
Nozioni di base sulla rete neurale ricorrente: cosa devi sapere
Pubblicato: 2024-09-19Le reti neurali ricorrenti (RNN) sono metodi essenziali nei regni dell'analisi dei dati, dell'apprendimento automatico (ML) e del deep learning. Questo articolo mira a esplorare le RNN e a dettagliarne funzionalità, applicazioni, vantaggi e svantaggi nel contesto più ampio del deep learning.
Sommario
Cos'è un RNN?
Come funzionano gli RNN
Tipi di RNN
RNN contro trasformatori e CNN
Applicazioni delle RNN
Vantaggi
Svantaggi
Cos'è una rete neurale ricorrente?
Una rete neurale ricorrente è una rete neurale profonda in grado di elaborare dati sequenziali mantenendo una memoria interna, consentendole di tenere traccia degli input passati per generare output. Le RNN sono una componente fondamentale del deep learning e sono particolarmente adatte per attività che coinvolgono dati sequenziali.
Il “ricorrente” in “rete neurale ricorrente” si riferisce al modo in cui il modello combina le informazioni provenienti dagli input passati con gli input attuali. Le informazioni provenienti dai vecchi input vengono archiviate in una sorta di memoria interna, chiamata “stato nascosto”. Si ripresenta, reimmettendo in se stesso i calcoli precedenti per creare un flusso continuo di informazioni.
Dimostriamolo con un esempio: supponiamo di voler utilizzare un RNN per rilevare il sentimento (positivo o negativo) della frase "Ha mangiato la torta felicemente". La RNN elaborerebbe la parolahe, aggiornerebbe il suo stato nascosto per incorporare quella parola, quindi passerebbe adate, combinandola con ciò che ha imparato dahe, e così via con ogni parola fino al completamento della frase. Per dirla in prospettiva, un essere umano che legge questa frase aggiornerebbe la propria comprensione con ogni parola. Una volta letta e compresa l'intera frase, l'essere umano può dire che la frase è positiva o negativa. Questo processo umano di comprensione è ciò che lo stato nascosto cerca di approssimare.
Le RNN sono uno dei modelli fondamentali di deep learning. Hanno svolto molto bene le attività di elaborazione del linguaggio naturale (PNL), sebbene i trasformatori li abbiano soppiantati. I trasformatori sono architetture di rete neurale avanzate che migliorano le prestazioni della RNN, ad esempio, elaborando i dati in parallelo e essendo in grado di scoprire relazioni tra parole distanti nel testo di partenza (utilizzando meccanismi di attenzione). Tuttavia, le RNN sono ancora utili per i dati di serie temporali e per le situazioni in cui sono sufficienti modelli più semplici.
Come funzionano gli RNN
Per descrivere in dettaglio come funzionano gli RNN, torniamo all'attività di esempio precedente: classificare il sentimento della frase "Ha mangiato la torta felicemente".
Iniziamo con un RNN addestrato che accetta input di testo e restituisce un output binario (1 rappresenta il positivo e 0 rappresenta il negativo). Prima che l'input venga fornito al modello, lo stato nascosto è generico: è stato appreso dal processo di training ma non è ancora specifico dell'input.
La prima parola,He, viene passata al modello. All'interno dell'RNN, il suo stato nascosto viene quindi aggiornato (allo stato nascosto h1) per incorporare la parolaHe. Successivamente, la parolaateviene passata all'RNN e h1 viene aggiornato (in h2) per includere questa nuova parola. Questo processo si ripete finché non viene passata l'ultima parola. Lo stato nascosto (h4) viene aggiornato per includere l'ultima parola. Quindi lo stato nascosto aggiornato viene utilizzato per generare uno 0 o un 1.
