
Cos'è un albero decisionale nel machine learning?
Pubblicato: 2024-08-14Gli alberi decisionali sono uno degli strumenti più comuni nel toolkit di machine learning di un analista di dati. In questa guida imparerai cosa sono gli alberi decisionali, come sono costruiti, varie applicazioni, vantaggi e altro ancora.
Sommario
- Cos'è un albero decisionale?
- Terminologia dell'albero decisionale
- Tipi di alberi decisionali
- Come funzionano gli alberi decisionali
- Applicazioni
- Vantaggi
- Svantaggi
Cos'è un albero decisionale?
Nell'apprendimento automatico (ML), un albero decisionale è un algoritmo di apprendimento supervisionato che assomiglia a un diagramma di flusso o a un diagramma decisionale. A differenza di molti altri algoritmi di apprendimento supervisionato, gli alberi decisionali possono essere utilizzati sia per attività di classificazione che di regressione. I data scientist e gli analisti utilizzano spesso gli alberi decisionali quando esplorano nuovi set di dati perché sono facili da costruire e interpretare. Inoltre, gli alberi decisionali possono aiutare a identificare importanti funzionalità dei dati che potrebbero essere utili quando si applicano algoritmi ML più complessi.
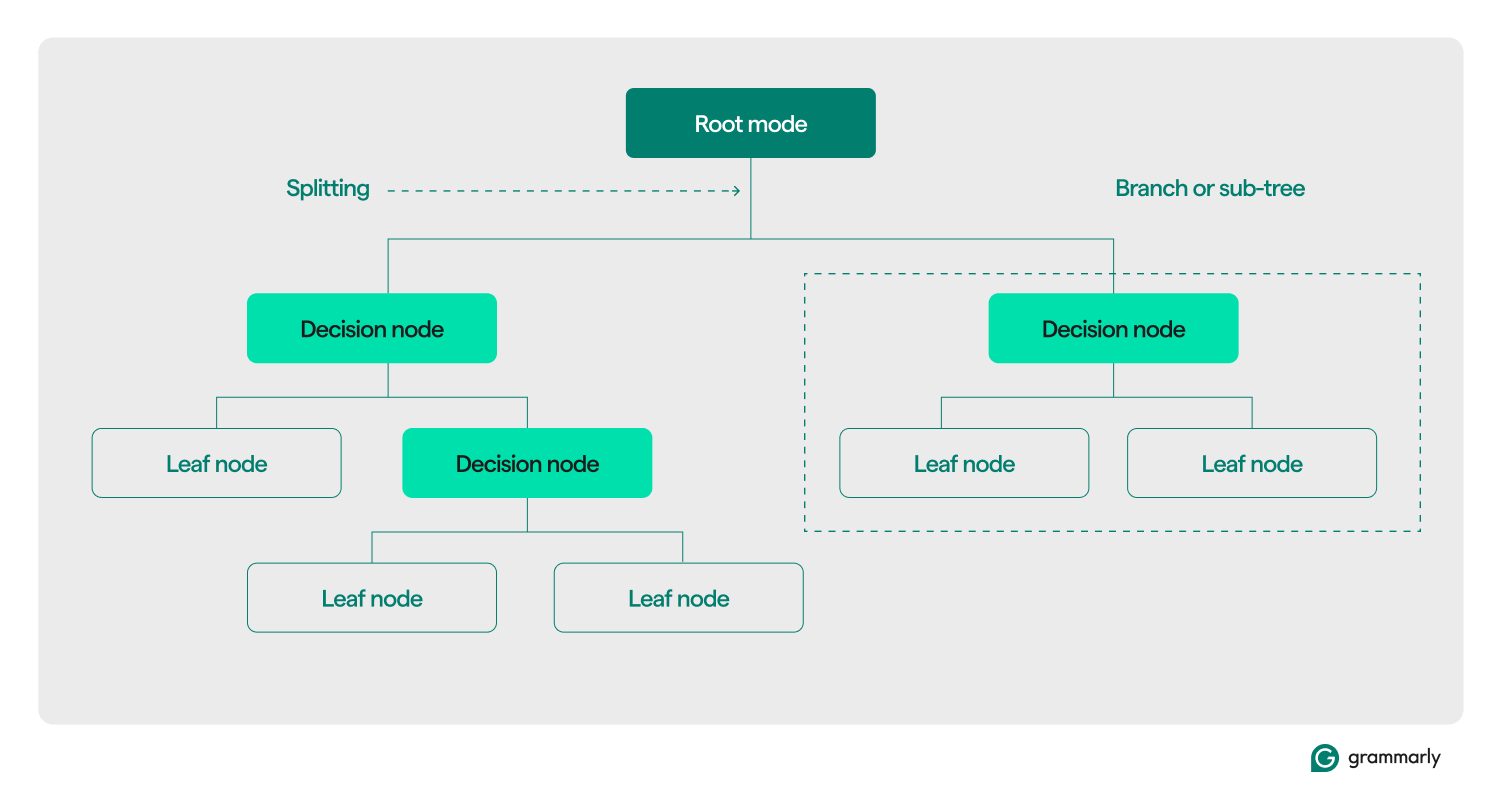
Terminologia dell'albero decisionale
Strutturalmente, un albero decisionale è tipicamente costituito da tre componenti: un nodo radice, nodi foglia e nodi decisionali (o interni). Proprio come i diagrammi di flusso o gli alberi in altri domini, le decisioni in un albero solitamente si muovono in una direzione (verso il basso o verso l'alto), iniziando dal nodo radice, passando attraverso alcuni nodi decisionali e terminando in uno specifico nodo foglia. Ogni nodo foglia collega un sottoinsieme dei dati di addestramento a un'etichetta. L'albero viene assemblato attraverso un processo di formazione e ottimizzazione ML e, una volta creato, può essere applicato a vari set di dati.
Ecco un'analisi più approfondita del resto della terminologia:
- Nodo radice:un nodo che contiene la prima di una serie di domande che l'albero decisionale porrà sui dati. Il nodo sarà connesso ad almeno uno (ma solitamente due o più) nodi decisionali o foglia.
