
Cos'è un codificatore automatico? Una guida per principianti
Pubblicato: 2024-10-28Gli autocodificatori sono una componente essenziale del deep learning, in particolare nelle attività di machine learning non supervisionate. In questo articolo esploreremo come funzionano gli autoencoder, la loro architettura e i vari tipi disponibili. Scoprirai anche le loro applicazioni nel mondo reale, insieme ai vantaggi e ai compromessi legati al loro utilizzo.
Sommario
- Cos'è un codificatore automatico?
- Architettura del codificatore automatico
- Tipi di codificatori automatici
- Applicazione
- Vantaggi
- Svantaggi
Cos'è un codificatore automatico?
Gli autocodificatori sono un tipo di rete neurale utilizzata nel deep learning per apprendere rappresentazioni efficienti e di dimensione inferiore dei dati di input, che vengono poi utilizzate per ricostruire i dati originali. In questo modo, questa rete apprende le caratteristiche più essenziali dei dati durante la formazione senza richiedere etichette esplicite, rendendola parte dell'apprendimento autosuperato. I codificatori automatici sono ampiamente applicati in attività quali la rimozione del rumore delle immagini, il rilevamento di anomalie e la compressione dei dati, dove la loro capacità di comprimere e ricostruire i dati è preziosa.
Architettura del codificatore automatico
Un codificatore automatico è composto da tre parti: un codificatore, un collo di bottiglia (noto anche come spazio latente o codice) e un decodificatore. Questi componenti lavorano insieme per acquisire le caratteristiche principali dei dati di input e utilizzarli per generare ricostruzioni accurate.
Gli autocodificatori ottimizzano il loro output regolando i pesi sia del codificatore che del decodificatore, con l'obiettivo di produrre una rappresentazione compressa dell'input che preservi le caratteristiche critiche. Questa ottimizzazione minimizza l'errore di ricostruzione, che rappresenta la differenza tra i dati di input e quelli di output.
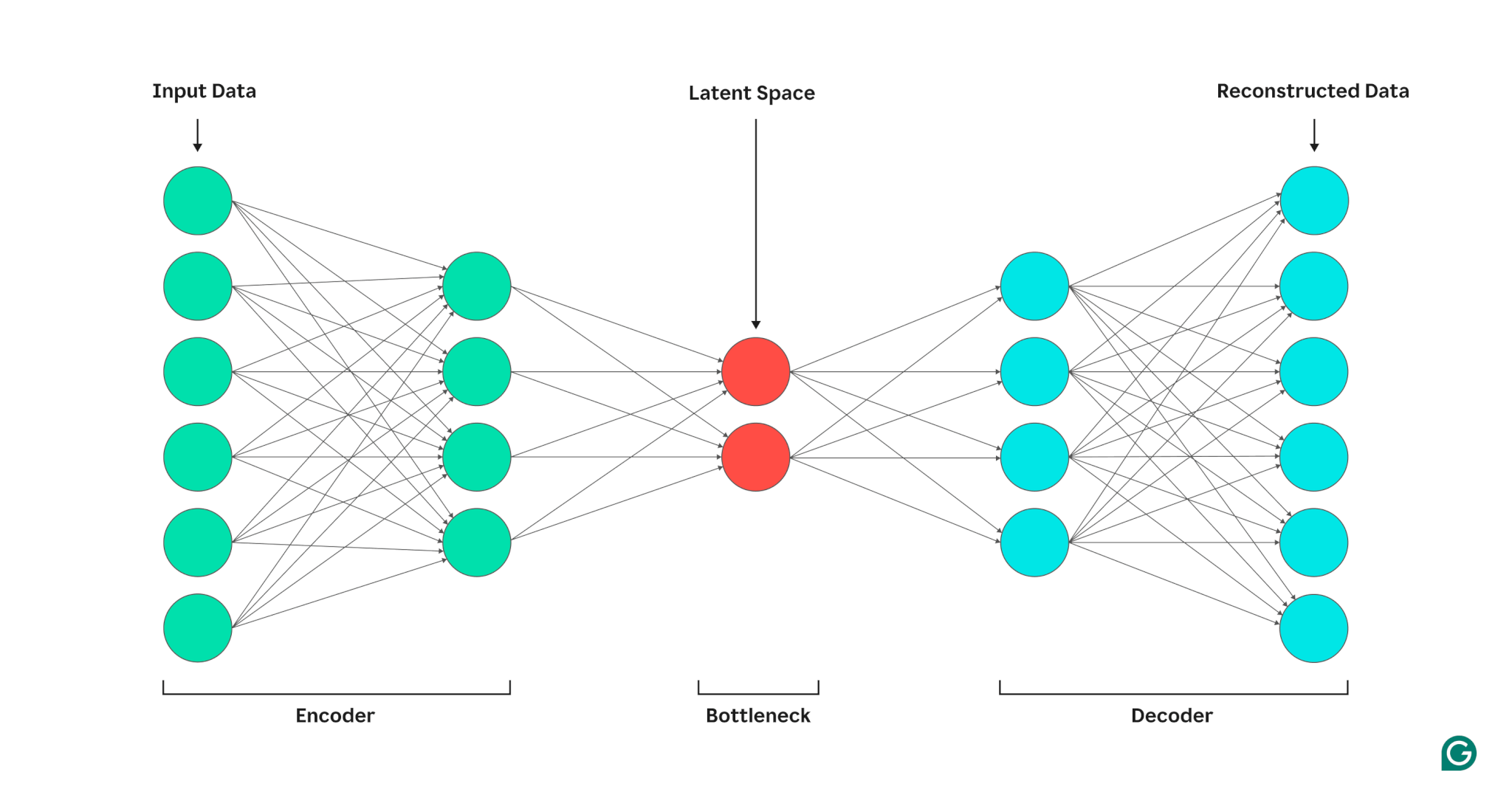
Codificatore