Ecco una rappresentazione visiva di come funziona il processo RNN:
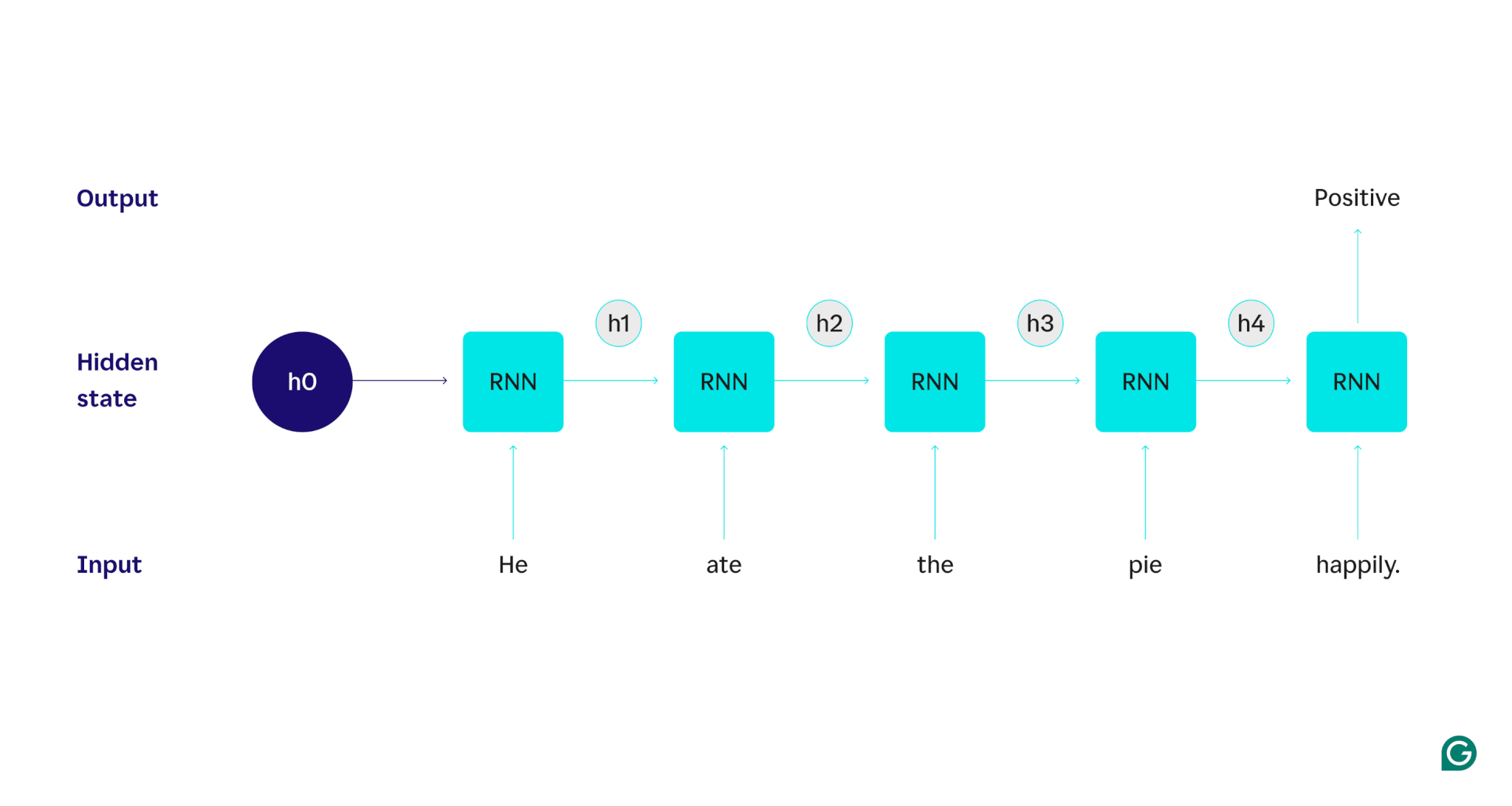
Questa ricorrenza è il nucleo della RNN, ma ci sono alcune altre considerazioni:
- Incorporamento del testo:RNN non può elaborare direttamente il testo poiché funziona solo su rappresentazioni numeriche. Il testo deve essere convertito in incorporamenti prima di poter essere elaborato da un RNN.
