
Foreste casuali nell'apprendimento automatico: cosa sono e come funzionano
Pubblicato: 2025-02-03Le foreste casuali sono una tecnica potente e versatile nell'apprendimento automatico (ML). Questa guida ti aiuterà a comprendere le foreste casuali, il modo in cui funzionano e le loro applicazioni, benefici e sfide.
Sommario
- Cos'è una foresta casuale?
- Alberi decisionali vs. Foresta casuale: qual è la differenza?
- Come funzionano le foreste casuali
- Applicazioni pratiche di foreste casuali
- Vantaggi delle foreste casuali
- Svantaggi delle foreste casuali
Cos'è una foresta casuale?
Una foresta casuale è un algoritmo di apprendimento automatico che utilizza più alberi decisionali per fare previsioni. È un metodo di apprendimento supervisionato progettato sia per le attività di classificazione che di regressione. Combinando le uscite di molti alberi, una foresta casuale migliora la precisione, riduce il eccesso e fornisce previsioni più stabili rispetto a un singolo albero decisionale.
Alberi decisionali vs. Foresta casuale: qual è la differenza?
Sebbene le foreste casuali siano costruite sugli alberi decisionali, i due algoritmi differiscono significativamente nella struttura e nell'applicazione:
Alberi decisionali
Un albero decisionale è costituito da tre componenti principali: un nodo radicale, nodi decisionali (nodi interni) e nodi fogliari. Come un diagramma di flusso, il processo decisionale inizia dal nodo radice, scorre attraverso i nodi decisionali in base alle condizioni e termina in un nodo foglia che rappresenta il risultato. Mentre gli alberi decisionali sono facili da interpretare e concettualizzare, sono anche inclini a un eccesso di adattamento, specialmente con set di dati complessi o rumorosi.
Foreste casuali
Una foresta casuale è un insieme di alberi decisionali che combina i loro risultati per migliorare le previsioni. Ogni albero è addestrato su un campione bootstrap unico (un sottoinsieme campionato casualmente del set di dati originale con sostituzione) e valuta le divisioni decisionali utilizzando un sottoinsieme di funzionalità selezionato in modo casuale in ciascun nodo. Questo approccio, noto come insaccamento, introduce la diversità tra gli alberi. By aggregating the predictions—using majority voting for classification or averages for regression—random forests produce more accurate and stable results than any single decision tree in the ensemble.
Come funzionano le foreste casuali
Le foreste casuali operano combinando più alberi decisionali per creare un modello di previsione robusto e accurato.
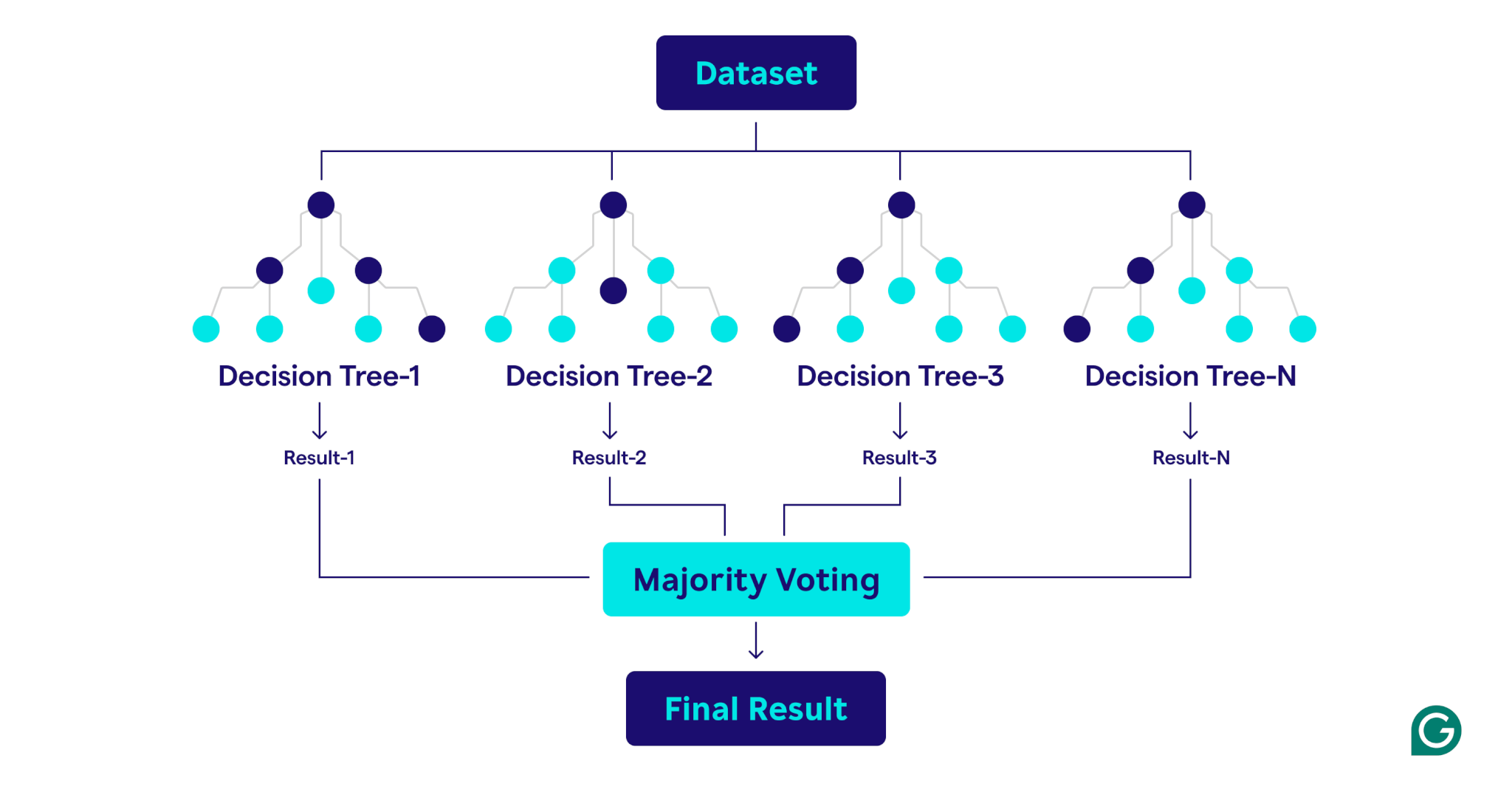
Ecco una spiegazione passo-passo del processo:
1. Impostazione iperparametri
Il primo passo è definire gli iperparametri del modello. Questi includono:
- Numero di alberi:determina le dimensioni della foresta
- Profondità massima per ogni albero:controlla la profondità di ogni albero decisionale può crescere
- Numero di funzionalità considerate ad ogni divisione:limita il numero di funzionalità valutate durante la creazione di divisioni
Questi iperparametri consentono di mettere a punto la complessità del modello e ottimizzare le prestazioni per set di dati specifici.
