
Apa yang dimaksud dengan Underfitting dalam Pembelajaran Mesin?
Diterbitkan: 2024-10-16Underfitting adalah masalah umum yang ditemui selama pengembangan model pembelajaran mesin (ML). Hal ini terjadi ketika model tidak dapat belajar secara efektif dari data pelatihan, sehingga menghasilkan performa di bawah standar. Pada artikel ini, kita akan membahas apa itu underfitting, bagaimana terjadinya, dan strategi untuk menghindarinya.
Daftar isi
- Apa itu underfitting?
- Bagaimana underfitting terjadi
- Underfitting vs. overfitting
- Penyebab umum dari underfitting
- Cara mendeteksi underfitting
- Teknik untuk mencegah underfitting
- Contoh praktis dari underfitting
Apa itu underfitting?
Underfitting adalah ketika model pembelajaran mesin gagal menangkap pola mendasar dalam data pelatihan, sehingga menyebabkan kinerja yang buruk pada data pelatihan dan pengujian. Jika hal ini terjadi, berarti model tersebut terlalu sederhana dan tidak berfungsi dengan baik dalam merepresentasikan hubungan data yang paling penting. Akibatnya, model kesulitan membuat prediksi akurat pada semua data, baik data yang terlihat selama pelatihan maupun data baru yang tidak terlihat.
Bagaimana underfitting bisa terjadi?
Underfitting terjadi ketika algoritme pembelajaran mesin menghasilkan model yang gagal menangkap properti terpenting dari data pelatihan; model yang gagal dengan cara ini dianggap terlalu sederhana. Misalnya, bayangkan Anda menggunakan regresi linier untuk memprediksi penjualan berdasarkan pembelanjaan pemasaran, demografi pelanggan, dan musiman. Regresi linier mengasumsikan hubungan antara faktor-faktor ini dan penjualan dapat direpresentasikan sebagai gabungan garis lurus.
Meskipun hubungan sebenarnya antara pembelanjaan pemasaran dan penjualan mungkin berbentuk kurva atau mencakup beberapa interaksi (misalnya, penjualan meningkat pesat pada awalnya, kemudian stagnan), model linier akan menyederhanakan dengan menggambar garis lurus. Penyederhanaan ini mengabaikan nuansa penting, sehingga menyebabkan prediksi dan kinerja keseluruhan yang buruk.
Masalah ini umum terjadi pada banyak model ML ketika bias yang tinggi (asumsi yang kaku) menghalangi model untuk mempelajari pola-pola penting, sehingga menyebabkan performanya buruk pada data pelatihan dan pengujian. Underfitting biasanya terlihat ketika model terlalu sederhana untuk mewakili kompleksitas data yang sebenarnya.
Underfitting vs. overfitting
Di ML, underfitting dan overfitting adalah masalah umum yang dapat berdampak negatif terhadap kemampuan model dalam membuat prediksi yang akurat. Memahami perbedaan antara keduanya sangat penting untuk membangun model yang dapat digeneralisasikan dengan baik pada data baru.
- Underfittingterjadi ketika model terlalu sederhana dan gagal menangkap pola-pola utama dalam data. Hal ini menyebabkan prediksi yang tidak akurat baik untuk data pelatihan maupun data baru.
- Overfittingterjadi ketika model menjadi terlalu kompleks, tidak hanya menyesuaikan pola sebenarnya tetapi juga noise dalam data pelatihan. Hal ini menyebabkan model berperforma baik pada set pelatihan, namun buruk pada data baru yang tidak terlihat.
Untuk mengilustrasikan konsep ini dengan lebih baik, pertimbangkan model yang memprediksi performa atlet berdasarkan tingkat stres. Titik biru pada diagram mewakili titik data dari set pelatihan, sedangkan garis menunjukkan prediksi model setelah dilatih berdasarkan data tersebut. 
1 Underfitting:Dalam hal ini, model menggunakan garis lurus sederhana untuk memprediksi performa, meskipun hubungan sebenarnya berbentuk kurva. Karena garisnya tidak cocok dengan data, modelnya terlalu sederhana dan gagal menangkap pola-pola penting, sehingga menghasilkan prediksi yang buruk. Ini adalah underfitting, yaitu model gagal mempelajari properti data yang paling berguna.
2 Kesesuaian optimal:Di sini, model cukup sesuai dengan kurva data. Ini menangkap tren yang mendasarinya tanpa terlalu sensitif terhadap titik data atau gangguan tertentu. Ini adalah skenario yang diinginkan, ketika model dapat digeneralisasi dengan cukup baik dan dapat membuat prediksi akurat pada data baru yang serupa. Namun, generalisasi masih menjadi tantangan ketika dihadapkan pada kumpulan data yang sangat berbeda atau lebih kompleks.