- Nodi decisionali (o nodi interni):nodi aggiuntivi contenenti domande. Un nodo decisionale conterrà esattamente una domanda sui dati e indirizzerà il flusso di dati a uno dei suoi figli in base alla risposta.
- Figli:uno o più nodi a cui punta un nodo radice o decisionale. Rappresentano un elenco di opzioni successive che il processo decisionale può adottare durante l'analisi dei dati.
- Nodi foglia (o nodi terminali):nodi che indicano che il processo decisionale è stato completato. Una volta che il processo decisionale raggiunge un nodo foglia, restituirà i valori dal nodo foglia come output.
- Etichetta (classe, categoria):generalmente, una stringa associata da un nodo foglia ad alcuni dati di addestramento. Ad esempio, una foglia potrebbe associare l'etichetta "Cliente soddisfatto" a un insieme di clienti specifici con cui è stato presentato l'algoritmo di training ML dell'albero decisionale.
- Ramo (o sottoalbero):questo è l'insieme di nodi costituito da un nodo decisionale in qualsiasi punto dell'albero, insieme a tutti i suoi figli e i loro figli, fino ai nodi foglia.
- Potatura:un'operazione di ottimizzazione tipicamente eseguita sull'albero per renderlo più piccolo e aiutarlo a restituire gli output più velocemente. La potatura di solito si riferisce alla "post-potatura", che comporta la rimozione algoritmica di nodi o rami dopo che il processo di training ML ha costruito l'albero. La "pre-potatura" si riferisce all'impostazione di un limite arbitrario alla profondità o alla larghezza di un albero decisionale che può crescere durante l'addestramento. Entrambi i processi impongono una complessità massima per l'albero decisionale, solitamente misurata dalla sua profondità o altezza massima. Ottimizzazioni meno comuni includono la limitazione del numero massimo di nodi decisionali o nodi foglia.
- Suddivisione:la fase di trasformazione principale eseguita su un albero decisionale durante la formazione. Implica la divisione di un nodo radice o decisionale in due o più sottonodi.
- Classificazione:un algoritmo ML che tenta di capire quale (da un elenco costante e discreto di classi, categorie o etichette) è quella più probabile da applicare a un dato. Potrebbe tentare di rispondere a domande come "Quale giorno della settimana è il migliore per prenotare un volo?" Maggiori informazioni sulla classificazione di seguito.
