
Punteggio F1 nell'apprendimento automatico: come calcolare, applicare e usarlo in modo efficace
Pubblicato: 2025-02-10Il punteggio F1 è una potente metrica per la valutazione dei modelli di apprendimento automatico (ML) progettati per eseguire classificazione binaria o multiclasse. Questo articolo spiegherà qual è il punteggio F1, perché è importante, come viene calcolato e le sue applicazioni, benefici e limitazioni.
Sommario
- Cos'è un punteggio F1?
- Come calcolare un punteggio F1
- Punteggio F1 vs. precisione
- Applicazioni del punteggio F1
- Vantaggi del punteggio F1
- Limitazioni del punteggio F1
Cos'è un punteggio F1?
I professionisti della ML affrontano una sfida comune quando si costruiscono modelli di classificazione: addestrare il modello a catturare tutti i casi evitando falsi allarmi. Ciò è particolarmente importante nelle applicazioni critiche come il rilevamento di frodi finanziarie e la diagnosi medica, in cui falsi allarmi e mancanti classificazioni hanno gravi conseguenze. Raggiungere il giusto equilibrio è particolarmente importante quando si tratta di set di dati squilibrati, in cui una categoria come le transazioni fraudolente è molto più rara dell'altra categoria (transazioni legittime).
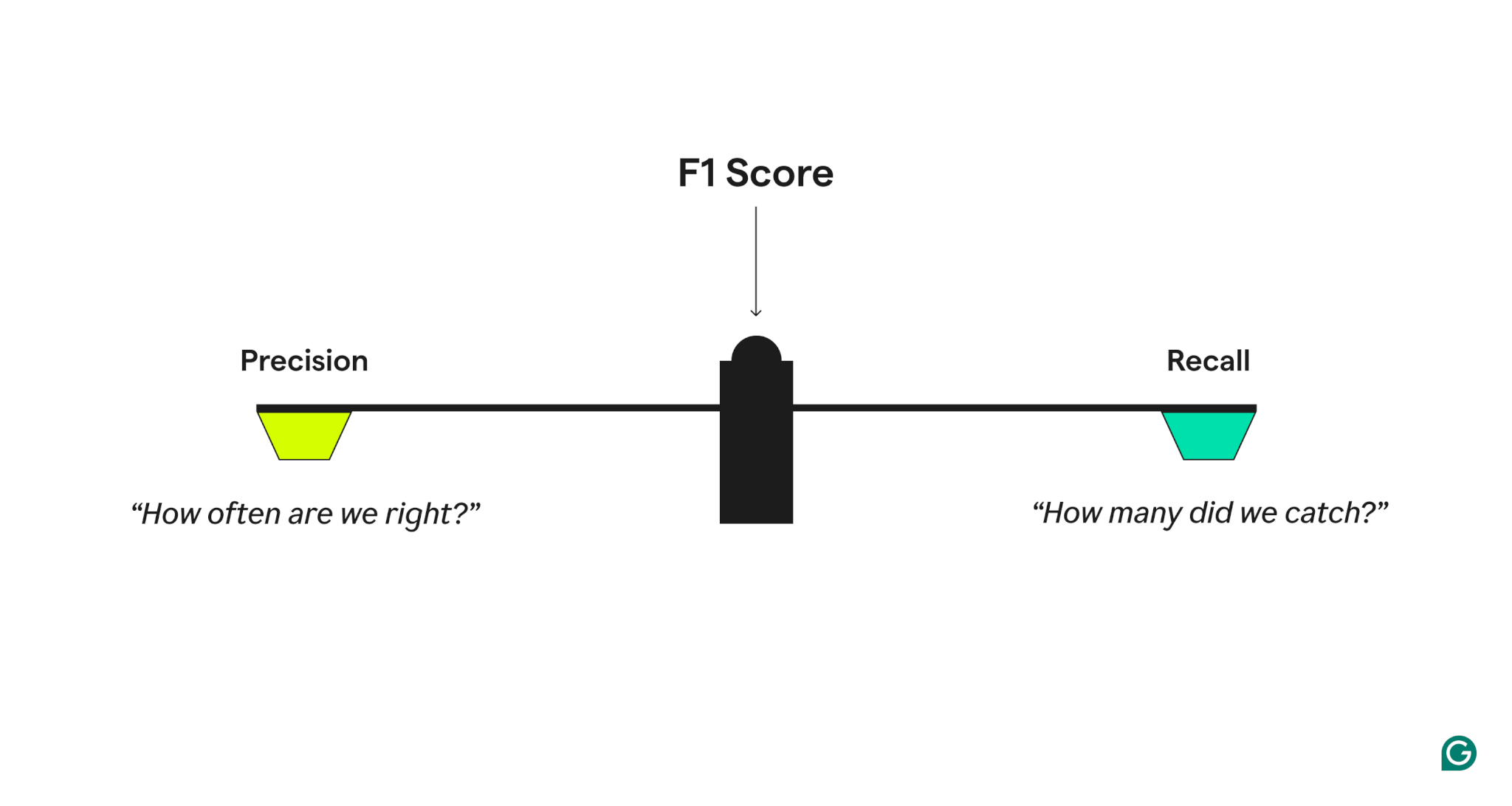
Precisione e richiamo
Per misurare la qualità delle prestazioni del modello, il punteggio F1 combina due metriche correlate:
- Precision, che risponde, "Quando il modello prevede un caso positivo, quanto spesso è corretto?"
