
Cos'è l'overfitting nel machine learning?
Pubblicato: 2024-10-15L'overfitting è un problema comune che si verifica durante l'addestramento dei modelli di machine learning (ML). Può avere un impatto negativo sulla capacità di un modello di generalizzare oltre i dati di addestramento, portando a previsioni imprecise negli scenari del mondo reale. In questo articolo esploreremo cos'è il sovradattamento, come si verifica, le cause comuni alla base e i modi efficaci per rilevarlo e prevenirlo.
Sommario
- Cos'è il sovradattamento?
- Come avviene il sovradattamento
- Adattamento eccessivo vs. adattamento insufficiente
- Cosa causa il sovradattamento?
- Come rilevare il sovradattamento
- Come evitare il sovradattamento
- Esempi di overfitting
Cos'è il sovradattamento?
L'overfitting si verifica quando un modello di machine learning apprende i modelli sottostanti e il rumore nei dati di addestramento, diventando eccessivamente specializzato in quello specifico set di dati. Questa attenzione eccessiva ai dettagli dei dati di training si traduce in prestazioni scadenti quando il modello viene applicato a dati nuovi e invisibili, poiché non riesce a generalizzare oltre i dati su cui è stato addestrato.
Come avviene il sovradattamento?
L'overfitting si verifica quando un modello apprende troppo dai dettagli specifici e dal rumore nei dati di addestramento, rendendolo eccessivamente sensibile ai modelli che non sono significativi per la generalizzazione. Si consideri, ad esempio, un modello creato per prevedere le prestazioni dei dipendenti sulla base di valutazioni storiche. Se il modello si adatta eccessivamente, potrebbe concentrarsi troppo su dettagli specifici e non generalizzabili, come lo stile di rating unico di un ex manager o circostanze particolari durante un ciclo di revisione precedente. Invece di apprendere i fattori più ampi e significativi che contribuiscono alla performance, come competenze, esperienza o risultati del progetto, il modello potrebbe avere difficoltà ad applicare le proprie conoscenze ai nuovi dipendenti o a sviluppare criteri di valutazione. Ciò porta a previsioni meno accurate quando il modello viene applicato a dati diversi dal set di addestramento.
Adattamento eccessivo vs. adattamento insufficiente
A differenza dell’overfitting, l’underfitting si verifica quando un modello è troppo semplice per catturare i modelli sottostanti nei dati. Di conseguenza, le prestazioni sono scarse sia sull'addestramento che sui nuovi dati, non riuscendo a fare previsioni accurate.
Per visualizzare la differenza tra underfitting e overfitting, immaginiamo di provare a prevedere le prestazioni atletiche in base al livello di stress di una persona. Possiamo tracciare i dati e mostrare tre modelli che tentano di prevedere questa relazione:

1 Underfitting:nel primo esempio, il modello utilizza una linea retta per fare previsioni, mentre i dati effettivi seguono una curva. Il modello è troppo semplice e non riesce a cogliere la complessità della relazione tra livello di stress e prestazione atletica. Di conseguenza, le previsioni sono per lo più imprecise, anche per i dati di addestramento. Questo è inadeguato.
2Vestibilità ottimale:il secondo esempio mostra un modello che raggiunge il giusto equilibrio. Cattura la tendenza sottostante nei dati senza complicarli eccessivamente. Questo modello si generalizza bene ai nuovi dati perché non tenta di adattare ogni piccola variazione nei dati di training, ma solo il modello principale.
3Overfitting:nell'esempio finale, il modello utilizza una curva ondulata altamente complessa per adattare i dati di addestramento. Sebbene questa curva sia molto accurata per i dati di training, acquisisce anche rumore casuale e valori anomali che non rappresentano la relazione effettiva. Questo modello è eccessivamente adattato perché è talmente calibrato sui dati di addestramento che è probabile che faccia previsioni inadeguate su dati nuovi e invisibili.
Cause comuni di overfitting
Ora che sappiamo cos'è l'overfitting e perché si verifica, esploriamo alcune cause comuni in modo più dettagliato:
- Dati di addestramento insufficienti
- Dati imprecisi, errati o irrilevanti
- Grandi pesi
- Sovrallenamento
- L'architettura del modello è troppo sofisticata
Dati di addestramento insufficienti
Se il set di dati di addestramento è troppo piccolo, potrebbe rappresentare solo alcuni degli scenari che il modello incontrerà nel mondo reale. Durante l'addestramento, il modello potrebbe adattarsi bene ai dati. Tuttavia, potresti riscontrare imprecisioni significative dopo averlo testato su altri dati. Il piccolo set di dati limita la capacità del modello di generalizzare a situazioni invisibili, rendendolo incline all'adattamento eccessivo.
