
Cos'è una rete neurale?
Pubblicato: 2024-06-26Cos'è una rete neurale?
Una rete neurale è un tipo di modello di deep learning nel campo più ampio del machine learning (ML) che simula il cervello umano. Elabora i dati attraverso nodi o neuroni interconnessi disposti in strati: input, nascosti e output. Ogni nodo esegue calcoli semplici, contribuendo alla capacità del modello di riconoscere modelli e fare previsioni.
Le reti neurali di deep learning sono particolarmente efficaci nella gestione di compiti complessi come il riconoscimento di immagini e parlato, costituendo una componente cruciale di molte applicazioni di intelligenza artificiale. I recenti progressi nelle architetture delle reti neurali e nelle tecniche di addestramento hanno sostanzialmente migliorato le capacità dei sistemi di intelligenza artificiale.
Come sono strutturate le reti neurali
Come indicato dal nome, un modello di rete neurale si ispira ai neuroni, gli elementi costitutivi del cervello. Gli esseri umani adulti hanno circa 85 miliardi di neuroni, ciascuno connesso a circa 1.000 altri. Una cellula cerebrale comunica con un’altra inviando sostanze chimiche chiamate neurotrasmettitori. Se la cellula ricevente riceve una quantità sufficiente di queste sostanze chimiche, si eccita e invia le proprie sostanze chimiche a un'altra cellula.
L'unità fondamentale di quella che a volte viene chiamata rete neurale artificiale (ANN) è unnodoche, invece di essere una cellula, è una funzione matematica. Proprio come i neuroni, comunicano con altri nodi se ricevono abbastanza input.
Questo è dove finiscono le somiglianze. Le reti neurali sono strutturate in modo molto più semplice del cervello, con strati ben definiti: input, nascosto e output. Una raccolta di questi livelli è chiamatamodello.Imparano osi allenanotentando ripetutamente di generare artificialmente risultati che somiglino il più possibile ai risultati desiderati. (Ne parleremo più avanti tra un minuto.)
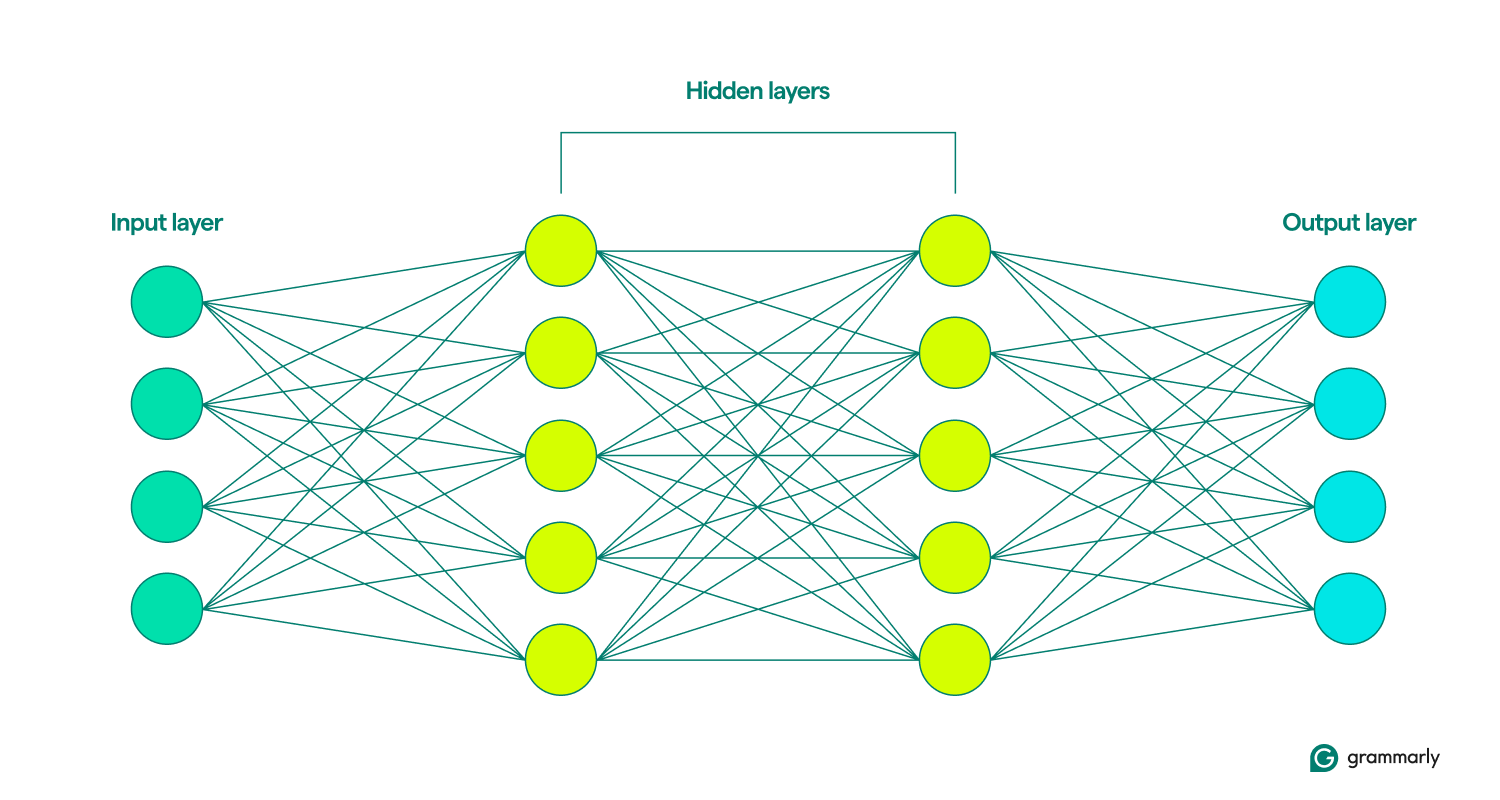
I livelli di input e output sono piuttosto autoesplicativi. La maggior parte di ciò che fanno le reti neurali avviene negli strati nascosti. Quando un nodo viene attivato dall'input di uno strato precedente, esegue i suoi calcoli e decide se trasferire l'output ai nodi dello strato successivo. Questi livelli sono così chiamati perché le loro operazioni sono invisibili all'utente finale, sebbene esistano tecniche che consentono agli ingegneri di vedere cosa succede nei cosiddetti livelli nascosti.