2. Campionamento bootstrap
Una volta impostati gli iperparametri, il processo di allenamento inizia con il campionamento bootstrap. Questo implica:
- I punti dati dal set di dati originale sono selezionati casualmente per creare set di dati di addestramento (campioni bootstrap) per ciascun albero decisionale.
- Ogni campione Bootstrap è in genere circa i due terzi della dimensione del set di dati originale, con alcuni punti dati ripetuti e altri esclusi.
- Il restante terzo dei punti dati, non incluso nel campione Bootstrap, è indicato come dati OBG (OOB).
3. Costruire alberi decisionali
Ogni albero decisionale nella foresta casuale è addestrato sul corrispondente campione Bootstrap usando un processo unico:
- Insaccamento delle caratteristiche:ad ogni divisione viene selezionato un sottoinsieme casuale di funzionalità, garantendo la diversità tra gli alberi.
- Spalazione del nodo:la migliore funzionalità dal sottoinsieme viene utilizzata per dividere il nodo:
- Per le attività di classificazione, criteri come Gini Impurità (una misura della frequenza con cui un elemento scelto in modo casuale sarebbe classificato in modo errato se fosse etichettato in modo casuale in base alla distribuzione delle etichette di classe nel nodo) misurano il modo in cui la divisione separa le classi.
- Per le attività di regressione, tecniche come la riduzione della varianza (un metodo che misura la suddivisione di un nodo riduce la varianza dei valori target, portando a previsioni più precise) valutare quanto la divisione riduce l'errore di previsione.
- L'albero cresce in modo ricorsivo fino a quando non soddisfa le condizioni di arresto, come una profondità massima o un numero minimo di punti dati per nodo.
4. Valutazione delle prestazioni
Poiché ogni albero è costruito, le prestazioni del modello vengono stimate utilizzando i dati OOB:
- La stima dell'errore OOB fornisce una misura imparziale delle prestazioni del modello, eliminando la necessità di un set di dati di convalida separato.
- Aggregando le previsioni da tutti gli alberi, la foresta casuale raggiunge una migliore precisione e riduce il sovrafittimento rispetto ai singoli alberi decisionali.

Applicazioni pratiche di foreste casuali
Come gli alberi decisionali su cui sono costruiti, le foreste casuali possono essere applicate ai problemi di classificazione e regressione in un'ampia varietà di settori, come l'assistenza sanitaria e la finanza.
Classificare le condizioni del paziente
Nell'assistenza sanitaria, le foreste casuali vengono utilizzate per classificare le condizioni del paziente in base a informazioni come storia medica, dati demografici e risultati dei test. Ad esempio, per prevedere se è probabile che un paziente sviluppi una condizione specifica come il diabete, ogni albero decisionale classifica il paziente come a rischio o meno sulla base di dati pertinenti e la foresta casuale fa la determinazione finale in base a un voto di maggioranza. Questo approccio significa che le foreste casuali sono particolarmente adatte per i set di dati complessi e ricchi di funzionalità presenti nell'assistenza sanitaria.