Innanzitutto, il codificatore comprime i dati di input in una rappresentazione più efficiente. I codificatori sono generalmente costituiti da più livelli con meno nodi in ciascuno strato. Man mano che i dati vengono elaborati attraverso ogni livello, il numero ridotto di nodi costringe la rete ad apprendere le caratteristiche più importanti dei dati per creare una rappresentazione che può essere archiviata in ogni livello. Questo processo, noto come riduzione della dimensionalità, trasforma l'input in un riepilogo compatto delle caratteristiche chiave dei dati. Gli iperparametri chiave nel codificatore includono il numero di livelli e neuroni per livello, che determinano la profondità e la granularità della compressione, e la funzione di attivazione, che determina il modo in cui le caratteristiche dei dati vengono rappresentate e trasformate su ciascun livello.
Collo di bottiglia
Il collo di bottiglia, noto anche come spazio latente o codice, è il punto in cui viene archiviata la rappresentazione compressa dei dati di input durante l'elaborazione. Il collo di bottiglia ha un numero limitato di nodi; ciò limita la quantità di dati che possono essere archiviati e determina il livello di compressione. Il numero di nodi nel collo di bottiglia è un iperparametro sintonizzabile, che consente agli utenti di controllare il compromesso tra compressione e conservazione dei dati. Se il collo di bottiglia è troppo piccolo, l'autoencoder può ricostruire i dati in modo errato a causa della perdita di dettagli importanti. D'altra parte, se il collo di bottiglia è troppo grande, l'autocodificatore può semplicemente copiare i dati di input invece di apprendere una rappresentazione generale significativa.
Decodificatore
In questa fase finale, il decodificatore ricrea i dati originali dal modulo compresso utilizzando le funzionalità chiave apprese durante il processo di codifica. La qualità di questa decompressione viene quantificata utilizzando l'errore di ricostruzione, che è essenzialmente una misura di quanto diversi sono i dati ricostruiti dall'input. L'errore di ricostruzione viene generalmente calcolato utilizzando l'errore quadratico medio (MSE). Poiché MSE misura la differenza al quadrato tra i dati originali e quelli ricostruiti, fornisce un modo matematicamente semplice per penalizzare più pesantemente gli errori di ricostruzione più grandi.