- Generazione di output:l'RNN genererà un output in ogni fase. Tuttavia, l'output potrebbe non essere molto accurato finché non viene elaborata la maggior parte dei dati di origine. Ad esempio, dopo aver elaborato solo la parte "Ha mangiato" della frase, l'RNN potrebbe non essere sicuro se rappresenti un sentimento positivo o negativo: "Ha mangiato" potrebbe risultare neutro. Solo dopo aver elaborato l'intera frase l'output della RNN sarebbe stato accurato.
- Formazione della RNN:la RNN deve essere addestrata per eseguire l'analisi del sentiment in modo accurato. La formazione prevede l'utilizzo di numerosi esempi etichettati (ad esempio, "Ha mangiato la torta con rabbia", etichettato come negativo), l'esecuzione degli stessi attraverso l'RNN e l'adeguamento del modello in base a quanto sono lontane le sue previsioni. Questo processo imposta il valore predefinito e il meccanismo di modifica per lo stato nascosto, consentendo all'RNN di apprendere quali parole sono significative per il tracciamento in tutto l'input.
Tipi di reti neurali ricorrenti
Esistono diversi tipi di RNN, ciascuno diverso nella struttura e nell'applicazione. Le RNN di base differiscono principalmente nella dimensione dei loro input e output. Le RNN avanzate, come le reti di memoria a lungo termine (LSTM), risolvono alcune delle limitazioni delle RNN di base.
RNN di base
RNN uno a uno:questo RNN accetta un input di lunghezza uno e restituisce un output di lunghezza uno. Pertanto, in realtà non si verifica alcuna ricorrenza, rendendola una rete neurale standard piuttosto che una RNN. Un esempio di RNN uno-a-uno sarebbe un classificatore di immagini, in cui l'input è una singola immagine e l'output è un'etichetta (ad esempio, "uccello").
RNN uno-a-molti:questo RNN accetta un input di lunghezza uno e restituisce un output multiparte. Ad esempio, in un'attività di didascalia di immagini, l'input è un'immagine e l'output è una sequenza di parole che descrivono l'immagine (ad esempio, "Un uccello attraversa un fiume in una giornata soleggiata").
RNN molti-a-uno:questo RNN accetta un input multiparte (ad esempio, una frase, una serie di immagini o dati di serie temporali) e restituisce un output di lunghezza uno. Ad esempio, un classificatore del sentiment di una frase (come quello di cui abbiamo parlato), dove l'input è una frase e l'output è una singola etichetta del sentiment (positiva o negativa).
RNN molti-a-molti:questo RNN accetta un input multiparte e restituisce un output multiparte. Un esempio è un modello di riconoscimento vocale, in cui l'input è una serie di forme d'onda audio e l'output è una sequenza di parole che rappresentano il contenuto parlato.
RNN avanzata: memoria a lungo termine (LSTM)
Le reti di memoria a lungo termine sono progettate per risolvere un problema significativo con le RNN standard: dimenticano le informazioni su input lunghi. Nelle RNN standard, lo stato nascosto è fortemente orientato verso le parti recenti dell'input. In un input lungo migliaia di parole, l'RNN dimenticherà dettagli importanti dalle frasi di apertura. Gli LSTM hanno un'architettura speciale per aggirare questo problema dell'oblio. Hanno moduli che selezionano e scelgono quali informazioni ricordare e dimenticare esplicitamente. Quindi le informazioni recenti ma inutili verranno dimenticate, mentre le informazioni vecchie ma rilevanti verranno conservate. Di conseguenza, gli LSTM sono molto più comuni degli RNN standard: semplicemente funzionano meglio su attività complesse o lunghe. Tuttavia, non sono perfetti poiché scelgono comunque di dimenticare gli oggetti.

RNN contro trasformatori e CNN
Altri due modelli comuni di deep learning sono le reti neurali convoluzionali (CNN) e i trasformatori. In cosa differiscono?
