
Machine Learning 101: cos'è e come funziona
Pubblicato: 2024-05-23L’apprendimento automatico (ML) è rapidamente diventato una delle tecnologie più importanti del nostro tempo. È alla base di prodotti come ChatGPT, consigli Netflix, auto a guida autonoma e filtri antispam per e-mail. Per aiutarti a comprendere questa tecnologia pervasiva, questa guida illustra cos'è il machine learning (e cosa non è), come funziona e il suo impatto.
Sommario
- Cos'è l'apprendimento automatico?
- Come funziona l'apprendimento automatico
- Tipo di apprendimento automatico
- Applicazioni
- Vantaggi
- Svantaggi
- Il futuro della ML
- Conclusione
Cos'è l'apprendimento automatico?
Per comprendere l’apprendimento automatico, dobbiamo prima comprendere l’intelligenza artificiale (AI). Sebbene i due siano usati in modo intercambiabile, non sono la stessa cosa. L’intelligenza artificiale è sia un obiettivo che un campo di studio. L’obiettivo è costruire sistemi informatici in grado di pensare e ragionare a livello umano (o addirittura sovrumano). L’intelligenza artificiale prevede anche molti metodi diversi per arrivarci. L’apprendimento automatico è uno di questi metodi, rendendolo un sottoinsieme dell’intelligenza artificiale.
L’apprendimento automatico si concentra specificamente sull’utilizzo di dati e statistiche nel perseguimento dell’intelligenza artificiale. L'obiettivo è creare sistemi intelligenti che possano apprendere ricevendo numerosi esempi (dati) e che non abbiano bisogno di essere programmati esplicitamente. Con dati sufficienti e un buon algoritmo di apprendimento, il computer rileva gli schemi nei dati e migliora le sue prestazioni.
Al contrario, gli approcci non ML all'intelligenza artificiale non dipendono dai dati e hanno una logica codificata scritta. Ad esempio, potresti creare un robot AI tris con prestazioni sovrumane semplicemente codificando tutte le mosse ottimali (ci sono 255.168 possibili giochi di tris, quindi ci vorrebbe un po' di tempo, ma è ancora possibile). Sarebbe però impossibile codificare un bot di intelligenza artificiale per gli scacchi: ci sono più partite di scacchi possibili che atomi nell’universo. Il machine learning funzionerebbe meglio in questi casi.
Una domanda ragionevole a questo punto è: come migliora esattamente un computer quando gli vengono forniti degli esempi?
Come funziona l'apprendimento automatico
In qualsiasi sistema ML sono necessarie tre cose: il set di dati, il modello ML (GPT è un esempio) e l'algoritmo di training. Per prima cosa, passi gli esempi dal set di dati. Il modello quindi prevede l'output corretto per quell'esempio. Se il modello è sbagliato, si utilizza l'algoritmo di training per aumentare le probabilità che il modello sia corretto per esempi simili in futuro. Ripeti questo processo finché non esaurisci i dati o finché non sei soddisfatto dei risultati. Una volta completato questo processo, puoi utilizzare il modello per prevedere i dati futuri.
Un esempio basilare di questo processo è insegnare a un computer a riconoscere le cifre scritte a mano come quelle seguenti.
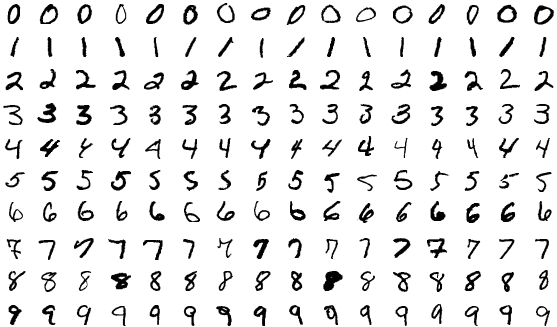
Fonte
Raccogli migliaia o centinaia di migliaia di immagini di cifre. Inizi con un modello ML di cui non è ancora stato visto alcun esempio. Inserisci le immagini nel modello e gli chiedi di prevedere quale numero ritiene sia presente nell'immagine. Restituirà un numero compreso tra zero e nove, diciamo uno. Quindi, essenzialmente, gli dici: "Questo numero in realtà è cinque, non uno". L'algoritmo di training aggiorna il modello, quindi è più probabile che risponda con cinque la prossima volta. Ripeti questo processo per (quasi) tutte le immagini disponibili e, idealmente, hai un modello con buone prestazioni in grado di riconoscere correttamente le cifre il 90% delle volte. Ora puoi utilizzare questo modello per leggere milioni di cifre su larga scala più velocemente di quanto potrebbe fare un essere umano. In pratica, il servizio postale degli Stati Uniti utilizza modelli ML per leggere il 98% degli indirizzi scritti a mano.