Tipi di codificatori automatici
Esistono diversi tipi di autoencoder specializzati, ciascuno ottimizzato per applicazioni specifiche, simili ad altre reti neurali.
Denoising degli autocodificatori
Gli autoencoder di rimozione del rumore sono progettati per ricostruire dati puliti da input rumorosi o danneggiati. Durante l'addestramento, il rumore viene aggiunto intenzionalmente ai dati di input, consentendo al modello di apprendere caratteristiche che rimangono coerenti nonostante il rumore. Gli output vengono quindi confrontati con gli input puliti originali. Questo processo rende i codificatori automatici di denoising estremamente efficaci nelle attività di riduzione del rumore audio e delle immagini, inclusa la rimozione del rumore di fondo nelle videoconferenze.
Codificatori automatici sparsi
Gli autocodificatori sparsi limitano il numero di neuroni attivi in un dato momento, incoraggiando la rete ad apprendere rappresentazioni dei dati più efficienti rispetto agli autocodificatori standard. Questo vincolo di scarsità viene applicato attraverso una penalità che scoraggia l'attivazione di più neuroni rispetto a una soglia specificata. I codificatori automatici sparsi semplificano i dati ad alta dimensione preservando le caratteristiche essenziali, rendendoli preziosi per attività come l'estrazione di caratteristiche interpretabili e la visualizzazione di set di dati complessi.
Codificatori automatici variazionali (VAE)
A differenza dei tipici codificatori automatici, i VAE generano nuovi dati codificando le caratteristiche dei dati di addestramento in una distribuzione di probabilità, anziché in un punto fisso. Campionando da questa distribuzione, i VAE possono generare nuovi dati diversi, invece di ricostruire i dati originali dall'input. Questa funzionalità rende i VAE utili per attività generative, inclusa la generazione di dati sintetici. Ad esempio, nella generazione di immagini, un VAE addestrato su un set di dati di numeri scritti a mano può creare nuove cifre dall'aspetto realistico basate sul set di addestramento che non sono repliche esatte.

Codificatori automatici contrattivi
Gli autocodificatori contrattivi introducono un ulteriore termine di penalità durante il calcolo dell'errore di ricostruzione, incoraggiando il modello ad apprendere rappresentazioni di caratteristiche resistenti al rumore. Questa penalità aiuta a prevenire l'adattamento eccessivo promuovendo l'apprendimento delle funzionalità che è invariante rispetto a piccole variazioni nei dati di input. Di conseguenza, gli autoencoder contrattivi sono più resistenti al rumore rispetto agli autoencoder standard.
Codificatori automatici convoluzionali (CAE)
I CAE utilizzano livelli convoluzionali per acquisire gerarchie e modelli spaziali all'interno di dati ad alta dimensione. L'uso di livelli convoluzionali rende i CAE particolarmente adatti per l'elaborazione dei dati di immagine. I CAE sono comunemente utilizzati in attività come la compressione delle immagini e il rilevamento di anomalie nelle immagini.
Applicazioni degli autocodificatori nell'intelligenza artificiale
I codificatori automatici hanno diverse applicazioni, come la riduzione della dimensionalità, la rimozione del rumore delle immagini e il rilevamento di anomalie.
Riduzione della dimensionalità
I codificatori automatici sono strumenti efficaci per ridurre la dimensionalità dei dati di input preservando le caratteristiche principali. Questo processo è utile per attività come la visualizzazione di set di dati ad alta dimensione e la compressione dei dati. Semplificando i dati, la riduzione della dimensionalità migliora anche l’efficienza computazionale, riducendo sia le dimensioni che la complessità.
Rilevamento anomalie
Apprendendo le caratteristiche chiave di un set di dati di destinazione, gli autocodificatori possono distinguere tra dati normali e anomali quando ricevono un nuovo input. La deviazione dalla norma è indicata da tassi di errore di ricostruzione superiori al normale. Pertanto, gli autocodificatori possono essere applicati a diversi domini come la manutenzione predittiva e la sicurezza delle reti informatiche.