3 Overfitting:Dalam skenario overfitting, model mengikuti hampir setiap titik data, termasuk noise dan fluktuasi acak pada data pelatihan. Meskipun performa model sangat baik pada set pelatihan, model ini terlalu spesifik untuk data pelatihan, sehingga kurang efektif saat memprediksi data baru. Ia kesulitan untuk menggeneralisasi dan kemungkinan besar akan membuat prediksi yang tidak akurat ketika diterapkan pada skenario yang tidak terlihat.
Penyebab umum dari underfitting
Ada banyak kemungkinan penyebab underfitting. Empat yang paling umum adalah:
- Arsitektur model terlalu sederhana.
- Pemilihan fitur yang buruk
- Data pelatihan tidak mencukupi
- Pelatihan tidak cukup
Mari kita gali lebih jauh untuk memahaminya.
Arsitektur model terlalu sederhana
Arsitektur model mengacu pada kombinasi algoritma yang digunakan untuk melatih model dan struktur model. Jika arsitekturnya terlalu sederhana, mungkin akan terjadi kesulitan dalam menangkap properti tingkat tinggi dari data pelatihan, sehingga menyebabkan prediksi yang tidak akurat.
Misalnya, jika suatu model mencoba menggunakan satu garis lurus untuk memodelkan data yang mengikuti pola melengkung, maka model tersebut akan selalu underfit. Hal ini karena garis lurus tidak dapat secara akurat mewakili hubungan tingkat tinggi dalam data melengkung, sehingga arsitektur model tidak memadai untuk tugas tersebut.
Pemilihan fitur yang buruk
Pemilihan fitur melibatkan pemilihan variabel yang tepat untuk model ML selama pelatihan. Misalnya, Anda mungkin meminta algoritma ML untuk melihat tahun lahir seseorang, warna mata, usia, atau ketiganya ketika memprediksi apakah seseorang akan menekan tombol beli di situs e-commerce.
Jika terdapat terlalu banyak fitur, atau fitur yang dipilih tidak berkorelasi kuat dengan variabel target, model tidak akan memiliki informasi relevan yang cukup untuk membuat prediksi yang akurat. Warna mata mungkin tidak relevan dengan konversi, dan usia memberikan informasi yang hampir sama dengan tahun lahir.
Data pelatihan tidak mencukupi
Jika titik data terlalu sedikit, model mungkin kurang cocok karena data tidak menangkap properti terpenting dari permasalahan. Hal ini dapat terjadi karena kurangnya data atau karena bias pengambilan sampel, yaitu sumber data tertentu dikecualikan atau kurang terwakili, sehingga model tidak dapat mempelajari pola-pola penting.

Pelatihan tidak cukup
Melatih model ML melibatkan penyesuaian parameter internal (bobot) berdasarkan perbedaan antara prediksi dan hasil sebenarnya. Semakin banyak iterasi pelatihan yang dilakukan model, semakin baik model tersebut dapat menyesuaikan diri dengan data. Jika model dilatih dengan iterasi yang terlalu sedikit, model tersebut mungkin tidak memiliki cukup peluang untuk belajar dari data, sehingga menyebabkan underfitting.
Cara mendeteksi underfitting
Salah satu cara untuk mendeteksi underfitting adalah dengan menganalisis kurva pembelajaran, yang memplot performa model (biasanya kerugian atau kesalahan) terhadap jumlah iterasi pelatihan. Kurva pembelajaran menunjukkan bagaimana model meningkat (atau gagal ditingkatkan) seiring waktu pada set data pelatihan dan validasi.
Kerugiannya adalah besarnya kesalahan model untuk sekumpulan data tertentu. Kerugian pelatihan mengukur hal ini untuk data pelatihan dan kerugian validasi untuk data validasi. Data validasi adalah kumpulan data terpisah yang digunakan untuk menguji performa model. Biasanya dihasilkan dengan membagi kumpulan data yang lebih besar secara acak menjadi data pelatihan dan validasi.
Jika terjadi underfitting, Anda akan melihat pola utama berikut:
- Kerugian pelatihan yang tinggi:Jika kerugian pelatihan model tetap tinggi dan berbentuk garis datar di awal proses, hal ini menunjukkan bahwa model tersebut tidak belajar dari data pelatihan. Hal ini jelas menunjukkan adanya underfitting, karena modelnya terlalu sederhana untuk disesuaikan dengan kompleksitas data.
- Kerugian pelatihan dan validasi serupa:Jika kerugian pelatihan dan validasi sama-sama tinggi dan tetap berdekatan selama proses pelatihan, ini berarti model berperforma buruk pada kedua set data. Hal ini menunjukkan bahwa model tidak menangkap informasi yang cukup dari data untuk membuat prediksi yang akurat, sehingga menunjukkan adanya underfitting.
