pohon Keputusan vs Hutan Acak: Apa bedanya?
Meskipun hutan acak dibangun di atas pohon keputusan, kedua algoritma berbeda secara signifikan dalam struktur dan aplikasi:
Pohon Keputusan
Pohon keputusan terdiri dari tiga komponen utama: node akar, node keputusan (node internal), dan node daun. Seperti diagram alur, proses pengambilan keputusan dimulai pada node akar, mengalir melalui node keputusan berdasarkan kondisi, dan berakhir pada node daun yang mewakili hasilnya. Sementara pohon keputusan mudah ditafsirkan dan dikonseptualisasikan, mereka juga cenderung berlebihan, terutama dengan set data yang kompleks atau berisik.
Hutan acak
Hutan acak adalah ansambel pohon keputusan yang menggabungkan output mereka untuk prediksi yang lebih baik. Setiap pohon dilatih pada sampel bootstrap yang unik (subset sampel secara acak dari dataset asli dengan penggantian) dan mengevaluasi pemisahan keputusan menggunakan subset fitur yang dipilih secara acak di setiap node. Pendekatan ini, yang dikenal sebagai fitur mengantongi, memperkenalkan keragaman di antara pohon -pohon. Dengan mengumpulkan prediksi - menggunakan pemungutan suara mayoritas untuk klasifikasi atau rata -rata untuk regresi - hutan trandom menghasilkan hasil yang lebih akurat dan stabil daripada pohon keputusan tunggal dalam ansambel.
Bagaimana hutan acak bekerja
Hutan acak beroperasi dengan menggabungkan beberapa pohon keputusan untuk membuat model prediksi yang kuat dan akurat.
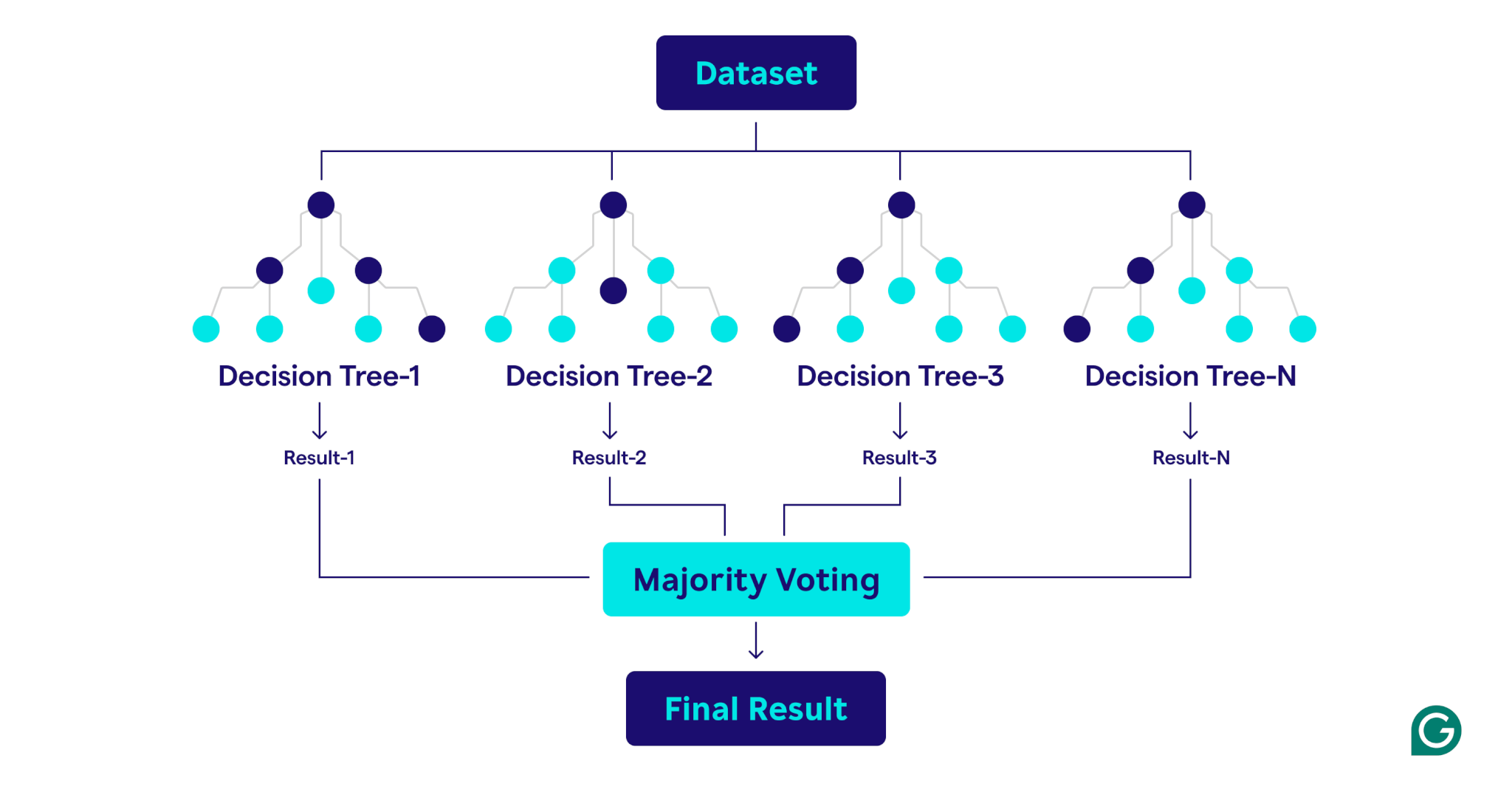
Berikut penjelasan langkah demi langkah tentang prosesnya:
1. Mengatur hyperparameters
Langkah pertama adalah mendefinisikan hiperparameter model. Ini termasuk:
- Jumlah pohon:Menentukan ukuran hutan
- Kedalaman maksimum untuk setiap pohon:Mengontrol seberapa dalam setiap pohon keputusan dapat tumbuh
- Jumlah fitur yang dipertimbangkan di setiap perpecahan:membatasi jumlah fitur yang dievaluasi saat membuat pemisahan
Hyperparameter ini memungkinkan untuk menyempurnakan kompleksitas model dan mengoptimalkan kinerja untuk kumpulan data tertentu.