RNN e trasformatori
Sia gli RNN che i trasformatori sono ampiamente utilizzati nella PNL. Tuttavia, differiscono in modo significativo nelle architetture e negli approcci all'elaborazione degli input.
Architettura ed elaborazione
- RNN:gli RNN elaborano l'input in sequenza, una parola alla volta, mantenendo uno stato nascosto che trasporta informazioni dalle parole precedenti. Questa natura sequenziale significa che le RNN possono lottare con dipendenze a lungo termine a causa di questa dimenticanza, in cui le informazioni precedenti possono andare perse man mano che la sequenza avanza.
- Trasformatori:i trasformatori utilizzano un meccanismo chiamato "attenzione" per elaborare l'input. A differenza degli RNN, i trasformatori esaminano l'intera sequenza simultaneamente, confrontando ogni parola con ogni altra parola. Questo approccio elimina il problema dell'oblio, poiché ogni parola ha accesso diretto all'intero contesto di input. Grazie a questa funzionalità, i trasformatori hanno mostrato prestazioni superiori in attività come la generazione di testo e l'analisi del sentiment.
Parallelizzazione
- RNN:la natura sequenziale delle RNN significa che il modello deve completare l'elaborazione di una parte dell'input prima di passare a quella successiva. Questo richiede molto tempo, poiché ogni passaggio dipende da quello precedente.
- Trasformatori:i trasformatori elaborano tutte le parti dell'input simultaneamente, poiché la loro architettura non si basa su uno stato nascosto sequenziale. Ciò li rende molto più parallelizzabili ed efficienti. Ad esempio, se l'elaborazione di una frase richiede 5 secondi per parola, un RNN impiegherebbe 25 secondi per una frase di 5 parole, mentre un trasformatore impiegherebbe solo 5 secondi.
Implicazioni pratiche
Grazie a questi vantaggi, i trasformatori sono più ampiamente utilizzati nell'industria. Tuttavia, le RNN, in particolare le reti di memoria a lungo termine (LSTM), possono ancora essere efficaci per compiti più semplici o quando si tratta di sequenze più brevi. Gli LSTM vengono spesso utilizzati come moduli di archiviazione di memoria critici in grandi architetture di machine learning.
RNN contro CNN
Le CNN sono fondamentalmente diverse dalle RNN in termini di dati che gestiscono e di meccanismi operativi.
Tipo di dati
- RNN:gli RNN sono progettati per dati sequenziali, come testo o serie temporali, in cui l'ordine dei punti dati è importante.
- CNN:le CNN vengono utilizzate principalmente per dati spaziali, come le immagini, in cui l'attenzione è sulle relazioni tra punti dati adiacenti (ad esempio, il colore, l'intensità e altre proprietà di un pixel in un'immagine sono strettamente correlate alle proprietà di altri pixel vicini). pixel).
Operazione
- RNN:gli RNN mantengono una memoria dell'intera sequenza, rendendoli adatti a compiti in cui il contesto e la sequenza contano.
- CNN:le CNN operano esaminando le regioni locali dell'input (ad esempio, i pixel vicini) attraverso strati convoluzionali. Ciò li rende molto efficaci per l'elaborazione delle immagini ma meno per i dati sequenziali, dove le dipendenze a lungo termine potrebbero essere più importanti.
Lunghezza immessa
- RNN:gli RNN possono gestire sequenze di input di lunghezza variabile con una struttura meno definita, rendendoli flessibili per diversi tipi di dati sequenziali.
- CNN:le CNN in genere richiedono input di dimensione fissa, il che può rappresentare una limitazione per la gestione di sequenze di lunghezza variabile.
Applicazioni delle RNN
Gli RNN sono ampiamente utilizzati in vari campi grazie alla loro capacità di gestire dati sequenziali in modo efficace.
Elaborazione del linguaggio naturale
La lingua è una forma di dati altamente sequenziale, quindi le RNN si comportano bene nei compiti linguistici. Gli RNN eccellono in attività quali la generazione di testi, l'analisi del sentiment, la traduzione e il riepilogo. Con librerie come PyTorch, qualcuno potrebbe creare un semplice chatbot utilizzando un RNN e alcuni gigabyte di esempi di testo.