Dati imprecisi, errati o irrilevanti
Anche se il set di dati di addestramento è di grandi dimensioni, potrebbe contenere errori. Questi errori potrebbero derivare da varie fonti, come i partecipanti che forniscono informazioni false nei sondaggi o letture errate dei sensori. Se il modello tenta di imparare da queste imprecisioni, si adatterà a modelli che non riflettono le vere relazioni sottostanti, portando a un overfitting.
Grandi pesi
Nei modelli di machine learning, i pesi sono valori numerici che rappresentano l'importanza assegnata a caratteristiche specifiche nei dati quando si effettuano previsioni. Quando i pesi diventano sproporzionatamente grandi, il modello potrebbe adattarsi eccessivamente, diventando eccessivamente sensibile a determinate funzionalità, incluso il rumore nei dati. Ciò accade perché il modello diventa troppo dipendente da caratteristiche particolari, il che compromette la sua capacità di generalizzare a nuovi dati.
Sovrallenamento
Durante l'addestramento, l'algoritmo elabora i dati in batch, calcola l'errore per ciascun batch e regola i pesi del modello per migliorarne la precisione.
È una buona idea continuare ad allenarsi il più a lungo possibile? Non proprio! Un addestramento prolungato sugli stessi dati può far sì che il modello memorizzi punti dati specifici, limitando la sua capacità di generalizzare a dati nuovi o invisibili, che è l'essenza del sovradattamento. Questo tipo di overfitting può essere mitigato utilizzando tecniche di arresto anticipato o monitorando le prestazioni del modello su un set di convalida durante l'addestramento. Discuteremo come funziona più avanti nell'articolo.
L'architettura del modello è troppo complessa
L'architettura di un modello di machine learning si riferisce al modo in cui i suoi strati e i suoi neuroni sono strutturati e al modo in cui interagiscono per elaborare le informazioni.

Architetture più complesse possono acquisire modelli dettagliati nei dati di training. Tuttavia, questa complessità aumenta la probabilità di overfitting, poiché il modello può anche imparare a catturare rumore o dettagli irrilevanti che non contribuiscono a previsioni accurate sui nuovi dati. Semplificare l'architettura o utilizzare tecniche di regolarizzazione può aiutare a ridurre il rischio di overfitting.
Come rilevare il sovradattamento
Rilevare il sovradattamento può essere complicato perché tutto può sembrare andare bene durante l’allenamento, anche quando si verifica il sovradattamento. Il tasso di perdita (o errore), una misura di quanto spesso il modello è sbagliato, continuerà a diminuire, anche in uno scenario di overfitting. Quindi, come possiamo sapere se si è verificato un overfitting? Abbiamo bisogno di un test affidabile.
Un metodo efficace è utilizzare una curva di apprendimento, un grafico che traccia una misura chiamata perdita. La perdita rappresenta l’entità dell’errore commesso dal modello. Tuttavia, non monitoriamo solo la perdita dei dati di addestramento; misuriamo anche la perdita di dati invisibili, chiamati dati di convalida. Questo è il motivo per cui la curva di apprendimento ha tipicamente due linee: perdita di formazione e perdita di convalida.