Quando le reti neurali includono più livelli nascosti, vengono chiamate reti di deep learning. Le moderne reti neurali profonde di solito hanno molti strati, inclusi sottolivelli specializzati che svolgono funzioni distinte. Ad esempio, alcuni sottolivelli migliorano la capacità della rete di considerare informazioni contestuali oltre l'input immediato da analizzare.
Come funzionano le reti neurali
Pensa a come imparano i bambini. Provano qualcosa, falliscono e riprovano in un modo diverso. Il ciclo continua ancora e ancora finché non hanno perfezionato il comportamento. Questo è più o meno il modo in cui apprendono anche le reti neurali.
All'inizio del loro addestramento, le reti neurali fanno ipotesi casuali. Un nodo sullo strato di input decide in modo casuale quale dei nodi nel primo strato nascosto attivare, quindi quei nodi attivano casualmente i nodi nello strato successivo e così via, finché questo processo casuale non raggiunge lo strato di output. (I modelli linguistici di grandi dimensioni come GPT-4 hanno circa 100 livelli, con decine o centinaia di migliaia di nodi in ogni livello.)
Considerando tutta la casualità, il modello confronta il suo risultato – il che probabilmente è terribile – e capisce quanto fosse sbagliato. Quindi regola la connessione di ciascun nodo agli altri nodi, modificando quanto più o meno inclini dovrebbero essere ad attivarsi in base a un dato input. Lo fa ripetutamente finché i suoi risultati non sono il più vicino possibile alle risposte desiderate.
Quindi, come fanno le reti neurali a sapere cosa dovrebbero fare? L’apprendimento automatico (ML) può essere suddiviso in diversi approcci, compreso l’apprendimento supervisionato e non supervisionato. Nell'apprendimento supervisionato, il modello viene addestrato su dati che includono etichette o risposte esplicite, come immagini abbinate a testo descrittivo. L’apprendimento non supervisionato, tuttavia, implica fornire al modello dati senza etichetta, consentendogli di identificare modelli e relazioni in modo indipendente.
