
Nozioni di base sulle reti avversarie generative: cosa devi sapere
Pubblicato: 2024-10-08Le reti generative avversarie (GAN) sono un potente strumento di intelligenza artificiale (AI) con numerose applicazioni nell'apprendimento automatico (ML). Questa guida esplora i GAN, come funzionano, le loro applicazioni e i loro vantaggi e svantaggi.
Sommario
- Cos'è un GAN?
- GAN contro CNN
- Come funzionano i GAN
- Tipi di GAN
- Applicazioni dei GAN
- Vantaggi dei GAN
- Svantaggi dei GAN
Cos’è una rete avversaria generativa?
Una rete generativa avversaria, o GAN, è un tipo di modello di deep learning tipicamente utilizzato nell'apprendimento automatico non supervisionato ma adattabile anche per l'apprendimento semi-supervisionato e supervisionato. I GAN vengono utilizzati per generare dati di alta qualità simili al set di dati di addestramento. Essendo un sottoinsieme dell’intelligenza artificiale generativa, i GAN sono composti da due sottomodelli: il generatore e il discriminatore.
1 Generatore:il generatore crea dati sintetici.
2 Discriminatore:Il discriminatore valuta l'output del generatore, distinguendo tra dati reali dal training set e dati sintetici creati dal generatore.
I due modelli si mettono in competizione: il generatore cerca di ingannare il discriminatore facendogli classificare i dati generati come reali, mentre il discriminatore migliora continuamente la sua capacità di rilevare dati sintetici. Questo processo contraddittorio continua finché il discriminatore non è più in grado di distinguere tra dati reali e generati. A questo punto, il GAN è in grado di generare immagini, video e altri tipi di dati realistici.
GAN contro CNN
I GAN e le reti neurali convoluzionali (CNN) sono tipi potenti di reti neurali utilizzate nel deep learning, ma differiscono significativamente in termini di casi d'uso e architettura.
Casi d'uso
- GAN:specializzati nella generazione di dati sintetici realistici basati su dati di addestramento. Ciò rende i GAN adatti per attività come la generazione di immagini, il trasferimento di stili di immagine e l’aumento dei dati. I GAN non sono supervisionati, il che significa che possono essere applicati a scenari in cui i dati etichettati sono scarsi o non disponibili.
- CNN:utilizzate principalmente per attività di classificazione dei dati strutturati, come l'analisi del sentiment, la categorizzazione degli argomenti e la traduzione linguistica. Grazie alle loro capacità di classificazione, le CNN fungono anche da buoni discriminatori nei GAN. Tuttavia, poiché le CNN richiedono dati di addestramento strutturati e annotati dall’uomo, sono limitate a scenari di apprendimento supervisionato.
Architettura
- GAN:sono costituiti da due modelli – un discriminatore e un generatore – che si impegnano in un processo competitivo. Il generatore crea immagini, mentre il discriminatore le valuta, spingendo il generatore a produrre nel tempo immagini sempre più realistiche.
- CNN:utilizza livelli di operazioni convoluzionali e di pooling per estrarre e analizzare caratteristiche dalle immagini. Questa architettura a modello singolo si concentra sul riconoscimento di modelli e strutture all'interno dei dati.
Nel complesso, mentre le CNN si concentrano sull’analisi dei dati strutturati esistenti, i GAN sono orientati alla creazione di dati nuovi e realistici.
Come funzionano i GAN
Ad alto livello, un GAN funziona mettendo due reti neurali – il generatore e il discriminatore – l’una contro l’altra. I GAN non richiedono un particolare tipo di architettura di rete neurale per nessuno dei due componenti, purché le architetture selezionate si completino a vicenda. Ad esempio, se una CNN viene utilizzata come discriminatore per la generazione di immagini, il generatore potrebbe essere una rete neurale deconvoluzionale (deCNN), che esegue il processo CNN al contrario. Ogni componente ha un obiettivo diverso:
- Generatore:produrre dati di qualità così elevata da indurre il discriminatore a classificarli come reali.