Di bawah ini adalah contoh bagan yang memperlihatkan kurva pembelajaran dalam skenario underfitting:
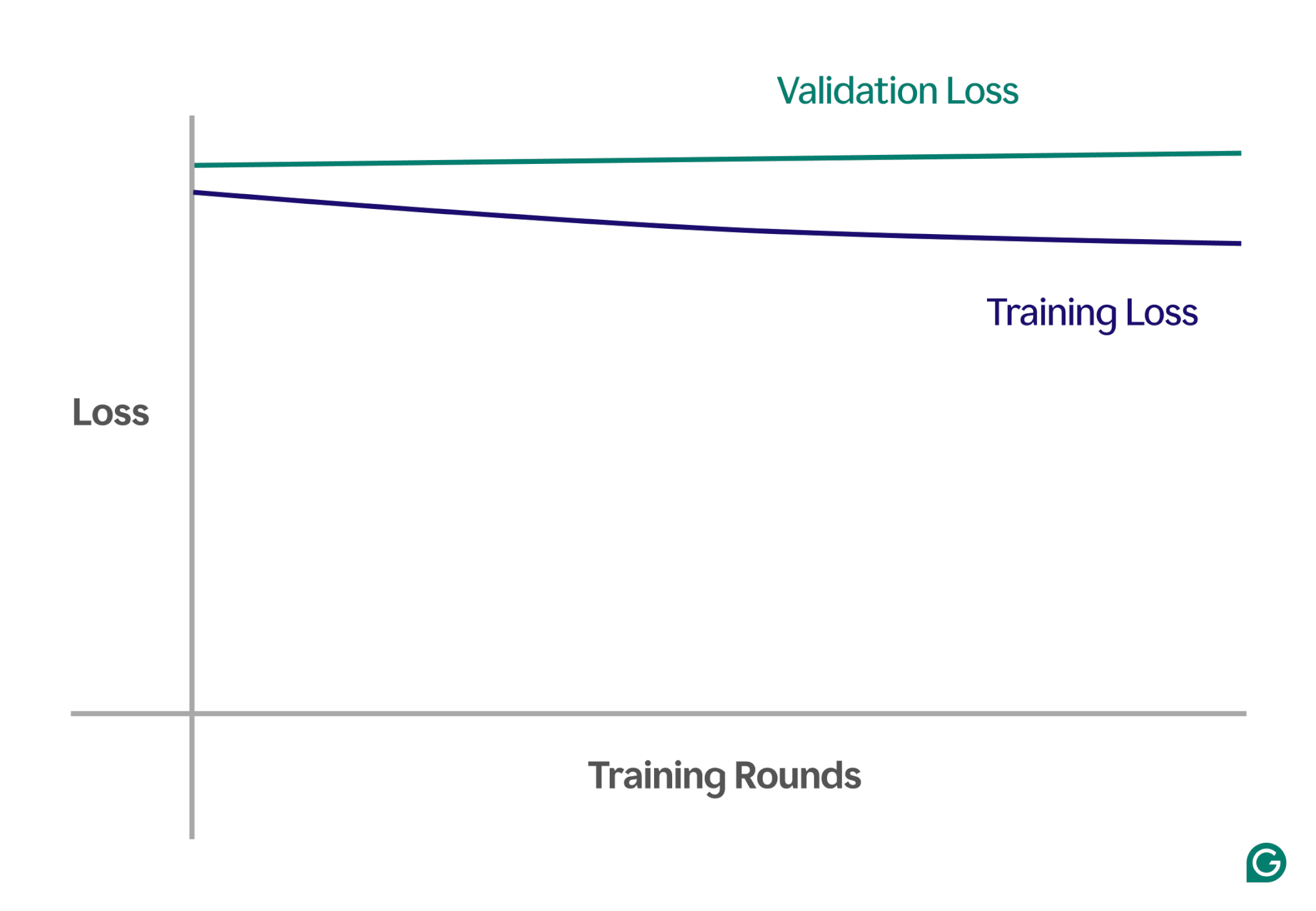
Dalam representasi visual ini, underfitting mudah dikenali:
- Dalam model yang sesuai, kerugian pelatihan berkurang secara signifikan sementara kerugian validasi mengikuti pola yang sama, dan pada akhirnya menjadi stabil.
- Dalam model yang kurang cocok, kerugian pelatihan dan validasi mulai tinggi dan tetap tinggi, tanpa peningkatan yang signifikan.
Dengan mengamati tren ini, Anda dapat dengan cepat mengidentifikasi apakah model tersebut terlalu sederhana dan memerlukan penyesuaian untuk meningkatkan kompleksitasnya.