2. Bootstrap Sampling
Setelah hyperparameters ditetapkan, proses pelatihan dimulai dengan pengambilan sampel bootstrap. Ini melibatkan:
- Poin data dari dataset asli dipilih secara acak untuk membuat set data pelatihan (sampel bootstrap) untuk setiap pohon keputusan.
- Setiap sampel bootstrap biasanya sekitar dua pertiga ukuran dataset asli, dengan beberapa titik data diulang dan yang lainnya dikecualikan.
- Sepertiga yang tersisa dari titik data, tidak termasuk dalam sampel bootstrap, disebut sebagai data out-of-bag (OOB).
3. Membangun Pohon Keputusan
Setiap pohon keputusan di hutan acak dilatih pada sampel bootstrap yang sesuai menggunakan proses yang unik:
- Fitur Bagging:Pada setiap split, subset acak fitur dipilih, memastikan keragaman di antara pohon.
- Pemisahan Node:Fitur terbaik dari subset digunakan untuk membagi node:
- Untuk tugas klasifikasi, kriteria seperti pengotor Gini (ukuran seberapa sering elemen yang dipilih secara acak akan diklasifikasikan secara tidak benar jika diberi label secara acak sesuai dengan distribusi label kelas dalam node) mengukur seberapa baik perpecahan memisahkan kelas.
- Untuk tugas regresi, teknik seperti reduksi varians (metode yang mengukur seberapa banyak pemisahan node mengurangi varian nilai target, yang mengarah ke prediksi yang lebih tepat) mengevaluasi seberapa banyak split mengurangi kesalahan prediksi.
- Pohon tumbuh secara rekursif sampai memenuhi kondisi penghentian, seperti kedalaman maksimum atau jumlah minimum titik data per node.
4. Mengevaluasi kinerja
Karena setiap pohon dibangun, kinerja model diperkirakan menggunakan data OOB:
- Estimasi kesalahan OOB memberikan ukuran kinerja model yang tidak bias, menghilangkan kebutuhan untuk dataset validasi terpisah.
- Dengan agregasi prediksi dari semua pohon, hutan acak mencapai peningkatan akurasi dan mengurangi overfitting dibandingkan dengan pohon keputusan individu.

Aplikasi praktis hutan acak
Seperti pohon keputusan tempat mereka dibangun, hutan acak dapat diterapkan pada masalah klasifikasi dan regresi di berbagai sektor, seperti perawatan kesehatan dan keuangan.
Mengklasifikasikan kondisi pasien
Dalam perawatan kesehatan, hutan acak digunakan untuk mengklasifikasikan kondisi pasien berdasarkan informasi seperti riwayat medis, demografi, dan hasil tes. Sebagai contoh, untuk memprediksi apakah pasien cenderung mengembangkan kondisi spesifik seperti diabetes, setiap pohon keputusan mengklasifikasikan pasien sebagai risiko atau tidak berdasarkan data yang relevan, dan hutan acak membuat penentuan akhir berdasarkan suara mayoritas. Pendekatan ini berarti bahwa hutan acak sangat cocok untuk kumpulan data yang kompleks dan kaya fitur yang ditemukan dalam perawatan kesehatan.
Memprediksi default pinjaman
Bank dan lembaga keuangan utama banyak menggunakan hutan acak untuk menentukan kelayakan pinjaman dan lebih memahami risiko. Model ini menggunakan faktor -faktor seperti pendapatan dan skor kredit untuk menentukan risiko. Karena risiko diukur sebagai nilai numerik kontinu, hutan acak melakukan regresi alih -alih klasifikasi. Setiap pohon keputusan, dilatih pada sampel bootstrap yang sedikit berbeda, mengeluarkan skor risiko yang diprediksi. Kemudian, hutan acak rata -rata semua prediksi individu, menghasilkan perkiraan risiko holistik yang kuat.