Se la perdita di addestramento continua a diminuire come previsto, ma la perdita di convalida aumenta, ciò suggerisce un overfitting. In altre parole, il modello sta diventando eccessivamente specializzato nei dati di addestramento e fatica a generalizzare a dati nuovi e invisibili. La curva di apprendimento potrebbe assomigliare a questa:
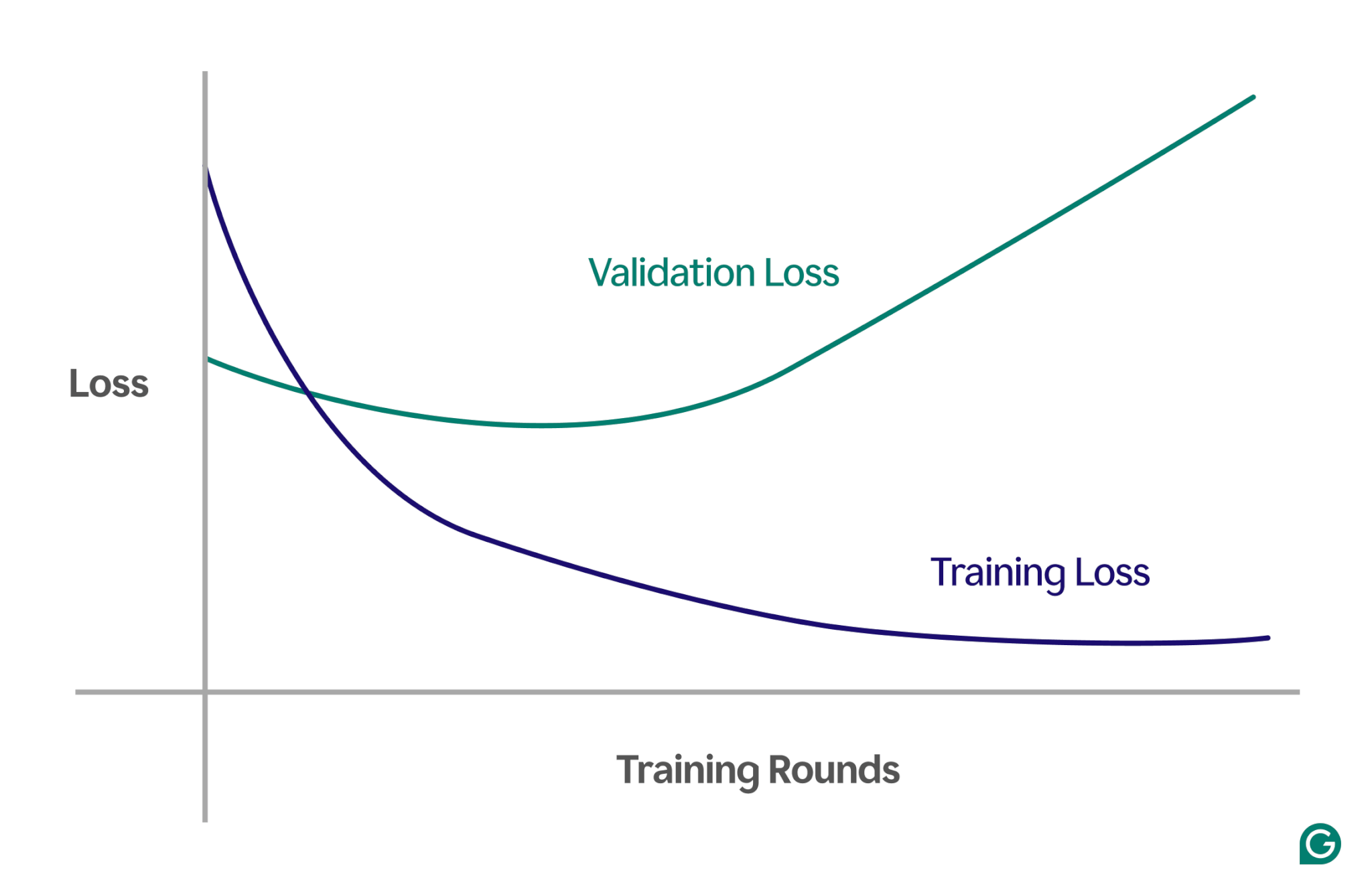
In questo scenario, anche se il modello migliora durante l'addestramento, funziona in modo scarso sui dati invisibili. Ciò probabilmente significa che si è verificato un overfitting.
Come evitare il sovradattamento
L’overfitting può essere affrontato utilizzando diverse tecniche. Ecco alcuni dei metodi più comuni:
Ridurre le dimensioni del modello
La maggior parte delle architetture dei modelli consente di regolare il numero di pesi modificando il numero di livelli, le dimensioni dei livelli e altri parametri noti come iperparametri. Se la complessità del modello causa un overfitting, può essere utile ridurne le dimensioni. Semplificare il modello riducendo il numero di strati o neuroni può ridurre il rischio di overfitting, poiché il modello avrà meno opportunità di memorizzare i dati di addestramento.
Regolarizzare il modello
La regolarizzazione comporta la modifica del modello per scoraggiare pesi elevati. Un approccio consiste nell’aggiustare la funzione di perdita in modo che misuri l’errore e includa l’entità dei pesi.