- Ricorda, quali risponde, "Di tutti i casi positivi reali, quanti ha identificato correttamente il modello?"
Un modello con alta precisione ma un basso richiamo è eccessivamente cauto, manca molti veri positivi, mentre uno con alto richiamo ma una bassa precisione è eccessivamente aggressiva, generando molti falsi positivi. Il punteggio F1 colpisce un equilibrio prendendo la media armonica di precisione e richiamo, il che dà più peso ai valori più bassi e garantisce che un modello si comporta bene su entrambe le metriche piuttosto che eccellere in una sola.
Esempio di precisione e richiamo
Per comprendere meglio la precisione e il richiamo, considera un sistema di rilevamento dello spam. Se il sistema ha un alto tasso di e -mail di segnalazione correttamente come spam, ciò significa che ha un'alta precisione. Ad esempio, se il sistema segnala 100 e -mail come spam e 90 di esse sono effettivamente spam, la precisione è del 90%. L'alto richiamo, d'altra parte, significa che il sistema rileva la maggior parte delle e -mail di spam. Ad esempio, se ci sono 200 e -mail di spam effettive e il nostro sistema ne cattura 90, il richiamo è del 45%.
Varianti del punteggio F1
Nei sistemi di classificazione multiclasse o scenari con esigenze specifiche, il punteggio F1 può essere calcolato in diversi modi, a seconda di quali fattori sono importanti:
- Macro-F1:calcola il punteggio F1 separatamente per ogni classe e prende la media
- Micro-F1:calcola il richiamo e la precisione su tutte le previsioni
- Ponderato-F1: simile alla macro-F1, ma le classi sono ponderate in base alla frequenza
Oltre il punteggio F1: la famiglia F-Score
Il punteggio F1 fa parte di una famiglia più ampia di metriche chiamate punteggi F. Questi punteggi offrono modi diversi per pesare la precisione e il richiamo:
- F2:pone una maggiore enfasi sul richiamo, che è utile quando i falsi negativi sono costosi
- F0.5:pone una maggiore enfasi sulla precisione, che è utile quando i falsi positivi sono costosi
Come calcolare un punteggio F1
Il punteggio F1 è matematicamente definito come media armonica di precisione e richiamo. Sebbene ciò possa sembrare complesso, il processo di calcolo è semplice se suddiviso in passaggi chiari.
La formula per il punteggio F1:

Prima di immergersi nei passaggi per calcolare F1, è importante comprendere i componenti chiave di quella che viene chiamata unamatrice di confusione, che viene utilizzata per organizzare i risultati della classificazione:
- True Positives (TP):il numero di casi correttamente identificati come positivi
- FALSI Positivi (FP):il numero di casi identificati erroneamente come positivo
- Falso negativi (FN):il numero di casi mancati (positivi effettivi che non sono stati identificati)
Il processo generale prevede la formazione del modello, il test delle previsioni e l'organizzazione dei risultati, il calcolo della precisione e il richiamo e il calcolo del punteggio F1.
Passaggio 1: allena un modello di classificazione
Innanzitutto, un modello deve essere addestrato per fare classificazioni binarie o multiclasse. Ciò significa che il modello deve essere in grado di classificare i casi come appartenenti a una delle due categorie. Gli esempi includono "spam/non spam" e "frode/non frode".
Passaggio 2: test previsioni e organizza i risultati
Successivamente, utilizzare il modello per eseguire classificazioni su un set di dati separato che non è stato utilizzato come parte della formazione. Organizza i risultati nella matrice di confusione. Questa matrice mostra:
- TP: quante previsioni erano effettivamente corrette
- FP: quante previsioni positive erano errate
- FN: quanti casi positivi sono mancati
La matrice di confusione fornisce una panoramica di come sta eseguendo il modello.
Passaggio 3: calcola la precisione
Usando la matrice di confusione, la precisione viene calcolata con questa formula:

Ad esempio, se un modello di rilevamento di spam ha identificato correttamente 90 e -mail SPAM (TP) ma ha contrassegnato erroneamente 10 e -mail nonpam (FP), la precisione è 0,90.