Un supplemento comune a questa formazione è l'apprendimento per rinforzo, in cui il modello migliora in risposta al feedback. Spesso, questo viene fornito da valutatori umani (se hai mai fatto clic su "pollice su" o "pollice giù" per un suggerimento di un computer, hai contribuito all'apprendimento per rinforzo). Tuttavia, ci sono anche modi in cui i modelli possono apprendere in modo iterativo in modo indipendente.
È accurato e istruttivo pensare all'output di una rete neurale come a una previsione. Che si tratti di valutare l’affidabilità creditizia o di generare una canzone, i modelli di intelligenza artificiale funzionano indovinando ciò che è più probabile che sia giusto. L’intelligenza artificiale generativa, come ChatGPT, fa un ulteriore passo avanti nella previsione. Funziona in sequenza, facendo ipotesi su cosa dovrebbe venire dopo l'output appena creato. (Scopriremo perché questo può essere problematico in seguito.)
Come le reti neurali generano risposte
Una volta addestrata una rete, come elabora le informazioni che vede per prevedere la risposta corretta? Quando digiti un messaggio come "Raccontami una storia sulle fate" nell'interfaccia ChatGPT, in che modo ChatGPT decide come rispondere?
Il primo passaggio prevede che il livello di input della rete neurale suddivida il prompt in piccoli blocchi di informazioni, noti cometoken. Per una rete di riconoscimento delle immagini, i token potrebbero essere pixel. Per una rete che utilizza l'elaborazione del linguaggio naturale (NLP), come ChatGPT, un token è in genere una parola, una parte di una parola o una frase molto breve.
Una volta che la rete ha registrato i token nell'input, tali informazioni vengono passate attraverso i livelli nascosti precedentemente addestrati. I nodi che passa da uno strato al successivo analizzano sezioni sempre più grandi dell'input. In questo modo, una rete di PNL può eventualmente interpretare un’intera frase o un paragrafo, non solo una parola o una lettera.
Ora la rete può iniziare a elaborare la sua risposta, cosa che fa come una serie di previsioni parola per parola di ciò che sarebbe accaduto dopo in base a tutto ciò su cui è stata addestrata.
Considera il suggerimento: "Raccontami una storia sulle fate". Per generare una risposta, la rete neurale analizza il prompt per prevedere la prima parola più probabile. Ad esempio, potrebbe determinare che esiste una probabilità dell'80% che “The” sia la scelta migliore, una probabilità del 10% per “A” e una probabilità del 10% per “Once”. Quindi seleziona un numero in modo casuale: se il numero è compreso tra 1 e 8, sceglie “Il”; se è 9 sceglie “A”; e se è 10, sceglie "Una volta". Supponiamo che il numero casuale sia 4, che corrisponde a "The". La rete quindi aggiorna la richiesta in “Raccontami una storia sulle fate. The" e ripete il processo per prevedere la parola successiva a "The". Questo ciclo continua, con la previsione di ogni nuova parola basata sul prompt aggiornato, finché non viene generata una storia completa.
Reti diverse faranno questa previsione in modo diverso. Ad esempio, un modello di riconoscimento delle immagini può provare a prevedere quale etichetta dare all'immagine di un cane e determinare che esiste una probabilità del 70% che l'etichetta corretta sia "laboratorio di cioccolato", del 20% per "spaniel inglese" e del 10% per "golden retriever". Nel caso della classificazione, generalmente, la rete seguirà la scelta più probabile piuttosto che un'ipotesi probabilistica.
Tipi di reti neurali
Ecco una panoramica dei diversi tipi di reti neurali e di come funzionano.
- Reti neurali feedforward (FNN): in questi modelli, le informazioni fluiscono in una direzione: dallo strato di input, attraverso gli strati nascosti e infine allo strato di output.Questo tipo di modello è ideale per attività di previsione più semplici, come il rilevamento di frodi con carte di credito.