Con la regolarizzazione, l'algoritmo di training riduce al minimo sia l'errore che la dimensione dei pesi, riducendo la probabilità di pesi elevati a meno che non forniscano un chiaro vantaggio al modello. Ciò aiuta a prevenire l’overfitting mantenendo il modello più generalizzato.
Aggiungi altri dati di allenamento
Anche l'aumento delle dimensioni del set di dati di addestramento può aiutare a prevenire l'adattamento eccessivo. Con più dati, è meno probabile che il modello venga influenzato da rumore o imprecisioni nel set di dati. Esporre il modello a esempi più vari lo renderà meno propenso a memorizzare singoli punti dati e ad apprendere invece modelli più ampi.
Applicare la riduzione della dimensionalità
A volte, i dati possono contenere caratteristiche (o dimensioni) correlate, il che significa che diverse caratteristiche sono correlate in qualche modo. I modelli di machine learning trattano le dimensioni come indipendenti, quindi se le funzionalità sono correlate, il modello potrebbe concentrarsi troppo su di esse, portando a un overfitting.
Le tecniche statistiche, come l’analisi delle componenti principali (PCA), possono ridurre queste correlazioni. PCA semplifica i dati riducendo il numero di dimensioni ed eliminando le correlazioni, rendendo meno probabile il sovradattamento. Concentrandosi sulle caratteristiche più rilevanti, il modello migliora la generalizzazione a nuovi dati.
Esempi pratici di overfitting
Per comprendere meglio il sovradattamento, esploriamo alcuni esempi pratici in diversi campi in cui il sovradattamento può portare a risultati fuorvianti.
Classificazione delle immagini
I classificatori di immagini sono progettati per riconoscere gli oggetti nelle immagini, ad esempio se un'immagine contiene un uccello o un cane.
Altri dettagli potrebbero essere correlati a ciò che stai cercando di rilevare in queste immagini. Ad esempio, le foto dei cani potrebbero spesso avere l'erba sullo sfondo, mentre le foto degli uccelli potrebbero spesso avere un cielo o le cime degli alberi sullo sfondo.
Se tutte le immagini di addestramento avessero questi dettagli di sfondo coerenti, il modello di apprendimento automatico potrebbe iniziare a fare affidamento sullo sfondo per riconoscere l’animale, invece di concentrarsi sulle caratteristiche reali dell’animale stesso. Di conseguenza, quando al modello viene chiesto di classificare l'immagine di un uccello appollaiato su un prato, potrebbe erroneamente classificarla come un cane perché si adatta eccessivamente alle informazioni di sfondo. Questo è un caso di adattamento eccessivo ai dati di addestramento.
Modellazione finanziaria
Supponiamo che tu stia negoziando azioni nel tuo tempo libero e ritieni che sia possibile prevedere i movimenti dei prezzi in base alle tendenze delle ricerche su Google per determinate parole chiave. Imposti un modello di machine learning utilizzando i dati di Google Trends per migliaia di parole.
Dato che ci sono così tante parole, alcune probabilmente mostreranno una correlazione con i prezzi delle azioni per puro caso. Il modello potrebbe adattarsi eccessivamente a queste correlazioni casuali, facendo previsioni inadeguate sui dati futuri perché le parole non sono predittori rilevanti dei prezzi delle azioni.
Quando si creano modelli per applicazioni finanziarie, è importante comprendere le basi teoriche delle relazioni tra i dati. L'inserimento di set di dati di grandi dimensioni in un modello senza un'attenta selezione delle caratteristiche può aumentare il rischio di overfitting, soprattutto quando il modello identifica correlazioni spurie che esistono per puro caso nei dati di addestramento.
Superstizione sportiva
Sebbene non siano strettamente legate all’apprendimento automatico, le superstizioni sportive possono illustrare il concetto di overfitting, in particolare quando i risultati sono legati a dati che logicamente non hanno alcun collegamento con il risultato.
Durante i campionati di calcio UEFA Euro 2008 e la Coppa del Mondo FIFA 2010, un polipo di nome Paul veniva utilizzato per prevedere i risultati delle partite che coinvolgevano la Germania. Paul ha corretto quattro previsioni su sei nel 2008 e tutte e sette nel 2010.
Se si considerano solo i “dati di addestramento” delle previsioni passate di Paul, un modello che concorda con le scelte di Paul sembrerebbe prevedere molto bene i risultati. Tuttavia, questo modello non sarebbe ben generalizzato ai giochi futuri, poiché le scelte del polpo sono predittori inaffidabili dei risultati delle partite.