Passaggio 4: calcola il richiamo
Successivamente, calcola il richiamo usando la formula:

Utilizzando l'esempio di rilevamento dello spam, se c'erano 200 e -mail di spam totali e il modello ne ha catturati 90 (TP) mentre mancavano 110 (FN), il richiamo è 0,45.

Passaggio 5: calcola il punteggio F1
Con la precisione e i valori di richiamo in mano, il punteggio F1 può essere calcolato.
Il punteggio F1 varia da 0 a 1. Quando si interpreta il punteggio, considera questi benchmark generali:
- 0.9 o superiore:il modello funziona alla grande, ma dovrebbe essere controllato per eccessiva.
- 0,7 a 0,9:buone prestazioni per la maggior parte delle applicazioni
- Da 0,5 a 0,7:le prestazioni sono OK, ma il modello potrebbe utilizzare il miglioramento.
- 0,5 o meno:il modello si sta comportando male e necessita di gravi miglioramenti.
Utilizzando i calcoli di esempio di rilevamento dello spam per precisione e richiamo, il punteggio F1 sarebbe dello 0,60 o del 60%.


In questo caso, il punteggio F1 indica che, anche con alta precisione, il richiamo inferiore sta influenzando le prestazioni complessive. Ciò suggerisce che c'è spazio per migliorare la cattura di più e -mail di spam.
Punteggio F1 vs. precisione
Mentre sia F1 chel'accuratezzaquantificano le prestazioni del modello, il punteggio F1 fornisce una misura più sfumata. L'accuratezza calcola semplicemente la percentuale di previsioni corrette. Tuttavia, fare affidamento sull'accuratezza per misurare le prestazioni del modello può essere problematico quando il numero di istanze di una categoria in un set di dati supera significativamente l'altra categoria. Questo problema è indicato comeparadosso di precisione.
Per comprendere questo problema, considerare l'esempio del sistema di rilevamento dello spam. Supponiamo che un sistema di posta elettronica riceva 1.000 e -mail ogni giorno, ma solo 10 di queste sono effettivamente spam. Se il rilevamento dello spam classifica semplicemente ogni e -mail come non spam, raggiungerà comunque una precisione del 99%. Questo perché 990 previsioni su 1.000 erano corrette, anche se il modello è in realtà inutile quando si tratta di rilevamento dello spam. Chiaramente, l'accuratezza non fornisce un quadro accurato della qualità del modello.
Il punteggio F1 evita questo problema combinando le misurazioni di precisione e richiamo. Pertanto, F1 dovrebbe essere usato al posto della precisione nei seguenti casi:
- Il set di dati è squilibrato.Ciò è comune in campi come la diagnosi di oscure condizioni mediche o il rilevamento dello spam, in cui una categoria è relativamente rara.
- FN e FP sono entrambi importanti.Ad esempio, i test di screening medico cercano di bilanciare i problemi effettivi senza sollevare falsi allarmi.
- Il modello deve trovare un equilibrio tra essere troppo aggressivo e troppo cauto.Ad esempio, nel filtro dello spam, un filtro eccessivamente cauto potrebbe far passare troppo spam (basso richiamo) ma raramente commette errori (alta precisione). D'altra parte, un filtro eccessivamente aggressivo potrebbe bloccare le e -mail reali (bassa precisione) anche se cattura tutto lo spam (richiamo elevato).
Applicazioni del punteggio F1
Il punteggio F1 ha una vasta gamma di applicazioni in vari settori in cui la classificazione equilibrata è fondamentale. Queste applicazioni includono il rilevamento di frodi finanziarie, la diagnosi medica e la moderazione del contenuto.
Rilevamento delle frodi finanziarie
I modelli progettati per rilevare frodi finanziarie sono una categoria di sistemi adatti alla misurazione utilizzando il punteggio F1. Le aziende finanziarie elaborano spesso milioni o miliardi di transazioni ogni giorno, con casi effettivi di frode relativamente rari. Per questo motivo, un sistema di rilevamento delle frodi deve catturare quante più transazioni fraudolente possibili, al contempo minimizzando contemporaneamente il numero di falsi allarmi e il conseguente inconveniente per i clienti. La misurazione del punteggio F1 può aiutare gli istituti finanziari a determinare quanto bene i loro sistemi bilanciano i pilastri gemelli della prevenzione delle frodi e una buona esperienza del cliente.