Potresti passare mesi o anni ad analizzare i dettagli anche di una piccola parte di questo processo (guarda quante diverse versioni di algoritmi di ottimizzazione esistono).
Tipi comuni di machine learning
Esistono in realtà quattro diversi tipi di metodi di apprendimento automatico: supervisionato, non supervisionato, semi-supervisionato e di rinforzo. La differenza principale sta nel modo in cui vengono etichettati i dati (ovvero, con o senza la risposta corretta).
Apprendimento supervisionato
Ai modelli di apprendimento supervisionato vengono forniti dati etichettati (con risposte corrette). L’esempio delle cifre scritte a mano rientra in questa categoria: possiamo dire al modello: “Cinque è la risposta giusta”. Il modello mira ad apprendere le connessioni esplicite tra input e output. Questi modelli possono produrre etichette discrete (ad esempio, prevedere "gatto" o "cane" data l'immagine di un animale domestico) o numeri (ad esempio, il prezzo previsto di una casa dato il numero di letti, bagni, posizione, ecc.) .
Apprendimento non supervisionato
Ai modelli di apprendimento non supervisionato vengono forniti dati senza etichetta (senza risposte corrette). Questi modelli identificano modelli nei dati di input per raggruppare i dati in modo significativo. Ad esempio, date molte immagini di cani e gatti senza una risposta corretta, il modello ML senza supervisione esaminerebbe le somiglianze e le differenze nelle immagini per raggruppare insieme le immagini di cani e gatti. Il clustering, le regole di associazione e la riduzione della dimensionalità sono metodi fondamentali nel machine learning non supervisionato.
Apprendimento semi-supervisionato
L’apprendimento semi-supervisionato è un approccio di machine learning che si colloca tra l’apprendimento supervisionato e quello non supervisionato. Questo metodo fornisce una quantità significativa di dati senza etichetta e un set più piccolo di dati con etichetta per l'addestramento del modello. Innanzitutto, il modello viene addestrato sui dati etichettati, quindi assegna le etichette ai dati senza etichetta confrontando la loro somiglianza con i dati etichettati.
Insegnamento rafforzativo
L'apprendimento per rinforzo non ha una serie di esempi ed etichette. Al modello viene invece assegnato un ambiente (ad esempio, i giochi sono comuni), una funzione di ricompensa e un obiettivo. Il modello impara a raggiungere l'obiettivo per tentativi ed errori. Eseguirà un'azione e la funzione di ricompensa gli dirà se l'azione aiuta a raggiungere l'obiettivo generale. Quindi, il modello si aggiorna per eseguire più o meno quell'azione. Il modello può imparare a raggiungere l'obiettivo eseguendo questa operazione molte volte.
Un famoso esempio di modello di apprendimento per rinforzo è AlphaGo Zero. Questo modello è stato addestrato per vincere partite di Go e gli è stato dato solo lo stato del tabellone Go. Ha poi giocato milioni di partite contro se stesso, imparando nel tempo quali mosse gli davano vantaggi e quali no. Ha raggiunto prestazioni di livello sovrumano in 70 ore di allenamento, superiori a quelle dei campioni del mondo di Go.
Apprendimento autosupervisionato
Esiste in realtà un quinto tipo di apprendimento automatico che è diventato importante di recente: l’apprendimento autosupervisionato. Ai modelli di apprendimento autosupervisionato vengono forniti dati senza etichetta, ma imparano a creare etichette da questi dati. Ciò è alla base dei modelli GPT dietro ChatGPT. Durante l'addestramento GPT, il modello mira a prevedere la parola successiva data una stringa di parole in input. Ad esempio, prendi la frase "Il gatto si sedette sul tappeto". A GPT viene dato "The" e viene chiesto di prevedere quale parola verrà dopo. Fa la sua previsione (diciamo “cane”), ma poiché ha la frase originale, sa qual è la risposta corretta: “gatto”. Quindi, a GPT viene dato "Il gatto" e gli viene chiesto di prevedere la parola successiva e così via. In questo modo, può apprendere modelli statistici tra le parole e altro ancora.
Applicazioni dell'apprendimento automatico
Qualsiasi problema o settore che disponga di molti dati può utilizzare il machine learning. Molti settori hanno ottenuto risultati straordinari da questo approccio e sempre più casi d’uso emergono. Ecco alcuni casi d'uso comuni di ML:
Scrivere
I modelli ML alimentano prodotti di scrittura generativa con intelligenza artificiale come Grammarly. Essendo addestrato su grandi quantità di ottima scrittura, Grammarly può creare una bozza per te, aiutarti a riscrivere e perfezionare e scambiare idee con te, tutto nel tuo tono e stile preferito.