- Discriminatore:classificare accuratamente un dato campione di dati come reale (dal set di dati di addestramento) o falso (generato dal generatore).
Questa competizione è un’implementazione di un gioco a somma zero, in cui una ricompensa data a un modello è anche una penalità per l’altro modello. Per il generatore, ingannare con successo il discriminatore si traduce in un aggiornamento del modello che migliora la sua capacità di generare dati realistici. Al contrario, quando il discriminatore identifica correttamente i dati falsi, riceve un aggiornamento che migliora le sue capacità di rilevamento. Matematicamente, il discriminatore mira a minimizzare l’errore di classificazione, mentre il generatore cerca di massimizzarlo.
Il processo di formazione del GAN
L'addestramento dei GAN prevede l'alternanza tra il generatore e il discriminatore in più epoche. Le epoche sono sessioni di addestramento complete sull'intero set di dati. Questo processo continua finché il generatore non produce dati sintetici che ingannano il discriminatore circa il 50% delle volte. Sebbene entrambi i modelli utilizzino algoritmi simili per la valutazione e il miglioramento delle prestazioni, i loro aggiornamenti avvengono in modo indipendente. Questi aggiornamenti vengono eseguiti utilizzando un metodo chiamato backpropagation, che misura l'errore di ciascun modello e regola i parametri per migliorare le prestazioni. Un algoritmo di ottimizzazione regola quindi i parametri di ciascun modello in modo indipendente.
Ecco una rappresentazione visiva dell'architettura GAN, che illustra la competizione tra generatore e discriminatore:
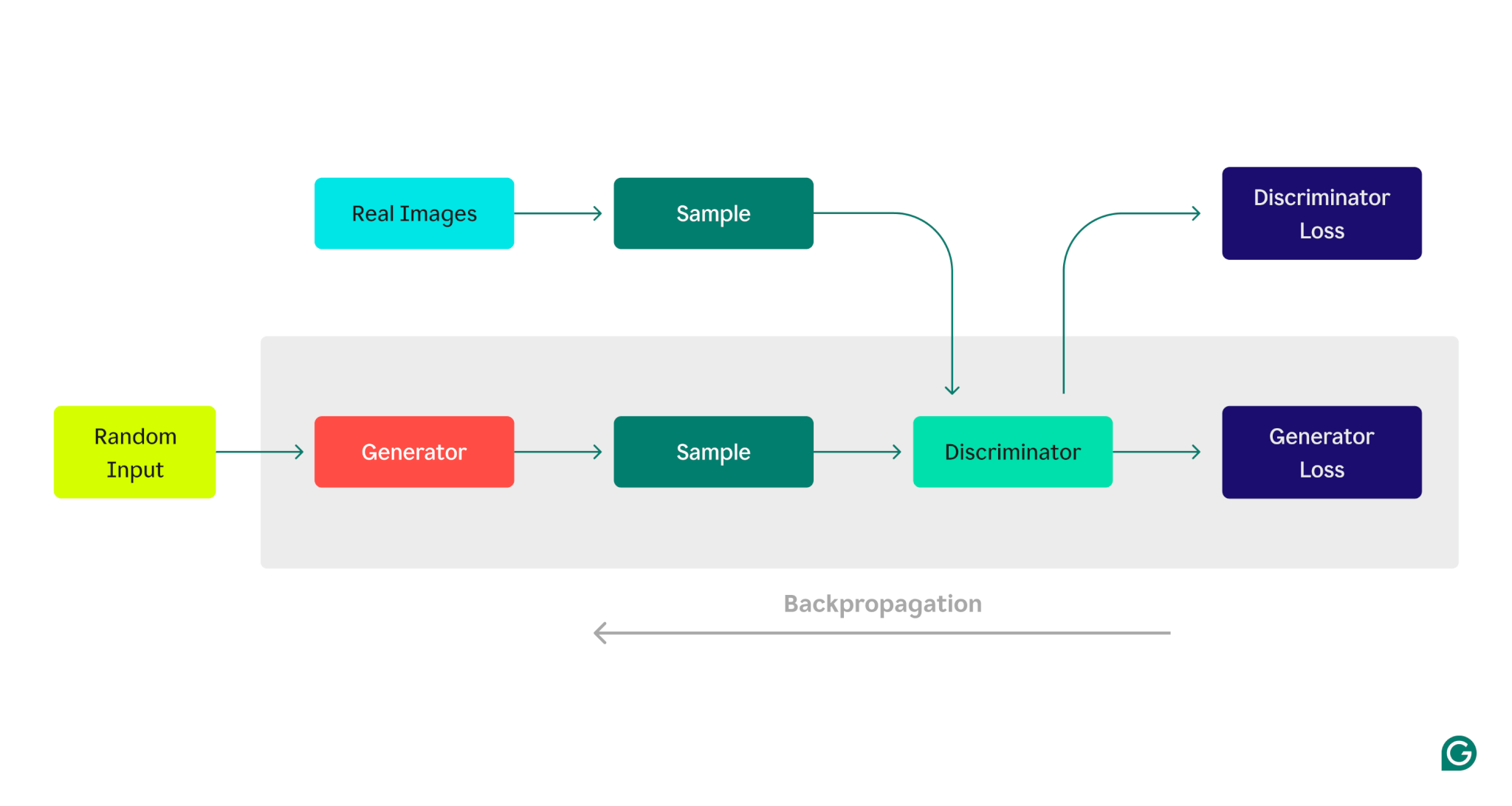
Fase di addestramento del generatore:
1 Il generatore crea campioni di dati, in genere iniziando con rumore casuale come input.