Riconoscimento vocale
Il riconoscimento vocale è il linguaggio al suo interno e quindi è anche altamente sequenziale. Per questo compito potrebbe essere utilizzato un RNN molti-a-molti. Ad ogni passaggio, l'RNN acquisisce lo stato nascosto precedente e la forma d'onda, emettendo la parola associata alla forma d'onda (in base al contesto della frase fino a quel momento).
Generazione musicale
Anche la musica è altamente sequenziale. I ritmi precedenti di una canzone influenzano fortemente i ritmi futuri. Un RNN molti-a-molti potrebbe prendere alcuni battiti iniziali come input e quindi generare battiti aggiuntivi come desiderato dall'utente. In alternativa, potrebbe prendere un input di testo come “jazz melodico” e produrre la sua migliore approssimazione dei ritmi jazz melodici.
Vantaggi delle RNN
Sebbene le RNN non siano più il modello di PNL de facto, hanno ancora alcuni usi a causa di alcuni fattori.
Buone prestazioni sequenziali
Gli RNN, in particolare gli LSTM, funzionano bene con dati sequenziali. Gli LSTM, con la loro architettura di memoria specializzata, possono gestire input sequenziali lunghi e complessi. Ad esempio, prima dell’era dei trasformatori Google Translate funzionava su un modello LSTM. Gli LSTM possono essere utilizzati per aggiungere moduli di memoria strategici quando le reti basate su trasformatori vengono combinate per formare architetture più avanzate.
Modelli più piccoli e più semplici
Gli RNN di solito hanno meno parametri del modello rispetto ai trasformatori. Gli strati di attenzione e feedforward nei trasformatori richiedono più parametri per funzionare in modo efficace. Le RNN possono essere addestrate con meno esecuzioni ed esempi di dati, rendendole più efficienti per casi d'uso più semplici. Ciò si traduce in modelli più piccoli, meno costosi e più efficienti che sono comunque sufficientemente performanti.
Svantaggi delle RNN
Le RNN sono cadute in disgrazia per un motivo: i Transformer, nonostante le loro dimensioni maggiori e il processo di addestramento, non hanno gli stessi difetti delle RNN.
Memoria limitata
Lo stato nascosto nelle RNN standard influenza pesantemente gli input recenti, rendendo difficile mantenere dipendenze a lungo raggio. Le attività con input lunghi non funzionano altrettanto bene con gli RNN. Anche se gli LSTM mirano ad affrontare questo problema, si limitano solo a mitigarlo e non a risolverlo completamente. Molte attività di intelligenza artificiale richiedono la gestione di input lunghi, rendendo la memoria limitata uno svantaggio significativo.
Non parallelizzabile
Ogni esecuzione del modello RNN dipende dall'output dell'esecuzione precedente, in particolare dallo stato nascosto aggiornato. Di conseguenza, l'intero modello deve essere elaborato in sequenza per ciascuna parte di un input. Al contrario, trasformatori e CNN possono elaborare l’intero input simultaneamente. Ciò consente l'elaborazione parallela su più GPU, accelerando notevolmente il calcolo. La mancanza di parallelizzabilità delle RNN porta a un addestramento più lento, a una generazione di output più lenta e a una quantità massima inferiore di dati da cui è possibile apprendere.
Problemi di gradiente
L'addestramento delle RNN può essere impegnativo perché il processo di backpropagation deve passare attraverso ogni fase di input (backpropagation nel tempo). A causa dei numerosi passaggi temporali, i gradienti, che indicano come regolare ciascun parametro del modello, possono peggiorare e diventare inefficaci. I gradienti possono fallire svanendo, il che significa che diventano molto piccoli e il modello non può più usarli per apprendere, o esplodendo, in cui i gradienti diventano molto grandi e il modello supera i suoi aggiornamenti, rendendo il modello inutilizzabile. Trovare un equilibrio tra questi problemi è difficile.