Teknik untuk mencegah underfitting
Jika Anda mengalami underfitting, ada beberapa strategi yang dapat Anda gunakan untuk meningkatkan performa model:
- Lebih banyak data pelatihan:Jika memungkinkan, dapatkan data pelatihan tambahan. Lebih banyak data memberi model peluang tambahan untuk mempelajari pola, asalkan datanya berkualitas tinggi dan relevan dengan masalah yang dihadapi.
- Perluas pilihan fitur:Tambahkan fitur yang lebih relevan ke model. Pilih fitur yang memiliki hubungan kuat dengan variabel target, sehingga memberikan peluang lebih besar bagi model untuk menangkap pola penting yang sebelumnya terlewatkan.
- Meningkatkan kekuatan arsitektur:Dalam model berdasarkan jaringan saraf, Anda dapat menyesuaikan struktur arsitektur dengan mengubah jumlah bobot, lapisan, atau hyperparameter lainnya. Hal ini memungkinkan model menjadi lebih fleksibel dan lebih mudah menemukan pola tingkat tinggi dalam data.
- Pilih model lain:Terkadang, bahkan setelah menyetel hyperparameter, model tertentu mungkin tidak cocok untuk tugas tersebut. Menguji beberapa algoritma model dapat membantu menemukan model yang lebih tepat dan meningkatkan kinerja.
Contoh praktis dari underfitting
Untuk mengilustrasikan dampak underfitting, mari kita lihat contoh nyata di berbagai domain saat model gagal menangkap kompleksitas data, sehingga menghasilkan prediksi yang tidak akurat.
Memprediksi harga rumah
Untuk memprediksi harga rumah secara akurat, Anda perlu mempertimbangkan banyak faktor, antara lain lokasi, ukuran, tipe rumah, kondisi, dan jumlah kamar tidur.
Jika Anda menggunakan terlalu sedikit fitur—seperti hanya ukuran dan tipe rumah—model tidak akan memiliki akses ke informasi penting. Misalnya, model mungkin berasumsi bahwa sebuah studio kecil tidak mahal, tanpa mengetahui bahwa studio tersebut berlokasi di Mayfair, London, sebuah kawasan dengan harga properti yang tinggi. Hal ini menyebabkan prediksi yang buruk.
Untuk mengatasi hal ini, data scientist harus memastikan pemilihan fitur yang tepat. Hal ini melibatkan penyertaan semua fitur yang relevan, mengecualikan fitur yang tidak relevan, dan penggunaan data pelatihan yang akurat.
Pengenalan ucapan
Teknologi pengenalan suara menjadi semakin umum dalam kehidupan sehari-hari. Misalnya, asisten ponsel cerdas, saluran bantuan layanan pelanggan, dan teknologi bantuan bagi penyandang disabilitas semuanya menggunakan pengenalan suara. Saat melatih model ini, data dari sampel ucapan dan interpretasinya yang benar digunakan.
Untuk mengenali ucapan, model mengubah gelombang suara yang ditangkap oleh mikrofon menjadi data. Jika kita menyederhanakan hal ini dengan hanya menyediakan frekuensi dan volume suara dominan pada interval tertentu, kita mengurangi jumlah data yang harus diproses oleh model.
Namun, pendekatan ini menghilangkan informasi penting yang diperlukan untuk memahami pidato sepenuhnya. Data menjadi terlalu sederhana untuk menangkap kompleksitas ucapan manusia, seperti variasi nada, nada, dan aksen.
Akibatnya, model tersebut akan mengalami kesulitan dalam mengenali bahkan perintah kata dasar, apalagi kalimat lengkap. Sekalipun modelnya cukup kompleks, kurangnya data yang komprehensif dapat menyebabkan underfitting.
Klasifikasi gambar
Pengklasifikasi gambar dirancang untuk mengambil gambar sebagai masukan dan mengeluarkan kata untuk mendeskripsikannya. Katakanlah Anda sedang membuat model untuk mendeteksi apakah suatu gambar berisi bola atau tidak. Anda melatih model menggunakan gambar bola dan objek lain yang diberi label.
Jika Anda salah menggunakan jaringan saraf dua lapis sederhana dan bukan model yang lebih sesuai seperti jaringan saraf konvolusional (CNN), model tersebut akan mengalami kesulitan. Jaringan dua lapis meratakan gambar menjadi satu lapisan, sehingga kehilangan informasi spasial yang penting. Selain itu, dengan hanya dua lapisan, model tersebut tidak memiliki kapasitas untuk mengidentifikasi fitur-fitur kompleks.
Hal ini menyebabkan underfitting, karena model akan gagal membuat prediksi yang akurat, bahkan pada data pelatihan. CNN mengatasi masalah ini dengan mempertahankan struktur spasial gambar dan menggunakan lapisan konvolusional dengan filter yang secara otomatis belajar mendeteksi fitur penting seperti tepi dan bentuk di lapisan awal dan objek yang lebih kompleks di lapisan selanjutnya.