2 Il discriminatore classifica questi campioni come reali (dal set di dati di addestramento) o falsi (generati dal generatore).
3 In base alla risposta del discriminatore, i parametri del generatore vengono aggiornati utilizzando la backpropagation.
Fase di formazione del discriminatore:
1 I dati falsi vengono generati utilizzando lo stato attuale del generatore.
2 I campioni generati vengono forniti al discriminatore, insieme ai campioni del set di dati di addestramento.
3 Utilizzando la backpropagation, i parametri del discriminatore vengono aggiornati in base alle sue prestazioni di classificazione.
Questo processo di addestramento iterativo continua, regolando i parametri di ciascun modello in base alle sue prestazioni, finché il generatore non produce costantemente dati che il discriminatore non può distinguere in modo affidabile dai dati reali.
Tipi di GAN
Basandosi sull'architettura GAN di base, spesso definita GAN vanilla, sono stati sviluppati e ottimizzati altri tipi specializzati di GAN per vari compiti. Alcune delle varianti più comuni sono descritte di seguito, sebbene questo non sia un elenco esaustivo:
GAN condizionale (cGAN)
I GAN condizionali, o cGAN, utilizzano informazioni aggiuntive, chiamate condizioni, per guidare il modello nella generazione di tipi specifici di dati durante l'addestramento su un set di dati più generale. Una condizione può essere un'etichetta di classe, una descrizione basata su testo o un altro tipo di informazioni di classificazione dei dati. Ad esempio, immagina di dover generare immagini solo di gatti siamesi, ma il set di dati di addestramento contiene immagini di tutti i tipi di gatti. In un cGAN, potresti etichettare le immagini di addestramento con il tipo di gatto e il modello potrebbe usarlo per imparare a generare solo immagini di gatti siamesi.