Diagnosi medica
Nella diagnosi e dei test medici, FN e FP hanno entrambi gravi conseguenze. Considera l'esempio di un modello progettato per rilevare rare forme di cancro. La diagnosi di un paziente sano in modo errato potrebbe portare a stress e trattamento inutili, mentre la mancanza di un caso di cancro effettivo avrà conseguenze disastrose per il paziente. In altre parole, il modello deve avere sia ad alta precisione che ad alto richiamo, il che è qualcosa che il punteggio F1 può misurare.
Moderazione del contenuto
La moderazione dei contenuti è una sfida comune nei forum online, nelle piattaforme di social media e nei mercati online. Per raggiungere la sicurezza della piattaforma senza sovraccendere, questi sistemi devono bilanciare la precisione e il richiamo. Il punteggio F1 può aiutare le piattaforme a determinare quanto bene il loro sistema bilancia questi due fattori.
Vantaggi del punteggio F1
Oltre a fornire generalmente una visione più sfumata delle prestazioni del modello rispetto alla precisione, il punteggio F1 offre diversi vantaggi chiave nella valutazione delle prestazioni del modello di classificazione. Questi benefici includono una formazione e un'ottimizzazione più rapide del modello, i costi di formazione ridotti e la cattura in anticipo.
Allenamento e ottimizzazione del modello più rapido
Il punteggio F1 può aiutare ad accelerare l'allenamento del modello fornendo una chiara metrica di riferimento che può essere utilizzata per guidare l'ottimizzazione. Invece di sintonizzare il richiamo e la precisione separatamente, che generalmente coinvolgono compromessi complessi, i professionisti della ML possono concentrarsi sull'aumento del punteggio F1. Con questo approccio semplificato, i parametri del modello ottimali possono essere identificati rapidamente.
Costi di formazione ridotti
Il punteggio F1 può aiutare i professionisti di ML a prendere decisioni informate su quando un modello è pronto per la distribuzione fornendo una singola misura sfumata delle prestazioni del modello. Con queste informazioni, i professionisti possono evitare cicli di formazione inutili, investimenti in risorse computazionali e dover acquisire o creare ulteriori dati di formazione. Nel complesso, ciò può portare a sostanziali riduzioni dei costi durante la formazione di modelli di classificazione.
Catturare in modo eccessivo in anticipo
Poiché il punteggio F1 considera sia la precisione che il richiamo, può aiutare i professionisti di ML a identificare quando un modello sta diventando troppo specializzato nei dati di allenamento. Questo problema, chiamato overfitting, è un problema comune con i modelli di classificazione. Il punteggio F1 offre ai professionisti un avvertimento precoce che devono regolare l'allenamento prima che il modello raggiunga un punto in cui non è in grado di generalizzare i dati del mondo reale.
Limitazioni del punteggio F1
Nonostante i suoi numerosi benefici, il punteggio F1 ha diverse importanti limitazioni che i professionisti dovrebbero considerare. Queste limitazioni includono una mancanza di sensibilità ai veri negativi, non essere adatti per alcuni set di dati ed essere più difficile da interpretare per problemi multiclassi.
Mancanza di sensibilità ai veri negativi
Il punteggio F1 non tiene conto dei veri negativi, il che significa che non è adatto per le applicazioni in cui la misurazione di ciò è importante. Ad esempio, considera un sistema progettato per identificare le condizioni di guida sicure. In questo caso, identificare correttamente quando le condizioni sono veramente sicure (veri negativi) è importante quanto l'identificazione di condizioni pericolose. Poiché non traccia FN, il punteggio F1 non catturerebbe accuratamente questo aspetto delle prestazioni complessive del modello.
Non è adatto per alcuni set di dati
Il punteggio F1 potrebbe non essere adatto per i set di dati in cui l'impatto di FP e FN è significativamente diverso. Considera l'esempio di un modello di screening del cancro. In una situazione del genere, la perdita di un caso positivo (FN) potrebbe essere pericolosa per la vita, mentre trovarsi erroneamente un caso positivo (FP) porta solo a test aggiuntivi. Quindi, usare una metrica che può essere ponderata per tenere conto di questo costo è una scelta migliore del punteggio F1.
Più difficile da interpretare per i problemi multiclassi
Mentre variazioni come i punteggi Micro-F1 e Macro-F1 indicano che il punteggio F1 può essere utilizzato per valutare i sistemi di classificazione multiclasse, interpretare queste metriche aggregate è spesso più complesso del punteggio binario F1. Ad esempio, il punteggio Micro-F1 potrebbe nascondere scarse prestazioni nella classificazione di classi meno frequenti, mentre il punteggio Macro-F1 potrebbe sovrappedere classi rare. Detto questo, le aziende devono valutare se la parità di trattamento delle classi o le prestazioni complessive a livello di istanza è più importante quando si sceglie la variante F1 giusta per i modelli di classificazione multiclasse.