- Regressione:un algoritmo ML che tenta di prevedere un valore continuo, che potrebbe non avere sempre limiti. Potrebbe tentare di rispondere (o prevedere la risposta) a domande come "Quante persone probabilmente prenoteranno un volo martedì prossimo?" Parleremo più approfonditamente degli alberi di regressione nella prossima sezione.
Tipi di alberi decisionali
Gli alberi decisionali sono generalmente raggruppati in due categorie: alberi di classificazione e alberi di regressione. È possibile creare un albero specifico da applicare alla classificazione, alla regressione o a entrambi i casi d'uso. La maggior parte degli alberi decisionali moderni utilizza l'algoritmo CART (Classification and Regression Trees), che può eseguire entrambi i tipi di attività.
Alberi di classificazione
Gli alberi di classificazione, il tipo più comune di albero decisionale, tentano di risolvere un problema di classificazione. Da un elenco di possibili risposte a una domanda (spesso semplici come "sì" o "no"), un albero di classificazione sceglierà quella più probabile dopo aver posto alcune domande sui dati presentati. Di solito sono implementati come alberi binari, il che significa che ogni nodo decisionale ha esattamente due figli.
Gli alberi di classificazione potrebbero provare a rispondere a domande a scelta multipla come "Questo cliente è soddisfatto?" o "Quale negozio fisico sarà probabilmente visitato da questo cliente?" oppure "Domani sarà una buona giornata per andare al campo da golf?"
I due metodi più comuni per misurare la qualità di un albero di classificazione si basano sul guadagno di informazioni e sull'entropia:
- Guadagno di informazioni:l'efficienza di un albero aumenta quando pone meno domande prima di raggiungere una risposta. Il guadagno di informazioni misura quanto “rapidamente” un albero può ottenere una risposta valutando quante più informazioni vengono apprese su un dato in ciascun nodo decisionale. Valuta se le domande più importanti e utili vengono poste per prime nell'albero.
- Entropia:la precisione è fondamentale per le etichette dell'albero decisionale. Le metriche dell'entropia misurano questa precisione valutando le etichette prodotte dall'albero. Valutano la frequenza con cui un dato casuale finisce con l'etichetta sbagliata e la somiglianza tra tutti i dati di addestramento che ricevono la stessa etichetta.
Misurazioni più avanzate della qualità dell'albero includono l'indice Gini,il rapporto di guadagno,le valutazioni chi-quadratoe varie misurazioni per la riduzione della varianza.
Alberi di regressione
Gli alberi di regressione vengono generalmente utilizzati nell'analisi di regressione per analisi statistiche avanzate o per prevedere dati da un intervallo continuo e potenzialmente illimitato. Data una gamma di opzioni continue (ad esempio, da zero a infinito sulla scala dei numeri reali), l'albero di regressione tenta di prevedere la corrispondenza più probabile per un dato dato dopo aver posto una serie di domande. Ogni domanda restringe la potenziale gamma di risposte. Ad esempio, un albero di regressione potrebbe essere utilizzato per prevedere i punteggi di credito, le entrate di una linea di business o il numero di interazioni su un video di marketing.
L'accuratezza degli alberi di regressione viene solitamente valutata utilizzando parametri comel'errore quadratico mediool'errore assoluto medio, che calcolano la distanza di uno specifico insieme di previsioni rispetto ai valori effettivi.
Come funzionano gli alberi decisionali
Come esempio di apprendimento supervisionato, gli alberi decisionali si basano su dati ben formattati per la formazione. I dati di origine contengono solitamente un elenco di valori che il modello dovrebbe imparare a prevedere o classificare. Ogni valore dovrebbe avere un'etichetta allegata e un elenco di funzionalità associate: proprietà che il modello dovrebbe imparare ad associare all'etichetta.

Costruire o formare
Durante il processo di addestramento, i nodi decisionali nell'albero decisionale vengono suddivisi ricorsivamente in nodi più specifici secondo uno o più algoritmi di addestramento. Una descrizione del processo a livello umano potrebbe assomigliare a questa:
- Inizia con il nodo radiceconnesso all'intero set di training.