GAN convoluzionale profondo (DCGAN)
Un GAN convoluzionale profondo, o DCGAN, è ottimizzato per la generazione di immagini. In un DCGAN, il generatore è una rete neurale convoluzionale a immersione profonda (deCNN) e il discriminatore è una CNN profonda. Le CNN sono più adatte per lavorare e generare immagini grazie alla loro capacità di catturare gerarchie e modelli spaziali. Il generatore in un DCGAN utilizza strati convoluzionali di sovracampionamento e trasposti per creare immagini di qualità superiore rispetto a quelle che un percettrone multistrato (una semplice rete neurale che prende decisioni valutando le caratteristiche di input) potrebbe generare. Allo stesso modo, il discriminatore utilizza livelli convoluzionali per estrarre caratteristiche dai campioni di immagini e classificarle accuratamente come reali o false.
CicloGAN
CycleGAN è un tipo di GAN progettato per generare un tipo di immagine da un altro. Ad esempio, un CycleGAN può trasformare l'immagine di un topo in un topo o di un cane in un coyote. I CycleGAN sono in grado di eseguire questa traduzione da immagine a immagine senza formazione su set di dati accoppiati, ovvero set di dati contenenti sia l'immagine di base che la trasformazione desiderata. Questa capacità si ottiene utilizzando due generatori e due discriminatori invece della singola coppia utilizzata da un GAN vanilla. In CycleGAN, un generatore converte le immagini dall'immagine di base alla versione trasformata, mentre l'altro generatore esegue una conversione nella direzione opposta. Allo stesso modo, ogni discriminatore controlla un particolare tipo di immagine per determinare se è reale o falsa. CycleGAN utilizza quindi un controllo di coerenza per assicurarsi che la conversione di un'immagine nell'altro stile e viceversa dia come risultato l'immagine originale.
Applicazioni dei GAN
Grazie alla loro architettura distintiva, i GAN sono stati applicati a una serie di casi d’uso innovativi, sebbene le loro prestazioni dipendano fortemente da attività specifiche e dalla qualità dei dati. Alcune delle applicazioni più potenti includono la generazione di testo in immagine, l'aumento dei dati e la generazione e manipolazione di video.
Generazione di testo in immagine
I GAN possono generare immagini da una descrizione testuale. Questa applicazione è preziosa nelle industrie creative, poiché consente ad autori e designer di visualizzare le scene e i personaggi descritti nel testo. Sebbene i GAN siano spesso utilizzati per tali compiti, altri modelli di intelligenza artificiale generativa, come DALL-E di OpenAI, utilizzano architetture basate su trasformatori per ottenere risultati simili.
Aumento dei dati
I GAN sono utili per l'aumento dei dati perché possono generare dati sintetici che assomigliano a dati di addestramento reali, sebbene il grado di accuratezza e realismo possa variare a seconda del caso d'uso specifico e dell'addestramento del modello. Questa funzionalità è particolarmente preziosa nell'apprendimento automatico per espandere set di dati limitati e migliorare le prestazioni del modello. Inoltre, i GAN offrono una soluzione per mantenere la privacy dei dati. In settori sensibili come la sanità e la finanza, i GAN possono produrre dati sintetici che preservano le proprietà statistiche del set di dati originale senza compromettere le informazioni sensibili.
Generazione e manipolazione di video
I GAN si sono mostrati promettenti in alcune attività di generazione e manipolazione di video. Ad esempio, i GAN possono essere utilizzati per generare fotogrammi futuri da una sequenza video iniziale, aiutando in applicazioni come la previsione del movimento pedonale o la previsione dei pericoli stradali per i veicoli autonomi. Tuttavia, queste applicazioni sono ancora in fase di ricerca e sviluppo attivi. I GAN possono anche essere utilizzati per generare contenuti video completamente sintetici e migliorare i video con effetti speciali realistici.
Vantaggi dei GAN
I GAN offrono diversi vantaggi distinti, inclusa la capacità di generare dati sintetici realistici, apprendere da dati non accoppiati ed eseguire formazione senza supervisione.