Prevedere le impostazioni predefinite del prestito
Le banche e le principali istituzioni finanziarie usano ampiamente foreste casuali per determinare l'idoneità del prestito e comprendere meglio il rischio. Il modello utilizza fattori come il reddito e il punteggio di credito per determinare il rischio. Poiché il rischio viene misurato come valore numerico continuo, la foresta casuale esegue la regressione anziché la classificazione. Ogni albero decisionale, addestrato su campioni di bootstrap leggermente diversi, emette un punteggio di rischio previsto. Quindi, la foresta casuale è in media tutte le previsioni individuali, risultando in una stima del rischio olistica robusta.
Prevedere la perdita dei clienti
Nel marketing, le foreste casuali vengono spesso utilizzate per prevedere la probabilità che un cliente non interrompa l'uso di un prodotto o servizio. Ciò comporta l'analisi dei modelli di comportamento dei clienti, come la frequenza di acquisto e le interazioni con il servizio clienti. Identificando questi schemi, le foreste casuali possono classificare i clienti a rischio di andarsene. Con queste intuizioni, le aziende possono adottare misure proattive e basate sui dati per mantenere i clienti, come offrire programmi di fidelizzazione o promozioni mirate.
Prevedere i prezzi immobiliari
Le foreste casuali possono essere utilizzate per prevedere i prezzi immobiliari, che è un compito di regressione. Per fare la previsione, la foresta casuale utilizza dati storici che includono fattori come la posizione geografica, le riprese quadrate e le vendite recenti nell'area. Il processo di media della foresta casuale si traduce in una previsione dei prezzi più affidabile e stabile di quella di un singolo albero decisionale, che è utile nei mercati immobiliari altamente volatili.
Vantaggi delle foreste casuali
Le foreste casuali offrono numerosi vantaggi, tra cui accuratezza, robustezza, versatilità e capacità di stimare l'importanza della caratteristica.
Precisione e robustezza
Le foreste casuali sono più accurate e robuste dei singoli alberi decisionali. Ciò si ottiene combinando le uscite di più alberi decisionali addestrati su diversi campioni di bootstrap del set di dati originale. La diversità risultante significa che le foreste casuali sono meno soggette a eccesso di alberi decisionali individuali. Questo approccio di ensemble significa che le foreste casuali sono brave a gestire dati rumorosi, anche in set di dati complessi.
Versatilità
Come gli alberi decisionali su cui sono costruiti, le foreste casuali sono altamente versatili. Possono gestire sia le attività di regressione che di classificazione, rendendoli applicabili a una vasta gamma di problemi. Le foreste casuali funzionano anche bene con set di dati grandi e ricchi di funzionalità e possono gestire i dati sia numerici che categorici.
Importanza della caratteristica
Le foreste casuali hanno una capacità integrata di stimare l'importanza di caratteristiche particolari. Come parte del processo di addestramento, le foreste casuali producono un punteggio che misura quanto la precisione del modello cambia se viene rimossa una particolare caratteristica. Mediando in media i punteggi per ciascuna caratteristica, le foreste casuali possono fornire una misura quantificabile di importanza della caratteristica. Le caratteristiche meno importanti possono quindi essere rimosse per creare alberi e foreste più efficienti.
Svantaggi delle foreste casuali
Mentre le foreste casuali offrono molti vantaggi, sono più difficili da interpretare e più costosi da allenarsi rispetto a un singolo albero decisionale e possono produrre previsioni più lentamente rispetto ad altri modelli.
Complessità
Mentre le foreste e gli alberi decisionali casuali hanno molto in comune, le foreste casuali sono più difficili da interpretare e visualizzare. Questa complessità sorge perché le foreste casuali usano centinaia o migliaia di alberi decisionali. La natura "Black Box" delle foreste casuali è un grave svantaggio quando la spiegabilità del modello è un requisito.
Costo computazionale
La formazione di centinaia o migliaia di alberi decisionali richiede molto più potenza e memoria di elaborazione rispetto alla formazione di un singolo albero decisionale. Quando sono coinvolti set di dati di grandi dimensioni, il costo computazionale può essere ancora più elevato. Questo grande requisito di risorse può comportare un costo monetario più elevato e tempi di allenamento più lunghi. Di conseguenza, le foreste casuali potrebbero non essere pratiche in scenari come Edge Computing, in cui sia la potenza di calcolo che la memoria sono scarse. Tuttavia, le foreste casuali possono essere parallelizzate, il che può aiutare a ridurre i costi di calcolo.
Tempo di previsione più lento
The prediction process of a random forest involves traversing every tree in the forest and aggregating their outputs, which is inherently slower than using a single model. Questo processo può comportare tempi di previsione più lenti rispetto ai modelli più semplici come la regressione logistica o le reti neurali, in particolare per le grandi foreste contenenti alberi profondi. Per i casi d'uso in cui il tempo è essenziale, come il trading ad alta frequenza o i veicoli autonomi, questo ritardo può essere proibitivo.