Denoising
Gli autocodificatori di rimozione del rumore possono pulire i dati rumorosi imparando a ricostruirli da input di addestramento rumorosi. Questa funzionalità rende i codificatori automatici di rimozione del rumore preziosi per attività come l'ottimizzazione delle immagini, incluso il miglioramento della qualità delle fotografie sfocate. Gli autoencoder di denoising sono utili anche nell'elaborazione dei segnali, dove possono pulire i segnali rumorosi per un'elaborazione e un'analisi più efficienti.
Vantaggi degli autoencoder
I codificatori automatici presentano una serie di vantaggi chiave. Questi includono la capacità di apprendere da dati senza etichetta, apprendere automaticamente funzionalità senza istruzioni esplicite ed estrarre funzionalità non lineari.
In grado di imparare da dati senza etichetta
I codificatori automatici sono un modello di apprendimento automatico non supervisionato, il che significa che possono apprendere le funzionalità dei dati sottostanti da dati senza etichetta. Questa capacità significa che gli autocodificatori possono essere applicati ad attività in cui i dati etichettati potrebbero essere scarsi o non disponibili.
Apprendimento automatico delle funzionalità
Le tecniche di estrazione delle caratteristiche standard, come l'analisi delle componenti principali (PCA), sono spesso poco pratiche quando si tratta di gestire set di dati complessi e/o di grandi dimensioni. Poiché gli autocodificatori sono stati progettati pensando ad attività come la riduzione della dimensionalità, possono apprendere automaticamente le caratteristiche e i modelli chiave nei dati senza la progettazione manuale delle caratteristiche.
Estrazione di caratteristiche non lineari
I codificatori automatici possono gestire relazioni non lineari nei dati di input, consentendo al modello di acquisire caratteristiche chiave da rappresentazioni di dati più complesse. Questa capacità significa che gli autoencoder hanno un vantaggio rispetto ai modelli che possono funzionare solo con dati lineari, poiché possono gestire set di dati più complessi.
Limitazioni degli autoencoder
Come altri modelli ML, i codificatori automatici presentano una serie di svantaggi. Questi includono la mancanza di interpretabilità, la necessità di grandi set di dati di addestramento per funzionare bene e capacità di generalizzazione limitate.
Mancanza di interpretabilità
Analogamente ad altri modelli ML complessi, gli autocodificatori soffrono di mancanza di interpretabilità, il che significa che è difficile comprendere la relazione tra i dati di input e l'output del modello. Negli autocodificatori, questa mancanza di interpretabilità si verifica perché gli autocodificatori apprendono automaticamente le funzionalità rispetto ai modelli tradizionali, in cui le funzionalità sono definite esplicitamente. Questa rappresentazione delle caratteristiche generate dalla macchina è spesso altamente astratta e tende a mancare di caratteristiche interpretabili dall'uomo, rendendo difficile capire cosa significhi ciascun componente nella rappresentazione.
Richiedono set di dati di addestramento di grandi dimensioni
I codificatori automatici in genere richiedono set di dati di addestramento di grandi dimensioni per apprendere rappresentazioni generalizzabili delle caratteristiche chiave dei dati. Dati i set di dati di addestramento di piccole dimensioni, gli autocodificatori possono tendere ad adattarsi eccessivamente, portando a una scarsa generalizzazione quando vengono presentati nuovi dati. I set di dati di grandi dimensioni, d'altro canto, forniscono la diversità necessaria affinché il codificatore automatico possa apprendere funzionalità dei dati che possono essere applicate in un'ampia gamma di scenari.
Generalizzazione limitata su nuovi dati
Gli autocodificatori addestrati su un set di dati spesso hanno capacità di generalizzazione limitate, il che significa che non riescono ad adattarsi ai nuovi set di dati. Questa limitazione si verifica perché gli autocodificatori sono orientati alla ricostruzione dei dati in base alle caratteristiche principali di un determinato set di dati. Pertanto, i codificatori automatici generalmente eliminano dettagli più piccoli dai dati durante l'addestramento e non possono gestire dati che non si adattano alla rappresentazione generalizzata delle caratteristiche.