Riconoscimento vocale
Siri, Alexa e la versione vocale di ChatGPT dipendono tutti dai modelli ML. Questi modelli vengono addestrati su molti esempi audio, insieme alle corrispondenti trascrizioni corrette. Con questi esempi, i modelli possono trasformare il parlato in testo. Senza il ML, questo problema sarebbe quasi inrisolvibile perché ognuno ha modi di parlare e di pronuncia diversi. Sarebbe impossibile enumerare tutte le possibilità.
Raccomandazioni
Dietro i tuoi feed su TikTok, Netflix, Instagram e Amazon ci sono modelli di raccomandazioni ML. Questi modelli vengono addestrati su molti esempi di preferenze (ad esempio, a persone come te è piaciuto questo film invece di quell'altro, questo prodotto invece di quell'altro) per mostrarti gli articoli e i contenuti che desideri vedere. Nel corso del tempo, i modelli possono anche incorporare le tue preferenze specifiche per creare un feed che si rivolge specificamente a te.
Intercettazione di una frode
Le banche utilizzano modelli ML per rilevare le frodi con carte di credito. I provider di posta elettronica utilizzano modelli ML per rilevare e deviare le e-mail di spam. Ai modelli Fraud ML vengono forniti molti esempi di dati fraudolenti; questi modelli quindi apprendono modelli tra i dati per identificare le frodi in futuro.
Auto a guida autonoma
Le auto a guida autonoma utilizzano il machine learning per interpretare e navigare sulle strade. Il ML aiuta le auto a identificare i pedoni e le corsie stradali, a prevedere il movimento delle altre auto e a decidere la loro azione successiva (ad esempio, accelerare, cambiare corsia, ecc.). Le auto a guida autonoma acquisiscono competenza formandosi su miliardi di esempi utilizzando questi metodi ML.
Vantaggi dell'apprendimento automatico
Se fatto bene, il machine learning può essere trasformativo. I modelli ML possono generalmente rendere i processi più economici, migliori o entrambi.
Efficienza del costo del lavoro
I modelli ML addestrati possono simulare il lavoro di un esperto a una frazione del costo. Ad esempio, un agente immobiliare esperto ha una grande intuizione quando si tratta di quanto costa una casa, ma ciò può richiedere anni di formazione. Anche gli agenti immobiliari esperti (ed esperti di qualsiasi tipo) sono costosi da assumere. Tuttavia, un modello ML addestrato su milioni di esempi potrebbe avvicinarsi alle prestazioni di un agente immobiliare esperto. Un modello del genere potrebbe essere addestrato in pochi giorni e, una volta addestrato, costerebbe molto meno da utilizzare. Gli agenti immobiliari meno esperti possono quindi utilizzare questi modelli per svolgere più lavoro in meno tempo.
Efficienza temporale
I modelli ML non sono vincolati dal tempo allo stesso modo in cui lo sono gli esseri umani. AlphaGo Zero ha giocato4,9 milioni di partitedi Go in tre giorni di allenamento . Per realizzarlo ci vorrebbero anni umani, se non decenni. Grazie a questa scalabilità, il modello è stato in grado di esplorare un’ampia varietà di mosse e posizioni di Go, portando a prestazioni sovrumane. I modelli ML possono anche cogliere modelli che gli esperti non riescono a cogliere; AlphaGo Zero ha persino trovato e utilizzato mosse solitamente non giocate dagli umani. Ciò non significa però che gli esperti non siano più preziosi; Gli esperti di Go sono migliorati molto utilizzando modelli come AlphaGo per provare nuove strategie.
Svantaggi dell'apprendimento automatico
Naturalmente, ci sono anche degli svantaggi nell’utilizzare i modelli ML. Vale a dire, sono costosi da addestrare e i loro risultati non sono facilmente spiegabili.
Formazione costosa
La formazione sul machine learning può diventare costosa. Ad esempio, lo sviluppo di AlphaGo Zero è costato 25 milioni di dollari e lo sviluppo di GPT-4 è costato più di 100 milioni di dollari. I costi principali per lo sviluppo di modelli ML sono l’etichettatura dei dati, le spese hardware e gli stipendi dei dipendenti.
I grandi modelli ML supervisionati richiedono milioni di esempi etichettati, ognuno dei quali deve essere etichettato da un essere umano. Una volta raccolte tutte le etichette, è necessario hardware specializzato per addestrare il modello. Le unità di elaborazione grafica (GPU) e le unità di elaborazione tensore (TPU) sono lo standard per l'hardware ML e possono essere costosi da noleggiare o acquistare: l'acquisto delle GPU può costare tra migliaia e decine di migliaia di dollari.