- Reti neurali ricorrenti (RNN): a differenza delle FNN, le RNN considerano gli input precedenti quando generano una previsione.Ciò li rende adatti ai compiti di elaborazione del linguaggio poiché la fine di una frase generata in risposta a un prompt dipende da come inizia la frase.
- Reti di memoria a lungo termine (LSTM): gli LSTM dimenticano selettivamente le informazioni, il che consente loro di lavorare in modo più efficiente.Ciò è fondamentale per l'elaborazione di grandi quantità di testo; ad esempio, l'aggiornamento di Google Translate del 2016 alla traduzione automatica neurale si basava sugli LSTM.
- Reti neurali convoluzionali (CNN): le CNN funzionano meglio durante l'elaborazione delle immagini.Usanolivelli convoluzionaliper scansionare l'intera immagine e cercare caratteristiche come linee o forme. Ciò consente alle CNN di considerare la posizione spaziale, ad esempio determinare se un oggetto si trova nella metà superiore o inferiore dell'immagine, e anche di identificare una forma o un tipo di oggetto indipendentemente dalla sua posizione.
- Reti generative avversarie (GAN): le GAN vengono spesso utilizzate per generare nuove immagini basate su una descrizione o su un'immagine esistente.Sono strutturati come una competizione tra due reti neurali: una retegeneratrice, che cerca di ingannare una retediscriminatricefacendole credere che un input falso sia reale.
- Trasformatori e reti di attenzione: i trasformatori sono responsabili dell’attuale esplosione delle capacità dell’intelligenza artificiale.Questi modelli incorporano un riflettore attentivo che consente loro di filtrare i propri input per concentrarsi sugli elementi più importanti e su come tali elementi si relazionano tra loro, anche attraverso le pagine di testo. I trasformatori possono anche addestrarsi su enormi quantità di dati, quindi modelli come ChatGPT e Gemini sono chiamatimodelli di linguaggio di grandi dimensioni (LLM).
Applicazioni delle reti neurali
Ce ne sono troppi da elencare, quindi ecco una selezione di modi in cui le reti neurali vengono utilizzate oggi, con un'enfasi sul linguaggio naturale.

Assistenza alla scrittura: i Transformers hanno trasformato il modo in cui i computer possono aiutare le persone a scrivere meglio.Gli strumenti di scrittura AI, come Grammarly, offrono riscritture a livello di frasi e paragrafi per migliorare il tono e la chiarezza. Questo tipo di modello ha anche migliorato la velocità e la precisione dei suggerimenti grammaticali di base. Scopri di più su come Grammarly utilizza l'intelligenza artificiale.
Generazione di contenuti: se hai utilizzato ChatGPT o DALL-E, hai sperimentato in prima persona l'intelligenza artificiale generativa.I trasformatori hanno rivoluzionato la capacità dei computer di creare media in sintonia con gli esseri umani, dalle favole della buonanotte ai rendering architettonici iperrealistici.
Riconoscimento vocale: i computer migliorano ogni giorno nel riconoscere il parlato umano.Con le nuove tecnologie che consentono loro di considerare un contesto più ampio, i modelli sono diventati sempre più accurati nel riconoscere ciò che l’oratore intende dire, anche se i suoni da soli potrebbero avere molteplici interpretazioni.
Diagnosi e ricerca medica: le reti neurali eccellono nel rilevamento e nella classificazione dei modelli, che vengono sempre più utilizzati per aiutare i ricercatori e gli operatori sanitari a comprendere e affrontare le malattie.Ad esempio, dobbiamo in parte ringraziare l’intelligenza artificiale per il rapido sviluppo dei vaccini contro il Covid-19.
Sfide e limiti delle reti neurali
Ecco un breve sguardo ad alcune, ma non a tutte, le questioni sollevate dalle reti neurali.
Bias: una rete neurale può imparare solo da ciò che le è stato detto.Se è esposto a contenuti sessisti o razzisti, è probabile che anche il suo output sarà sessista o razzista. Ciò può verificarsi nella traduzione da una lingua senza genere a una con genere, dove gli stereotipi persistono senza un'esplicita identificazione di genere.