Memprediksi kehilangan pelanggan
Dalam pemasaran, hutan acak sering digunakan untuk memprediksi kemungkinan pelanggan menghentikan penggunaan produk atau layanan. Ini melibatkan menganalisis pola perilaku pelanggan, seperti frekuensi pembelian dan interaksi dengan layanan pelanggan. Dengan mengidentifikasi pola -pola ini, hutan acak dapat mengklasifikasikan pelanggan yang berisiko pergi. Dengan wawasan ini, perusahaan dapat mengambil langkah-langkah proaktif dan berbasis data untuk mempertahankan pelanggan, seperti menawarkan program loyalitas atau promosi yang ditargetkan.
Memprediksi harga real estat
Hutan acak dapat digunakan untuk memprediksi harga real estat, yang merupakan tugas regresi. Untuk membuat prediksi, hutan acak menggunakan data historis yang mencakup faktor -faktor seperti lokasi geografis, rekaman persegi, dan penjualan terbaru di daerah tersebut. Proses rata -rata hutan acak menghasilkan prediksi harga yang lebih andal dan stabil daripada pohon keputusan individu, yang berguna di pasar real estat yang sangat mudah menguap.
Keuntungan dari Hutan Acak
Hutan acak menawarkan banyak keuntungan, termasuk akurasi, ketahanan, keserbagunaan, dan kemampuan untuk memperkirakan kepentingan fitur.
Keakuratan dan ketahanan
Hutan acak lebih akurat dan kuat daripada pohon keputusan individu. Ini dicapai dengan menggabungkan output dari beberapa pohon keputusan yang dilatih pada sampel bootstrap yang berbeda dari dataset asli. Keragaman yang dihasilkan berarti bahwa hutan acak kurang rentan terhadap overfitting daripada pohon keputusan individu. Pendekatan ensembel ini berarti bahwa hutan acak pandai menangani data yang bising, bahkan dalam set data yang kompleks.
Keserbagunaan
Seperti pohon keputusan tempat mereka dibangun, hutan acak sangat fleksibel. Mereka dapat menangani tugas regresi dan klasifikasi, membuatnya berlaku untuk berbagai masalah. Hutan acak juga bekerja dengan baik dengan kumpulan data yang besar dan kaya fitur dan dapat menangani data numerik dan kategorikal.
Fitur pentingnya
Hutan acak memiliki kemampuan bawaan untuk memperkirakan pentingnya fitur tertentu. Sebagai bagian dari proses pelatihan, hutan acak menghasilkan skor yang mengukur seberapa banyak akurasi model berubah jika fitur tertentu dihapus. Dengan rata -rata skor untuk setiap fitur, hutan acak dapat memberikan ukuran kepentingan fitur yang dapat diukur. Fitur yang kurang penting kemudian dapat dihapus untuk membuat pohon dan hutan yang lebih efisien.
Kerugian hutan acak
Sementara hutan acak menawarkan banyak manfaat, mereka lebih sulit untuk ditafsirkan dan lebih mahal untuk berlatih daripada pohon keputusan tunggal, dan mereka mungkin menghasilkan prediksi lebih lambat daripada model lainnya.
Kompleksitas
Sementara hutan acak dan pohon keputusan memiliki banyak kesamaan, hutan acak lebih sulit untuk ditafsirkan dan divisualisasikan. Kompleksitas ini muncul karena hutan acak menggunakan ratusan atau ribuan pohon keputusan. Sifat "kotak hitam" dari hutan acak adalah kelemahan serius ketika model yang dapat dijelaskan adalah persyaratan.
Biaya komputasi
Melatih ratusan atau ribuan pohon keputusan membutuhkan lebih banyak kekuatan dan memori pemrosesan daripada melatih satu pohon keputusan tunggal. Ketika kumpulan data besar terlibat, biaya komputasi bisa lebih tinggi. Persyaratan sumber daya yang besar ini dapat menghasilkan biaya moneter yang lebih tinggi dan waktu pelatihan yang lebih lama. Akibatnya, hutan acak mungkin tidak praktis dalam skenario seperti komputasi tepi, di mana daya komputasi dan memori langka. Namun, hutan acak dapat diparalelkan, yang dapat membantu mengurangi biaya perhitungan.
Waktu prediksi yang lebih lambat
Proses prediksi hutan acak melibatkan melintasi setiap pohon di hutan dan mengumpulkan output mereka, yang secara inheren lebih lambat daripada menggunakan model tunggal. Proses ini dapat menghasilkan waktu prediksi yang lebih lambat daripada model yang lebih sederhana seperti regresi logistik atau jaringan saraf, terutama untuk hutan besar yang mengandung pohon dalam. Untuk kasus penggunaan di mana waktu adalah esensi, seperti perdagangan frekuensi tinggi atau kendaraan otonom, penundaan ini bisa menjadi penghalang.