Infine, lo sviluppo di eccellenti modelli ML richiede l’assunzione di ricercatori o ingegneri di machine learning, che possono richiedere salari elevati grazie alle loro capacità e competenze.
Scarsa chiarezza nel processo decisionale
Per molti modelli ML, non è chiaro il motivo per cui forniscono i risultati che ottengono. AlphaGo Zero non può spiegare il ragionamento alla base del suo processo decisionale; sa che una mossa funzionerà in una situazione specifica ma non saperché. Ciò può avere conseguenze significative quando i modelli ML vengono utilizzati nelle situazioni quotidiane. I modelli ML utilizzati nel settore sanitario possono fornire risultati errati o distorti e potremmo non saperlo perché il motivo alla base dei risultati è poco chiaro. Il bias, in generale, è una grande preoccupazione per i modelli ML e la mancanza di spiegabilità rende il problema più difficile da affrontare. Questi problemi si applicano soprattutto ai modelli di deep learning. I modelli di deep learning sono modelli ML che utilizzano reti neurali a più livelli per elaborare l'input. Sono in grado di gestire dati e domande più complicati.
D'altro canto, i modelli ML più semplici e “superficiali” (come gli alberi decisionali e i modelli di regressione) non soffrono degli stessi svantaggi. Richiedono ancora molti dati ma sono economici da addestrare altrimenti. Sono anche più spiegabili. Lo svantaggio è che tali modelli possono avere un’utilità limitata; applicazioni avanzate come GPT richiedono modelli più complessi.
Il futuro dell'apprendimento automatico
I modelli ML basati su trasformatore sono stati di gran moda negli ultimi anni. Questo è il tipo di modello ML specifico che alimenta GPT (la T in GPT), Grammarly e Claude AI. Hanno ricevuto attenzione anche i modelli ML basati sulla diffusione, che alimentano prodotti per la creazione di immagini come DALL-E e Midjourney.
Questa tendenza non sembra destinata a cambiare a breve. Le aziende di ML si concentrano sull'aumento delle dimensioni dei propri modelli: modelli più grandi che hanno capacità migliori e set di dati più grandi su cui addestrarli. Ad esempio, GPT-4 aveva un numero di parametri di modello 10 volte superiore a quello di GPT-3. Probabilmente vedremo ancora più settori utilizzare l’intelligenza artificiale generativa nei loro prodotti per creare esperienze personalizzate per gli utenti.
Anche la robotica si sta scaldando. I ricercatori stanno utilizzando il machine learning per creare robot in grado di spostare e utilizzare oggetti come gli esseri umani. Questi robot possono sperimentare nel loro ambiente e utilizzare l’apprendimento per rinforzo per adattarsi rapidamente e raggiungere i propri obiettivi, ad esempio come calciare un pallone da calcio.
Tuttavia, man mano che i modelli ML diventano più potenti e pervasivi, ci sono preoccupazioni riguardo al loro potenziale impatto sulla società. Questioni come pregiudizi, privacy e spostamento del lavoro sono oggetto di accesi dibattiti e vi è un crescente riconoscimento della necessità di linee guida etiche e pratiche di sviluppo responsabile.
Conclusione
L’apprendimento automatico è un sottoinsieme dell’intelligenza artificiale, con l’obiettivo esplicito di creare sistemi intelligenti consentendo loro di apprendere dai dati. L'apprendimento supervisionato, non supervisionato, semi-supervisionato e per rinforzo sono i principali tipi di ML (insieme all'apprendimento auto-supervisionato). Il machine learning è al centro di molti nuovi prodotti in uscita oggi, come ChatGPT, auto a guida autonoma e consigli Netflix. Può essere più economico o migliore delle prestazioni umane, ma allo stesso tempo è inizialmente costoso e meno spiegabile e gestibile. Il machine learning è inoltre destinato a diventare ancora più popolare nei prossimi anni.
Il machine learning presenta molte complessità e l’opportunità di apprendere e contribuire al campo è in espansione. In particolare, le guide di Grammarly su AI, deep learning e ChatGPT possono aiutarti a saperne di più su altre parti importanti di questo campo. Oltre a ciò, entrare nei dettagli del ML (come come vengono raccolti i dati, come appaiono effettivamente i modelli e gli algoritmi dietro l'"apprendimento") può aiutarti a incorporarlo in modo efficace nel tuo lavoro.
Con il machine learning in continua crescita e con l'aspettativa che toccherà quasi tutti i settori, ora è il momento di iniziare il tuo viaggio nel machine learning!