- Dividere il nodo radice:utilizzando un approccio statistico, assegnare una decisione al nodo radice in base a una delle caratteristiche dei dati e distribuire i dati di addestramento ad almeno due nodi foglia separati, collegati come figli alla radice.
- Applica ricorsivamente il secondo passaggioa ciascuno dei bambini, trasformandoli da nodi foglia in nodi decisionali. Interrompi quando viene raggiunto un limite (ad esempio, l'altezza/profondità dell'albero, una misura della qualità dei figli in ciascuna foglia in ciascun nodo, ecc.) o se hai esaurito i dati (ad esempio, ogni foglia contiene dati punti correlati esattamente a un'etichetta).
La decisione su quali funzionalità considerare in ciascun nodo differisce per i casi d'uso di classificazione, regressione e classificazione e regressione combinate. Esistono molti algoritmi tra cui scegliere per ogni scenario. Gli algoritmi tipici includono:
- ID3 (classificazione):ottimizza l'entropia e il guadagno di informazioni
- C4.5 (classificazione):una versione più complessa di ID3, che aggiunge la normalizzazione al guadagno di informazioni
- CART (classificazione/regressione): “Albero di classificazione e regressione”; un algoritmo avido che ottimizza per la minima impurità nei set di risultati
- CHAID (classificazione/regressione): “Rilevamento automatico dell'interazione chi-quadrato”; utilizza misurazioni del chi quadrato invece dell'entropia e del guadagno di informazioni
- MARS (classificazione/regressione): utilizza approssimazioni lineari a tratti per catturare le non linearità
Un regime di addestramento comune è la foresta casuale. Una foresta casuale, o foresta decisionale casuale, è un sistema che costruisce molti alberi decisionali correlati. È possibile addestrare più versioni di un albero in parallelo utilizzando combinazioni di algoritmi di addestramento. Sulla base di varie misurazioni della qualità degli alberi, un sottoinsieme di questi alberi verrà utilizzato per produrre una risposta. Per i casi d'uso di classificazione, come risposta viene restituita la classe selezionata dal maggior numero di alberi. Per i casi d'uso di regressione, la risposta viene aggregata, solitamente come previsione media o media dei singoli alberi.
Valutazione e utilizzo di alberi decisionali
Una volta costruito, un albero decisionale può classificare nuovi dati o prevedere valori per un caso d'uso specifico. È importante mantenere le metriche sulle prestazioni dell'albero e utilizzarle per valutare l'accuratezza e la frequenza degli errori. Se il modello si discosta troppo dalle prestazioni previste, potrebbe essere il momento di riqualificarlo su nuovi dati o trovare altri sistemi ML da applicare a quel caso d'uso.
Applicazioni degli alberi decisionali in ML
Gli alberi decisionali hanno una vasta gamma di applicazioni in vari campi. Ecco alcuni esempi per illustrare la loro versatilità:
Processo decisionale personale informato
Un individuo potrebbe tenere traccia dei dati, ad esempio, sui ristoranti che ha visitato. Potrebbero tenere traccia di tutti i dettagli rilevanti, come tempo di viaggio, tempo di attesa, cucina offerta, orari di apertura, punteggio medio delle recensioni, costo e visita più recente, insieme a un punteggio di soddisfazione per la visita dell'individuo a quel ristorante. È possibile addestrare un albero decisionale su questi dati per prevedere il probabile punteggio di soddisfazione per un nuovo ristorante.
Calcola le probabilità sul comportamento dei clienti
I sistemi di assistenza clienti potrebbero utilizzare alberi decisionali per prevedere o classificare la soddisfazione del cliente. È possibile addestrare un albero decisionale per prevedere la soddisfazione del cliente in base a vari fattori, ad esempio se il cliente ha contattato l'assistenza o effettuato un acquisto ripetuto o in base alle azioni eseguite all'interno di un'app. Inoltre, può incorporare risultati di sondaggi sulla soddisfazione o altri feedback dei clienti.