Generazione di dati sintetici di alta qualità
L'architettura dei GAN consente loro di produrre dati sintetici che possono approssimare i dati del mondo reale in applicazioni come l'aumento dei dati e la creazione di video, sebbene la qualità e la precisione di questi dati possano dipendere fortemente dalle condizioni di addestramento e dai parametri del modello. Ad esempio, i DCGAN, che utilizzano le CNN per l’elaborazione ottimale delle immagini, eccellono nella generazione di immagini realistiche.
In grado di apprendere da dati non accoppiati
A differenza di alcuni modelli ML, i GAN possono apprendere da set di dati senza esempi accoppiati di input e output. Questa flessibilità consente di utilizzare i GAN in un'ampia gamma di attività in cui i dati accoppiati sono scarsi o non disponibili. Ad esempio, nelle attività di traduzione da immagine a immagine, i modelli tradizionali spesso richiedono un set di dati di immagini e le relative trasformazioni per l'addestramento. Al contrario, i GAN possono sfruttare una più ampia varietà di potenziali set di dati per la formazione.
Apprendimento non supervisionato
I GAN sono un metodo di apprendimento automatico non supervisionato, il che significa che possono essere addestrati su dati non etichettati senza una direzione esplicita. Ciò è particolarmente vantaggioso perché l'etichettatura dei dati è un processo lungo e costoso. La capacità dei GAN di apprendere dai dati non etichettati li rende preziosi per le applicazioni in cui i dati etichettati sono limitati o difficili da ottenere. I GAN possono anche essere adattati per l’apprendimento semi-supervisionato e supervisionato, consentendo loro di utilizzare anche dati etichettati.
Svantaggi dei GAN
Sebbene i GAN siano uno strumento potente nell’apprendimento automatico, la loro architettura crea una serie unica di svantaggi. Questi svantaggi includono la sensibilità agli iperparametri, elevati costi computazionali, fallimento della convergenza e un fenomeno chiamato collasso della modalità.
Sensibilità degli iperparametri
I GAN sono sensibili agli iperparametri, ovvero parametri impostati prima dell'addestramento e non appresi dai dati. Gli esempi includono le architetture di rete e il numero di esempi di formazione utilizzati in una singola iterazione. Piccoli cambiamenti in questi parametri possono influenzare in modo significativo il processo di formazione e i risultati del modello, rendendo necessaria un’ampia messa a punto per le applicazioni pratiche.
Costo computazionale elevato
A causa della loro architettura complessa, del processo di formazione iterativo e della sensibilità degli iperparametri, i GAN spesso comportano costi computazionali elevati. La formazione efficace di un GAN richiede hardware specializzato e costoso, nonché molto tempo, il che può rappresentare un ostacolo per molte organizzazioni che desiderano utilizzare i GAN.
Fallimento della convergenza
Ingegneri e ricercatori possono dedicare una notevole quantità di tempo alla sperimentazione delle configurazioni di addestramento prima di raggiungere un tasso accettabile al quale l'output del modello diventa stabile e accurato, noto come tasso di convergenza. La convergenza nei GAN può essere molto difficile da raggiungere e potrebbe non durare a lungo. Il fallimento della convergenza si verifica quando il discriminatore non riesce a decidere sufficientemente tra dati reali e falsi, ottenendo una precisione di circa il 50% perché non ha acquisito la capacità di identificare dati reali, a differenza dell'equilibrio previsto raggiunto durante un addestramento di successo. Alcuni GAN potrebbero non raggiungere mai la convergenza e richiedere analisi specializzate per essere riparati.
Collasso della modalità
I GAN sono soggetti a un problema chiamato collasso della modalità, in cui il generatore crea una gamma limitata di output e non riesce a riflettere la diversità delle distribuzioni dei dati del mondo reale. Questo problema nasce dall’architettura GAN, perché il generatore si concentra eccessivamente sulla produzione di dati che possono ingannare il discriminatore, portandolo a generare esempi simili.