Overfitting: un modello addestrato in modo improprio può leggere troppo nei dati che gli sono stati forniti e avere difficoltà con nuovi input.Ad esempio, i software di riconoscimento facciale sviluppati principalmente su persone di una certa etnia potrebbero funzionare male con volti di altre razze. Oppure un filtro antispam potrebbe non rilevare un nuovo tipo di posta indesiderata perché è troppo concentrato su schemi già visti.
Allucinazioni: gran parte dell’intelligenza artificiale generativa di oggi utilizza in una certa misura la probabilità per scegliere cosa produrre piuttosto che selezionare sempre la scelta più alta.Questo approccio lo aiuta a essere più creativo e a produrre testi che sembrano più naturali, ma può anche portarlo a fare affermazioni semplicemente false. (Questo è anche il motivo per cui gli LLM a volte sbagliano i calcoli di base.) Sfortunatamente, queste allucinazioni sono difficili da rilevare a meno che non si conosca meglio o si verifichino i fatti con altre fonti.
Interpretabilità: spesso è impossibile sapere esattamente come una rete neurale fa previsioni.Anche se questo può essere frustrante dal punto di vista di chi cerca di migliorare il modello, può anche avere conseguenze, poiché si fa sempre più affidamento sull’intelligenza artificiale per prendere decisioni che hanno un grande impatto sulla vita delle persone. Alcuni modelli utilizzati oggi non si basano su reti neurali proprio perché i loro creatori vogliono essere in grado di ispezionare e comprendere ogni fase del processo.
Proprietà intellettuale: molti credono che i LLM violino il diritto d'autore incorporando scritti e altre opere d'arte senza autorizzazione.Sebbene tendano a non riprodurre direttamente opere protette da copyright, è noto che questi modelli creano immagini o frasi che probabilmente derivano da artisti specifici o addirittura creano opere nello stile distintivo di un artista quando richiesto.
Consumo energetico: tutto questo addestramento e funzionamento dei modelli di trasformatori consuma un'energia enorme.Infatti, nel giro di pochi anni, l’intelligenza artificiale potrebbe consumare tanta energia quanto quella della Svezia o dell’Argentina. Ciò evidenzia la crescente importanza di considerare le fonti energetiche e l’efficienza nello sviluppo dell’IA.
Il futuro delle reti neurali
Predire il futuro dell’intelligenza artificiale è notoriamente difficile. Nel 1970, uno dei più importanti ricercatori sull’intelligenza artificiale predisse che “tra tre e otto anni avremo una macchina con l’intelligenza generale di un essere umano medio”. (Non siamo ancora molto vicini all’intelligenza generale artificiale (AGI). Almeno la maggior parte delle persone non la pensa così.)
Possiamo però evidenziare alcune tendenze a cui prestare attenzione. Modelli più efficienti ridurrebbero il consumo energetico e gestirebbero reti neurali più potenti direttamente su dispositivi come gli smartphone. Nuove tecniche di addestramento potrebbero consentire previsioni più utili con meno dati di addestramento. Una svolta nell’interpretabilità potrebbe aumentare la fiducia e aprire nuovi percorsi per migliorare l’output della rete neurale. Infine, la combinazione dell’informatica quantistica e delle reti neurali potrebbe portare a innovazioni che possiamo solo iniziare a immaginare.
Conclusione
Le reti neurali, ispirate alla struttura e alla funzione del cervello umano, sono fondamentali per la moderna intelligenza artificiale. Eccellono nelle attività di riconoscimento e previsione di modelli, alla base di molte delle odierne applicazioni di intelligenza artificiale, dal riconoscimento di immagini e parlato all'elaborazione del linguaggio naturale. Con i progressi nell’architettura e nelle tecniche di training, le reti neurali continuano a portare miglioramenti significativi nelle capacità dell’intelligenza artificiale.
Nonostante il loro potenziale, le reti neurali devono affrontare sfide quali bias, overfitting e un elevato consumo di energia. Affrontare questi problemi è fondamentale poiché l’intelligenza artificiale continua ad evolversi. Guardando al futuro, le innovazioni nell’efficienza dei modelli, nell’interpretabilità e nell’integrazione con l’informatica quantistica promettono di espandere ulteriormente le possibilità delle reti neurali, portando potenzialmente ad applicazioni ancora più trasformative.