Aiuta a informare le decisioni aziendali
Per alcune decisioni aziendali ricche di dati storici, un albero decisionale può fornire stime o previsioni per i passaggi successivi. Ad esempio, un'azienda che raccoglie informazioni demografiche e geografiche sui propri clienti può addestrare un albero decisionale per valutare quali nuove località geografiche potrebbero essere redditizie o dovrebbero essere evitate. Gli alberi decisionali possono anche aiutare a determinare i migliori limiti di classificazione per i dati demografici esistenti, ad esempio identificando le fasce di età da considerare separatamente quando si raggruppano i clienti.
Selezione di funzionalità per ML avanzato e altri casi d'uso
Le strutture dell'albero decisionale sono leggibili e comprensibili dall'uomo. Una volta costruito un albero, è possibile identificare quali caratteristiche sono più rilevanti per il set di dati e in quale ordine. Queste informazioni possono guidare lo sviluppo di sistemi ML o algoritmi decisionali più complessi. Ad esempio, se un’azienda apprende da un albero decisionale che i clienti danno priorità al costo di un prodotto sopra ogni altra cosa, può concentrare sistemi ML più complessi su queste informazioni o ignorare i costi quando esplora funzionalità più sfumate.
Vantaggi degli alberi decisionali in ML
Gli alberi decisionali offrono numerosi vantaggi significativi che li rendono una scelta popolare nelle applicazioni ML. Ecco alcuni vantaggi chiave:
Veloce e facile da costruire
Gli alberi decisionali sono uno degli algoritmi ML più maturi e ben compresi. Non dipendono da calcoli particolarmente complessi e possono essere costruiti rapidamente e facilmente. Finché le informazioni richieste sono prontamente disponibili, un albero decisionale è un semplice primo passo da compiere quando si considerano soluzioni ML a un problema.
Facile da comprendere per gli esseri umani
L'output degli alberi decisionali è particolarmente facile da leggere e interpretare. La rappresentazione grafica di un albero decisionale non dipende da una conoscenza avanzata della statistica. Pertanto, gli alberi decisionali e le loro rappresentazioni possono essere utilizzati per interpretare, spiegare e supportare i risultati di analisi più complesse. Gli alberi decisionali sono eccellenti per trovare ed evidenziare alcune delle proprietà di alto livello di un dato set di dati.
È richiesta un'elaborazione dati minima
Gli alberi decisionali possono essere costruiti altrettanto facilmente su dati incompleti o su dati con valori anomali inclusi. Dati i dati decorati con funzionalità interessanti, gli algoritmi dell'albero decisionale tendono a non essere influenzati tanto quanto altri algoritmi ML se ricevono dati che non sono stati preelaborati.
Svantaggi degli alberi decisionali in ML
Sebbene gli alberi decisionali offrano molti vantaggi, presentano anche diversi inconvenienti:
Suscettibile al sovradattamento
Gli alberi decisionali sono soggetti a overfitting, che si verifica quando un modello apprende il rumore e i dettagli nei dati di training, riducendo le sue prestazioni sui nuovi dati. Ad esempio, se i dati di training sono incompleti o sparsi, piccole modifiche nei dati possono produrre strutture ad albero significativamente diverse. Tecniche avanzate come la potatura o l'impostazione di una profondità massima possono migliorare il comportamento degli alberi. In pratica, gli alberi decisionali spesso necessitano di aggiornamenti con nuove informazioni, che possono alterarne significativamente la struttura.
Scarsa scalabilità
Oltre alla tendenza ad adattarsi eccessivamente, gli alberi decisionali devono affrontare problemi più avanzati che richiedono una quantità significativamente maggiore di dati. Rispetto ad altri algoritmi, il tempo di addestramento degli alberi decisionali aumenta rapidamente con la crescita dei volumi di dati. Per set di dati più grandi che potrebbero avere proprietà significative di alto livello da rilevare, gli alberi decisionali non sono la soluzione ideale.
Non altrettanto efficace per la regressione o i casi di utilizzo continuo
Gli alberi decisionali non apprendono molto bene le distribuzioni complesse dei dati. Suddividono lo spazio delle funzionalità lungo linee facili da comprendere ma matematicamente semplici. Per problemi complessi in cui i valori anomali sono rilevanti, regressione e casi d'uso continui, ciò spesso si traduce in prestazioni molto inferiori rispetto ad altri modelli e tecniche ML.